可以使用工作区 UI、Databricks CLI 或工作区 API 管理 Databricks 笔记本。 此页上的任务使用 UI;有关其他方法,请参阅 Databricks CLI 和 工作区 API 参考。
为笔记本和文件启用选项卡
若要更好地在工作区笔记本和文件之间导航,请启用选项卡体验。 转到 “设置 > 开发人员”,向下滚动到 实验功能,并打开 笔记本和文件的选项卡。

选项卡体验允许在打开的笔记本、查询和文件之间快速切换,而无需导航到工作区文件浏览器,或打开多个浏览器选项卡。 还可以在新选项卡中打开和创建笔记本。
创建笔记本
使用边栏中的“新建”按钮
若要在默认文件夹中创建新笔记本,请单击左侧边栏中的“ + 新建 ”,然后从菜单中选择 “笔记本 ”。
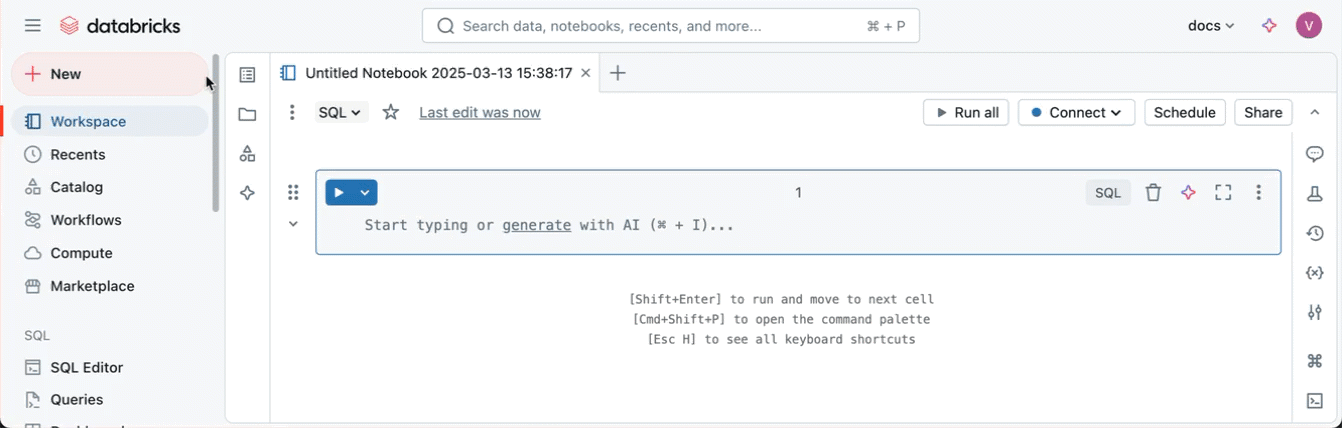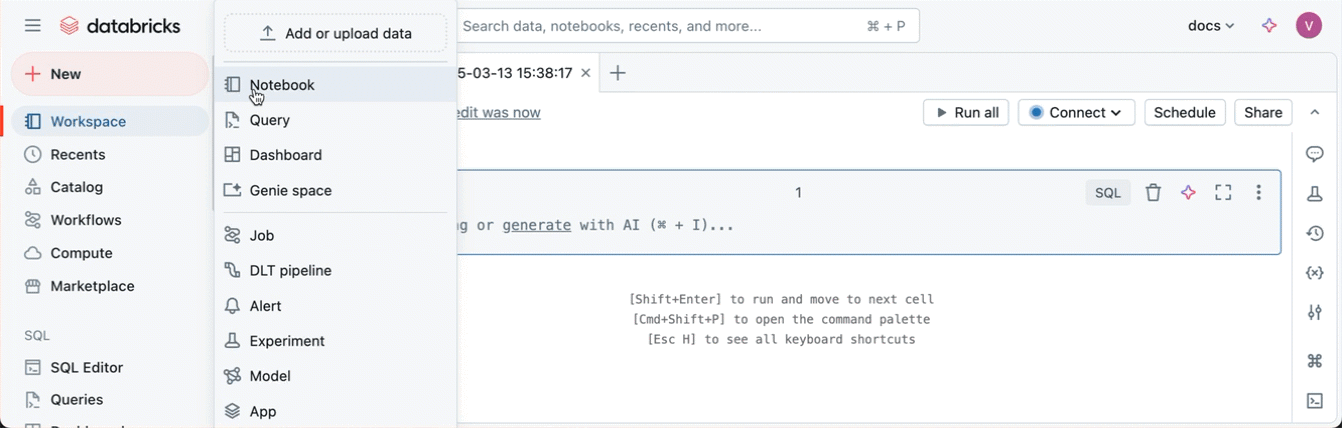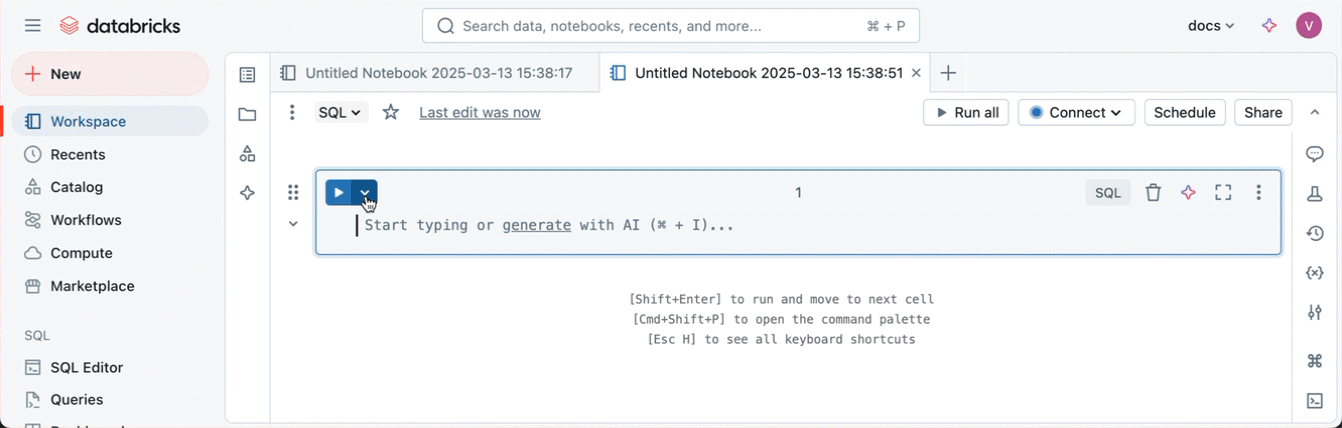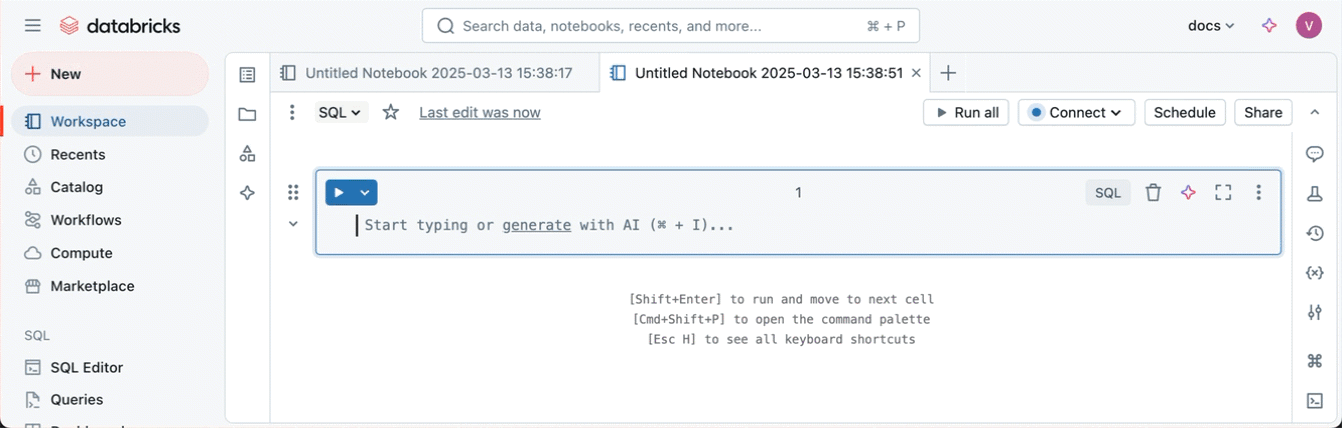
Databricks 会在主工作区的文件夹中创建并打开一个新的空白笔记本 Drafts 。 将笔记本命名后,它会从 Drafts 文件夹移到你的主工作区文件夹。 默认语言是最近使用的语言。 在启用了 Unity Catalog 的工作区中,笔记本会自动连接到无服务器计算服务。 否则,笔记本将绑定到您最近使用过的计算资源。
在任何文件夹中创建笔记本
可以按照以下步骤在任何文件夹(例如,在共享文件夹中)创建新笔记本:
在边栏中单击
 “工作区”。
“工作区”。右键单击任何文件夹的名称,然后选择“创建 > 笔记本”。 将在工作区中打开一个空白笔记本。
