了解如何使用 Apache Kafka 的镜像功能将主题复制到辅助群集。 可以连续运行镜像,也可以间歇性地运行镜像,将数据从一个群集迁移到另一个群集。
在本文中,你将使用镜像在两个 HDInsight 群集之间复制主题。 这些群集位于不同数据中心的不同虚拟网络中。
注释
- 可以使用镜像群集作为容错。
- 仅当主群集是 HDI Kafka 2.4.1 或 3.2.0 且辅助群集是 HDI Kafka 3.2.0 版本时,这才有效。
- 如果主群集发生故障,辅助群集将无缝工作。
- 使用者组偏移将自动转换为辅助群集。
- 只需将主要群集使用者指向具有相同使用者组的辅助群集,使用者组就会从它退出主群集的偏移处开始使用。
- 唯一的区别是备份群集中的主题名称将从TOPIC_NAME更改为主群集名称.TOPIC_NAME。
Apache Kafka 镜像的工作原理
镜像的工作原理是使用 Apache Kafka 的 MirrorMaker2 工具。 MirrorMaker 使用来自主群集上的主题的记录,然后在辅助群集上创建一个本地副本。 MirrorMaker2 使用一个(或多个)使用者从主要群集读取记录,使用一个生成者将记录写入本地(辅助)群集。
用于灾难恢复的最有用的镜像设置使用不同的 Azure 区域中的 Kafka 群集。 为获得此结果,群集所在的虚拟网络将对等互连到一起。
主要和辅助群集在节点与分区数目方面可以不同,主题中的偏移也可以不同。 镜像维护用于分区的键值,因此,根据键保留记录顺序。
跨网络边界执行镜像操作
如果需要在不同网络中的 Kafka 群集之间进行镜像,则需要考虑以下更多注意事项:
网关:网络必须能够在 TCP/IP 级别通信。
服务器寻址:可以选择使用群集节点的 IP 地址或完全限定的域名来寻址群集节点。
IP 地址:如果将 Kafka 群集配置为使用 IP 地址播发,则可以使用代理节点和 ZooKeeper 节点的 IP 地址继续执行镜像设置。
域名称:如果未在 Kafka 群集上配置 IP 地址播发,则群集必须能够使用完全限定的域名 (FQDN) 相互连接。 这需要每个网络中配置为将请求转发到其他网络的域名系统 (DNS) 服务器。 创建 Azure 虚拟网络时,必须指定自定义 DNS 服务器和服务器的 IP 地址,而不是使用网络提供的自动 DNS。 创建虚拟网络后,必须创建使用该 IP 地址的 Azure 虚拟机。 然后,在计算机上安装并配置 DNS 软件。
重要
在将 HDInsight 安装到虚拟网络之前创建和配置自定义 DNS 服务器。 HDInsight 无需进行其他配置,即可使用为虚拟网络配置的 DNS 服务器。
有关连接两个 Azure 虚拟网络的详细信息,请参阅 配置连接。
镜像体系结构
此体系结构具有不同资源组和虚拟网络中的两个群集:主群集和辅助群集。
创建步骤
创建两个新的资源组:
资源组 位置 kafka-primary-rg 中国北部 kafka-secondary-rg 中国北部 在 kafka-primary-rg 中创建新的虚拟网络 kafka-primary-vnet。 保留默认设置。
在 kafka-secondary-rg 中创建新的虚拟网络 kafka-secondary-vnet,也使用默认设置。
注释
保持两个 VNet 的地址不重叠,否则 VNet 对等互连将不起作用。 示例:
- kafka-primary-vnet 可以具有地址空间 10.0.0.0
- kafka-secondary-vnet 的地址空间可以为 10.1.0.0
创建虚拟网络对等互连。 此步骤创建两个对等互连:一个从 kafka-primary-vnet 连接到 kafka-secondary-vnet,一个从 kafka-secondary-vnet 连接回到 kafka-primary-vnet。
选择 kafka-primary-vnet 虚拟网络。
在“设置”下选择“对等互连”。
选择 并添加。
在“添加对等互连”屏幕上输入详细信息,如以下屏幕截图所示。
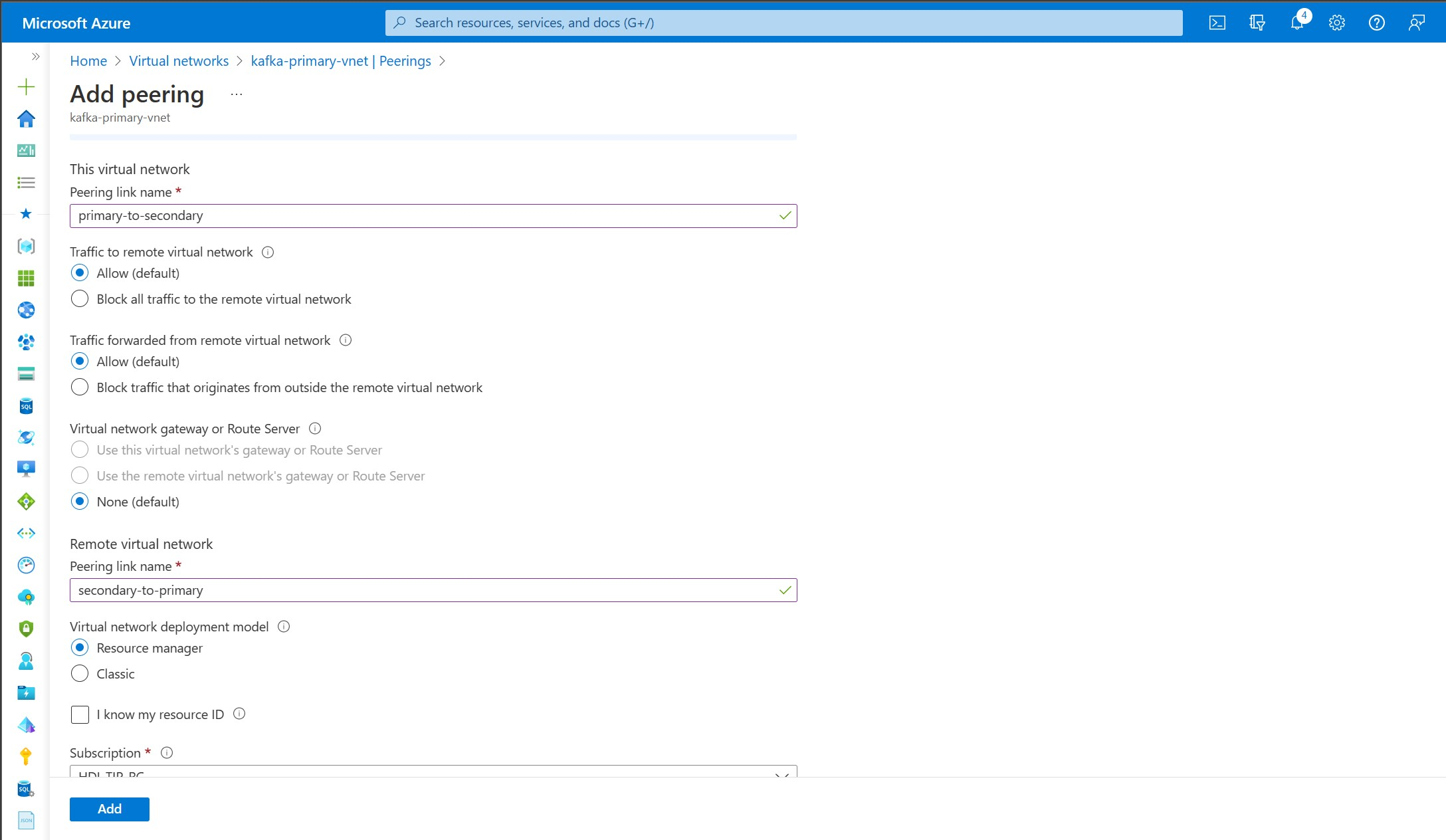
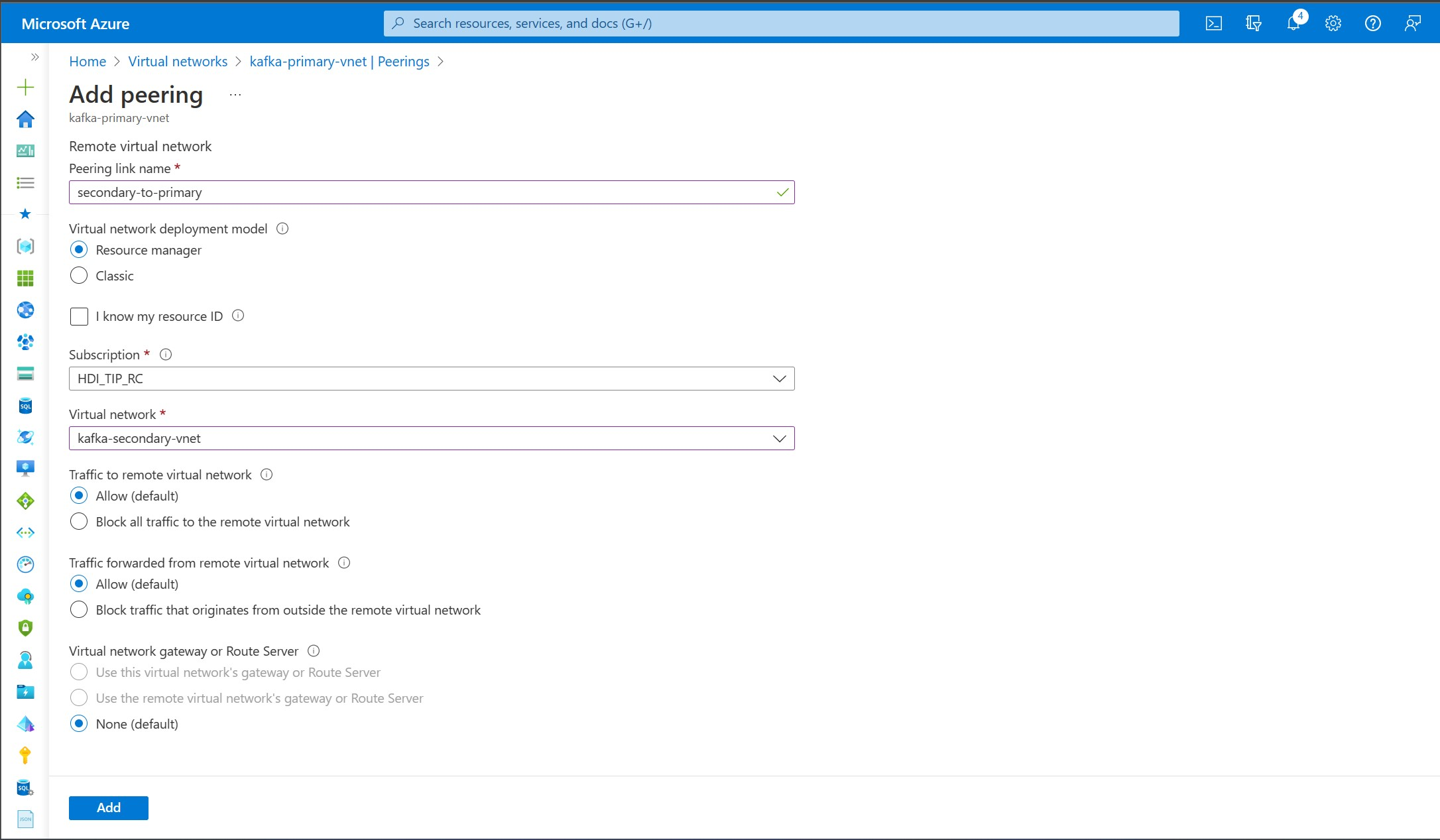
创建两个新的 Kafka 群集:
群集名称 HDInsight 版本 资源组 虚拟网络 存储帐户 primary-kafka-cluster 5.0 kafka-primary-rg kafka-primary-vnet Kafka主存储 secondary-kafka-cluster 5.1 kafka-secondary-rg kafka-secondary-vnet Kafka 二级存储 注释
从现在开始,我们将使用
primary-kafka-cluster作为PRIMARYCLUSTER,使用secondary-kafka-cluster作为SECONDARYCLUSTER。
将 PRIMARYCLUSTER 工作节点的 IP 地址配置到客户机以进行 DNS 解析
使用头节点
SECONDARYCLUSTER运行镜像创建器脚本。 然后,我们需要/etc/hosts的SECONDARYCLUSTER文件中 PRIMARYCLUSTER 的工作器节点的 IP 地址。连接到
PRIMARYCLUSTERssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.cn执行以下命令并获取工作器节点 IP 和 FQDN 的条目
cat /etc/hosts复制这些条目并连接到
SECONDARYCLUSTER并运行ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.cn`编辑辅助群集的
/etc/hosts文件,并在此处添加这些项。在您进行了更改之后,
/etc/hosts文件在SECONDARYCLUSTER中的外观类似于给定的图像。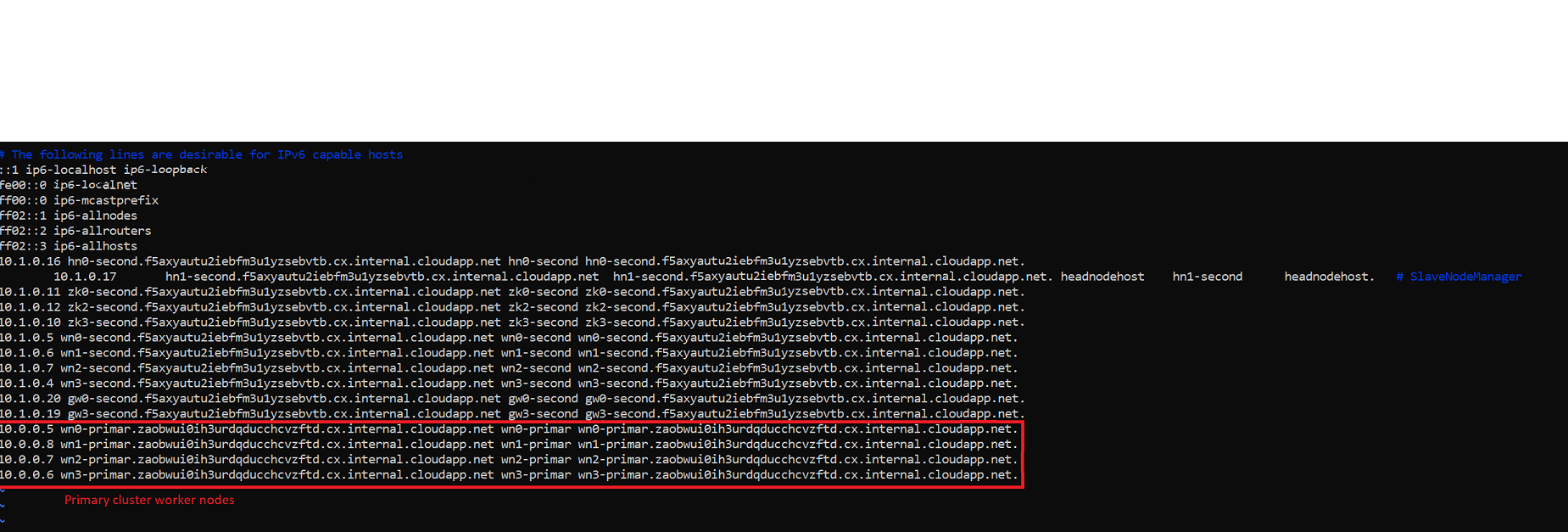
保存并关闭该文件。

在 PRIMARYCLUSTER 中创建多个主题
使用此命令创建主题并替换变量。
bash /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --zookeeper $KAFKAZKHOSTS --create --topic $TOPICNAME --partitions $NUM_PARTITIONS --replication-factor $REPLICATION_FACTOR
在 SECONDARYCLUSTER 中配置 MirrorMaker2
现在更改 MirrorMaker2 属性文件中的配置。
使用管理员权限执行以下命令
sudo su vi /etc/kafka/conf/connect-mirror-maker.properties注释
本文包含一个对 Azure 不再使用的术语的引用。 在从软件中删除该术语后,我们会将其从本文中删除。
属性文件如下所示。
# specify any number of cluster aliases clusters = source, destination # connection information for each cluster # This is a comma separated host:port pairs for each cluster # for example. "A_host1:9092, A_host2:9092, A_host3:9092" and you can see the exact host name on Ambari > Hosts source.bootstrap.servers = wn0-src kafka.bx.internal.chinacloudapp.cn:9092,wn1-src-kafka.bx.internal.chinacloudapp.cn:9092,wn2-src-kafka.bx.internal.chinacloudapp.cn:9092 destination.bootstrap.servers = wn0-dest-kafka.bx.internal.chinacloudapp.cn:9092,wn1-dest-kafka.bx.internal.chinacloudapp.cn:9092,wn2-dest-kafka.bx.internal.chinacloudapp.cn:9092 # enable and configure individual replication flows source->destination.enabled = true # regex which defines which topics gets replicated. For eg "foo-.*" source->destination.topics = .* groups=.* topics.blacklist="*.internal,__.*" # Setting replication factor of newly created remote topics Replication.factor=3 checkpoints.topic.replication.factor=1 heartbeats.topic.replication.factor=1 offset-syncs.topic.replication.factor=1 offset.storage.replication.factor=1 status.storage.replication.factor=1 config.storage.replication.factor=1此处的源是你的
PRIMARYCLUSTER,目标是你的SECONDARYCLUSTR。 将它替换为正确的名称,并将source.bootstrap.servers和destination.bootstrap.servers替换为各自工作器节点的正确 FQDN 或 IP。可以使用正则表达式指定要复制的主题及其配置。 将参数
replication.factor设置为 3,可以确保 MirrorMaker 脚本创建的所有主题的复制因子为 3。将这些主题的复制因子从 1 增加到 3
checkpoints.topic.replication.factor=1 heartbeats.topic.replication.factor=1 offset-syncs.topic.replication.factor=1 offset.storage.replication.factor=1 status.storage.replication.factor=1 config.storage.replication.factor=1注释
成为中转站级别所有主题的默认不同步副本的原因是 2。 保留复制因子 =1,在运行 mirrormaker2 时将引发异常
需要 启用自动主题创建 功能,然后镜像制作脚本会在辅助群集中复制名称为
PRIMARYCLUSTER.TOPICNAME且具有相同配置的主题。 保存文件,这样我们就完成配置了。要在两侧镜像主题,例如
Primary to Secondary和Secondary to Primary(主动-主动),可以添加额外的配置destination->source.enabled=true destination->source.topics = .*对于自动执行的使用者偏移同步,也需要启用复制并控制同步持续时间。 以下属性将每 30 秒同步偏移一次。 对于主动-主动场景,我们需要通过两种方式执行此操作。
groups=.* emit.checkpoints.enabled = true source->destination.sync.group.offsets.enabled = true source->destination.sync.group.offsets.interval.ms=30000 destination->source.sync.group.offsets.enabled = true destination->source.sync.group.offsets.interval.ms=30000如果不想跨群集复制内部主题,请使用以下属性
topics.blacklist="*.internal,__.*"更改后的最终配置文件应如下所示
# specify any number of cluster aliases clusters = primary-kafka-cluster, secondary-kafka-cluster # connection information for each cluster # This is a comma separated host:port pairs for each cluster # for example. "A_host1:9092, A_host2:9092, A_host3:9092" and you can see the exact host name on Ambari -> Hosts primary-kafka-cluster.bootstrap.servers = wn0-src-kafka.bx.internal.chinacloudapp.cn:9092,wn1-src-kafka.bx.internal.chinacloudapp.cn:9092,wn2-src-kafka.bx.internal.chinacloudapp.cn:9092 secondary-kafka-cluster.bootstrap.servers = wn0-dest-kafka.bx.internal.chinacloudapp.cn:9092,wn1-dest-kafka.bx.internal.chinacloudapp.cn:9092,wn2-dest-kafka.bx.internal.chinacloudapp.cn:9092 # enable and configure individual replication flows primary-kafka-cluster->secondary-kafka-cluster.enabled = true # enable this for both side replication secondary-kafka-cluster->primary-kafka-cluster.enabled = true # regex which defines which topics gets replicated. For eg "foo-.*" primary-kafka-cluster->secondary-kafka-cluster.topics = .* secondary-kafka-cluster->primary-kafka-cluster.topics = .* groups=.* emit.checkpoints.enabled = true primary-kafka-cluster->secondary-kafka-cluster.sync.group.offsets.enabled=true primary-kafka-cluster->secondary-kafka-cluster.sync.group.offsets.interval.ms=30000 secondary-kafka-cluster->primary-kafka-cluster.sync.group.offsets.enabled = true secondary-kafka-cluster->primary-kafka-cluster.sync.group.offsets.interval.ms=30000 topics.blacklist="*.internal,__.*" # Setting replication factor of newly created remote topics Replication.factor=3 checkpoints.topic.replication.factor=3 heartbeats.topic.replication.factor=3 offset-syncs.topic.replication.factor=3 offset.storage.replication.factor=3 status.storage.replication.factor=3 config.storage.replication.factor=3启动 Mirror Maker2
SECONDARYCLUSTER,应正常运行/usr/hdp/current/kafka-broker ./bin/connect-mirror-maker.sh ./config/connect-mirror-maker.properties现在在
PRIMARYCLUSTER中启动生成者export clusterName='primary-kafka-cluster' export TOPICNAME='TestMirrorMakerTopic' export KAFKABROKERS='wn0-primar:9092' export KAFKAZKHOSTS='zk0-primar:2181' //Start Producer # For Kafka 2.4 bash /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --zookeeper $KAFKAZKHOSTS --topic $TOPICNAME # For Kafka 3.2 bash /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --boostrap-server $KAFKABROKERS --topic $TOPICNAME现在,通过使用者组启动 PRIMARYCLUSTER 中的使用者
//Start Consumer # For Kafka 2.4 bash /usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --zookeeper $KAFKAZKHOSTS --topic $TOPICNAME --group my-group --from- beginning # For Kafka 3.2 bash /usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --boostrap-server $KAFKABROKERS --topic $TOPICNAME --group my-group --from-beginning现在,停止 PRIMARYCONSUMER 中的使用者,然后使用同一使用者组启动 SECONDARYCLUSTER 中的使用者
export clusterName='secondary-kafka-cluster' export TOPICNAME='primary-kafka-cluster.TestMirrorMakerTopic' export KAFKABROKERS='wn0-second:9092' export KAFKAZKHOSTS='zk0-second:2181' # List all the topics whether they're replicated or not bash /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --zookeeper $KAFKAZKHOSTS --list # Start Consumer bash /usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic $TOPICNAME --from-beginning你会注意到,在辅助群集使用者组中,my-group 无法使用任何消息,因为消息已由主群集使用者组使用。 现在,可在主群集中生成更多消息,并尝试在辅助群集中使用它们。 可以从
SECONDARYCLUSTER开始使用。
删除群集
警告
HDInsight 群集按分钟使用比例收费,无论使用与否。 请务必在使用完群集之后将其删除。 请参阅如何删除 HDInsight 群集。
本文中的步骤在不同的 Azure 资源组中创建群集。 若要删除创建的所有资源,可以删除创建的两个资源组: kafka-primary-rg 和 kafka-secondary-rg。 删除资源组会删除本文创建的所有资源,包括群集、虚拟网络和存储帐户。
后续步骤
本文介绍了如何使用 MirrorMaker2 创建 Apache Kafka 群集的副本。
使用以下链接来发现与 Kafka 配合使用的其他方式: