本文介绍如何将数据流式传输到事件中心,并使用 Azure 流分析对其进行处理。 本文将引导你完成以下步骤:
- 创建事件中心命名空间。
- 创建一个 Kafka 客户端,用于将消息发送到事件中心。
- 创建一个流分析作业,用于将数据从事件中心复制到 Azure Blob 存储。
使用事件中心公开的 Kafka 终结点时,无需更改协议客户端或运行自己的群集。 Azure 事件中心支持 Apache Kafka 版本 1.0 及更高版本。
先决条件
若要完成本快速入门,请确保符合以下先决条件:
- 一份 Azure 订阅。 如果您还没有,请在开始之前创建一个试用订阅。
- Java 开发工具包 (JDK) 1.7+。
- 下载并安装 Maven 二进制存档。
- Git
- 一个 Azure 存储帐户。 如果没有,请在继续下一步之前 创建一个 。 本演练中的流分析作业将输出数据存储在 Azure Blob 存储中。
创建事件中心命名空间
当你创建事件中心命名空间时,系统会自动为该命名空间启用 Kafka 终结点。 可以从使用 Kafka 协议的应用程序,将事件流式传输到事件中心。 按照使用 Azure 门户创建事件中心中的分步说明创建事件中心命名空间。
注释
基本层不支持适用于 Kafka 的事件中心。
在事件中心使用 Kafka 发送消息
将 适用于 Kafka 的 Azure 事件中心存储库 克隆到计算机。
导航到文件夹:
azure-event-hubs-for-kafka/quickstart/java/producer.在
src/main/resources/producer.config中更新生产者的配置详细信息。 指定事件中心命名空间的名称和连接字符串。bootstrap.servers={EVENT HUB NAMESPACE}.servicebus.chinacloudapi.cn:9093 security.protocol=SASL_SSL sasl.mechanism=PLAIN sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="$ConnectionString" password="{CONNECTION STRING for EVENT HUB NAMESPACE}";导航到
azure-event-hubs-for-kafka/quickstart/java/producer/src/main/java/,然后在您选择的编辑器中打开 TestDataReporter.java 文件。为以下代码行添加注释:
//final ProducerRecord<Long, String> record = new ProducerRecord<Long, String>(TOPIC, time, "Test Data " + i);添加以下代码行来代替注释的代码:
final ProducerRecord<Long, String> record = new ProducerRecord<Long, String>(TOPIC, time, "{ \"eventData\": \"Test Data " + i + "\" }");此代码以 JSON 格式发送事件数据。 为流分析作业配置输入时,请将 JSON 指定为输入数据的格式。
运行生产者 并将数据流传输至事件中心。 在 Windows 计算机上,在使用 Node.js 命令提示符时,请在运行这些命令之前切换到
azure-event-hubs-for-kafka/quickstart/java/producer文件夹。mvn clean package mvn exec:java -Dexec.mainClass="TestProducer"
验证事件中心是否接收数据
在“实体”下选择事件中心。 确认看到名为 测试的事件中心。
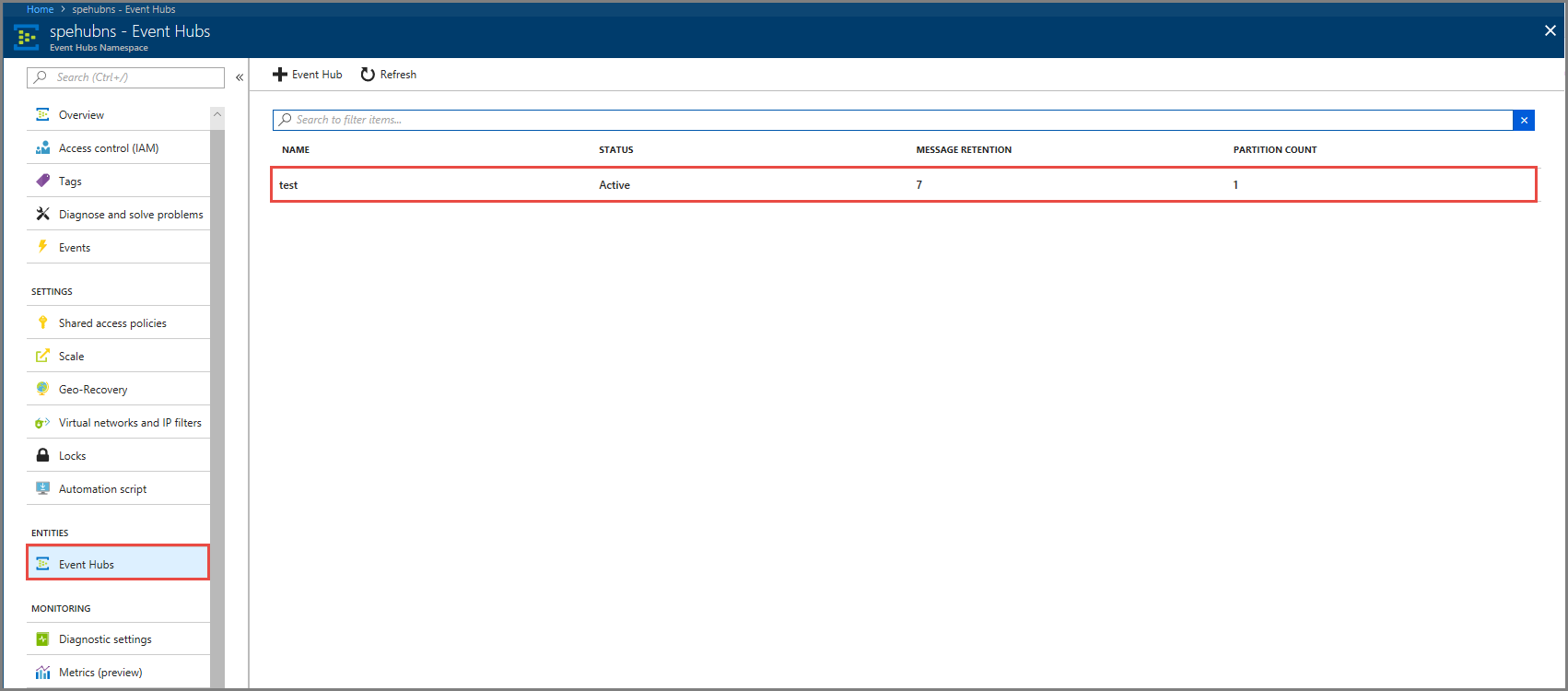
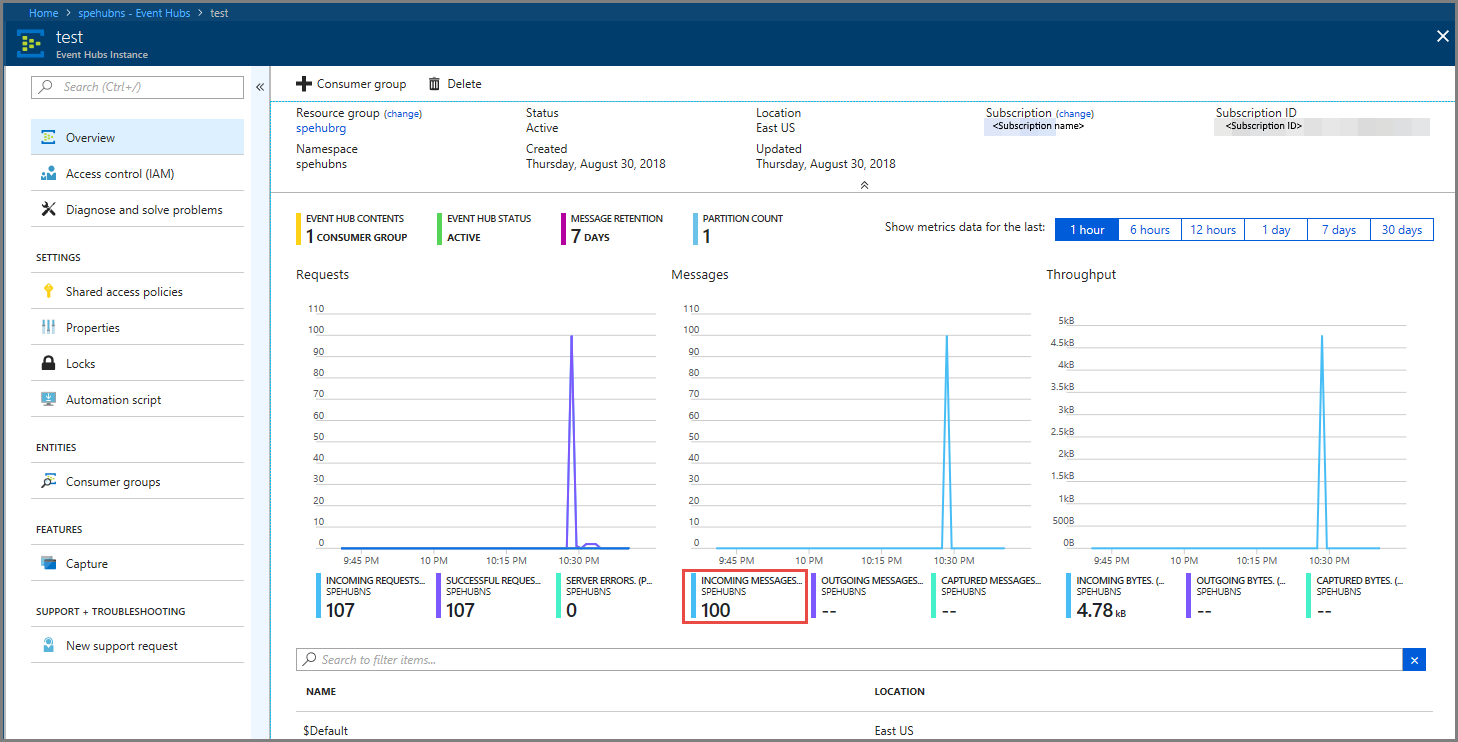
确认看到消息传入事件中心。
使用流分析作业处理事件数据
在本部分中,创建 Azure 流分析作业。 Kafka 客户端将事件发送到事件中心。 创建一个流分析作业,该作业将事件数据作为输入和输出到 Azure Blob 存储。 如果没有 Azure 存储帐户, 请创建一个。
流分析作业中的查询经过数据,而不执行任何分析。 可以创建一个查询,该查询转换输入数据,生成不同格式的或带有见解的输出数据。
创建流分析作业
- 在 Azure 门户中选择“+ 创建资源”。
- 在 Azure 市场菜单中选择“分析”,然后选择“流分析作业”。
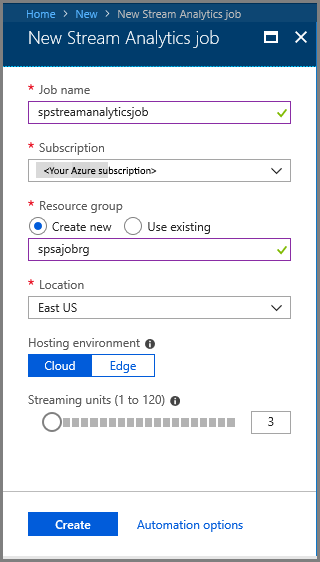
- 在 “新建流分析 ”页上,执行以下作:
输入作业的名称。
选择订阅。
为资源组选择“新建”,然后输入名称。 还可以 使用现有 资源组。
选择职位的地点。
选择“ 创建 ”以创建作业。
配置作业输入
在通知消息中,选择“转到资源”以查看“流分析作业”页。
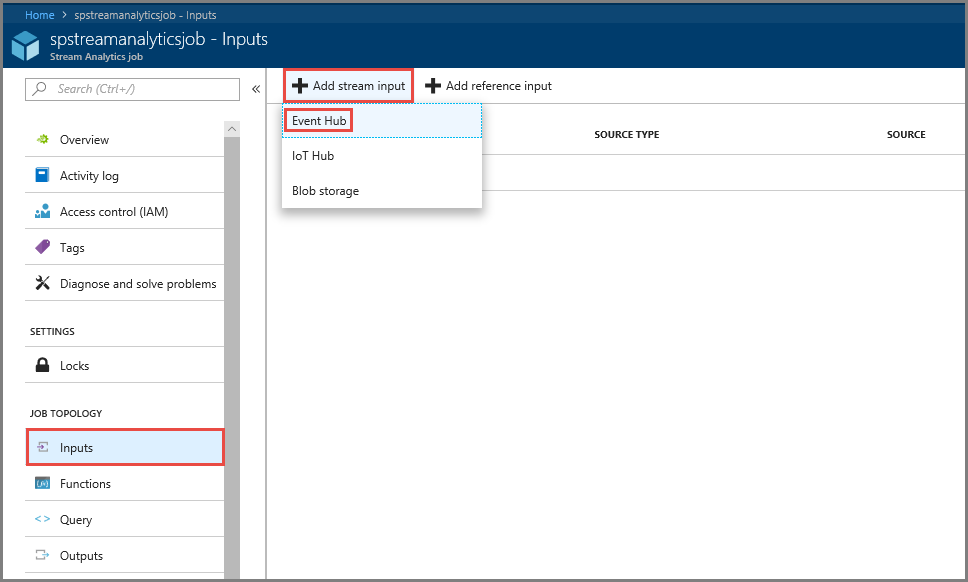
在左侧菜单中的“作业拓扑”部分选择“输入”。
选择 “添加流输入”,然后选择 “事件中心”。
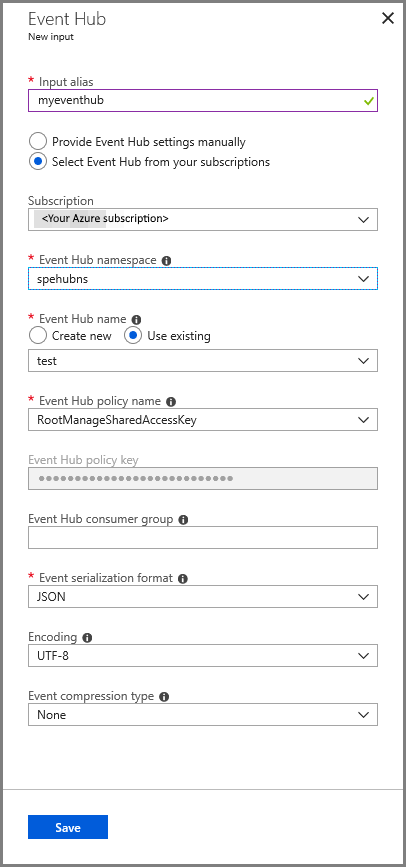
在 “事件中心输入 配置”页上,执行以下作:
指定输入的 别名 。
选择 Azure 订阅。
选择之前创建的事件中心命名空间。
选择事件中心的测试。
选择“保存”。
配置作业输出
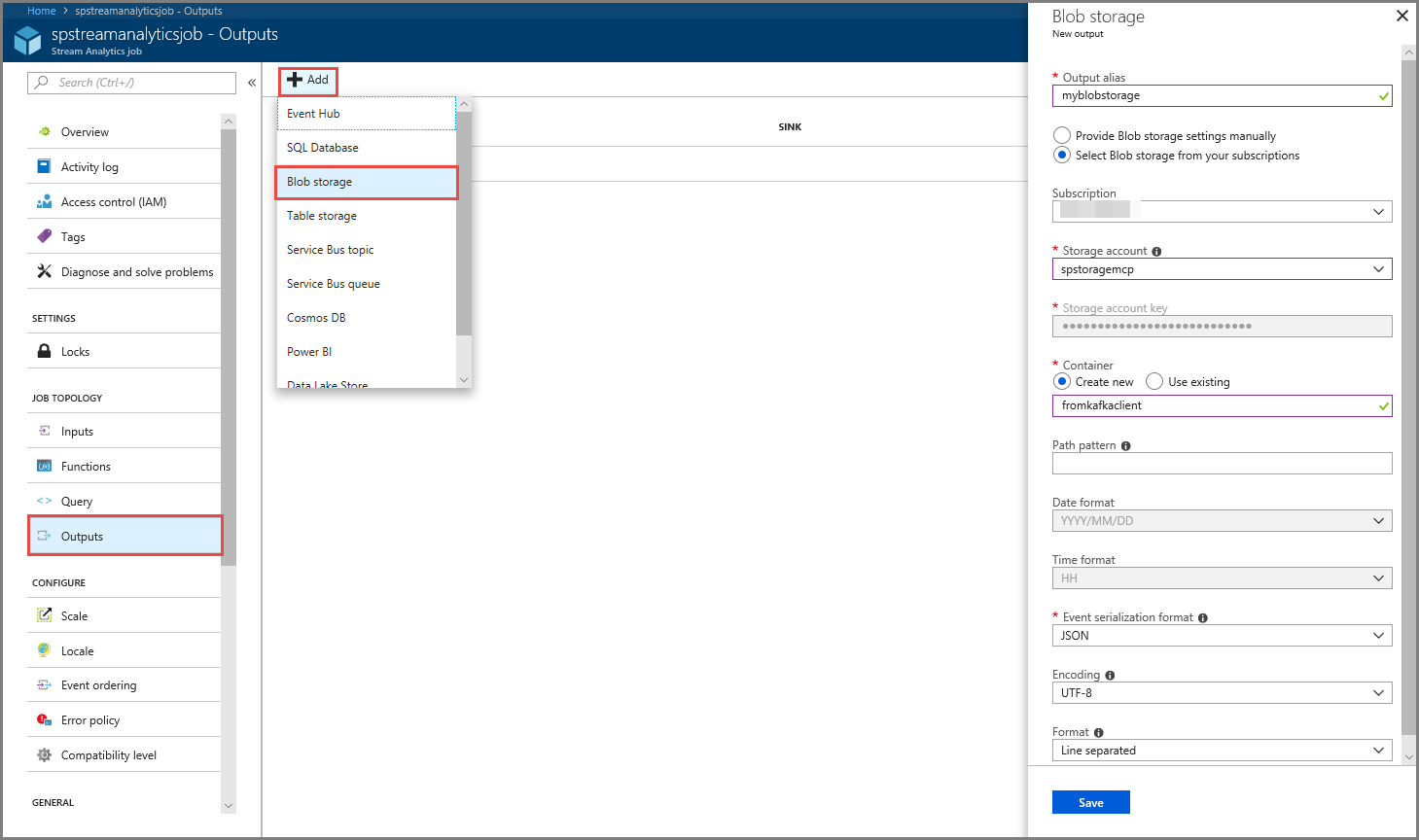
- 在菜单上的“作业拓扑”部分选择“输出”。
- 选择工具栏上的“+ 添加”,并选择“Blob 存储”
- 在“Blob 存储输出设置”页上,执行以下作:
指定输出的 别名 。
选择 Azure 订阅。
选择 Azure 存储帐户。
输入存储流分析查询输出数据的 容器的名称 。
选择“保存”。
定义查询
设置流分析作业以读取传入数据流后,下一步是创建一个实时分析数据的转换。 使用 流分析查询语言定义转换查询。 在本演练中,定义经过数据而不执行任何转换的查询。
