将笔记本附加到群集并运行单元格时,笔记本会保存状态并显示单元格输出。 可以清除状态和输出、处理结果表、排序、筛选和格式化数据以及下载结果。
清除笔记本状态和输出
要清除笔记本状态和输出,请选择“运行”菜单底部的“清除”选项之一。
| 菜单选项 | 描述 |
|---|---|
| 清除所有单元格输出 | 清除单元格输出。 如果共享笔记本并想要避免包含任何结果,这将非常有用。 |
| 清除状态 | 清除笔记本状态,包括函数和变量定义、数据和导入的库。 |
| 清除状态和输出 | 清除单元格输出和笔记本状态。 |
| 清除状态,然后运行全部 | 清除笔记本状态并启动新的运行。 |
结果表
运行单元格时,结果将显示在结果表中。 使用结果表,可以执行以下操作:
- 将一列或表格结果数据的其他部分复制到剪贴板。
- 对结果表进行文本搜索。
- 对数据进行排序和筛选。
- 使用键盘箭头键在表格单元格之间导航。
- 选择列名或单元格值的一部分,方法是双击并拖动以选择所需文本。
- 使用 列资源管理器 搜索、显示或隐藏、固定和重新排列列。
若要查看结果表的限制,请参阅笔记本结果表限制。
选择数据
若要在结果表中选择数据,请执行下列操作之一。
- 将数据或数据子集复制到剪贴板。
- 单击列或行标题。
- 单击表格左上角的单元格以选择整个表格。
- 将光标拖动到任意一组单元格上以选择它们。
- 若要选择多个列,请按住 Ctrl (Windows)或 Cmd (macOS),然后单击其他列标题。 然后,可以使用
 ,一次性将复制、筛选、格式和固定等操作应用到所有选定的列。
,一次性将复制、筛选、格式和固定等操作应用到所有选定的列。
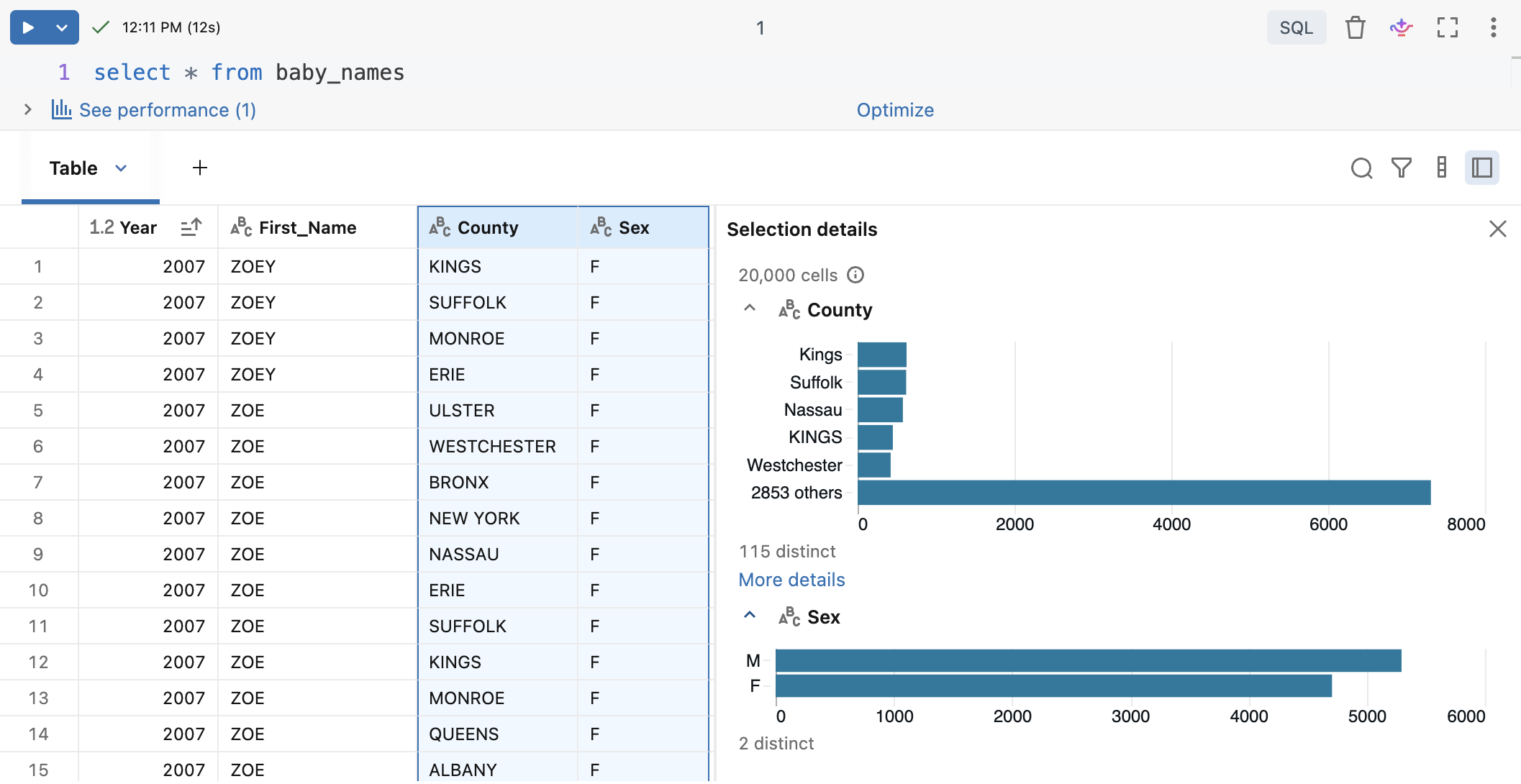
若要打开显示选择信息的侧窗格,请单击 ![]() 打开选择详细信息。 选择列标题时,将显示分析统计信息。
打开选择详细信息。 选择列标题时,将显示分析统计信息。
将数据复制至剪贴板
若要将 CSV 格式的结果表复制到剪贴板,请单击表标题选项卡旁边的向下箭头,然后单击“ 将结果复制到剪贴板”。

或者,单击表格左上角的框以选择完整表,然后右键单击并从下拉菜单中选择 “复制 ”。
可通过多种方式复制所选数据:
- 在 MacOS 上按
Cmd + C或在 Windows 上按Ctrl + C,以 CSV 格式将结果复制到剪贴板。 - 右键单击并选择“ 复制 ”,以 CSV 格式将结果复制到剪贴板。
