了解如何使用 Apache Spark 通过 DStreams 将数据流式传入或流式传出 Apache Kafka on HDInsight。 本示例使用在 Spark 群集上运行的 Jupyter Notebook。
注意
本文档中的步骤创建了一个包含 Spark on HDInsight 和 Kafka on HDInsight 群集的 Azure 资源组。 这些群集都位于一个 Azure 虚拟网络中,这样 Spark 群集便可与 Kafka 群集直接通信。
完成本文档中的步骤后,请记得删除这些群集,避免产生额外费用。
重要
此示例使用 DStreams,这是较旧的 Spark 流式处理技术。 有关使用较新的 Spark 流式处理功能的示例,请参阅使用 Apache Kafka 的 Spark 结构化流式处理文档。
创建群集
Apache Kafka on HDInsight 不提供通过公共 Internet 访问 Kafka 中转站的权限。 与 Kafka 对话的任何内容都必须与 Kafka 群集中的节点位于同一 Azure 虚拟网络中。 对于此示例,Kafka 和 Spark 群集都位于 Azure 虚拟网络中。 下图显示通信在群集之间的流动方式:
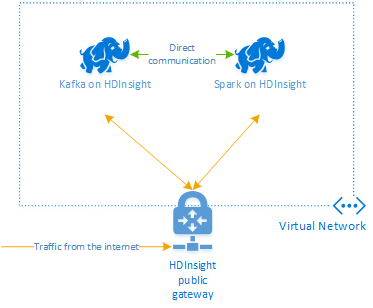
注意
虽然 Kafka 本身受限于虚拟网络中的通信,但可以通过 Internet 访问群集上的其他服务(例如 SSH 和 Ambari)。 有关可用于 HDInsight 的公共端口的详细信息,请参阅 HDInsight 使用的端口和 URI。
尽管可手动创建 Azure 虚拟网络、Kafka 和 Spark 群集,但使用 Azure 资源管理器模板更简单。 使用以下步骤将 Azure 虚拟网络、Kafka 和 Spark 群集部署到 Azure 订阅。
使用以下按钮登录到 Azure,并在 Azure 门户中打开模板。

警告
若要确保 Kafka on HDInsight 的可用性,群集必须至少包含四个工作器节点。 此模板创建的 Kafka 群集包含四个工作器节点。
此模板为 Kafka 和 Spark 创建 HDInsight 4.0 群集。
使用以下信息填充“自定义部署”部分中的条目:
属性 值 资源组 创建一个组或选择有个现有的组。 位置 选择在地理上邻近的位置。 基群集名称 此值将用作 Spark 和 Kafka 群集的基名称。 例如,输入 hdistreaming 将创建名为 spark-hdistreaming 的 Spark 群集和名为 kafka-hdistreaming 的 Kafka 群集。 群集登录用户名 Spark 和 Kafka 群集的管理员用户名。 群集登录密码 Spark 和 Kafka 群集的管理员用户密码。 SSH 用户名 创建 Spark 和 Kafka 群集的 SSH 用户。 SSH 密码 Spark 和 Kafka 群集的 SSH 用户的密码。 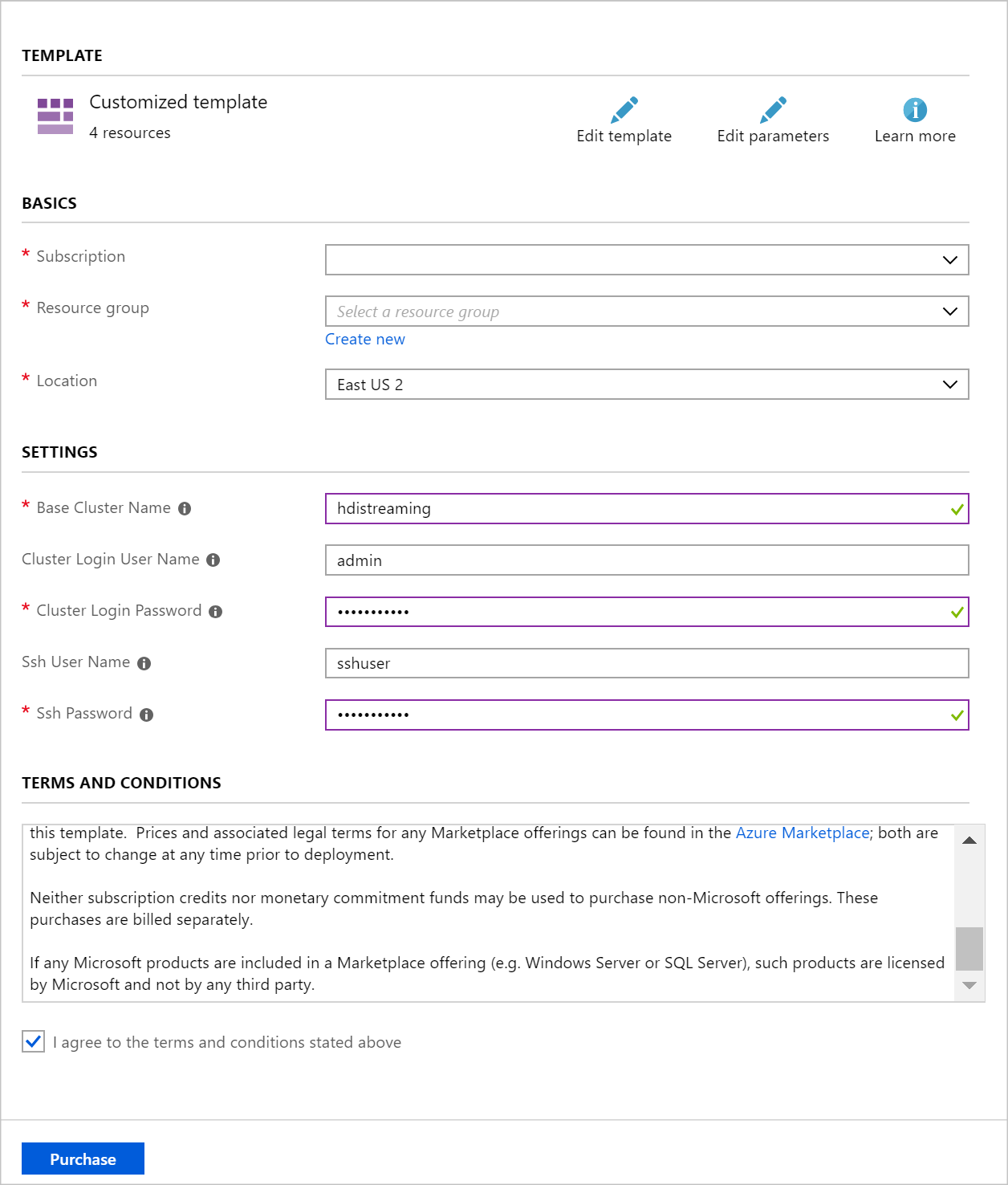
阅读“条款和条件”,并选择“我同意上述条款和条件”。
最后,选择“购买”。 创建群集大约需要 20 分钟时间。
创建资源后,会显示摘要页面。
重要
请注意,HDInsight 群集的名称为 spark-BASENAME 和 kafka-BASENAME,其中 BASENAME 是为模板提供的名称。 在连接到群集的后续步骤中,会用到这些名称。
使用笔记本
可在 https://github.com/Azure-Samples/hdinsight-spark-scala-kafka 处查看本文档所描述示例的代码。
删除群集
警告
HDInsight 群集是基于分钟按比例计费,而不管用户是否使用它们。 请务必在使用完群集之后将其删除。 请参阅如何删除 HDInsight 群集。
由于本文档中的步骤在相同的 Azure 资源组中创建两个群集,因此可在 Azure 门户中删除资源组。 删除该组将删除按照本文档创建的所有资源、Azure 虚拟网络和群集使用的存储帐户。
后续步骤
在本示例中,了解如何使用 Spark 对 Kafka 进行读取和写入。 使用以下链接来发现与 Kafka 配合使用的其他方式: