这些功能和 Azure Databricks 平台的改进已于 2019 年 1 月发布。
注意
在大多数情况下,下面列出的发布日期和内容仅对应于Azure公有云的实际部署。
本文提供 Azure 公有云上的 Azure Databricks 服务演进历程供您参考,其内容可能与由世纪互联运营的 Azure 中的实际部署不一致。
注意
发布分阶段进行。 在初始发布日期后,可能最长需要等待一周,你的 Azure Databricks 帐户才会更新。
即将发生的更改:Python 3 将成为创建群集时的默认版本
2019 年 1 月 29 日
当 Databricks 平台版本 2.91 在二月中旬发布时,新群集的默认 Python 版本将从 Python 2 切换到 Python 3。 现有群集当然不会更改其 Python 版本。 但如果你习惯在新建群集时将 Python 2 作为默认版本,则需开始注意 Python 版本的选择。
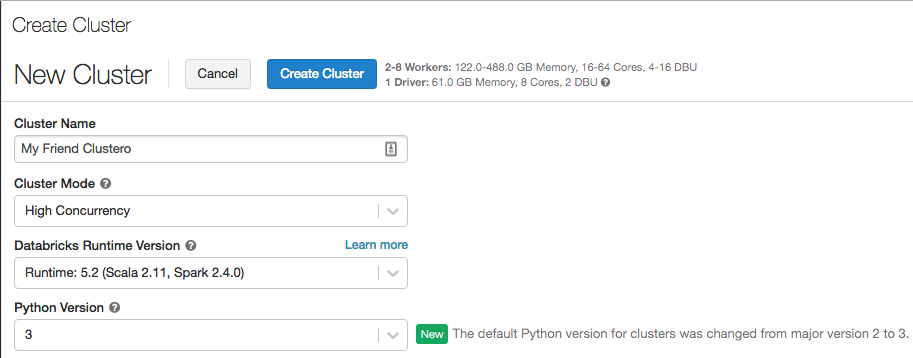
现已发布用于机器学习的 Databricks Runtime 5.2 (Beta)
2019 年 1 月 24 日
Databricks Runtime 5.2 ML 是基于 Databricks Runtime 5.2 构建的。 它包含许多常见的机器学习库,包括 TensorFlow、PyTorch、Keras 和 XGBoost,并使用 Horovod 提供分布式 TensorFlow 训练。 除了自 Databricks Runtime ML 5.1 以来的库更新外,Databricks Runtime 5.2 ML 还包括以下新功能:
- 随着 Databricks 的性能优化,GraphFrames 现在支持 Pregel API (Python)。
-
HorovodRunner 添加了以下功能:
- 在 GPU 群集上,训练过程映射到 GPU 而不是工作器节点,以简化对多 GPU 实例类型的支持。 利用此内置支持,你可以在无需自定义代码的情况下分发到多 GPU 计算机上的所有 GPU。
-
HorovodRunner.run()现在返回来自第一个训练过程的返回值。
Databricks Runtime 5.2 发布版
2019 年 1 月 24 日
Databricks Runtime 5.2 现已推出。 Databricks Runtime 5.2 包括 Apache Spark 2.4.0、新增的 Delta Lake 和结构化流式处理功能与升级,以及已升级的 Python、R、Java 和 Scala 库。
群集配置 JSON 视图
2019 年 1 月 15 日 - 22 日
群集配置页现在支持 JSON 视图:
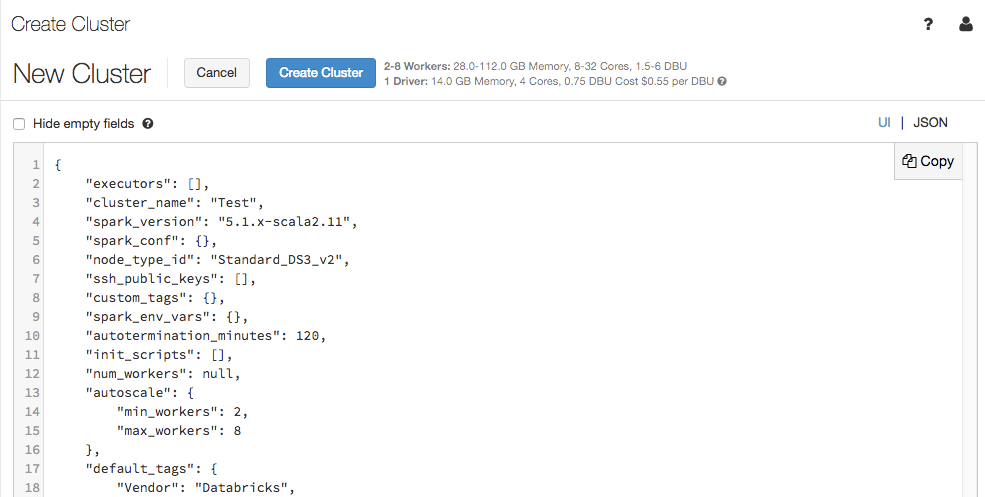
JSON 视图为只读视图。 不过,你可以复制 JSON,并将它与群集 API 配合使用,以便创建和更新群集。
群集用户界面
2019 年 1 月 15 日 -22 日:版本 2.89
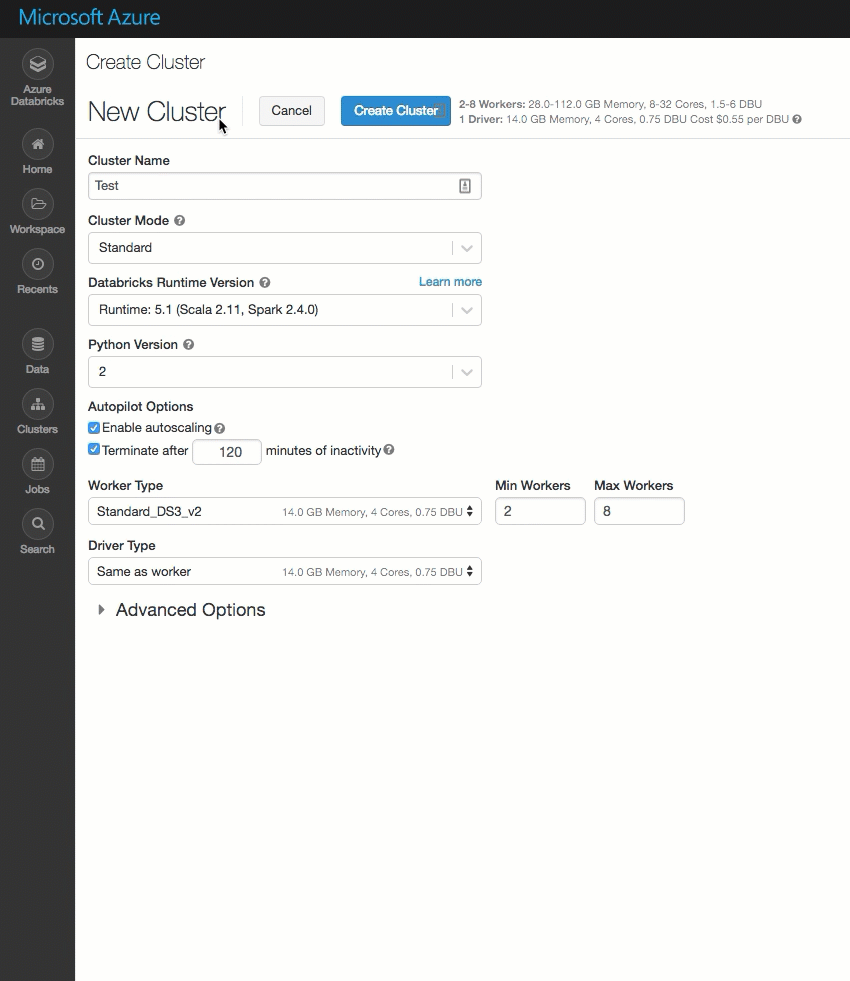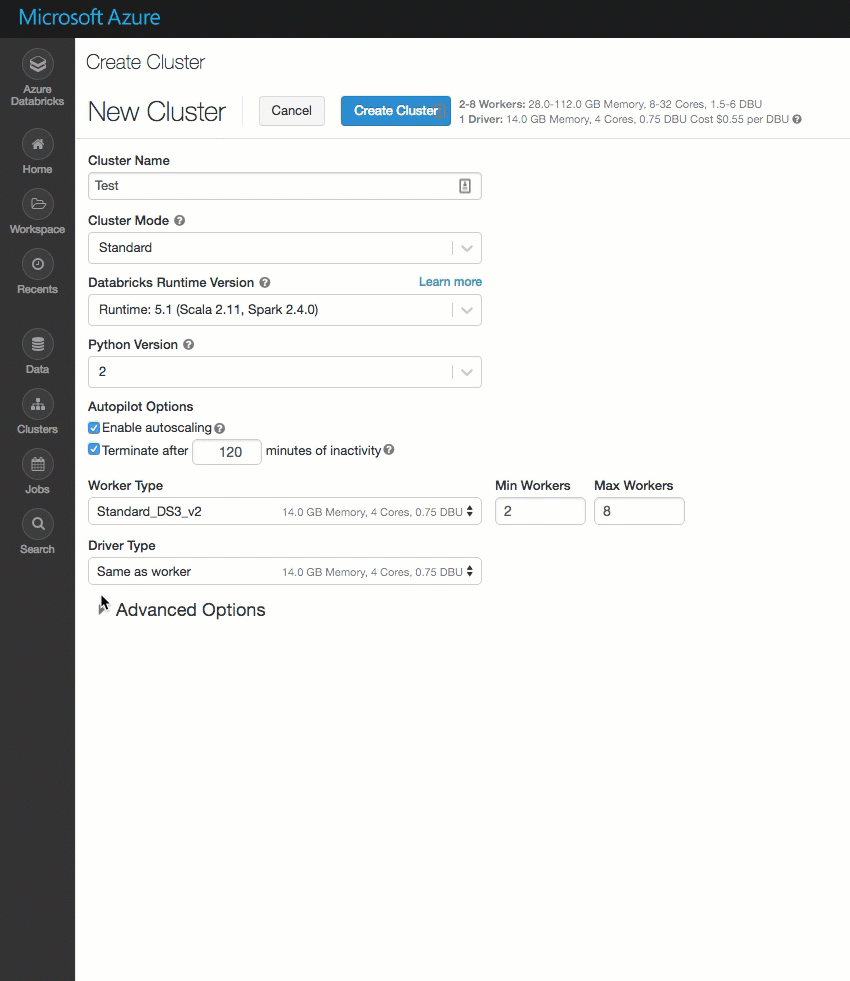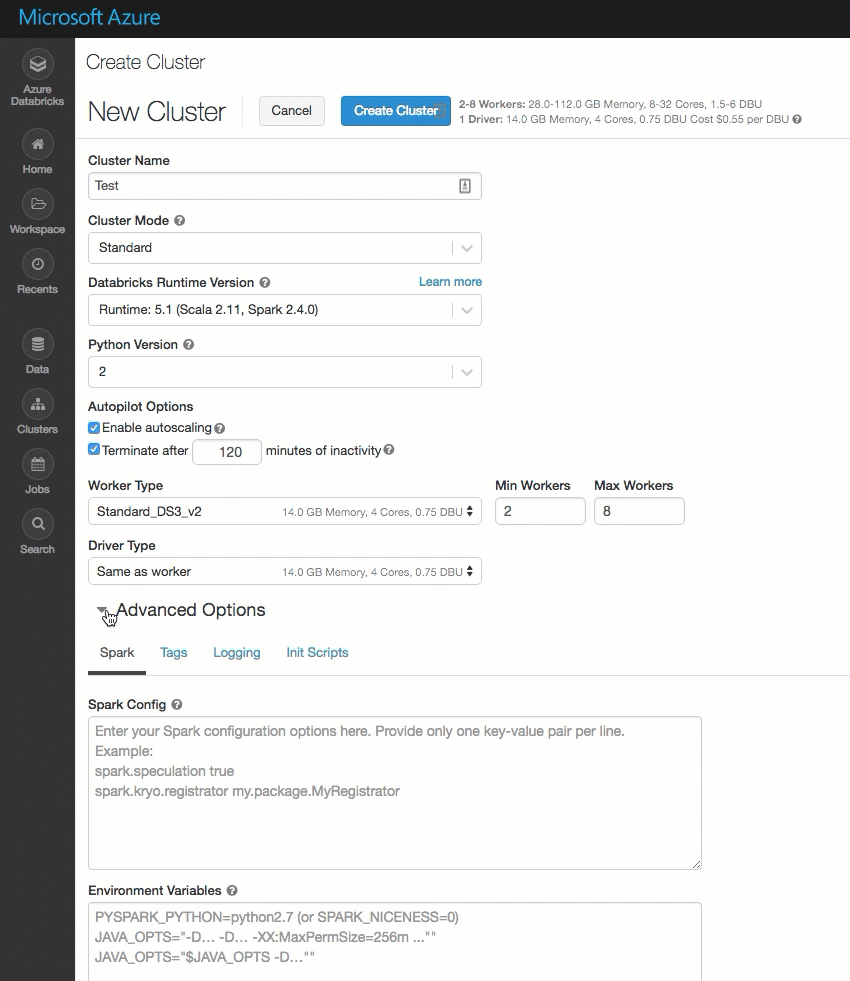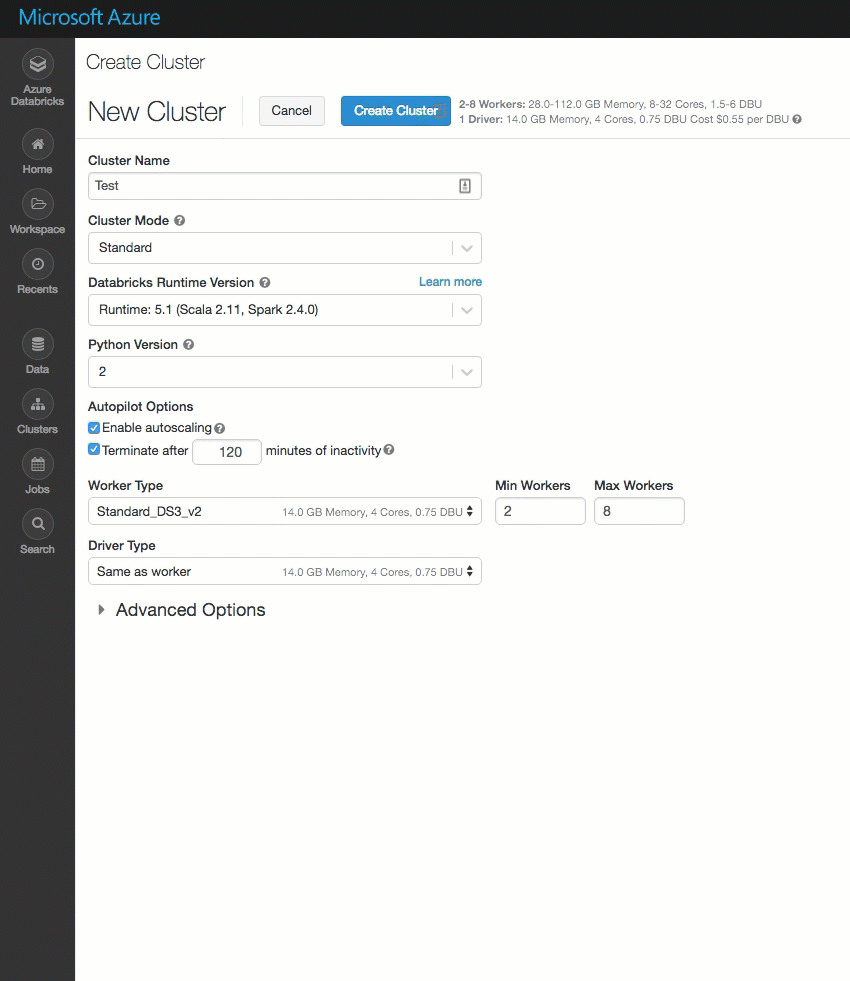
已清理“群集创建”页,并对其进行重新组织以方便使用,其中包括新的“高级选项”开关。
在自己的 Azure 虚拟网络中部署 Azure Databricks(VNet 注入)
2019 年 1 月 10 日
重要
此功能目前以公共预览版提供。
Azure Databricks 的默认部署是 Azure 上的完全托管服务:所有计算平面资源(包括与所有群集关联的虚拟网络 (VNet))都部署到锁定的资源组。 但如果需要进行网络自定义,那么现在可以在自己的虚拟网络中部署 Azure Databricks(有时称为 VNet 注入),以便能够:
- 使用服务终结点以更安全的方式将 Azure Databricks 连接到其他 Azure 服务(如 Azure 存储)。
- 连接到本地数据源以与 Azure Databricks 配合使用,以充分利用用户定义的路由。
- 将 Azure Databricks 连接到网络虚拟设备以检查所有出站流量并根据允许和拒绝规则执行操作。
- 将 Azure Databricks 配置为使用自定义 DNS。
- 配置网络安全组 (NSG) 规则以指定出口流量限制。
- 在现有虚拟网络中部署 Azure Databricks 群集。
通过将 Azure Databricks 部署到自己的虚拟网络中,还可以利用灵活的 CIDR 范围(虚拟网络的 CIDR 范围在 /16-/24 之间,子网的 CIDR 范围在 /18-/26 之间)。
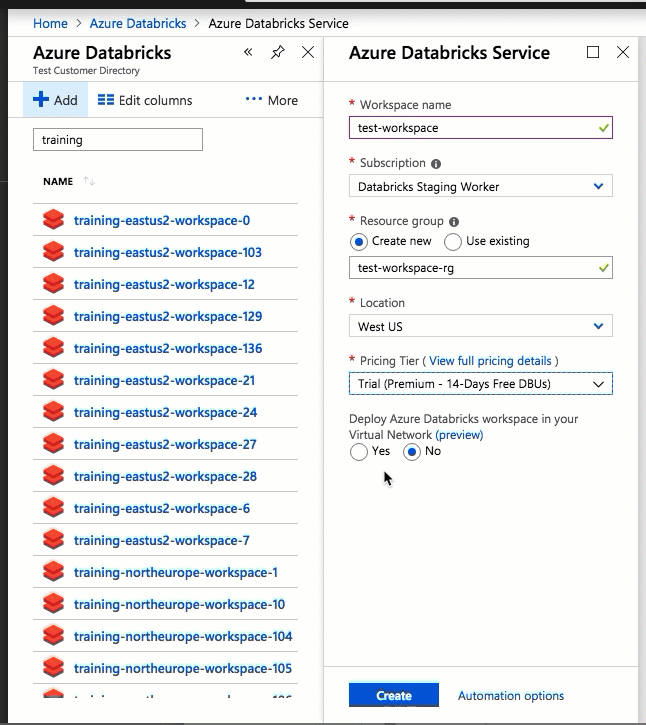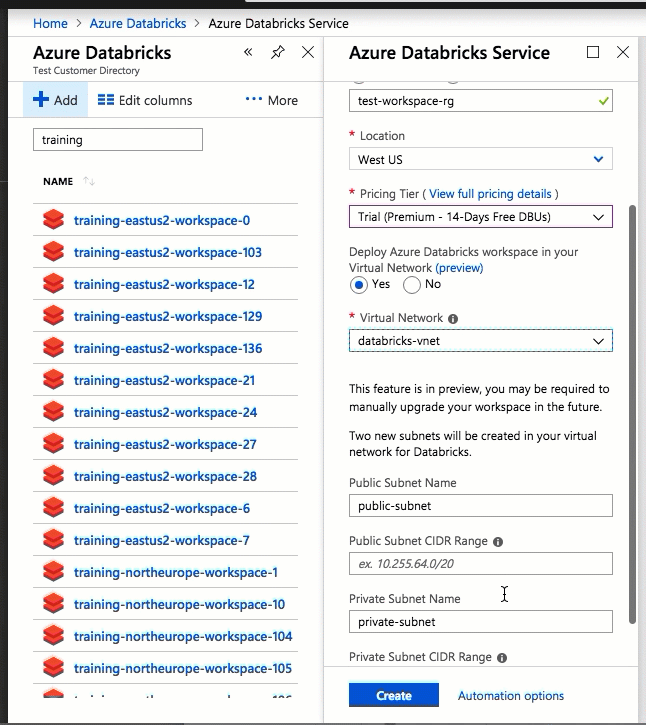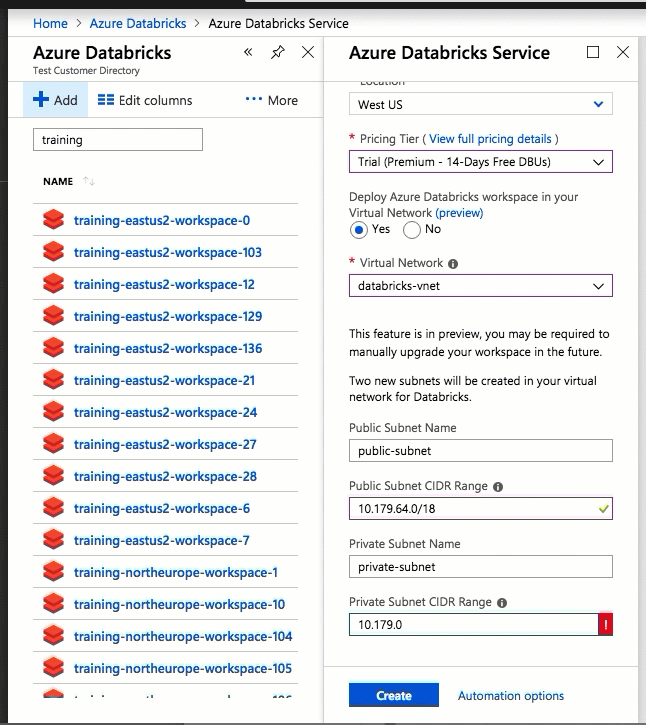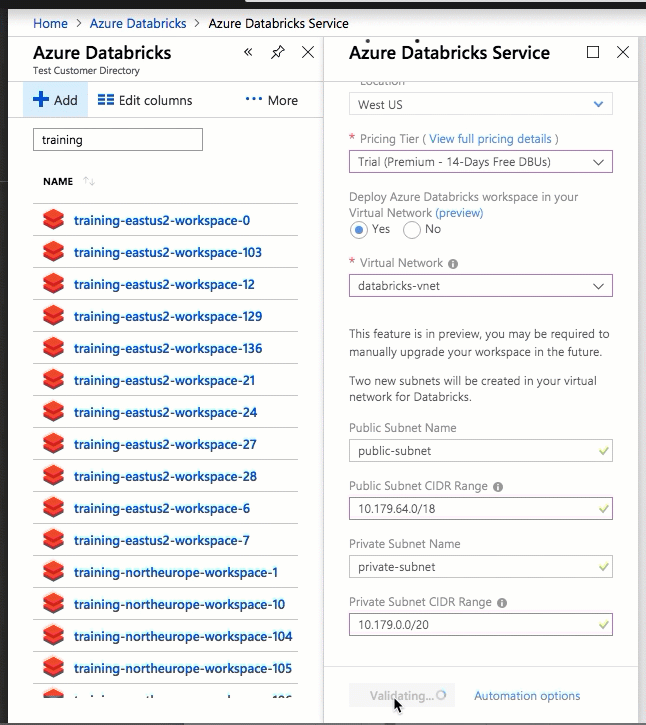
使用 Azure 门户 UI 进行配置非常快捷:在创建工作区时,只需选择“在虚拟网络中部署 Azure Databricks 工作区”,然后选择虚拟网络,并提供两个子网的 CIDR 范围。 Azure Databricks 使用您提供的 CIDR 范围内的两个新子网和网络安全组更新虚拟网络,允许入站和出站子网流量,并将工作区实施到更新的虚拟网络中。
如果希望自行配置用于 VNet 注入的虚拟网络(例如,你想要使用现有子网、使用现有网络安全组,或者创建自己的安全规则),则可以使用 Azure Databricks 提供的 ARM 模板(而不是门户 UI)。
注意
此功能以前仅通过注册提供。 它仍处于预览阶段,但现在完全是自助服务。
有关详细信息,请参阅在 Azure 虚拟网络中部署 Azure Databricks(VNet 注入)和将 Azure Databricks 工作区连接到本地网络。
资源库用户界面
2019 年 1 月 2日 - 9 日:版本 2.88
最初在 2018 年 11 月发布并随后很快还原的库 UI 改进功能已经重新发布。 这些更新使你可以更轻松地上传、安装和管理用于 Azure Databricks 群集的库。
Azure Databricks UI 现在支持工作区库和群集安装的库。 工作区组件位于工作区中,可安装在一个或多个集群中。 群集安装的库是只存在于其安装到的群集的上下文中的库。 此外:
- 现在可以从上传到对象存储的文件创建库。
- 现在可以从库详细信息页和群集的“库”选项卡中安装和卸载库。
- 现在,使用 API 安装的库会在群集的“库”选项卡中显示。
有关详细信息,请参阅 “安装库”。
群集事件
2019 年 1 月 2日 - 9 日:版本 2.88
已添加了新的群集事件以反映 Spark 驱动程序状态。 有关详细信息,请参阅群集 API。
使用 Azure DevOps Services 控制笔记本版本
2019 年 1 月 2日 - 9 日:版本 2.88
利用 Azure Databricks,现在可以轻松地使用 Azure DevOps Services(以前称为 VSTS)对笔记本进行版本控制。 身份验证是自动完成的,设置过程非常简单,并且你可以像在 GitHub 集成中一样来管理笔记本的修订版。
有关详细信息,请参阅笔记本的 Git 版本控制(旧版)