- 概述
- Azure 门户
- Azure 数据工厂
- Azure CLI
- Azure PowerShell
- REST API (cURL)
- Azure 资源管理器 模板
本教程介绍如何使用 Azure 数据工厂在 Azure HDInsight 中按需创建 Apache Hadoop 群集。 然后,在 Azure 数据工厂中使用数据管道运行 Hive 作业并删除群集。 本教程结束时,你将了解如何 operationalize 运行大数据作业,以便按计划完成群集创建、作业运行和群集删除。
本教程涵盖以下任务:
- 创建 Azure 存储帐户
- 了解 Azure 数据工厂活动
- 使用 Azure 门户创建数据工厂
- 创建链接服务
- 创建管道
- 触发管道
- 监视流水线
- 验证输出
如果没有 Azure 订阅,请在开始前创建一个试用版订阅。
先决条件
已安装 PowerShell Az 模块 。
Microsoft Entra 服务主体。 创建服务主体后,请务必使用链接文章中的说明检索 应用程序 ID 和 身份验证密钥 。 本教程稍后需要这些值。 此外,请确保服务主体是订阅或在其中创建群集的资源组的 参与者 角色的成员。 有关检索所需值并分配正确的角色的说明,请参阅 创建Microsoft Entra 服务主体。
创建初步 Azure 对象
在本部分中,将创建用于按需创建的 HDInsight 群集的各种对象。 创建的存储帐户将包含示例 HiveQL 脚本, partitionweblogs.hql用于模拟在群集上运行的示例 Apache Hive 作业。
本部分使用 Azure PowerShell 脚本创建存储帐户,并复制存储帐户中所需的文件。 本部分中的 Azure PowerShell 示例脚本执行以下任务:
- 登录到 Azure。
- 创建 Azure 资源组。
- 创建 Azure 存储帐户。
- 在存储帐户中创建 Blob 容器
- 将示例 HiveQL 脚本(partitionweblogs.hql)复制到 Blob 容器中。 示例脚本已在另一个公共 Blob 容器中提供。 下面的 PowerShell 脚本将这些文件的副本复制到它创建的 Azure 存储帐户中。
创建存储帐户和复制文件
重要
指定由脚本创建的 Azure 资源组和 Azure 存储帐户的名称。 记下脚本输出的资源组名称、存储帐户名称和存储帐户密钥。 在下一部分中需要用到它们。
$resourceGroupName = "<Azure Resource Group Name>"
$storageAccountName = "<Azure Storage Account Name>"
$location = "China East2"
$sourceStorageAccountName = "hditutorialdata"
$sourceContainerName = "adfv2hiveactivity"
$destStorageAccountName = $storageAccountName
$destContainerName = "adfgetstarted" # don't change this value.
####################################
# Connect to Azure
####################################
#region - Connect to Azure subscription
Write-Host "`nConnecting to your Azure subscription ..." -ForegroundColor Green
$sub = Get-AzSubscription -ErrorAction SilentlyContinue
if(-not($sub))
{
Connect-AzAccount -Environment AzureChinaCloud
}
# If you have multiple subscriptions, set the one to use
# Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>"
#endregion
####################################
# Create a resource group, storage, and container
####################################
#region - create Azure resources
Write-Host "`nCreating resource group, storage account and blob container ..." -ForegroundColor Green
New-AzResourceGroup `
-Name $resourceGroupName `
-Location $location
New-AzStorageAccount `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName `
-Kind StorageV2 `
-Location $location `
-SkuName Standard_LRS `
-EnableHttpsTrafficOnly 1
$destStorageAccountKey = (Get-AzStorageAccountKey `
-ResourceGroupName $resourceGroupName `
-Name $destStorageAccountName)[0].Value
$sourceContext = New-AzStorageContext `
-StorageAccountName $sourceStorageAccountName `
-Anonymous
$destContext = New-AzStorageContext `
-StorageAccountName $destStorageAccountName `
-StorageAccountKey $destStorageAccountKey
New-AzStorageContainer `
-Name $destContainerName `
-Context $destContext
#endregion
####################################
# Copy files
####################################
#region - copy files
Write-Host "`nCopying files ..." -ForegroundColor Green
$blobs = Get-AzStorageBlob `
-Context $sourceContext `
-Container $sourceContainerName `
-Blob "hivescripts\hivescript.hql"
$blobs|Start-AzStorageBlobCopy `
-DestContext $destContext `
-DestContainer $destContainerName `
-DestBlob "hivescripts\partitionweblogs.hql"
Write-Host "`nCopied files ..." -ForegroundColor Green
Get-AzStorageBlob `
-Context $destContext `
-Container $destContainerName
#endregion
Write-host "`nYou will use the following values:" -ForegroundColor Green
write-host "`nResource group name: $resourceGroupName"
Write-host "Storage Account Name: $destStorageAccountName"
write-host "Storage Account Key: $destStorageAccountKey"
Write-host "`nScript completed" -ForegroundColor Green
验证存储帐户
- 登录到 Azure 门户。
- 从左侧导航到 “所有服务>常规>资源组”。
- 选择在 PowerShell 脚本中创建的资源组名称。 如果列出的资源组太多,请使用筛选器。
- 在 “概述” 视图中,除非与其他项目共享资源组,否则只会看到列出的一个资源。 该资源是具有前面指定名称的存储帐户。 选择存储帐户名称。
- 选择 “容器 ”磁贴。
- 选择 adfgetstarted 容器。 你会看到名为
hivescripts的文件夹。 - 打开文件夹并确保它包含示例脚本文件 partitionweblogs.hql。
了解 Azure 数据工厂活动
Azure 数据工厂 协调并自动移动和转换数据。 Azure 数据工厂可以实时创建 HDInsight Hadoop 群集来处理输入数据切片,并在处理完成后删除群集。
在 Azure 数据工厂中,数据工厂可以有一个或多个数据管道。 数据管道具有一个或多个活动。 有两种类型的活动:
- 数据移动活动。 使用数据移动活动将数据从源数据存储移动到目标数据存储。
- 数据转换活动。 使用数据转换活动来处理和转换数据。 HDInsight Hive 活动是数据工厂支持的转换活动之一。 您在本教程中会使用 Hive 转换活动。
在本文中,将 Hive 活动配置为创建按需 HDInsight Hadoop 群集。 当活动运行以处理数据时,会发生以下情况:
会自动创建 HDInsight Hadoop 群集,以便实时处理切片。
通过在群集上运行 HiveQL 脚本来处理输入数据。 在本教程中,与 Hive 活动关联的 HiveQL 脚本执行以下作:
- 使用现有表(hivesampletable)创建另一个表 HiveSampleOut。
- 使用原始 hivesampletable 中的特定列填充 HiveSampleOut 表。
处理完成后,HDInsight Hadoop 群集将被删除,并且群集在配置的时间段内处于空闲状态(timeToLive 设置)。 如果在此存活时间的空闲期内,下一个数据切片可供处理,则使用同一集群来处理该切片。
创建数据工厂
登录到 Azure 门户。
在左侧菜单中,导航到
+ Create a resource>“分析>数据工厂”。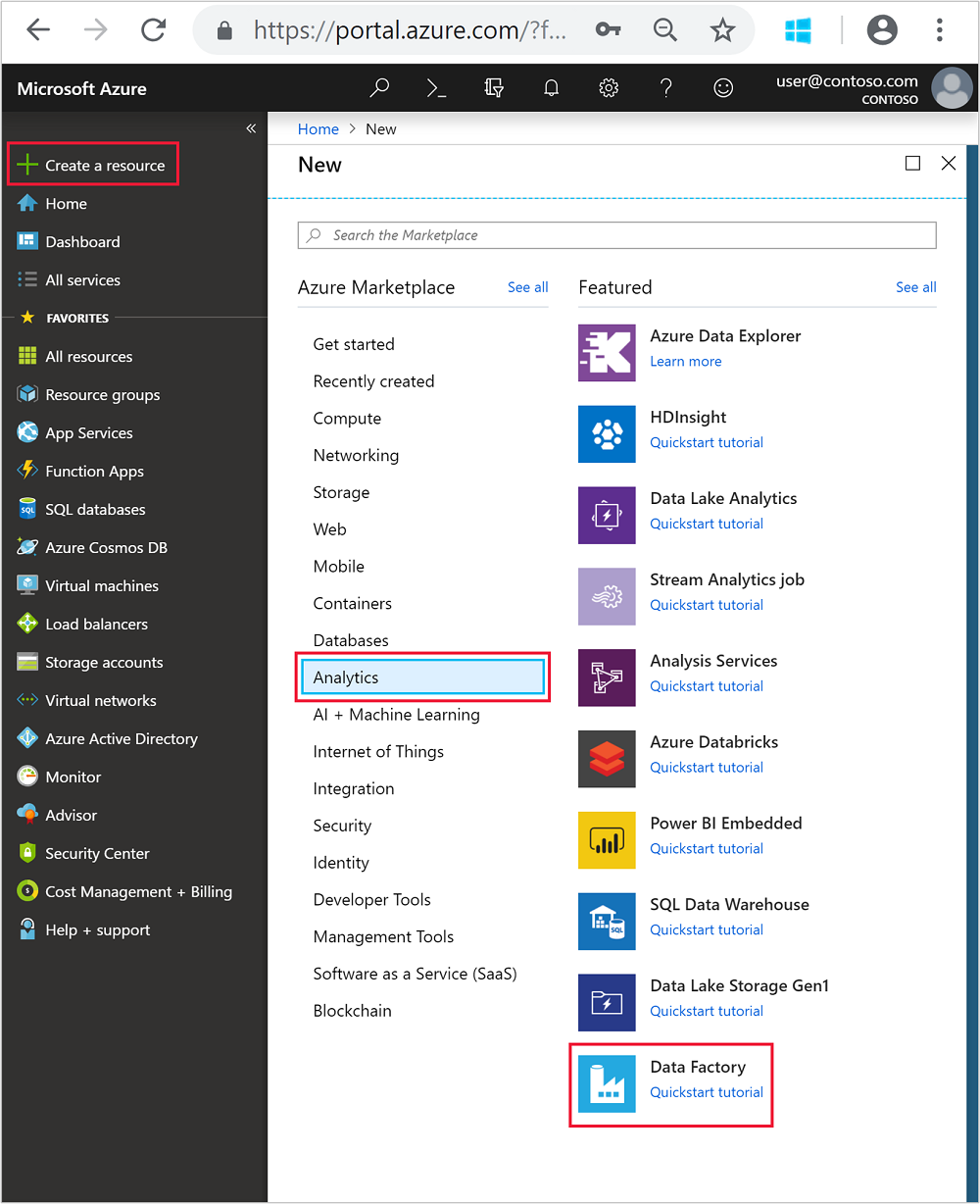
为 “新建数据工厂 ”磁贴输入或选择以下值:
资产 价值 Name 输入数据工厂的名称。 该名称必须全局唯一。 版本 在 V2 处离开。 Subscription 选择 Azure 订阅。 资源组 选择使用 PowerShell 脚本创建的资源组。 位置 该位置会自动设置为之前创建资源组时指定的位置。 在本教程中,位置设置为 中国东部 2。 启用 GIT 取消选中此框。 
选择 创建。 创建数据工厂可能需要 2 到 4 分钟。
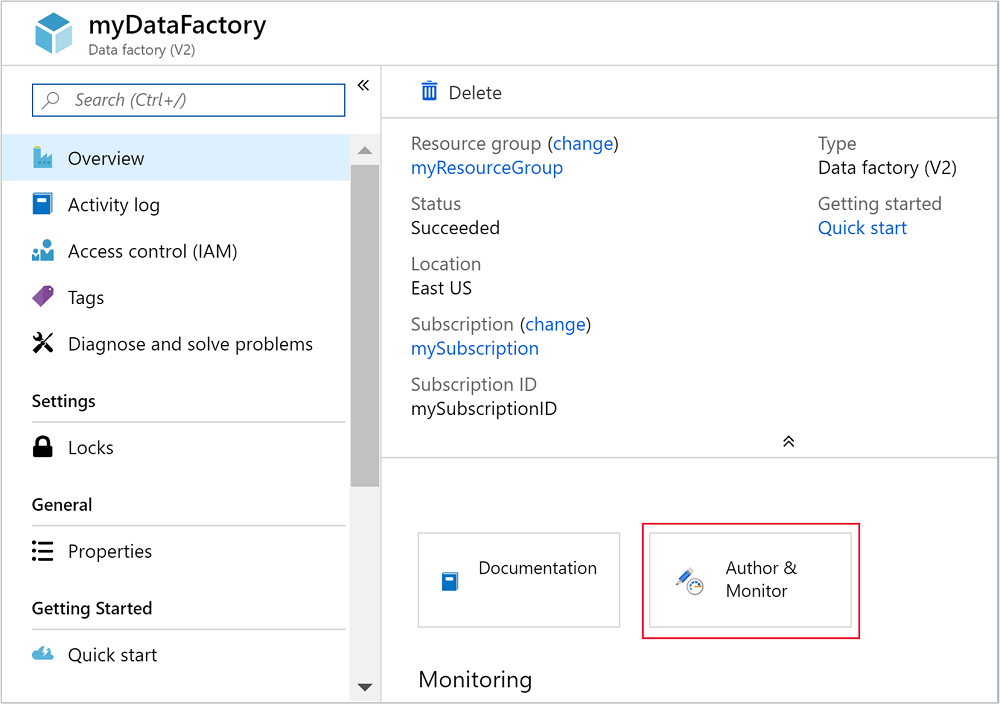
创建数据工厂后,将收到 “部署成功 ”通知,其中包含 “转到资源 ”按钮。 选择 转到资源 以打开数据工厂默认视图。
选择 “创作与监视”以启动 Azure 数据工厂创作与监视门户。
创建链接服务
在本部分中,你将在你的数据工厂中创建两个关联服务。
- 一个用于将 Azure 存储帐户链接到数据工厂的 Azure 存储链接服务。 按需 HDInsight 群集使用此存储。 它还包含群集上运行的 Hive 脚本。
- 一个按需 HDInsight 链接服务。 Azure 数据工厂会自动创建 HDInsight 群集并运行 Hive 脚本。 然后,当群集空闲预配置的时间后,就会删除 HDInsight 群集。
创建 Azure 存储链接服务
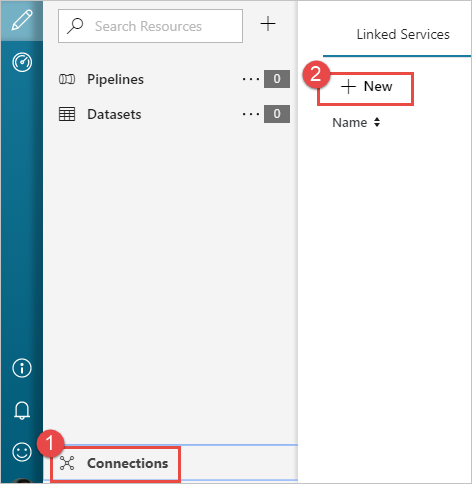
在“ 开始 ”页面的左窗格中,选择“ 作者” 图标。

从窗口左下角选择 “连接 ”,然后选择“ +新建”。
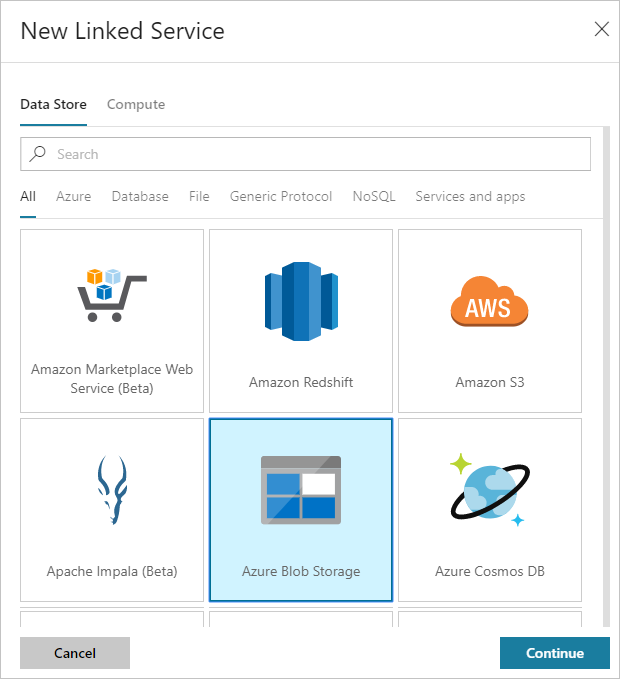
在“ 新建链接服务 ”对话框中,选择 “Azure Blob 存储 ”,然后选择“ 继续”。
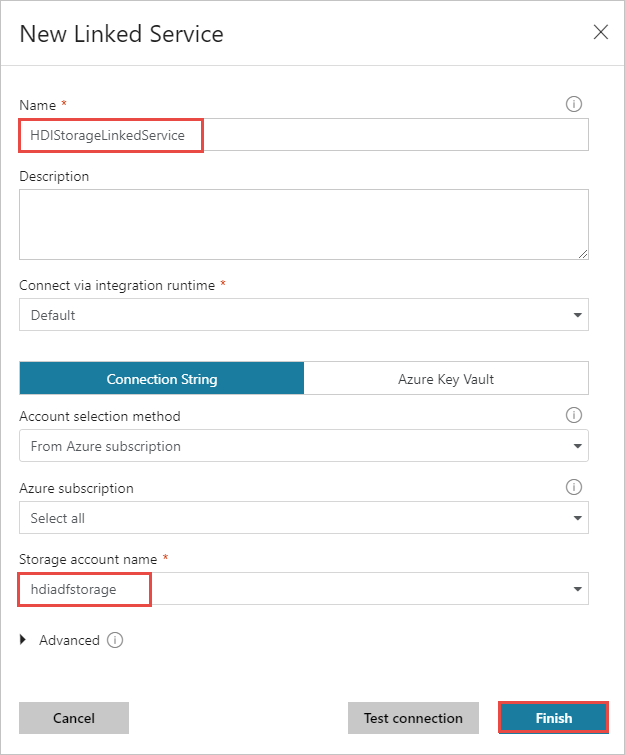
为存储链接服务提供以下值:
资产 价值 Name 输入 HDIStorageLinkedService。Azure 订阅 从下拉列表中选择订阅。 存储帐户名称 选择在 PowerShell 脚本中创建的 Azure 存储帐户。 选择 “测试连接 ”,如果成功,请选择“ 创建”。
创建按需 HDInsight 链接服务
再次选择“+ 新建”按钮,创建另一个链接服务。
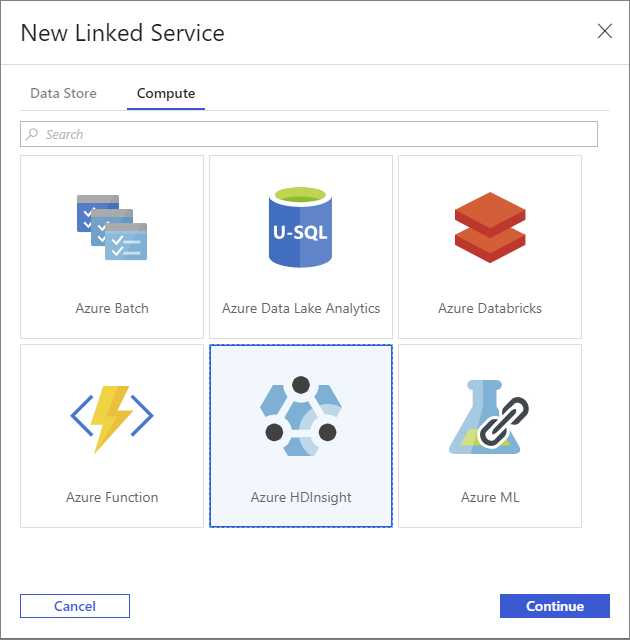
在“ 新建链接服务 ”窗口中,选择“ 计算 ”选项卡。
选择 Azure HDInsight,然后选择“ 继续”。
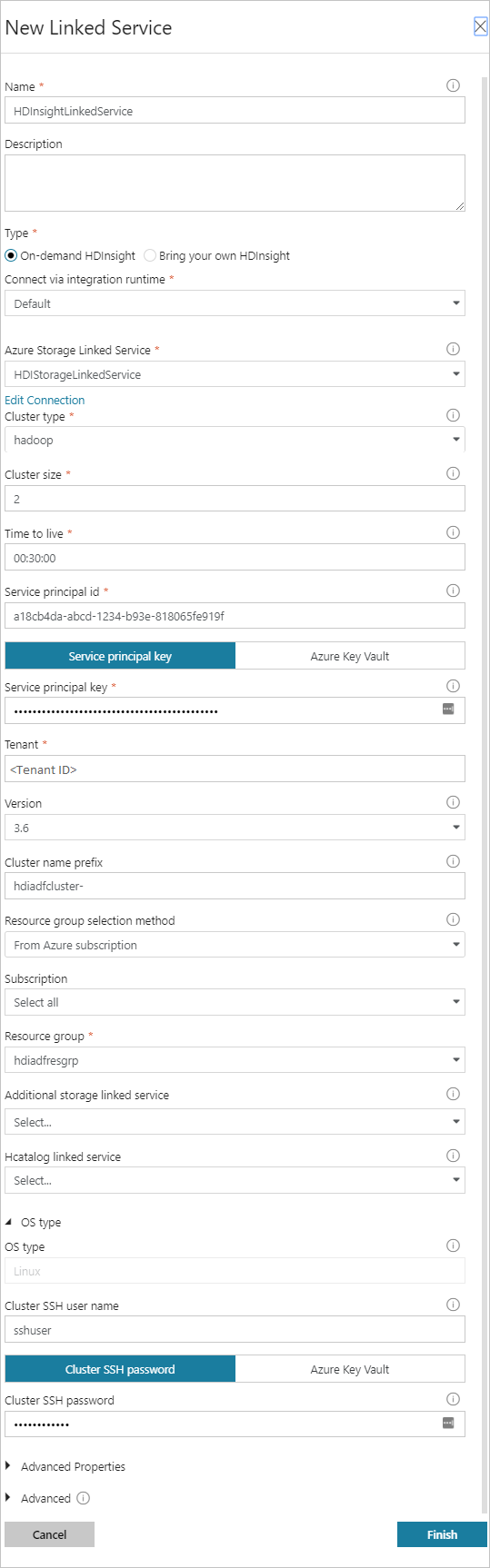
在 “新建链接服务 ”窗口中,输入以下值,并将其余值保留为默认值:
资产 价值 Name 输入 HDInsightLinkedService。类型 选择 按需 HDInsight。 Azure 存储链接服务 选择 HDIStorageLinkedService。群集类型 选择 hadoop 生存时间 请输入您希望 HDInsight 群集在自动删除前可用的时间长短。 服务主体 ID 提供作为先决条件的一部分创建的 Microsoft Entra 服务主体的应用程序 ID。 服务主体密钥 提供 Microsoft Entra 服务主体的身份验证密钥。 群集名称前缀 提供一个值,该值将前缀为数据工厂创建的所有群集类型。 Subscription 从下拉列表中选择订阅。 选择资源组 选择在前面使用的 PowerShell 脚本中创建的资源组。 OS 类型/群集 SSH 用户名 通常输入 SSH 用户名 sshuser。OS 类型/群集 SSH 密码 为 SSH 用户提供密码 OS 类型/群集用户名 输入群集用户名,通常 admin。OS 类型/群集密码 为群集用户提供密码。 然后选择“创建”。
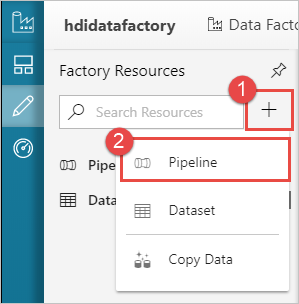
创建管道
选择 + 加号按钮,然后选择 管道。
在 "活动"工具箱中,展开 "HDInsight",并将 "Hive"活动拖动到管道设计器图面。 在“ 常规 ”选项卡中,提供活动的名称。
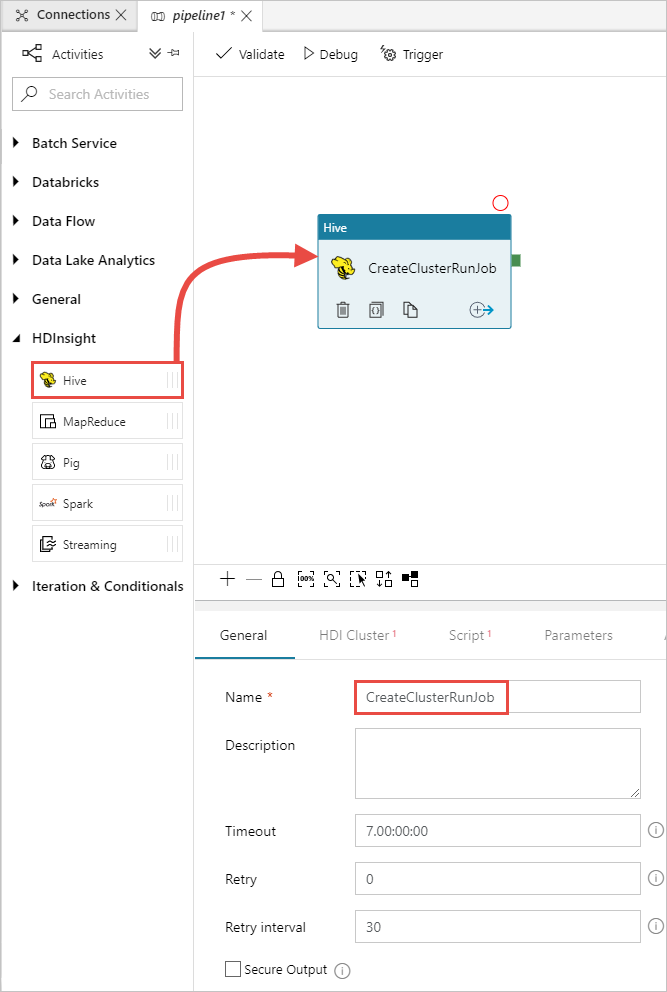
确保已选择 Hive 活动,选择 “HDI 群集 ”选项卡。从 HDInsight 链接服务 下拉列表中,为 HDInsight 选择之前创建的链接服务 (HDInsightLinkedService)。
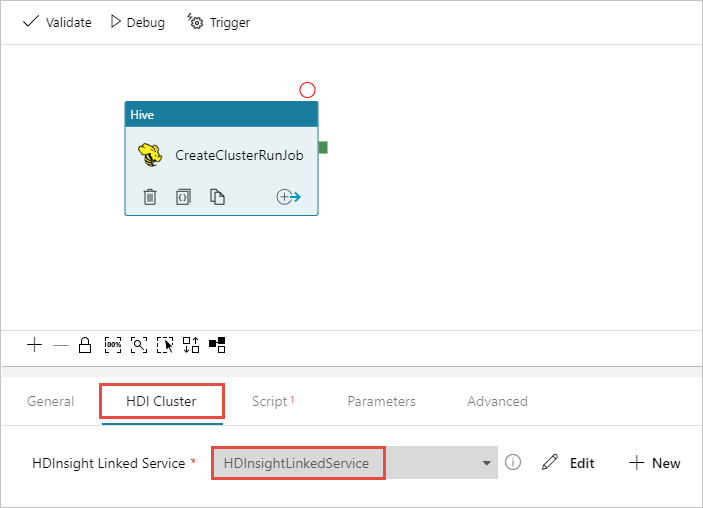
选择“ 脚本 ”选项卡并完成以下步骤:
对于 脚本链接服务,请从下拉列表中选择 HDIStorageLinkedService 。 此值是之前创建的存储链接服务。
对于 文件路径,选择 “浏览存储 ”并导航到示例 Hive 脚本可用的位置。 如果之前运行了 PowerShell 脚本,则此位置应为
adfgetstarted/hivescripts/partitionweblogs.hql。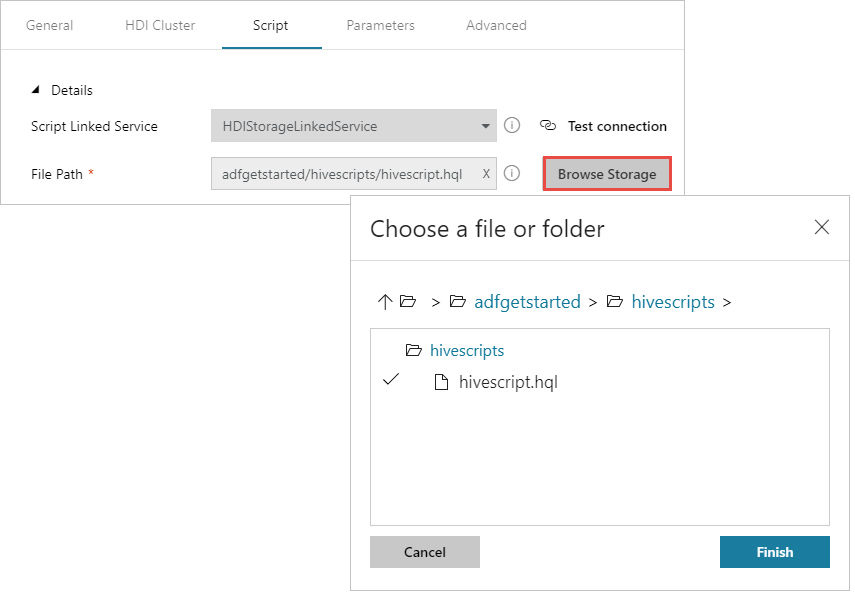
在 “高级>参数”下,选择
Auto-fill from script。 此选项查找 Hive 脚本中在运行时需要值的参数。在 值 文本框中,以格式
wasbs://adfgetstarted@<StorageAccount>.blob.core.chinacloudapi.cn/outputfolder/添加现有文件夹。 此路径区分大小写。 此路径是将存储脚本输出的位置。wasbs架构是必需的,因为存储帐户现在默认已启用安全传输。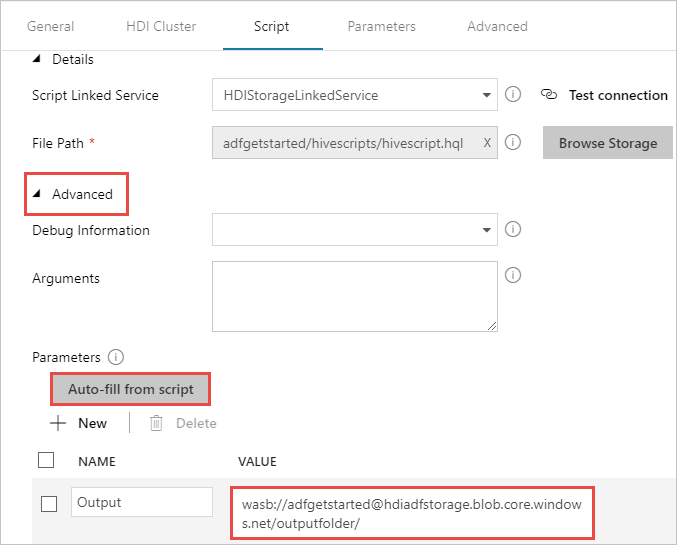
选择 “验证” 以验证管道。 选择 >>(右键头)按钮,关闭验证窗口。
最后,选择“ 全部发布 ”,将项目发布到 Azure 数据工厂。
触发管道
在设计器图面上的工具栏中,选择“ 立即添加触发器>触发器”。
在弹出侧栏中选择 “确定 ”。
监视流水线
在左侧切换到“监视”选项卡。 “管道运行”列表中会显示一个管道运行。 请注意“ 状态 ”列下的运行状态。
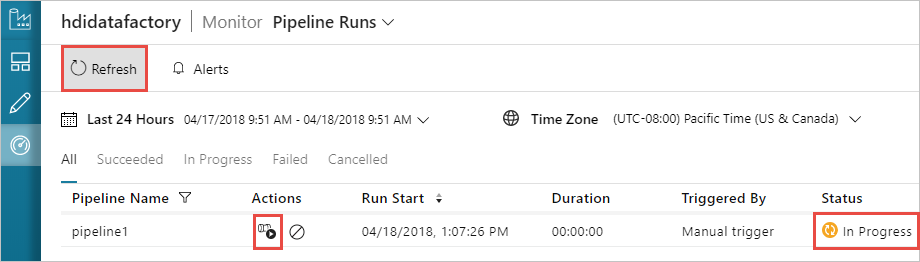
选择 “刷新 ”以刷新状态。
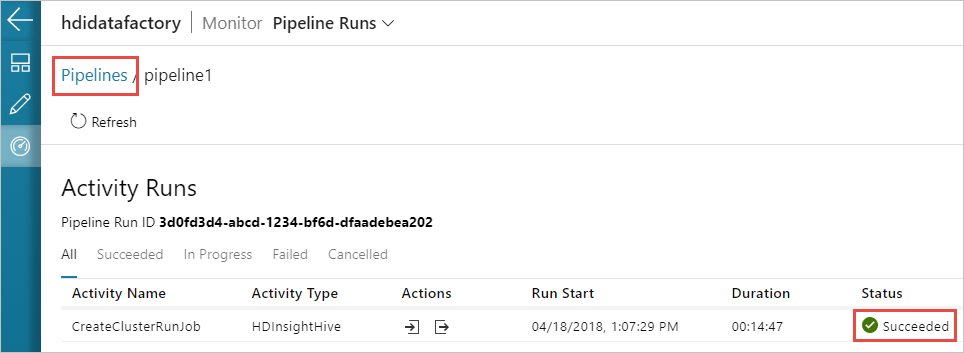
还可以选择 “查看活动运行” 图标以查看与管道关联的活动运行。 在下面的屏幕截图中,你只看到一个活动运行,因为创建的管道中只有一个活动。 若要切换回上一视图,请选择页面顶部的 “管道 ”。
验证输出
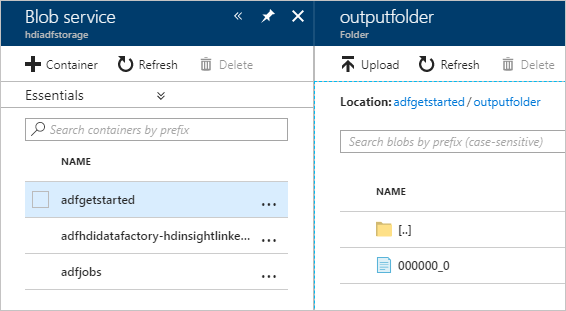
若要验证输出,请在 Azure 门户中导航到本教程中使用的存储帐户。 应会看到以下文件夹或容器:
会看到一个 adfgerstarted/outputfolder ,其中包含作为管道一部分运行的 Hive 脚本的输出。
会看到 adfhdidatafactory-<linked-service-name>-<timestamp> 容器。 此容器是作为管道运行一部分创建的 HDInsight 群集的默认存储位置。
会看到包含 Azure 数据工厂作业日志的 adfjobs 容器。
清理资源
创建按需 HDInsight 群集时,无需显式删除 HDInsight 群集。 群集是根据创建管道时提供的配置删除的。 即使在删除群集后,与群集关联的存储帐户也会继续存在。 此行为是经过设计的,以便你能够保持数据完好无损。 但是,如果不想保留数据,可以删除创建的存储帐户。
或者,可以删除为本教程创建的整个资源组。 此过程将删除创建的存储帐户和 Azure 数据工厂。
删除资源组
登录到 Azure 门户。
在左窗格中选择 资源组 。
选择在 PowerShell 脚本中创建的资源组名称。 如果列出的资源组太多,请使用筛选器。 此时会打开资源组。
在资源磁贴上,默认存储帐户和数据工厂应被列出,除非您与其他项目共享资源组。
选择“删除资源组”。 这样做会删除存储帐户和存储在存储帐户中的数据。
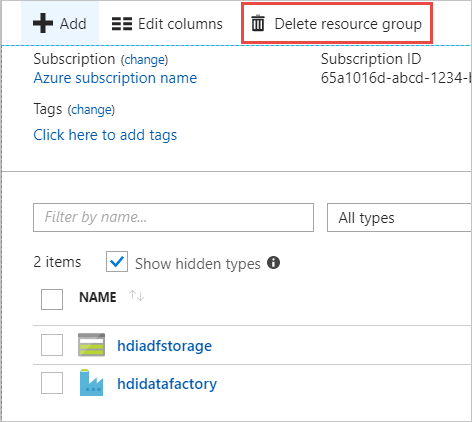
输入资源组名称以确认删除,然后选择“ 删除”。
后续步骤
本文介绍了如何使用 Azure 数据工厂创建按需 HDInsight 群集并运行 Apache Hive 作业。 请继续学习下一篇文章,了解如何使用自定义配置创建 HDInsight 群集。