本页介绍笔记本计算资源的选项。 您可以在通用计算资源池上运行笔记本,无服务器计算,或者对于 SQL 命令,您可以使用 SQL 数据库仓库,这是一种优化为 SQL 分析计算的资源。 有关计算类型的详细信息,请参阅 “计算”。
默认计算
在启用了 Unity Catalog 的工作区中,新笔记本默认使用无服务器计算。 如果不手动选择计算资源并运行单元格,笔记本会自动连接到无服务器计算资源。
自动附加计算
在开发人员设置中,可以将笔记本配置为自动附加到计算资源,并在与编辑器交互时启动会话:
单击右上角的用户图标。
单击“设置”。
单击 “开发人员 ”导航到开发人员设置。
要在编辑器交互时自动启动计算会话,请启用编辑器交互时自动创建会话。 Databricks 根据您的首选项(无服务器计算或 SQL 仓库)以及上次使用的计算资源默认使用计算资源。
OR
如果不希望笔记本自动连接到并启动计算资源,请关闭此设置。
代码帮助功能(包括自动完成、代码格式设置和调试器)要求将笔记本附加到活动计算会话。 如果笔记本尚未启动计算会话,则代码协助功能处于非活动状态。
面向笔记本的无服务器计算
无服务器计算使你能够快速将笔记本连接到按需计算资源。
若要附加到无服务器计算,请单击笔记本中的计算下拉菜单,然后选择 “无服务器”。
有关详细信息,请参阅适用于笔记本的无服务器计算。
无服务器笔记本的自动会话还原
无服务器计算的空闲终止可能会导致笔记本中正在进行的工作(如 Python 变量值)丢失。 若要避免这种情况,请 为无服务器笔记本启用自动会话还原。
- 单击工作区右上角的用户名,然后单击下拉列表中的 “设置 ”。
- 在“设置”边栏中,选择“开发人员”。
- 在 实验性功能 下,切换打开 无服务器笔记本的自动会话还原 设置。
启用此设置后,Databricks 可以在空闲终止之前快照无服务器笔记本的内存状态。 在空闲断开连接后返回到笔记本时,页面顶部会显示一个横幅。 单击“ 重新连接 ”以还原工作状态。
重新连接时,Databricks 将恢复整个工作环境,包括:
- Python 变量、函数和类定义:Python 状态使用 pickle/cloudpickle 进行进程内序列化,并还原到新的 REPL 中,因此无需重新导入或重新声明。
- Spark 数据帧、缓存视图和临时视图:已加载、转换或缓存的数据(包括临时视图)会保留,因此避免了昂贵的重新加载或重新计算。
- Spark 会话状态:Spark 级别配置设置、临时视图、目录修改和用户定义的函数(UDF)通过 Spark Connect 会话迁移进行还原,因此无需重置它们。
如果环境已发生变化,使反序列化过程变得不安全,例如不兼容的 Python 版本或包版本,快照将失效,并且笔记本会重新启动一个新的会话。
快照数据存储
快照数据存储在工作区的默认存储中。 笔记本本身仅存储元数据,包括具有笔记本 ID、时间戳和会话信息的指针。 数据有效负载不存储在笔记本中。 Blob 路径在笔记本属性中存储之前进行加密,快照路径从笔记本导出和导入中排除,以防止将状态还原到其他工作区。
快照遵循云存储 TTL 默认值(大约一个月)并自动过期。 删除笔记本也会删除其快照。 云账户在使用标准工作区存储时会产生存储费用。 此功能使用 Python 进程的序列化,而不是容器级别的检查点,从而使快照更小、更快地创建。
安全性和访问控制
快照还原遵循笔记本权限。 还原状态需要笔记本的 RUN 权限。 加密元数据可防止查看者直接提取快照 Blob,并在还原时强制实施权限检查。
局限性
此功能有限制,不支持还原以下内容:
- Spark 状态存在时间超过 4 天
- Spark 状态信息大于 50 MB
- 与 SQL 脚本相关的数据
- 文件句柄
- 锁和其他并发基元
- 网络连接
将笔记本附加到通用计算资源
若要将笔记本附加到通用计算资源,需要对计算资源具有 CAN ATTACH TO 权限。
重要
只要笔记本附加到某计算资源,对笔记本具有“可运行”权限的任何用户就具有访问该计算资源的隐式权限。
若要将笔记本附加到计算资源,请单击 笔记本工具栏中的计算选择器 ,然后从下拉菜单中选择资源。
该菜单显示你最近使用过或当前正在运行的一系列通用计算和 SQL 仓库。
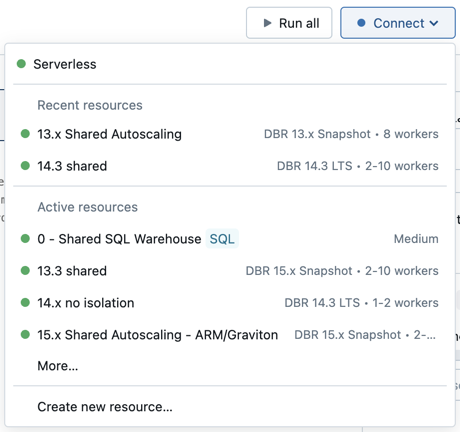
若要从所有可用计算中进行选择,请单击“更多...”。 从可用的常规计算或 SQL 仓库中进行选择。
还可以通过从下拉菜单中选择“创建新资源...”来创建新的通用计算资源。
重要
附加的笔记本定义了以下 Apache Spark 变量。
| 类 | 变量名称 |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
不要创建SparkSession、SparkContext或SQLContext。 这样做会导致行为不一致。
将笔记本与 SQL 仓库配合使用
将笔记本附加到 SQL 仓库时,可以运行 SQL 和 Markdown 单元。 使用任何其他语言(如 Python 或 R)运行单元格都会导致错误。 在 SQL 仓库上执行的 SQL 单元显示在 SQL 仓库的查询历史记录中。 运行查询的用户可以通过单击输出底部的耗时从笔记本查看查询概要。
附加到 SQL 仓库的笔记本支持进行 SQL 仓库会话,您可以在会话中定义变量、创建临时视图,并在多个查询执行过程中持久化状态。 可以迭代生成 SQL 逻辑,而无需一次性运行所有语句。 请参阅什么是 SQL 仓库会话?
运行笔记本需要专业版或无服务器 SQL 仓库。 你必须有权访问工作区和 SQL 仓库。
若要将笔记本附加到 SQL 仓库,请执行以下操作:
单击笔记本工具栏中的计算选择器。 下拉菜单显示当前正在运行或最近使用的计算资源。 SQL 仓库带有
 。
。从菜单中选择一个 SQL 仓库。
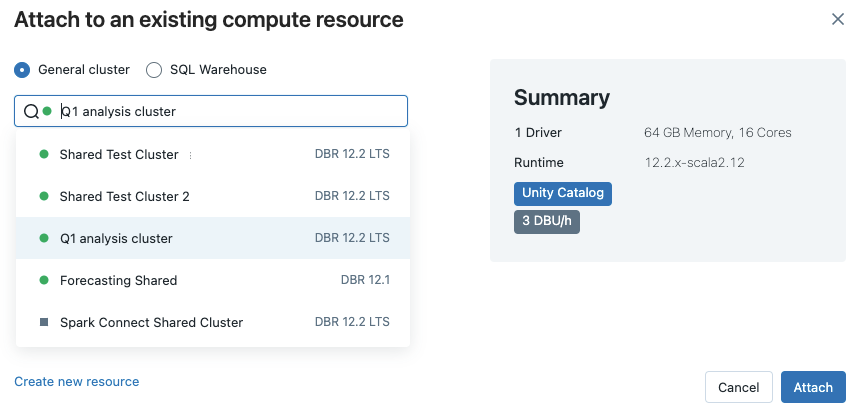
若要查看所有可用的 SQL 仓库,请从下拉菜单中选择 “更多...” 。 此时会出现一个对话框,其中显示了笔记本可用的计算资源。 选择 SQL 仓库,选择要使用的仓库,然后单击“ 附加”。
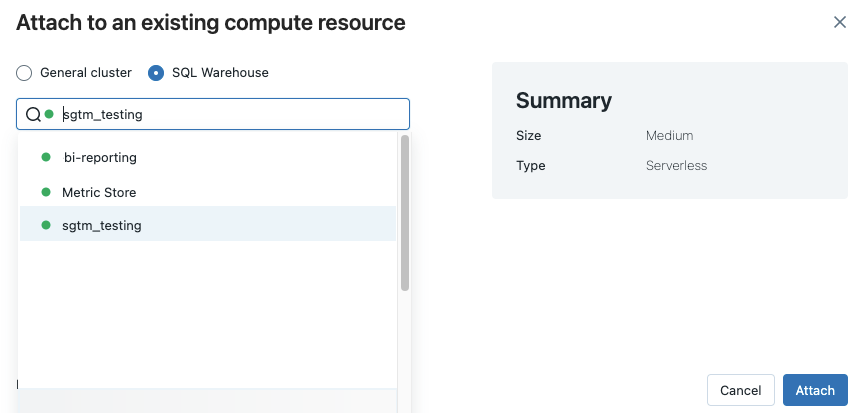
创建工作流或计划作业时,还可以选择 SQL 仓库作为 SQL 笔记本的计算资源。
SQL 仓库限制
有关详细信息,请参阅 Databricks 笔记本的已知限制 。