在新选项卡中创建笔记本
如果 启用了笔记本和文件的选项卡,则还可以通过单击 + 最后一个选项卡右侧的图标,从任何打开的工作区文件创建新笔记本。

打开笔记本
在工作区中,单击笔记本将其打开。
如果 启用了笔记本和文件的选项卡,可以通过单击 + 选项卡栏上的图标或在左侧面板上的工作区浏览器中单击笔记本,在新选项卡中打开笔记本。
克隆笔记本
克隆笔记本:
- 打开笔记本后,单击笔记本工具栏中的“文件”,然后单击“克隆...”。
- (可选)编辑笔记本的新名称。
- (可选)单击“ 浏览 ”以更改工作区位置以将笔记本克隆到。 默认情况下,笔记本克隆到与当前笔记本相同的位置。
- (可选)取消选中“包括输出”,以将单元格输出排除在克隆的笔记本之外。 默认情况下,包括输出。
- 单击“克隆”。
删除笔记本
有关如何访问工作区菜单以及删除工作区中的笔记本或其他项目的信息,请参阅“使用文件夹和文件夹对象”和“管理工作区对象”。
复制笔记本路径或 URL
若要在不打开笔记本的情况下获取笔记本文件路径或 URL,请右键单击笔记本名称,然后选择“复制 > 路径”或“复制 > URL”。
重命名笔记本
若要更改已打开笔记本的标题,请单击标题并进行内联编辑,或单击“文件”>“重命名”。
控制对笔记本的访问
如果 Azure Databricks 帐户有高级计划,则可以使用工作区访问控制来控制谁有权访问笔记本。
配置编辑器设置
若要配置编辑器设置,请执行以下操作:
单击工作区右上角的用户名,然后从下拉菜单中选择 “设置 ”。
在“设置”边栏中,选择“开发人员”。
查看附加到群集的笔记本
群集详细信息页上的“笔记本”选项卡显示了最近附加到群集的笔记本。 该选项卡还显示了笔记本的状态,以及上次在笔记本中运行命令的时间。