- 右键单击并选择 “复制方式 ”,以 CSV、TSV 或 Markdown 格式复制所选数据。

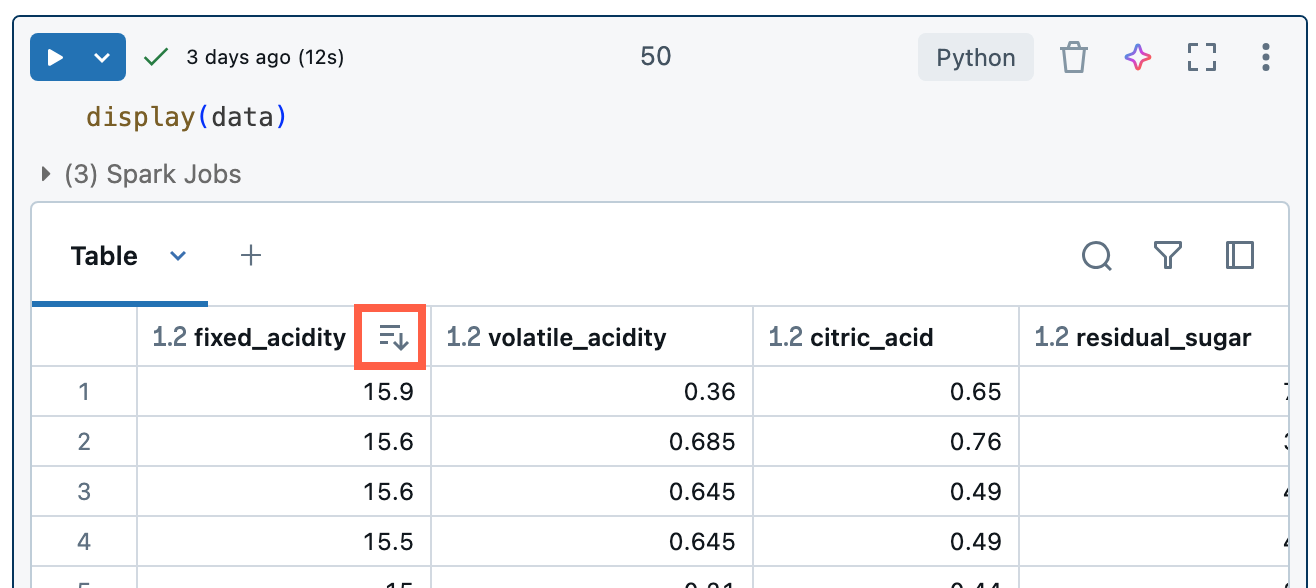
对结果进行排序
若要按列中的值对结果表进行排序,请将光标悬停在列名上。 包含列名称的图标显示在单元格右侧。 单击箭头对列进行排序。
若要按多个列进行排序,请按住 Shift 键,同时单击这些列的排序箭头。
默认情况下,排序遵循自然排序顺序。 若要实施字典排序顺序,请在 SQL 中使用ORDER BY,或在您的环境中使用相应的SORT函数。
筛选结果
使用结果表上的筛选器来仔细查看数据。 应用于结果表的筛选器还会影响可视化效果,在不修改基础查询或数据集的情况下启用交互式浏览。 请参阅 “筛选可视化效果”。
可通过多种方式创建筛选器:
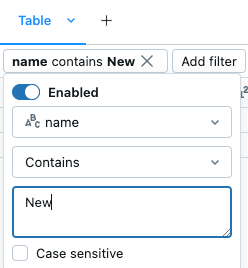
“筛选”对话框
使用内置筛选器对话框
单击
 在单元格结果的右上角打开筛选对话框。 还可以通过单击
在单元格结果的右上角打开筛选对话框。 还可以通过单击  来访问此对话框。
来访问此对话框。选择要筛选的列。
选择要应用的筛选器规则。
选择要筛选的值。
按值
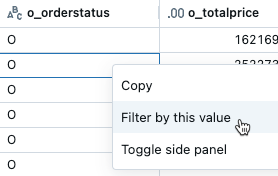
按特定值进行筛选
在结果表中,右键单击具有该值的单元格。
从下拉菜单中选择“ 按此值筛选 ”。
按列
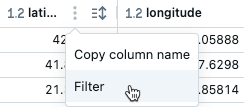
在特定列上筛选
将鼠标悬停在要筛选的列上。
单击
单击筛选。
选择要筛选的值。
若要暂时打开或关闭筛选器,请单击对话框中 的“已启用/禁用 ”按钮。
若要删除筛选器,请单击“ ![]() 在筛选器名称旁
在筛选器名称旁  。
。
将筛选器应用于完整数据集
默认情况下,筛选器仅应用于结果表中显示的结果。 如果返回的数据被截断(例如,当查询返回的行数超过 10,000 行或数据集大于 2MB 时),筛选器将仅应用于返回的行。 表右上角的注释指示筛选器已应用于截断的数据。
可以改为筛选完整数据集。 单击 “截断的数据”,然后选择“ 完整数据集”。 根据数据集的大小,可能需要很长时间才能应用筛选器。

从筛选的结果创建查询
在以 SQL 作为 默认语言的笔记本中,从筛选结果表或可视化中,可以创建应用筛选器的新查询。 在表或可视化效果的右上角,单击“ 创建查询”。 查询将作为下一个单元格添加到笔记本中。
