使用 Microsoft Entra ID(以前称为 Azure Active Directory)凭据直通身份验证(旧版)访问 Azure Data Lake Storage。
重要
本文档已过时,将来可能不会更新。
凭据直通是一种旧式数据治理模型。 Databricks 建议你升级到 Unity Catalog。 Unity Catalog 提供一个集中位置来管理和审核帐户中多个工作区的数据访问,从而简化了数据的安全性和治理。 请参阅什么是 Unity Catalog?。
要提高安全性和治理状况,请联系 Azure Databricks 帐户团队,以在 Azure Databricks 帐户中禁用凭据直通身份验证。
注意
本文包含对术语“列入白名单”的引用,Azure Databricks 不再使用该术语。 在从软件中删除该术语后,我们会将其从本文中删除。
可以使用用于登录 Azure Databricks 的同一 Microsoft Entra ID(以前为 Azure Active Directory)标识,从 Azure Databricks 群集中自动对 ADLS Gen2 进行身份验证。 为群集启用 Azure Data Lake Storage 凭据传递身份验证时,在该群集上运行的命令可以在 Azure Data Lake Storage 中读取和写入数据,无需配置用于访问存储的服务主体凭据。
Azure Data Lake Storage 凭据直通仅受 Azure Data Lake Storage Gen2 支持。 Azure Blob 存储不支持凭据传递。
本文介绍:
- 为标准和高并发群集启用凭据传递。
- 配置凭据传递和初始化 ADLS 帐户中的存储资源。
- 启用凭据传递后,直接访问 ADLS 资源。
- 启用凭据传递后,通过装入点访问 ADLS 资源。
- 使用凭据传递时受支持的功能和限制。
包括笔记本是为了提供在 ADLS Gen2 存储帐户中使用凭据直通的示例。
要求
高级计划。 有关将标准计划升级到高级计划的详细信息,请参阅升级或降级 Azure Databricks 工作区。
Azure Data Lake Storage Gen2 存储帐户。 Azure Data Lake Storage Gen2 存储帐户必须使用分层命名空间才能与 Azure Data Lake Storage 凭据直通身份验证配合使用。 请参阅创建存储帐户,了解有关创建新 ADLS Gen2 帐户的说明,包括如何启用分层命名空间。
已正确配置的 Azure Data Lake Storage 的用户权限。 Azure Databricks 管理员需要确保用户拥有正确的角色(例如,存储 Blob 数据参与者)来读取和写入存储在 Azure Data Lake Storage 中的数据。 请参阅使用 Azure 门户分配用于访问 Blob 和队列数据的 Azure 角色。
了解为直通启用的工作区中工作区管理员的权限,并查看现有的工作区管理员分配。 工作区管理员可以管理对工作区的操作,包括添加用户和服务主体、创建群集以及将其他用户委派为工作区管理员。 工作区管理任务(例如管理作业所有权和查看笔记本)可能会提供对 Azure Data Lake Storage 中注册的数据的间接访问权限。 工作区管理员是一个特权角色,应该谨慎分配。
你不能使用配置了 ADLS 凭据的群集,例如,使用凭据传递的服务主体凭据。
重要
如果你位于防火墙后面,但该防火墙尚未配置为允许将流量发往 Microsoft Entra ID,那么你不能使用 Microsoft Entra ID 凭据向 Azure Data Lake Storage 进行身份验证。 默认情况下,Azure 防火墙阻止 Active Directory 访问。 若要允许访问,请配置 AzureActiveDirectory 服务标记。 可以在 Azure IP 范围和服务标记 JSON 文件中的 AzureActiveDirectory 标记下找到网络虚拟设备的等效信息。 有关详细信息,请参阅 Azure 防火墙服务标记和 Azure 中国云的 Azure IP 地址。
日志记录建议
可以在 Azure 存储诊断日志中记录传递到 ADLS 存储的标识。 通过记录标识,可以将 ADLS 请求绑定到 Azure Databricks 群集中的单个用户。 在存储帐户上启用诊断日志记录功能以开始接收这些日志:
- Azure Data Lake Storage Gen2:使用 PowerShell 执行
Set-AzStorageServiceLoggingProperty命令进行配置。 指定 2.0 作为版本,因为日志条目格式 2.0 包含请求中的用户主体名称。
为高并发群集启用 Azure Data Lake Storage 凭据直通
高并发性群集可由多个用户共享。 它们仅支持启用 Azure Data Lake Storage 凭据传递的 Python 和 SQL。
重要
为高并发群集启用 Azure Data Lake Storage 凭据传递会阻止群集上的所有端口(端口 44、53 和 80 除外)。

为标准群集启用 Azure Data Lake Storage 凭据直通
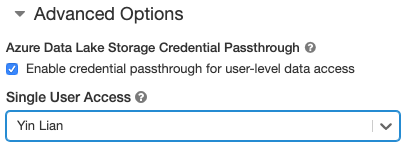
对于启用了凭据直通身份验证的标准群集,只能进行单用户访问。 标准群集支持 Python、SQL、Scala 和 R。在 Databricks Runtime 10.4 LTS 及更高版本上,支持 sparklyr。
你必须在群集创建时分配一个用户,但该群集随时可由具有“可管理”权限的用户编辑,以替换原始用户。
重要
分配给群集的用户必须至少有群集的“可附加到”权限,才能在群集上运行命令。 工作区管理员和群集创建者有“可管理”权限,但不能在群集上运行命令,除非他们是指定的群集用户。
创建容器
容器提供一种方法来整理 Azure 存储帐户中的对象。
使用凭据传递直接访问 Azure Data Lake Storage
配置 Azure Data Lake Storage 凭据传递和创建存储容器后,可以使用 abfss:// 路径直接访问 Azure Data Lake Storage Gen2 中的数据。
Azure Data Lake Storage Gen2
Python
spark.read.format("csv").load("abfss://<container-name>@<storage-account-name>.dfs.core.chinacloudapi.cn/MyData.csv").collect()
R
# SparkR
library(SparkR)
sparkR.session()
collect(read.df("abfss://<container-name>@<storage-account-name>.dfs.core.chinacloudapi.cn/MyData.csv", source = "csv"))
# sparklyr
library(sparklyr)
sc <- spark_connect(method = "databricks")
sc %>% spark_read_csv("abfss://<container-name>@<storage-account-name>.dfs.core.chinacloudapi.cn/MyData.csv") %>% sdf_collect()
- 将
<container-name>替换为 ADLS Gen2 存储帐户中的容器的名称。 - 将
<storage-account-name>替换为 ADLS Gen2 存储帐户名称。
使用凭据直通将 Azure Data Lake Storage 装载到 DBFS
可以将 Azure Data Lake Storage 帐户或其中的文件夹装载到什么是 Databricks 文件系统 (DBFS)?。 此装载是指向一个数据湖存储的指针,因此数据永远不会在本地同步。
使用启用了 Azure data Lake Storage 凭据直通身份验证的群集装载数据时,对装入点的任何读取或写入操作都会使用 Microsoft Entra ID 凭据。 此装入点对其他用户可见,但只有以下用户具有读取和写入访问权限:
- 有权访问基础 Azure Data Lake Storage 存储帐户
- 正在使用已启用 Azure Data Lake Storage 凭据直通身份验证的群集的用户
Azure Data Lake Storage Gen2
若要装载 Azure Data Lake Storage Gen2 文件系统或其内部文件夹,请使用以下命令:
Python
configs = {
"fs.azure.account.auth.type": "CustomAccessToken",
"fs.azure.account.custom.token.provider.class": spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
}
# Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.chinacloudapi.cn/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
Scala
val configs = Map(
"fs.azure.account.auth.type" -> "CustomAccessToken",
"fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName")
)
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://<container-name>@<storage-account-name>.dfs.core.chinacloudapi.cn/",
mountPoint = "/mnt/<mount-name>",
extraConfigs = configs)
- 将
<container-name>替换为 ADLS Gen2 存储帐户中的容器的名称。 - 将
<storage-account-name>替换为 ADLS Gen2 存储帐户名称。 - 将
<mount-name>替换为 DBFS 中的预期装入点的名称。
警告
不要提供存储帐户访问密钥或服务主体凭据来向装入点进行身份验证。 那样会使得其他用户可以使用这些凭据访问文件系统。 Azure Data Lake Storage 凭据直通身份验证的目的是让你不必使用这些凭据,以及确保只有有权访问基础 Azure Data Lake Storage 帐户的用户才能访问文件系统。
安全性
与其他用户共享 Azure Data Lake Storage 凭据直通身份验证群集是安全的。 你和其他用户彼此独立,无法读取或使用彼此的凭据。
支持的功能
| 功能 | 最低 Databricks Runtime 版本 | 说明 |
|---|---|---|
| Python 和 SQL | 5.5 | |
%run |
5.5 | |
| DBFS | 5.5 | 仅当 DBFS 路径解析为 Azure Data Lake Storage Gen2 中的位置时,才会传递凭据。 对于会解析为其他存储系统的 DBFS 路径,请使用另一方法来指定凭据。 |
| Azure Data Lake Storage Gen2 | 5.5 | |
| 增量缓存 | 5.5 | |
| PySpark ML API | 5.5 | 不支持以下 ML 类: * org/apache/spark/ml/classification/RandomForestClassifier* org/apache/spark/ml/clustering/BisectingKMeans* org/apache/spark/ml/clustering/GaussianMixture* org/spark/ml/clustering/KMeans* org/spark/ml/clustering/LDA* org/spark/ml/evaluation/ClusteringEvaluator* org/spark/ml/feature/HashingTF* org/spark/ml/feature/OneHotEncoder* org/spark/ml/feature/StopWordsRemover* org/spark/ml/feature/VectorIndexer* org/spark/ml/feature/VectorSizeHint* org/spark/ml/regression/IsotonicRegression* org/spark/ml/regression/RandomForestRegressor* org/spark/ml/util/DatasetUtils |
| 广播变量 | 5.5 | 在 PySpark 中,可以构造的 Python UDF 的大小存在限制,因为大型 UDF 是作为广播变量发送的。 |
| 笔记本范围的库 | 5.5 | |
| Scala | 5.5 | |
| SparkR | 6.0 | |
| sparklyr | 10.1 | |
| 从另一个笔记本中运行 Databricks 笔记本 | 6.1 | |
| PySpark ML API | 6.1 | 所有 PySpark ML 类都受支持。 |
| 群集指标 | 6.1 | |
| Databricks Connect | 7.3 | 标准群集支持直通身份验证。 |
限制
Azure Data Lake Storage 凭据直通身份验证不支持以下功能:
%fs(请改用等效的 dbutils.fs 命令)。- Databricks 工作流。
- Databricks REST API 参考。
- Unity Catalog。
- 表访问控制。 Azure Data Lake Storage 凭据传递所授予的权限可用于绕过表 ACL 的细化权限,而表 ACL 的额外限制会限制你通过凭据传递获得的某些权益。 具体而言:
- 如果你的 Microsoft Entra ID 权限允许你访问特定表所基于的数据文件,那么你可以通过 RDD API 获取对该表的完全权限(无论通过表 ACL 对其施加的限制如何)。
- 只有在使用数据帧 API 时,才会受到表 ACL 权限的约束。 如果你尝试直接通过数据帧 API 读取文件,则即使你可以直接通过 RDD API 读取那些文件,也会看到警告,指出你在任何文件上都没有
SELECT权限。 - 你将无法从 Azure Data Lake Storage 以外的文件系统所支持的表进行读取,即使你具有读取表的表 ACL 权限。
- SparkContext (
sc) 和 SparkSession (spark) 对象上的以下方法:已弃用的方法。
允许非管理员用户调用 Scala 代码的方法,例如
addFile()和addJar()。访问 Azure Data Lake Storage Gen2 以外的文件系统的任何方法(若要访问启用了 Azure Data Lake Storage 凭据直通身份验证的群集上的其他文件系统,请使用另一方法来指定凭据,并参阅故障排除下关于受信任文件系统的部分)。
旧的 Hadoop API(
hadoopFile()和hadoopRDD())。流式处理 API,因为直通凭据会在流仍在运行时过期。
- DBFS 装载 (
/dbfs) 仅在 Databricks Runtime 7.3 LTS 及更高版本中可用。 此路径不支持配置了凭据直通身份验证的装入点。 - Azure 数据工厂。
- 高并发性群集上的 MLflow。
- 高并发性群集上的 azureml-sdk Python 包。
- 不能使用 Microsoft Entra ID 令牌生存期策略来延长 Microsoft Entra ID 传递令牌的生存期。 因此,如果向群集发送耗时超过一小时的命令,并在 1 小时标记期过后访问 Azure Data Lake Storage 资源,该命令会失败。
- 使用 Hive 2.3 和更高版本时,无法在启用了凭据直通的群集上添加分区。 有关详细信息,请参阅相关的故障排除部分。
示例笔记本
以下笔记本演示 Azure Data Lake Storage Gen2 的 Azure Data Lake Storage 凭据直通身份验证。
Azure Data Lake Storage Gen2 直通笔记本
故障排除
py4j.security.Py4JSecurityException:… 未加入允许列表
如果访问的方法未被 Azure Databricks 明确标记为对 Azure Data Lake Storage 凭据直通身份验证群集安全,则将引发此异常。 在大多数情况下,这意味着该方法可能会允许 Azure Data Lake Storage 凭据直通身份验证群集上的用户访问其他用户的凭据。
org.apache.spark.api.python.PythonSecurityException:路径… 使用不受信任的文件系统
如果你尝试访问了一个文件系统,而 Azure Data Lake Storage 凭据直通身份验证群集不知道该文件系统是否安全,则会引发此异常。 使用不受信任的文件系统可能会使 Azure Data Lake Storage 凭据直通身份验证群集上的用户能够访问其他用户的凭据,因此我们禁用了我们无法确信其会被用户安全使用的所有文件系统。
若要在 Azure Data Lake Storage 凭据直通身份验证群集上配置一组受信任的文件系统,请将该群集上的 Spark conf 键 spark.databricks.pyspark.trustedFilesystems 设置为以逗号分隔的类名称列表,这些名称是 org.apache.hadoop.fs.FileSystem 的受信任实现。
在启用了凭据传递的情况下添加分区失败并显示 AzureCredentialNotFoundException
使用 Hive 2.3-3.1 时,如果你尝试在启用了凭据直通的群集上添加分区,则会发生以下异常:
org.apache.spark.sql.AnalysisException: org.apache.hadoop.hive.ql.metadata.HiveException: MetaException(message:com.databricks.backend.daemon.data.client.adl.AzureCredentialNotFoundException: Could not find ADLS Gen2 Token
若要解决此问题,请在未启用凭据直通的群集上添加分区。