了解如何使用 Apache Kafka 的镜像功能将主题复制到辅助群集。 可以连续运行镜像,也可以间歇性地运行镜像,将数据从一个群集迁移到另一个群集。
在本文中,你将使用镜像在两个 HDInsight 群集之间复制主题。 这些群集位于不同数据中心的不同虚拟网络中。
Warning
不要使用镜像作为实现容错的方法。 主题中项的偏移量在主要群集和辅助群集之间有所不同,因此客户端不能互换使用这两个群集。 如果您关注容错能力,则应为集群中的主题设置副本。 有关详细信息,请参阅 Apache Kafka on HDInsight 入门。
Apache Kafka 镜像的工作原理
镜像的工作原理是使用 Apache Kafka 的 MirrorMaker 工具。 MirrorMaker 使用主群集上主题的记录,然后在辅助群集上创建本地副本。 MirrorMaker 使用一个(或多个)从主集群读取数据的 消费者,以及一个向本地(辅助)集群写入数据的 生产者。
用于灾难恢复的最有用的镜像设置使用不同Azure区域中的 Kafka 群集。 为此,将群集所在的虚拟网络彼此对等互连。
下图演示了镜像过程以及群集之间的通信如何流动:
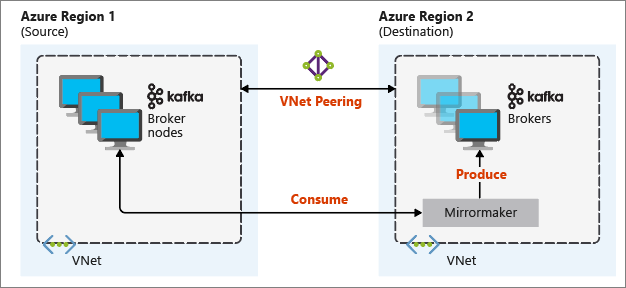
主群集和辅助群集在节点数和分区数中可能不同,主题中的偏移量也不同。 镜像会保留用于分区的键值,因此会对每个键保留记录顺序。
跨网络边界镜像
如果需要在不同网络中的 Kafka 群集之间进行镜像,需要注意以下其他注意事项:
网关:网络必须能够在 TCP/IP 级别进行通信。
服务器寻址:可以选择使用群集节点的 IP 地址或完全限定的域名来寻址群集节点。
IP 地址:如果将 Kafka 群集配置为使用 IP 地址播发,则可以使用代理节点和 ZooKeeper 节点的 IP 地址继续执行镜像设置。
域名:如果未为 Kafka 群集配置 IP 地址播发,群集必须能够使用完全限定的域名(FQDN)相互连接。 这需要每个网络中配置为将请求转发到其他网络的域名系统 (DNS) 服务器。 创建Azure虚拟网络时,必须指定自定义 DNS 服务器和服务器的 IP 地址,而不是使用网络提供的自动 DNS。 创建虚拟网络后,必须创建使用该 IP 地址的Azure虚拟机。 然后,在计算机上安装并配置 DNS 软件。
重要
在将 HDInsight 安装到虚拟网络之前创建和配置自定义 DNS 服务器。 HDInsight 无需进行其他配置,即可使用为虚拟网络配置的 DNS 服务器。
有关连接两个Azure虚拟网络的详细信息,请参阅“配置连接”。
镜像体系结构
此体系结构具有不同资源组和虚拟网络中的两个群集:主群集和辅助群集。
创建步骤
创建两个新的资源组:
资源组 Location kafka-primary-rg 中国北部 3 kafka-secondary-rg 中国北部 3 在 kafka-primary-rg 中创建一个新的虚拟网络 kafka-primary-vnet。 保留默认设置。
在 kafka-secondary-rg 中创建一个新的虚拟网络 kafka-secondary-vnet,同样使用默认设置。
创建两个新的 Kafka 群集:
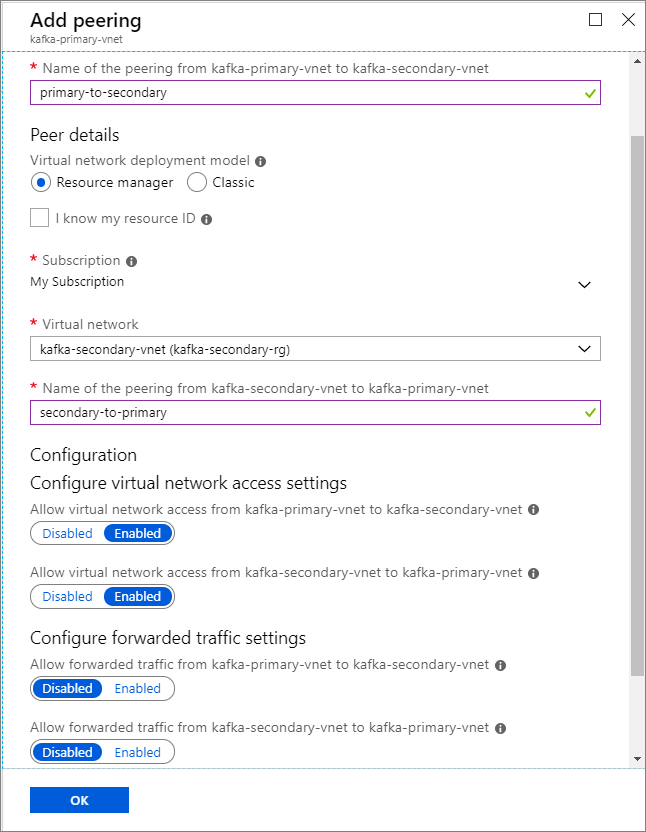
群集名称 资源组 虚拟网络 存储帐户 kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage 创建虚拟网络对等互连。 此步骤将创建两个对等互连关系:一个从 kafka-primary-vnet 到 kafka-secondary-vnet,另一个则从 kafka-secondary-vnet 返回到 kafka-primary-vnet。
选择 kafka-primary-vnet 虚拟网络。
在“设置”下选择“对等互连”。
选择 并添加。
在 “添加对等互连 ”屏幕上,输入详细信息,如以下屏幕截图所示。
配置 IP 通告
配置 IP 播发,使客户端能够使用代理 IP 地址而不是域名进行连接。
转到主群集的 Ambari 仪表板:
https://PRIMARYCLUSTERNAME.azurehdinsight.cn。选择 “服务>Kafka”。 选择“ 配置 ”选项卡。
将以下配置行添加到底部 kafka-env 模板 部分。 选择“保存”。
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.properties在 “保存配置” 屏幕上输入备注,然后选择“ 保存”。
如果收到配置警告,请选择“ 仍然继续”。
在 “保存配置更改”上,选择“ 确定”。
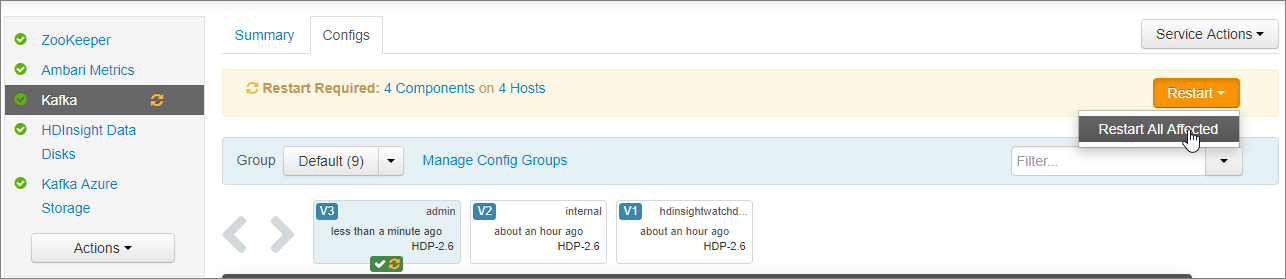
在“需要重新启动”通知中,选择“重新启动>重新启动所有受影响的项目”。 然后选择“确认全部重启”。
配置 Kafka 以侦听所有网络接口
- 停留在配置选项卡,该选项卡位于服务>Kafka下。 在 Kafka Broker 部分中,将 侦听器 属性设置为
PLAINTEXT://0.0.0.0:9092。 - 选择“保存”。
- 选择重启>确认全部重启。
记录主集群的代理 IP 地址和 ZooKeeper 地址
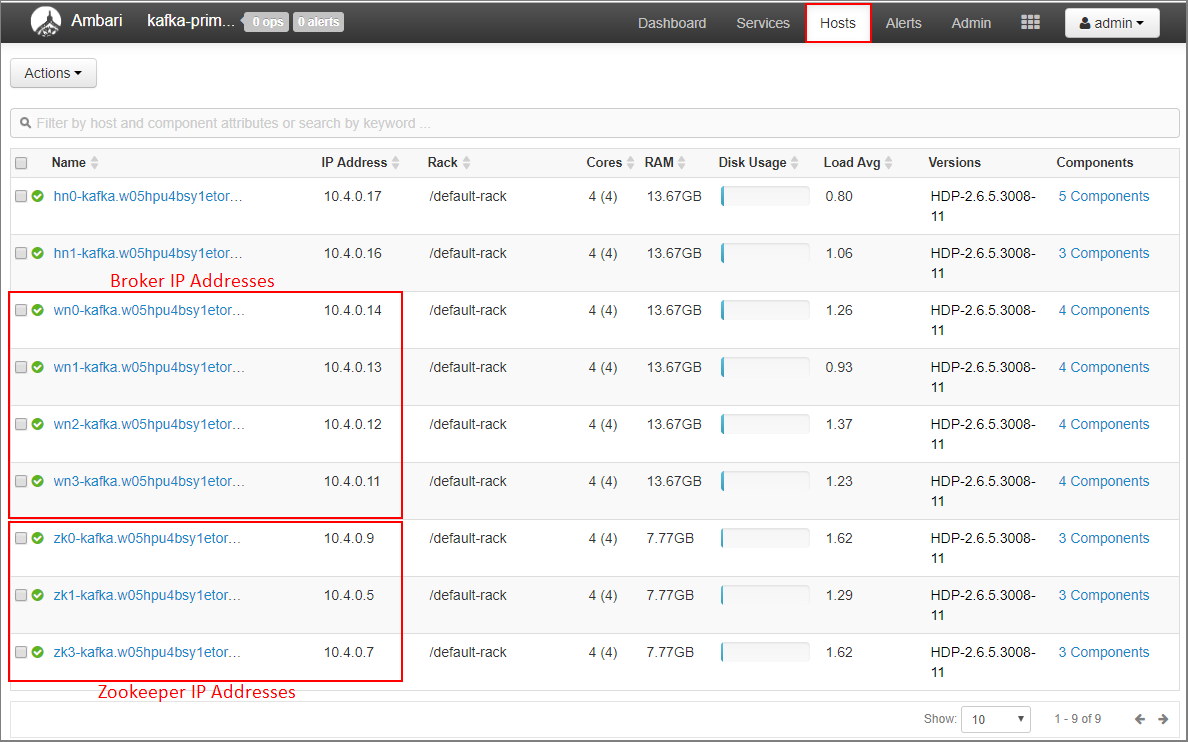
在 Ambari 仪表板上,选择主机。
记下代理和 ZooKeepers 的 IP 地址。 代理节点的主机名前两个字母是wn,ZooKeeper 节点的主机名前两个字母是zk。
对第二个群集 kafka-secondary-cluster 重复上述三个步骤:配置 IP 播发、设置侦听器,并记下代理和 ZooKeeper IP 地址。
创建主题
使用 SSH 连接到主群集:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.cn将
sshuser替换为创建群集时所使用的 SSH 用户名。 用创建群集时使用的基名称替换PRIMARYCLUSTER。有关详细信息,请参阅 将 SSH 与 HDInsight 配合使用。
使用以下命令创建两个环境变量,其中包含主群集的 Apache ZooKeeper 主机和代理主机。 将字符串
ZOOKEEPER_IP_ADDRESS1替换为前面记录的实际 IP 地址,例如10.23.0.11和10.23.0.7。BROKER_IP_ADDRESS1也是如此。 如果你使用自定义 DNS 服务器进行 FQDN 解析,请按照以下步骤获取 Broker 和 ZooKeeper 的名称。# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'若要创建名为