创建的查询将筛选器叠加于原始查询。 这样,就可以使用更小、更相关的数据集,从而实现更高效的数据浏览和分析。

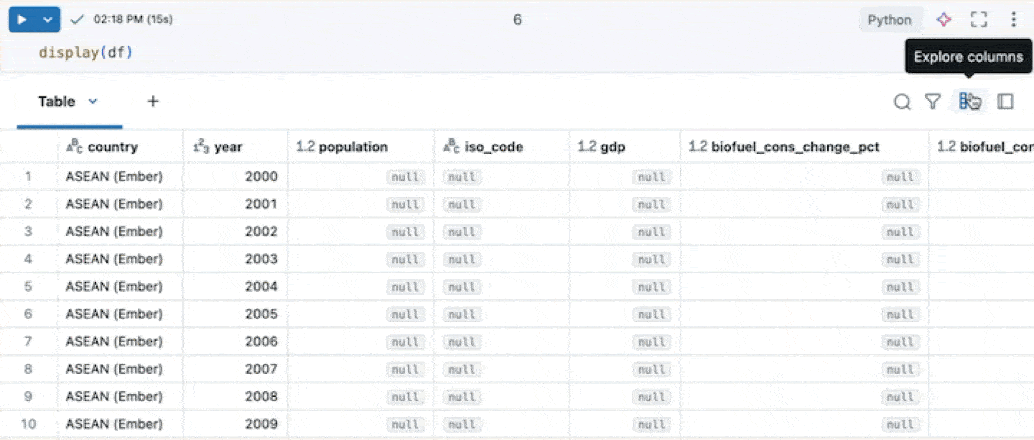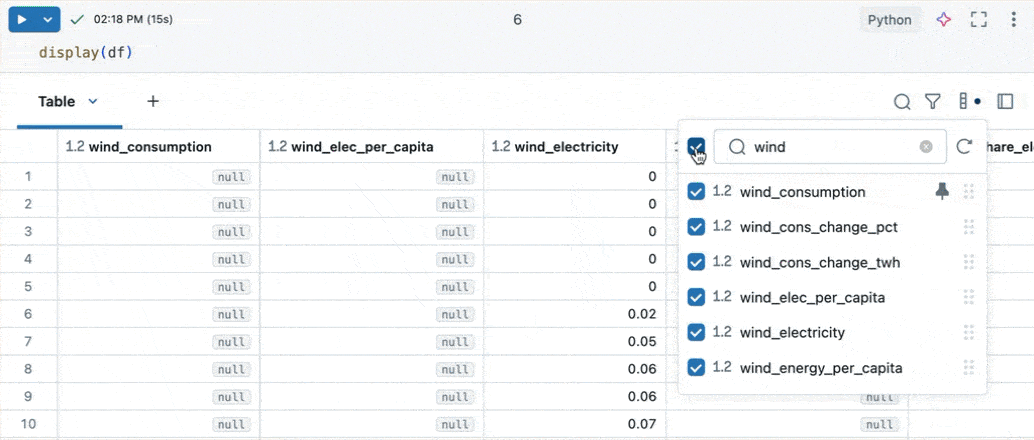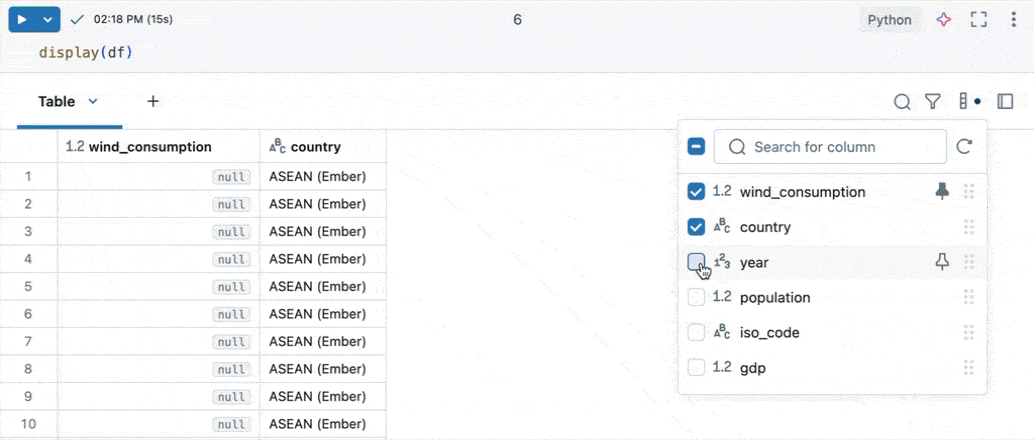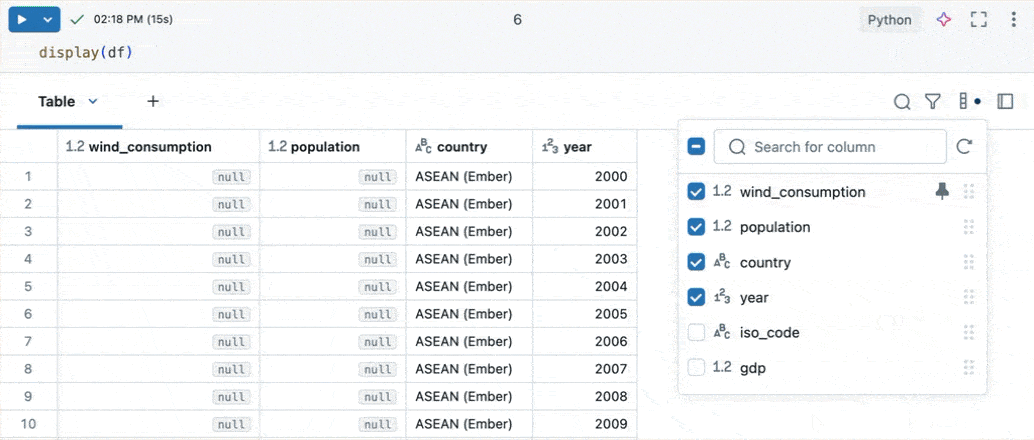
浏览列
为了便于处理包含多个列的表,可以使用列资源管理器。 要打开列浏览器,请点击结果表右上角的“列图标”(![]() )。
)。
使用列资源管理器可以:
- 搜索列:在搜索栏中键入以筛选列的列表。 单击结果表浏览器中的列以在表格中调至该列。
- 显示或隐藏列:使用复选框控制列可见性。 顶部的复选框可同时切换所有列的可见性。 可以使用名称旁边的复选框显示或隐藏各个列。
- 固定列:将鼠标悬停在列名上以显示固定图标。 单击固定图标以固定列。 在结果表中水平滚动时,固定的列保持可见。
-
重新排列列:单击并按住列名称右侧的拖动图标(
 然后将该列拖放到其新的所需位置。 这会对结果表中的列重新排序。
然后将该列拖放到其新的所需位置。 这会对结果表中的列重新排序。
设置列格式
列标题指示列的数据类型。 例如, 指示整数数据类型。 将鼠标悬停在指示器上可查看数据类型。
指示整数数据类型。 将鼠标悬停在指示器上可查看数据类型。
可以将结果表中列的格式设置为货币、百分比、URL 等类型,控制小数位数,让表格内容更清晰。
请使用列名称旁边的 Kebab 菜单来设置列格式。
下载结果
默认情况下已启用“下载结果”。 若要更改此设置,请参阅 “管理从笔记本下载结果”的功能。
可以将包含表格输出的单元格结果下载到本地计算机。 单击选项卡标题旁边的向下箭头。 菜单选项取决于结果中的行数和 Databricks Runtime 版本。 下载的结果以 CSV 文件的形式保存在本地计算机上,该文件的名称与笔记本名称相对应。
对于连接到 SQL 仓库或无服务器计算的笔记本,还可以将结果下载为 Excel 文件。
浏览 SQL 单元格结果
在 Databricks 笔记本中,SQL 语言单元格的结果会自动作为数据帧并分配给变量 _sqldf。 可以在后续的 Python 和 SQL 单元格中使用该 _sqldf 变量来引用之前的 SQL 输出。 有关详细信息,请参阅浏览 SQL 单元格结果。
查看每个单元格的多个输出
Python 笔记本以及非 Python 笔记本中的 %python 单元格支持每个单元格多个输出。 例如,以下代码的输出包括绘图和表:
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data=data.data, columns=data.feature_names)
ax = iris.plot()
print("plot")
display(ax)
print("data")
display(iris)
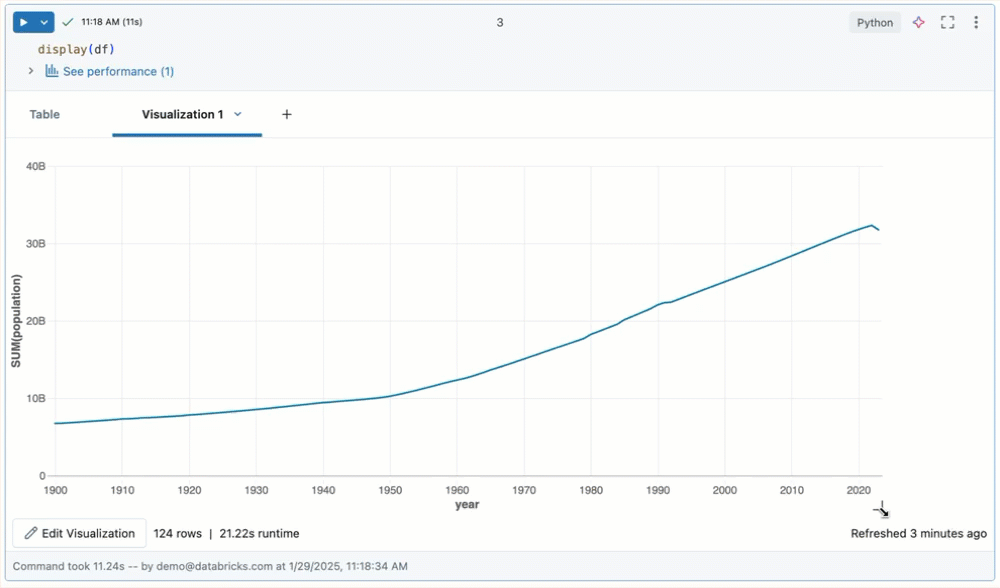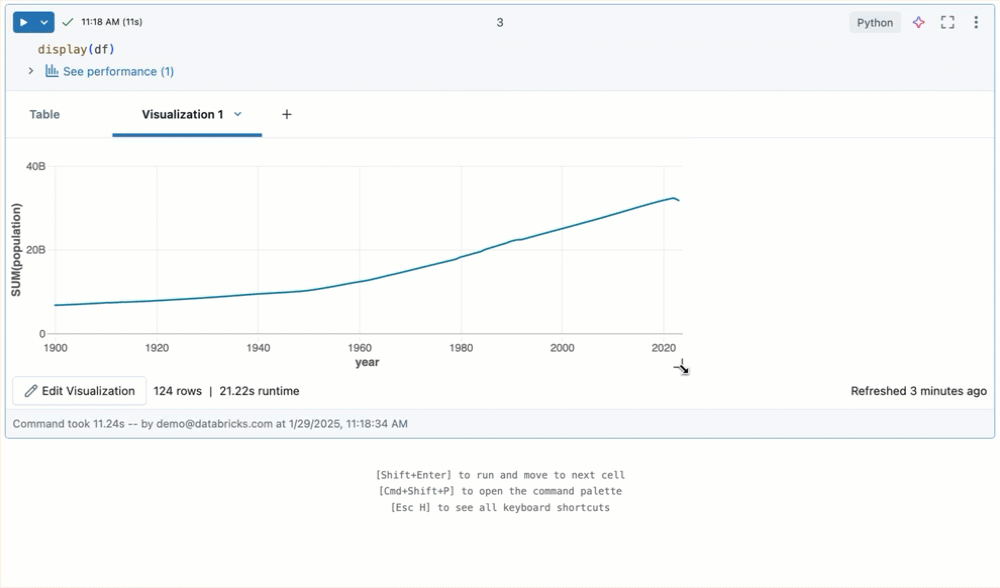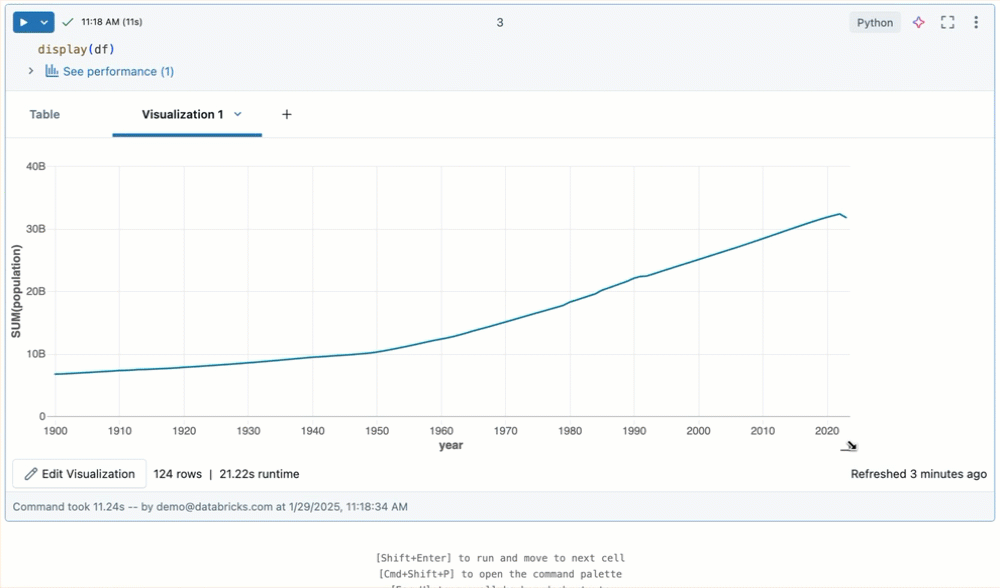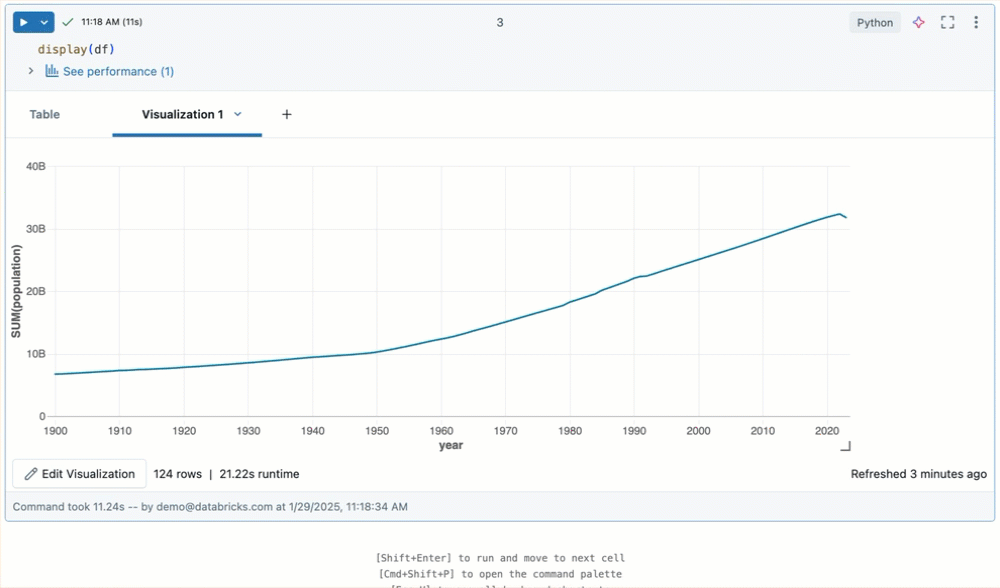
调整输出大小
通过拖动表格或可视化效果的右下角调整单元格输出的大小。
在 Databricks Git 文件夹中提交笔记本输出
要了解如何提交 .ipynb 笔记本输出,请参阅允许提交 .ipynb 笔记本输出。
- 笔记本必须是 .ipynb 文件
- 工作区管理员设置必须允许提交笔记本输出