本文介绍在与 Azure HDInsight 群集交互时出现的问题的故障排除步骤和可能的解决方案。
场景:OutOfMemoryError 或无响应的 Apache Ambari 指标收集器
背景
Ambari 指标收集器是一个守护程序,该守护程序在群集中的特定主机上运行,并从已注册的发布者、监视器和接收器接收数据。
问题
- 你可能会在 Ambari UI 中收到严重的“指标收集器进程”警报,并显示以下类似消息。
Connection failed: timed out to <headnode fqdn>:6188 - Ambari 指标收集器可能会频繁地在头节点中重启
- Ambari UI 或 Grafana 中的某些 Apache Ambari 指标可能会不显示。 例如,“NAMENODE”显示“已启动”状态,而不是“活动/待机”状态 。 “无可用数据”消息可能出现在 Ambari 仪表板中
原因
以下情形可能会导致这些问题:
频繁发生内存不足异常
检查 Apache Ambari 指标收集器日志 /var/log/ambari-metrics-collector/ambari-metrics-collector.log*。
19:59:45,457 ERROR [325874797@qtp-2095573052-22] log:87 - handle failed
java.lang.OutOfMemoryError: Java heap space
19:59:45,457 FATAL [MdsLoggerSenderThread] YarnUncaughtExceptionHandler:51 - Thread Thread[MdsLoggerSenderThread,5,main] threw an Error. Shutting down now...
java.lang.OutOfMemoryError: Java heap space
垃圾回收繁忙
Apache Ambari 指标收集器未侦听 hbase-ams 日志
/var/log/ambari-metrics-collector/hbase-ams-master-hn*.log中的 61882021-04-13 05:57:37,546 INFO [timeline] timeline.HadoopTimelineMetricsSink: No live collector to send metrics to. Metrics to be sent will be discarded. This message will be skipped for the next 20 times.获取 Apache Ambari 指标收集器
pid并检查 GC 性能ps -fu ams | grep 'org.apache.ambari.metrics.AMSApplicationServer'使用
jstat -gcutil <pid> 1000 100检查垃圾回收状态。 如果看到 FGCT 在短时间内大幅增加,则表明 Apache Ambari 指标收集器正忙于处理完全 GC,无法处理其他请求。
解决方法
若要避免这些问题,请考虑使用下列选项之一:
从“Ambari”>“Ambari 指标收集器”>“配置”>“高级 ams-env”>“指标收集器堆大小”增加 Apache Ambari 指标收集器的堆内存

请按照以下步骤清除 Ambari 指标服务 (AMS) 数据。
注意
清除 AMS 数据会删除所有可用的 AMS 历史数据。 如果需要历史记录,这可能不是最佳选择。
- 登录到 Ambari 门户
- 将 AMS 设置为维护状态
- 从 Ambari 停止 AMS
- 从 AMS 配置屏幕 1 中识别以下内容。
hbase.rootdir(默认值为file:///mnt/data/ambari-metrics-collector/hbase)2.hbase.tmp.dir(默认值为/var/lib/ambari-metrics-collector/hbase-tmp) - 通过 SSH 连接到 Apache Ambari 指标收集器所在的头节点。 作为超级用户:
- 通过备份并删除
'hbase.tmp.dir'/zookeeper的内容来删除 AMS Zookeeper 数据 - 从
<hbase.tmp.dir>/phoenix-spool文件夹中删除任何 Phoenix 假脱机文件 - (完全可以在开始时跳过此步骤,并尝试重启 AMS 以查看问题是否已得到解决。如果 AMS 仍无法启动,请尝试执行此步骤)AWS 数据将会存储在上面所识别的
hbase.rootdir中。 使用常规 OS 命令来备份并删除文件。 示例:tar czf /mnt/backupof-ambari-metrics-collector-hbase-$(date +%Y%m%d-%H%M%S).tar.gz /mnt/data/ambari-metrics-collector/hbase - 使用 Ambari 重启 AMS。
对于 Kafka 群集,如果上述解决方案没有帮助,请考虑以下解决方案。
Ambari 指标服务需要处理大量 kafka 指标,因此最好仅启用允许列表中的指标。 转到 Ambari>AmbariMetrics>CONFIGS>Advancedams-env,将以下属性设置为 true。 完成此修改后,需要根据需要在 Ambari UI 中重启受影响的服务。

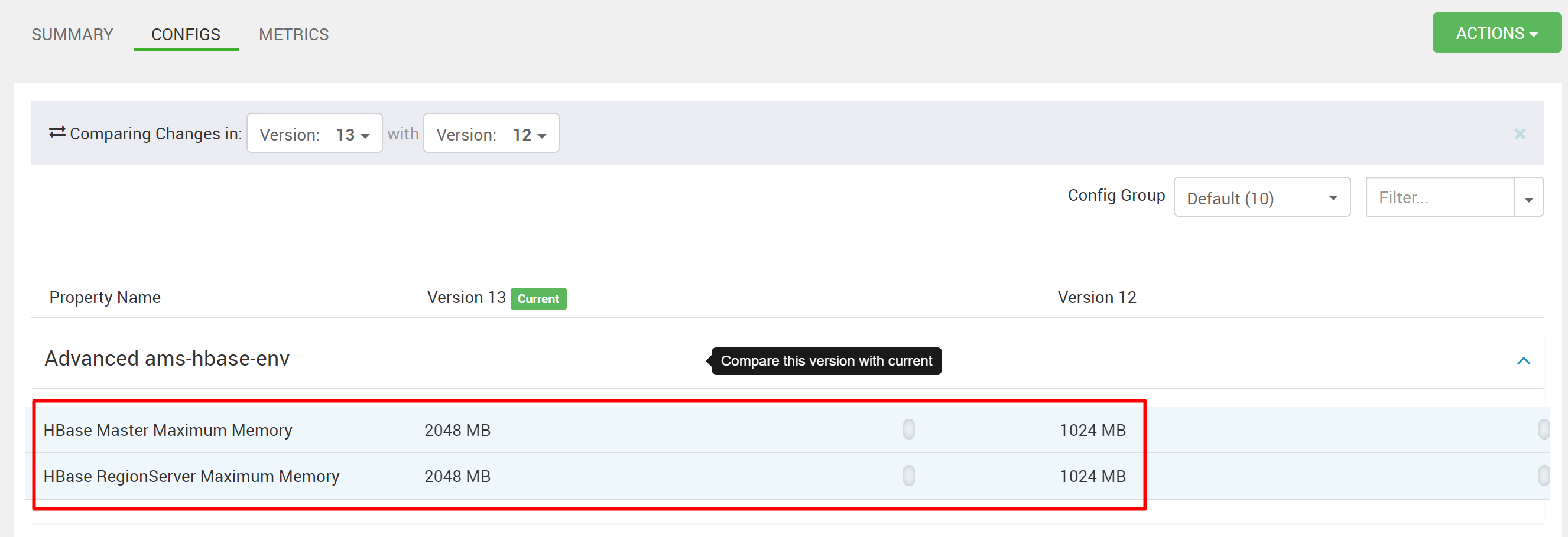
处理具有有限内存的独立 HBase 的大量指标会影响 HBase 响应时间。 因此,指标将不可用。 如果 Kafka 群集具有许多主题,但仍生成大量允许的指标,请增加 Ambari 指标服务中 HMaster 和 RegionServer 的堆内存。 转到 Ambari>AmbariMetrics>CONFIGS>Advanced hbase-env>HBaseMaster Maximum Memory 和 HBase RegionServer Maximum Memory,并增加值。 在 Ambari UI 中重启所需的服务。
后续步骤
如果你的问题未在本文中列出,或者无法解决问题,请访问以下渠道之一获取更多支持:
- 如果需要更多帮助,可以从 Azure 门户提交支持请求。 从菜单栏中选择“支持” ,或打开“帮助 + 支持” 中心。