testtopic的主题,请使用以下命令:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTS使用以下命令验证是否已创建主题:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTS响应包含
testtopic。使用以下命令查看此(主)群集的中转站主机信息:
echo $PRIMARY_BROKERHOSTS这会返回类似于以下文本的信息:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092保存此信息。 在下一部分中使用。
配置镜像
使用不同的 SSH 会话连接到辅助群集:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.cn将
sshuser替换为创建集群时使用的 SSH 用户名。 将SECONDARYCLUSTER替换为您在创建群集时使用的名称。有关详细信息,请参阅 将 SSH 与 HDInsight 配合使用。
使用
consumer.properties文件配置与主集群的通信。 若要创建文件,请使用以下命令:nano consumer.properties使用以下文本作为
consumer.properties文件的内容:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroup用主集群中的代理主机 IP 地址替换
PRIMARY_BROKERHOSTS。此文件描述从主 Kafka 群集读取时要使用的使用者信息。 有关详细信息,请参阅使用者配置。
kafka.apache.org若要保存文件,请按 Ctrl+X,按 Y,然后按 Enter。
在配置与辅助群集通信的生成者之前,请为辅助群集的中转站 IP 地址设置变量。 使用以下命令创建此变量:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'此命令
echo $SECONDARY_BROKERHOSTS应返回类似于以下文本的信息:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092使用
producer.properties文件与辅助集群通信。 若要创建文件,请使用以下命令:nano producer.properties将以下文本用作
producer.properties文件的内容:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=none用上一步中使用的代理服务器 IP 地址替换
SECONDARY_BROKERHOSTS。有关详细信息,请参阅生成者配置。
kafka.apache.org使用以下命令创建具有辅助群集 ZooKeeper 主机 IP 地址的环境变量:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'Kafka on HDInsight 的默认配置不允许自动创建主题。 在启动镜像过程之前,必须使用下列选项之一:
在辅助群集上创建主题:此选项还允许设置分区数和复制因子。
可以使用以下命令提前创建主题:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTS用要创建的主题名称替换
testtopic。配置群集以创建自动主题:此选项允许 MirrorMaker 自动创建主题。 请注意,创建出来的主题,其分区数或复制因子可能与主主题不同。
