标记会话提供了一种结构化的方法,用于收集来自域专家的关于 GenAI 应用程序行为的反馈。 标记会话是一种特殊的 MLflow 运行类型,其中包含一组特定的跟踪,你希望域专家使用 MLflow 评审应用进行评审。
标记会话的目标是在现有 MLflow 跟踪上收集人工生成的评估(标签)。 可以捕获Feedback或Expectation数据,然后可以通过系统评估使用这些数据来改进 GenAI 应用。 有关在应用开发期间收集评估的详细信息,请参阅 开发期间的标签。
标记会话显示在 MLflow UI 的 “评估 ”选项卡中。 由于标记会话在 MLflow 运行时记录,因此还可以使用 MLflow API mlflow.search_runs()访问跟踪和相关评估。
标记会话的工作原理
标记会话充当跟踪及其关联标签的容器,可实现可驱动评估和改进工作流的系统反馈收集。 当您创建标记会话时,您可以定义:
- 名称:会话的描述性标识符。
- 分配的用户:将提供标签的域专家。
- 代理:(可选)用于在需要时生成响应的 GenAI 应用。
- 标记架构:反馈收集的问题和格式。 可以使用内置架构(
EXPECTED_FACTS、、EXPECTED_RESPONSEGUIDELINES)或创建自定义架构。 有关创建和使用架构的详细信息 ,请参阅“创建和管理标记架构 ”。 - 多轮次聊天:是否支持聊天样式标记。
有关 LabelingSession API 的详细信息,请参阅 mlflow.genai.LabelingSession。
创建标记会话
可以使用 UI 或 API 创建标记会话。
重要
会话名称可能不唯一。 使用 MLflow 运行 ID (session.mlflow_run_id) 存储和引用会话。
使用 UI 创建会话
若要在 MLflow UI 中创建标记会话,请执行以下作:
在 Databricks 工作区的左侧栏中,单击“ 试验”。
单击实验的名称以打开。
单击边栏中的“标记会话”。
单击“ 创建会话”。 此时会显示“ 创建标记会话 ”对话框。

输入会话的名称。
还可以选择指定评估数据集或选择标记架构。
“标签预览”部分可以让您查看问题在审阅者眼中的显示效果。
准备就绪后,单击“ 创建会话”。 新会话显示在页面左侧的列表中。
若要与审阅者共享会话,请单击列表中的会话名称,然后单击右上角的“ 共享 ”。

输入每个审阅者的电子邮件地址,然后单击“ 保存”。 审阅者会收到通知并授予评审应用的访问权限。
使用 UI 查看会话
若要查看会话的审阅者反馈,请单击列表中的会话名称,然后单击请求。
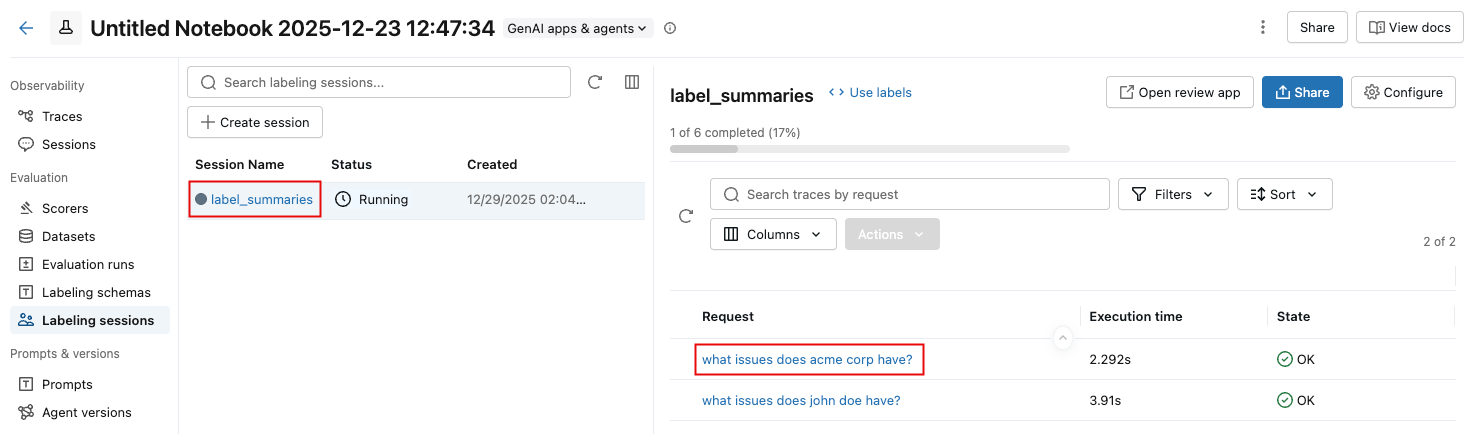
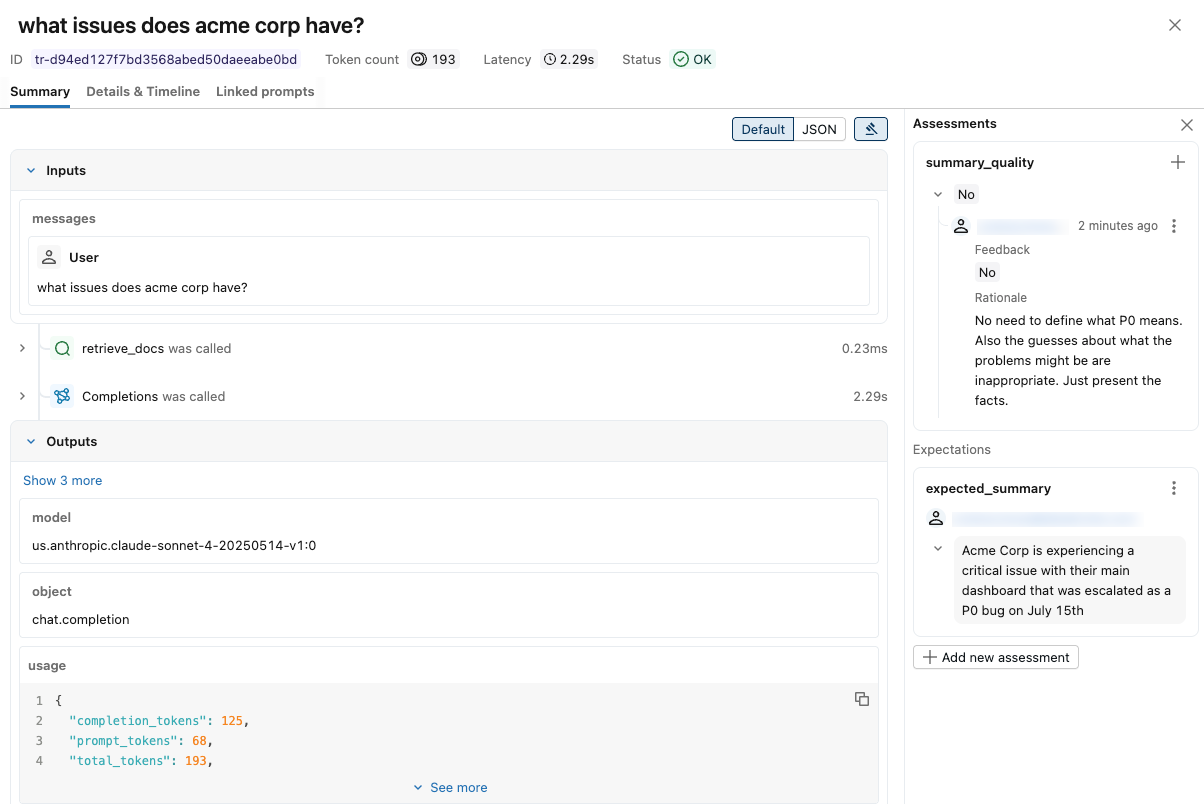
会显示一条通知,其中包含追踪信息和审阅者的评估。 若要显示审阅者的输入,请单击右上角 的“评估 ”。
使用 API 创建会话
若要创建完全以编程方式控制所有配置选项的会话,请使用 MLflow API mlflow.genai.labeling.create_labeling_session()。
创建基本会话
import mlflow.genai.labeling as labeling
import mlflow.genai.label_schemas as schemas
# Create a simple labeling session with built-in schemas
session = labeling.create_labeling_session(
name="customer_service_review_jan_2024",
assigned_users=["alice@company.com", "bob@company.com"],
label_schemas=[schemas.EXPECTED_FACTS] # Required: at least one schema needed
)
print(f"Created session: {session.name}")
print(f"Session ID: {session.labeling_session_id}")
使用自定义标签架构创建会话
import mlflow.genai.labeling as labeling
import mlflow.genai.label_schemas as schemas
# Create custom schemas first
quality_schema = schemas.create_label_schema(
name="response_quality",
type="feedback",
title="Rate the response quality",
input=schemas.InputCategorical(options=["Poor", "Fair", "Good", "Excellent"]),
overwrite=True,
)
# Create session using the schemas
session = labeling.create_labeling_session(
name="quality_assessment_session",
assigned_users=["expert@company.com"],
label_schemas=["response_quality", schemas.EXPECTED_FACTS],
)
管理标记会话
有关 API 的详细信息,请参阅 mlflow.genai.get_labeling_sessions 和 mlflow.genai.delete_labeling_sessions。
检索会话
import mlflow.genai.labeling as labeling
# Get all labeling sessions
all_sessions = labeling.get_labeling_sessions()
print(f"Found {len(all_sessions)} sessions")
for session in all_sessions:
print(f"- {session.name} (ID: {session.labeling_session_id})")
print(f" Assigned users: {session.assigned_users}")
获取特定会话
import mlflow
import mlflow.genai.labeling as labeling
import pandas as pd
# Get all labeling sessions first
all_sessions = labeling.get_labeling_sessions()
# Find session by name (note: names may not be unique)
target_session = None
for session in all_sessions:
if session.name == "customer_service_review_jan_2024":
target_session = session
break
if target_session:
print(f"Session name: {target_session.name}")
print(f"Experiment ID: {target_session.experiment_id}")
print(f"MLflow Run ID: {target_session.mlflow_run_id}")
print(f"Label schemas: {target_session.label_schemas}")
else:
print("Session not found")
# Alternative: Get session by MLflow Run ID (if you know it)
run_id = "your_labeling_session_run_id"
run = mlflow.search_runs(
experiment_ids=["your_experiment_id"],
filter_string=f"tags.mlflow.runName LIKE '%labeling_session%' AND attribute.run_id = '{run_id}'"
).iloc[0]
print(f"Found labeling session run: {run['run_id']}")
print(f"Session name: {run['tags.mlflow.runName']}")
删除会话
import mlflow.genai.labeling as labeling
# Find the session to delete by name
all_sessions = labeling.get_labeling_sessions()
session_to_delete = None
for session in all_sessions:
if session.name == "customer_service_review_jan_2024":
session_to_delete = session
break
if session_to_delete:
# Delete the session (removes from Review App)
review_app = labeling.delete_labeling_session(session_to_delete)
print(f"Deleted session: {session_to_delete.name}")
else:
print("Session not found")
向会话添加跟踪
创建会话后,必须向其添加跟踪以供专家评审。 可以使用 UI 或 add_traces() API 执行此作。 有关 API 的详细信息,请参阅 mlflow.genai.LabelingSession.add_traces。
注释
有关在“复审应用”UI 中如何为标注者呈现和显示跟踪数据的详细信息,包括不同数据类型(字典、OpenAI 消息、工具调用)的显示方式,请参阅 复审应用内容呈现。
使用 UI 添加跟踪
若要向标记会话添加追踪,请执行以下操作:
在 Databricks 工作区的左侧栏中,单击“ 试验”。
单击实验的名称以打开。
单击侧边栏中的跟踪。
选择您要添加的跟踪,通过选中跟踪 ID 左侧的复选框。
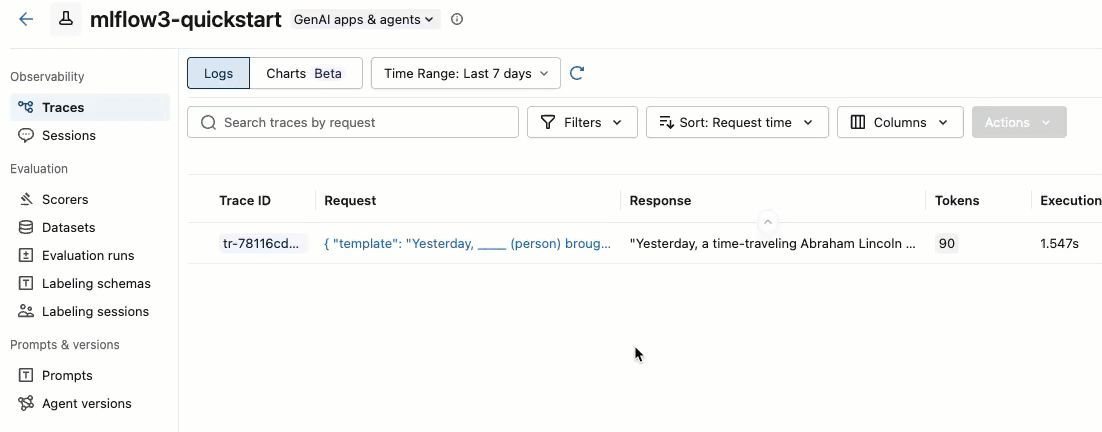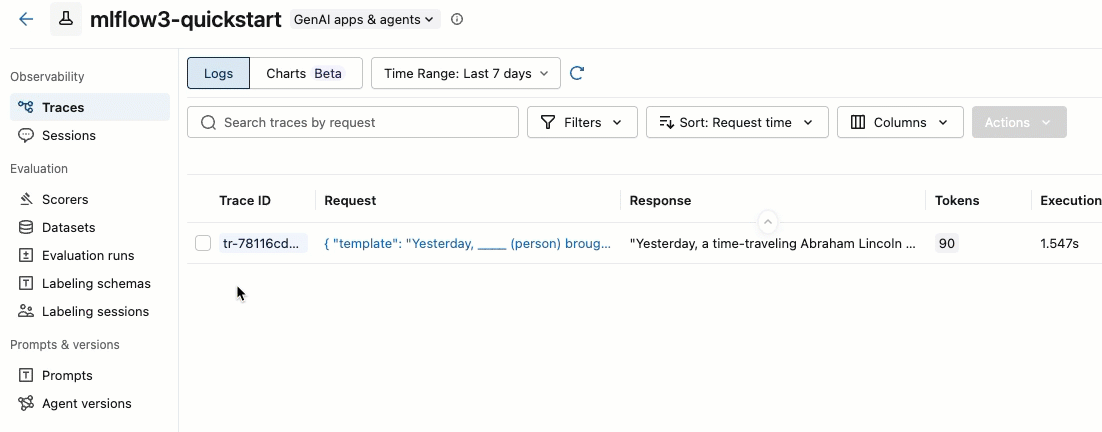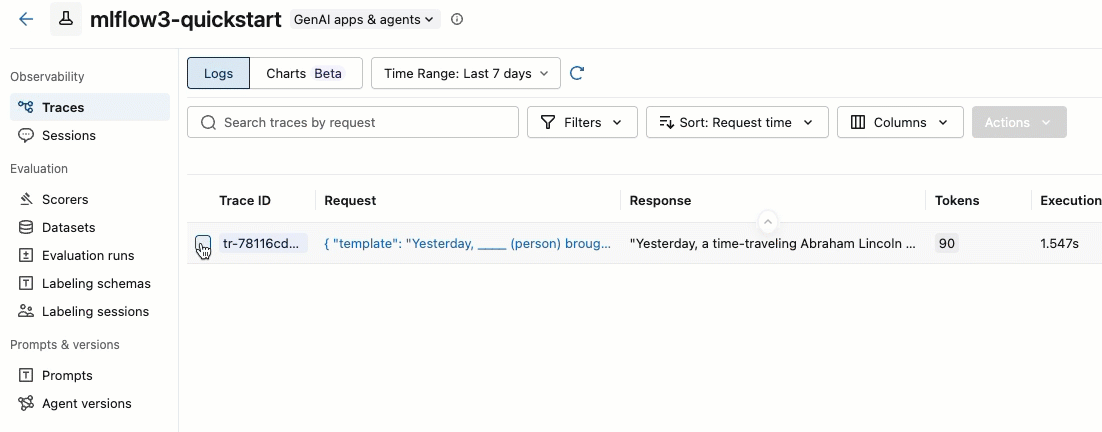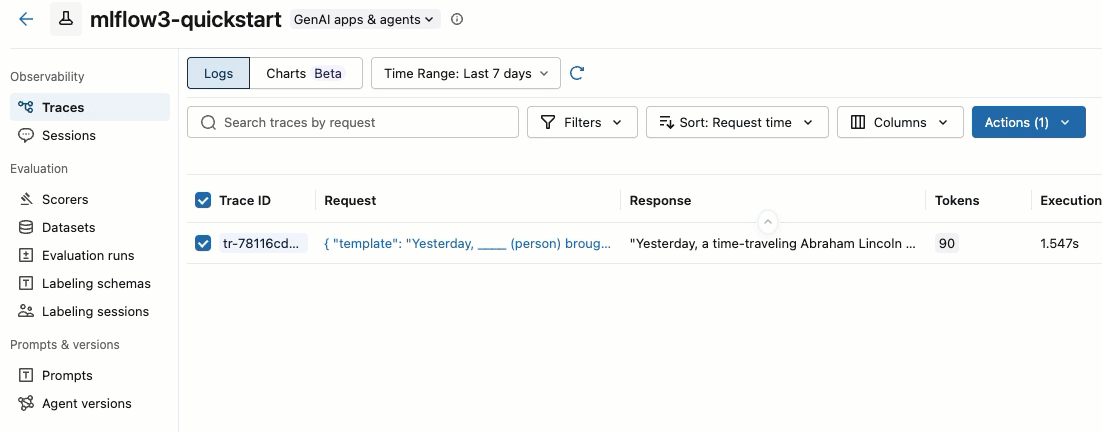
在“操作”下拉菜单中,选择“添加到标注会话”。
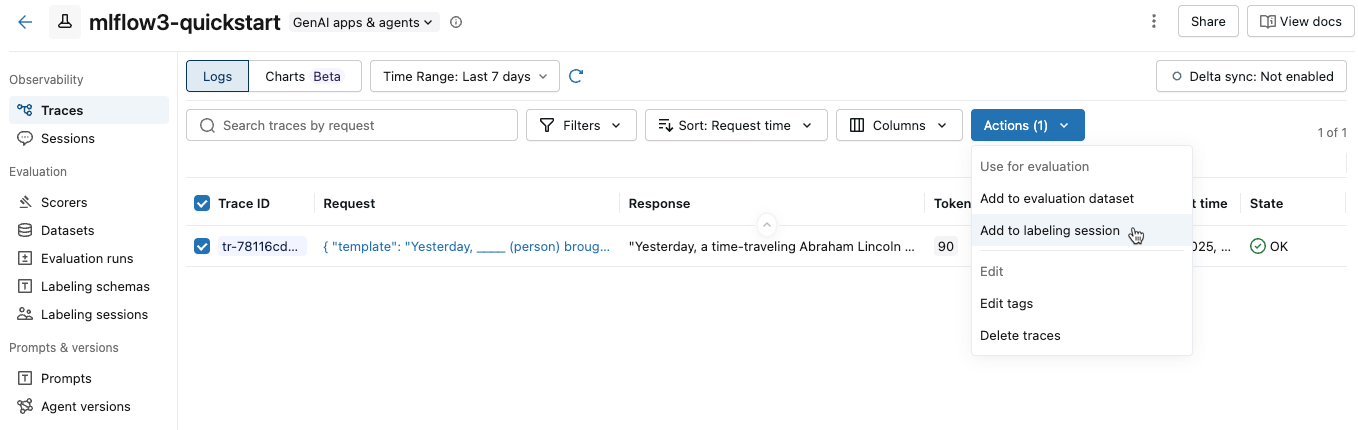
会弹出一个对话框,其中显示了实验的现有标记会话。
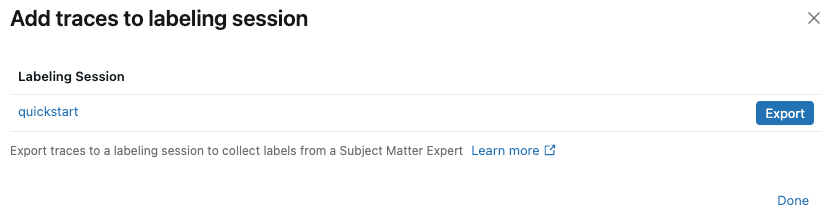
在对话框中,单击要添加跟踪的标记会话旁的导出,然后单击完成。
将跟踪结果添加到搜索结果中
初始化 OpenAI 客户端以连接到 OpenAI 托管的 LLM。
OpenAI 托管的 LLM
使用本地 OpenAI SDK 连接到由 OpenAI 托管的模型。 从 可用的 OpenAI 模型中选择一个模型。
import mlflow import os import openai # Ensure your OPENAI_API_KEY is set in your environment # os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured # Enable auto-tracing for OpenAI mlflow.openai.autolog() # Set up MLflow tracking to Databricks mlflow.set_tracking_uri("databricks") mlflow.set_experiment("/Shared/docs-demo") # Create an OpenAI client connected to OpenAI SDKs client = openai.OpenAI() # Select an LLM model_name = "gpt-4o-mini"创建示例跟踪并将其添加到标记会话:
import mlflow.genai.labeling as labeling # First, create some sample traces with a simple app @mlflow.trace def support_app(question: str): """Simple support app that generates responses""" mlflow.update_current_trace(tags={"test_tag": "C001"}) response = client.chat.completions.create( model=model_name, # This example uses Databricks hosted Claude 3.5 Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc. messages=[ {"role": "system", "content": "You are a helpful customer support agent."}, {"role": "user", "content": question}, ], ) return {"response": response.choices[0].message.content} # Generate some sample traces with mlflow.start_run(): # Create traces with negative feedback for demonstration support_app("My order is delayed") support_app("I can't log into my account") # Now search for traces to label traces_df = mlflow.search_traces( filter_string="tags.test_tag = 'C001'", max_results=50 ) # Create session and add traces session = labeling.create_labeling_session( name="negative_feedback_review", assigned_users=["quality_expert@company.com"], label_schemas=["response_quality", "expected_facts"] ) # Add traces from search results session.add_traces(traces_df) print(f"Added {len(traces_df)} traces to session")
添加单个跟踪对象
初始化 OpenAI 客户端以连接到 OpenAI 托管的 LLM。
OpenAI 托管的 LLM
使用本地 OpenAI SDK 连接到由 OpenAI 托管的模型。 从 可用的 OpenAI 模型中选择一个模型。
import mlflow import os import openai # Ensure your OPENAI_API_KEY is set in your environment # os.environ["OPENAI_API_KEY"] = "<YOUR_API_KEY>" # Uncomment and set if not globally configured # Enable auto-tracing for OpenAI mlflow.openai.autolog() # Set up MLflow tracking to Databricks mlflow.set_tracking_uri("databricks") mlflow.set_experiment("/Shared/docs-demo") # Create an OpenAI client connected to OpenAI SDKs client = openai.OpenAI() # Select an LLM model_name = "gpt-4o-mini"创建单个跟踪对象并将其添加到标记会话:
import mlflow.genai.labeling as labeling # Set up the app to generate traces @mlflow.trace def support_app(question: str): """Simple support app that generates responses""" mlflow.update_current_trace(tags={"test_tag": "C001"}) response = client.chat.completions.create( model=model_name, # This example uses Databricks hosted Claude 3.5 Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc. messages=[ {"role": "system", "content": "You are a helpful customer support agent."}, {"role": "user", "content": question}, ], ) return {"response": response.choices[0].message.content} # Generate specific traces for edge cases with mlflow.start_run() as run: # Create traces for specific scenarios support_app("What's your refund policy?") trace_id_1 = mlflow.get_last_active_trace_id() support_app("How do I cancel my subscription?") trace_id_2 = mlflow.get_last_active_trace_id() support_app("The website is down") trace_id_3 = mlflow.get_last_active_trace_id() # Get the trace objects trace1 = mlflow.get_trace(trace_id_1) trace2 = mlflow.get_trace(trace_id_2) trace3 = mlflow.get_trace(trace_id_3) # Create session and add traces session = labeling.create_labeling_session( name="negative_feedback_review", assigned_users=["name@databricks.com"], label_schemas=["response_quality", schemas.EXPECTED_FACTS], ) # Add individual traces session.add_traces([trace1, trace2, trace3])
检索反馈响应
审阅者完成标注会话后,MLflow 会将他们的响应作为 Assessments 存储在该会话中的跟踪上。 可以在 UI 中或使用 MLflow API 检索它们。
UI
打开 试验 UI,单击标记会话,然后单击请求。 单击右上角 的“评估 ”以查看每个审阅者的响应。 有关屏幕截图,请参阅 使用 UI 查看会话。
API
将 mlflow.search_traces() 与该会话的 mlflow_run_id 一起使用。 返回的数据帧包含一个 assessments 列,其中包含每个审阅者的标签。
import mlflow
traces = mlflow.search_traces(run_id=session.mlflow_run_id)
print(traces[["trace_id", "assessments"]])
有关 API 的详细信息,请参阅 mlflow.search_traces。
管理分配的用户
用户访问要求
在 Databricks 帐户中,任何用户都可以被分配到标记会话中,无论他们是否有工作区访问权限。 但是,授予用户对标记会话的权限将允许他们访问标记会话的 MLflow 试验。
为用户设置权限
对于无权访问工作区的用户,帐户管理员使用帐户级 SCIM 预配将用户和组从标识提供者自动同步到 Databricks 帐户。
对于已有权访问包含评审应用的工作区的用户,无需进行其他配置。
重要
将用户分配到标记会话时,系统会自动向包含标记会话的 MLflow 试验授予必要的 WRITE 权限。 这样,分配的用户可以访问查看和交互试验数据。
将用户添加到现有会话
若要将用户添加到现有会话,请使用 set_assigned_users。 有关 API 的详细信息,请参阅 mlflow.genai.LabelingSession.set_assigned_users。
import mlflow.genai.labeling as labeling
# Find existing session by name
all_sessions = labeling.get_labeling_sessions()
session = None
for s in all_sessions:
if s.name == "customer_review_session":
session = s
break
if session:
# Add more users to the session
new_users = ["expert2@company.com", "expert3@company.com"]
session.set_assigned_users(session.assigned_users + new_users)
print(f"Session now has users: {session.assigned_users}")
else:
print("Session not found")
替换分配的用户
import mlflow.genai.labeling as labeling
# Find session by name
all_sessions = labeling.get_labeling_sessions()
session = None
for s in all_sessions:
if s.name == "session_name":
session = s
break
if session:
# Replace all assigned users
session.set_assigned_users(["new_expert@company.com", "lead_reviewer@company.com"])
print("Updated assigned users list")
else:
print("Session not found")
同步到评估数据集
可以同步收集 Expectations 到 评估数据集。
数据集同步的工作原理
该方法 sync() 执行智能更新插入操作。 有关 API 的详细信息,请参阅 mlflow.genai.LabelingSession.sync。
- 每个跟踪记录的输入都作为唯一的键,以标识数据集中的记录。
- 对于具有匹配输入的跟踪,当预期名称相同时,标记会话中的预期会覆盖数据集中的现有预期。
- 从标记会话生成的跟踪如果与数据集中的现有跟踪输入不匹配,将被添加为新记录。
- 具有不同输入的现有数据集记录保持不变。
此方法允许你通过添加新示例和更新现有示例的基础真相来迭代地改进评估数据集。
数据集同步
import mlflow.genai.labeling as labeling
# Find session with completed labels by name
all_sessions = labeling.get_labeling_sessions()
session = None
for s in all_sessions:
if s.name == "completed_review_session":
session = s
break
if session:
# Sync expectations to dataset
session.sync(to_dataset="customer_service_eval_dataset")
print("Synced expectations to evaluation dataset")
else:
print("Session not found")
最佳做法
会话管理
使用清晰、描述性、日期标记的名称,例如
customer_service_review_march_2024。使会话专注于特定的评估目标或时间段。
建议每次会话记录 25 到 100 条,以避免审阅者疲劳。
在创建会话时,始终存储
session.mlflow_run_id。 使用运行 ID 进行编程访问,而不是依赖于会话名称,因为会话名称可能不唯一。import mlflow.genai.labeling as labeling # Good: Store run ID for later reference session = labeling.create_labeling_session(name="my_session", ...) session_run_id = session.mlflow_run_id # Store this! # Later: Use run ID to find session via mlflow.search_runs() # rather than searching by name through all sessions
用户管理
- 根据域专业知识和可用性分配用户。
- 在多个专家之间均匀分配标注工作。
- 请记住,用户必须有权访问 Databricks 工作区。