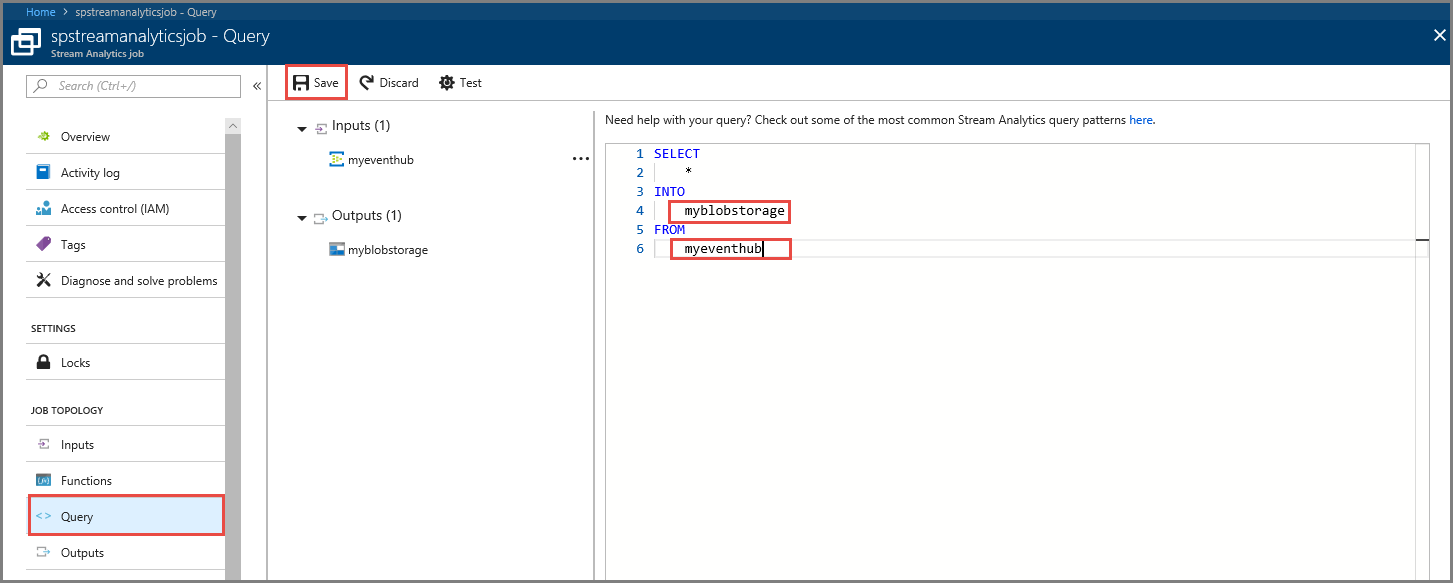
选择 查询。
在查询窗口中,将
[YourOutputAlias]替换为之前创建的输出别名。将
[YourInputAlias]替换为之前创建的输入别名。在工具栏上选择“保存”。
运行流分析作业
在左侧菜单中选择 “概述 ”。
选择开始。
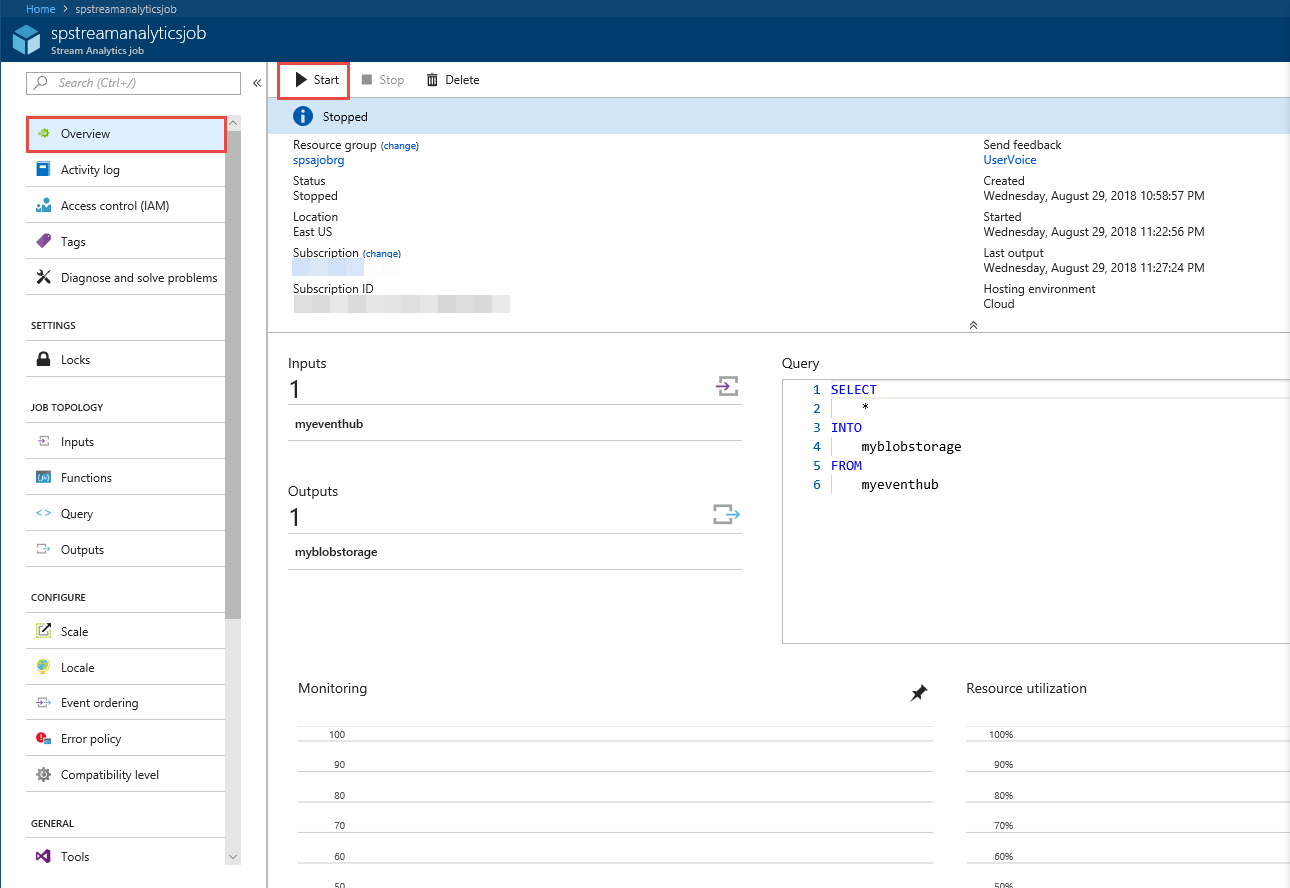
在 “开始作业 ”页上,选择“ 开始”。
等待作业的状态从 “开始” 更改为 “正在运行”。

测试方案
再次运行 Kafka 生成者 以将事件发送到事件中心。
mvn exec:java -Dexec.mainClass="TestProducer"确认看到在“Azure Blob 存储”中生成“输出数据”。 容器中看到一个 JSON 文件,其中包含 100 行,类似于以下示例行:
{"eventData":"Test Data 0","EventProcessedUtcTime":"2018-08-30T03:27:23.1592910Z","PartitionId":0,"EventEnqueuedUtcTime":"2018-08-30T03:27:22.9220000Z"} {"eventData":"Test Data 1","EventProcessedUtcTime":"2018-08-30T03:27:23.3936511Z","PartitionId":0,"EventEnqueuedUtcTime":"2018-08-30T03:27:22.9220000Z"} {"eventData":"Test Data 2","EventProcessedUtcTime":"2018-08-30T03:27:23.3936511Z","PartitionId":0,"EventEnqueuedUtcTime":"2018-08-30T03:27:22.9220000Z"}Azure 流分析作业从事件中心接收输入数据,并将其存储在此方案中的 Azure Blob 存储中。
后续步骤
本文介绍了如何在不更改协议客户端或运行自己的群集的情况下,将事件流式传输到事件中心。 若要了解有关 Apache Kafka 事件中心的详细信息,请参阅 适用于 Azure 事件中心的 Apache Kafka 开发人员指南。