若要将辅助群集配置为自动创建主题,请执行以下步骤:
- 转到辅助群集的 Ambari 仪表板:
https://SECONDARYCLUSTERNAME.azurehdinsight.cn。 - 选择 “服务>Kafka”。 然后选择“ 配置 ”选项卡。
- 在 “筛选器” 字段中,输入值
auto.create。 这会筛选属性列表并显示auto.create.topics.enable设置。 - 将值
auto.create.topics.enable更改为true,然后选择“ 保存”。 添加备注,然后再次选择“ 保存 ”。 - 选择 Kafka 服务,选择“重启”,然后选择“重启所有受影响的”。 出现提示时,选择“ 确认全部重启”。
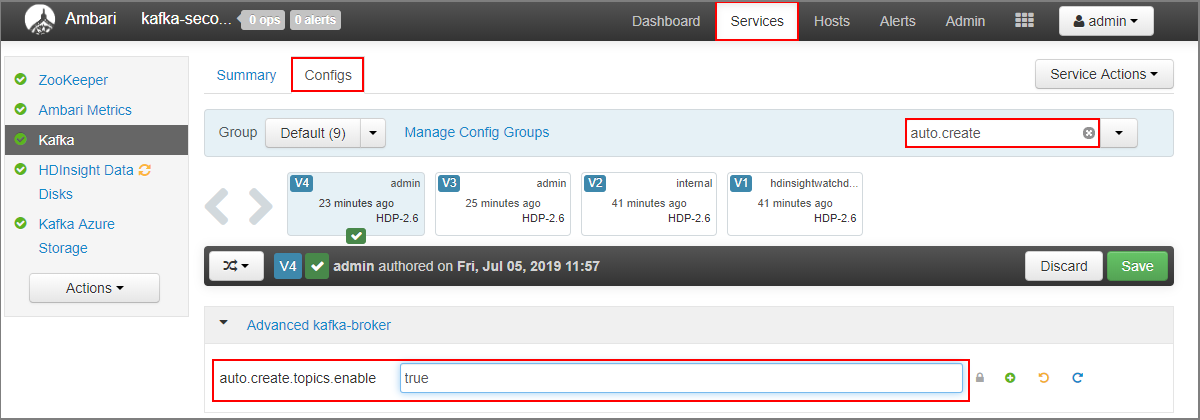
- 转到辅助群集的 Ambari 仪表板:
启动 MirrorMaker
注释
本文包含一个对 Azure 不再使用的术语的引用。 在从软件中删除该术语后,我们会将其从本文中删除。
从 SSH 连接到辅助群集,使用以下命令启动 MirrorMaker 进程:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4此示例中使用的参数包括:
参数 Description --consumer.config指定包含使用者属性的文件。 你可以使用这些属性创建一个从主 Kafka 集群读取数据的消费者。 --producer.config指定包含生成者属性的文件。 您可以使用这些属性创建一个向次要 Kafka 集群写入数据的生产者。 --whitelistMirrorMaker 从主群集复制到辅助群集的主题列表。 --num.streams要创建的使用者线程数。 辅助节点上的使用者现在正在等待接收消息。
从 SSH 连接到主群集,使用以下命令启动生成者并将消息发送到主题:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopic当你看到有光标的空白行时,输入几条文本消息。 消息将发送到主集群中的该主题。 完成后,按 Ctrl+C 结束生成者进程。
从 SSH 连接到辅助群集,按 Ctrl+C 结束 MirrorMaker 进程。 结束该过程可能需要几秒钟时间。 若要验证消息是否已复制到辅助数据库,请使用以下命令:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginning现在,主题列表中现已包含
testtopic,该主题是在 MirrorMaster 将主题从主集群镜像到辅助集群时创建的。 从主题检索到的消息与在主群集上输入的消息相同。
删除群集
Warning
HDInsight 群集按分钟使用比例收费,无论使用与否。 请务必在使用完群集之后将其删除。 请参阅如何删除 HDInsight 群集。
本文中的步骤在不同的Azure资源组中创建群集。 若要删除创建的所有资源,可以删除创建的两个资源组: kafka-primary-rg 和 kafka-secondary-rg。 删除资源组会删除本文创建的所有资源,包括群集、虚拟网络和存储帐户。
后续步骤
本文介绍了如何使用 MirrorMaker 创建 Apache Kafka 群集的副本。 使用以下链接发现使用 Kafka 的其他方法: