本文演示如何使用 IntelliJ IDE 的 Azure Toolkit 插件在 Azure HDInsight 上开发 Apache Spark 应用程序。 Azure HDInsight 是托管在云中的开放源代码分析服务。 凭借该服务,你可使用开放源代码框架,如 Hadoop、Apache Spark、Apache Hive 和 Apache Kafka。
可按多种方式使用 Azure 工具包插件:
- 开发 Scala Spark 应用程序并将其提交到 HDInsight Spark 群集。
- 访问 Azure HDInsight Spark 群集资源。
- 本地开发和运行 Scala Spark 应用程序。
在本文中,学习如何:
- 使用 Azure Toolkit for IntelliJ 插件
- 开发 Apache Spark 应用程序
- 将应用程序提交到 Azure HDInsight 群集
先决条件
HDInsight 上的 Apache Spark 群集。 有关说明,请参阅在 Azure HDInsight 中创建 Apache Spark 群集。 仅支持公有云中的 HDInsight 群集,而不支持其他安全云类型(例如政府云)。
Oracle Java 开发工具包。 本文使用 Java 版本 8.0.202。
IntelliJ IDEA。 本文使用 IntelliJ IDEA Community 2018.3.4。
Azure Toolkit for IntelliJ。 请参阅安装 Azure Toolkit for IntelliJ。
安装适用于 IntelliJ IDEA 的 Scala 插件
安装 Scala 插件的步骤:
打开 IntelliJ IDEA。
在欢迎屏幕上,导航到“配置”>“插件”打开“插件”窗口。
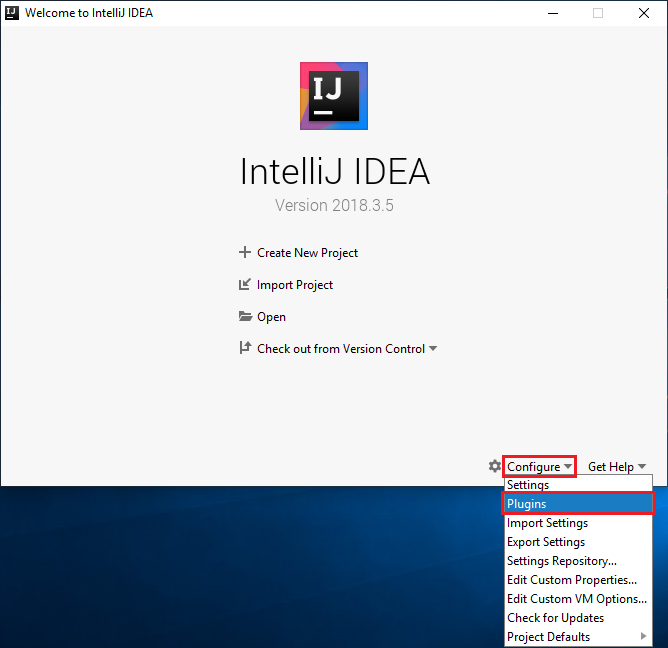
选择在新窗口中作为特色功能列出的 Scala 插件对应的“安装”。
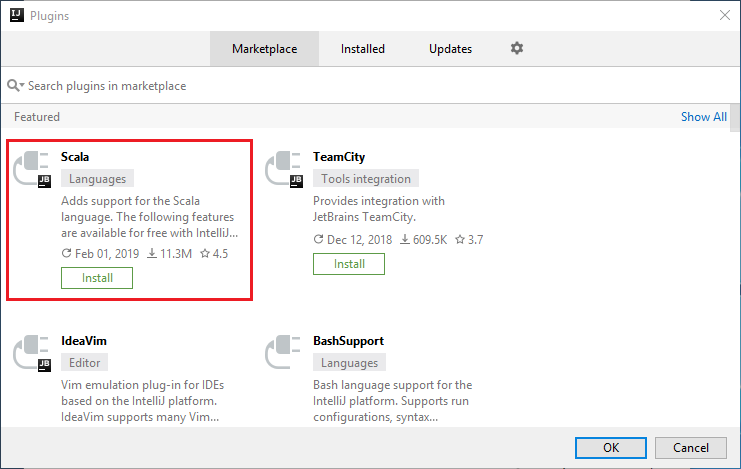
成功安装该插件后,必须重启 IDE。
为 HDInsight Spark 群集创建 Spark Scala 应用程序
启动 IntelliJ IDEA,选择“创建新项目”打开“新建项目”窗口。
在左窗格中选择“Azure Spark/HDInsight”。
在主窗口中选择“Spark 项目(Scala)”。
在“生成工具”下拉列表中选择以下任一选项:
Maven:支持 Scala 项目创建向导。
SBT:用于管理依赖项和生成 Scala 项目。
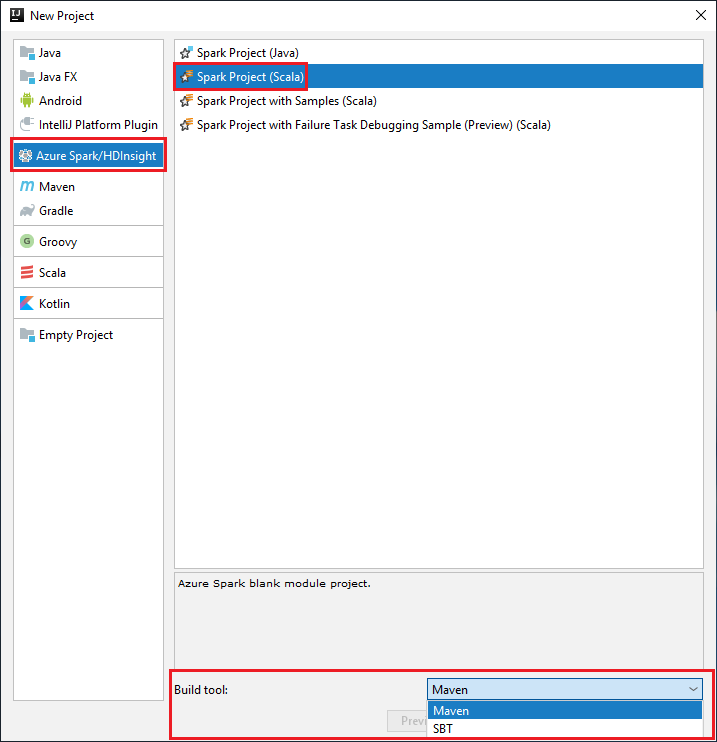
选择下一步。
在“新建项目”窗口中提供以下信息:
属性 说明 项目名称 输入名称。 本文使用的是 myApp。项目位置 输入项目保存位置。 项目 SDK 首次使用 IDEA 时,此字段可能为空。 选择“新建...”并导航到 JDK。 Spark 版本 创建向导集成了适当版本的 Spark SDK 和 Scala SDK。 如果 Spark 群集版本低于 2.0,请选择“Spark 1.x” 。 否则,请选择“Spark 2.x” 。 本示例使用“Spark 2.3.0 (Scala 2.11.8)”。 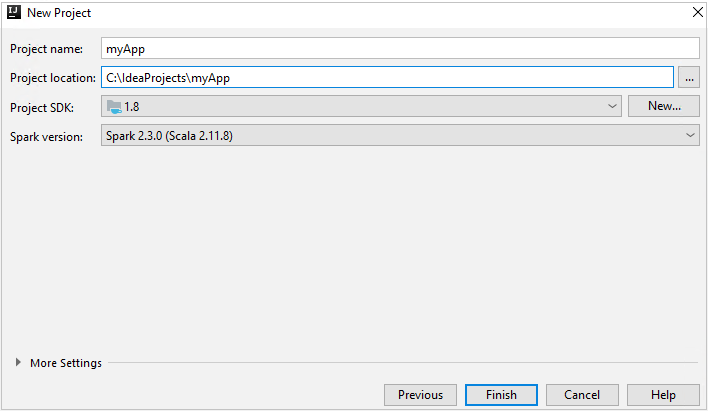
选择“完成”。 可能需要在几分钟后才会显示该项目。
Spark 项目自动为你创建项目。 要查看项目,请执行以下步骤:
a. 在菜单栏中,导航到“文件”>“项目结构...”。
b. 在“项目结构”窗口中选择“项目”。
c. 查看项目后选择“取消”。
执行以下步骤,添加应用程序源代码:
a. 在“项目”中,导航到“myApp”>“src”>“main”>“scala”。
b. 右键单击“scala”,然后导航到“新建”>“Scala 类”。
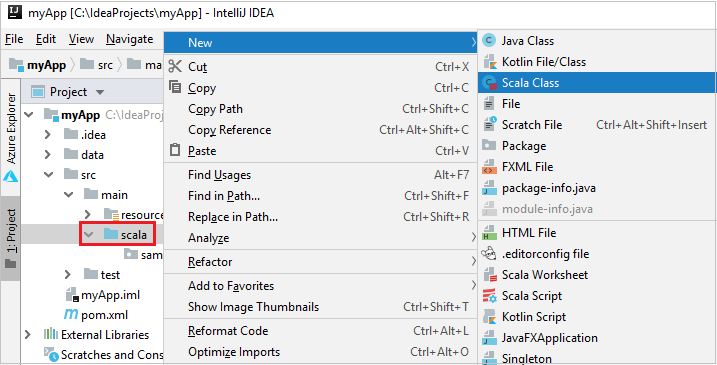
c. 在“新建 Scala 类”对话框中提供名称,在“种类”下拉列表中选择“对象”,然后选择“确定”。
d. 主视图中随后会打开 myApp.scala 文件。 将默认代码替换为以下代码:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }此代码从 HVAC.csv(用于所有 HDInsight Spark 群集)中读取数据,检索在 CSV 的第七列中只有一个数字的行,并将输出写入群集的默认存储容器下的
/HVACOut。
连接到 HDInsight 群集
用户可以登录 Azure 订阅,也可以链接 HDInsight 群集。 使用 Ambari 用户名/密码或域加入凭据连接到 HDInsight 群集。
登录到 Azure 订阅
在菜单栏中,导航到“视图”>“工具窗口”>“Azure 资源管理器”。
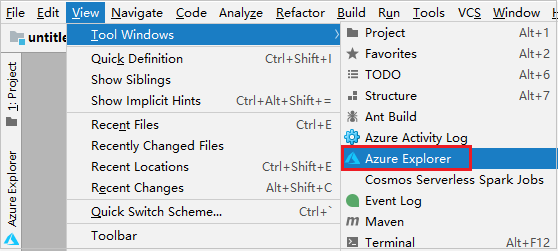
在 Azure 资源管理器中右键单击“Azure”节点,然后选择“登录”。
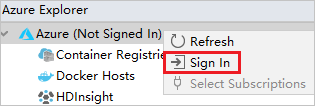
在“Azure 登录”对话框中,依次选择“设备登录”、“登录” 。
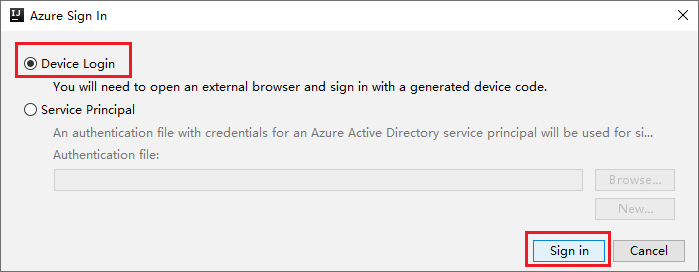
在“Azure 设备登录”对话框中单击“复制并打开”。
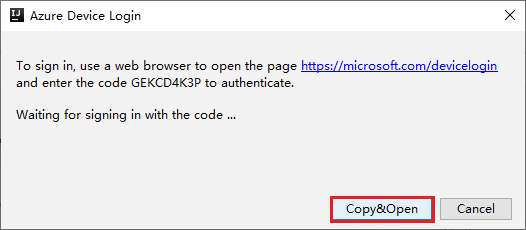
在浏览器界面中粘贴代码,然后单击“下一步”。
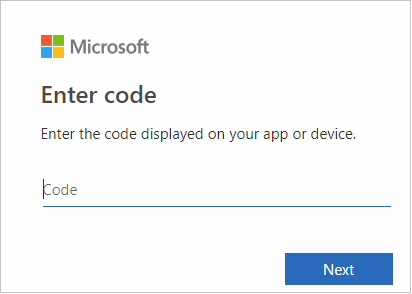
输入 Azure 凭据,然后关闭浏览器。
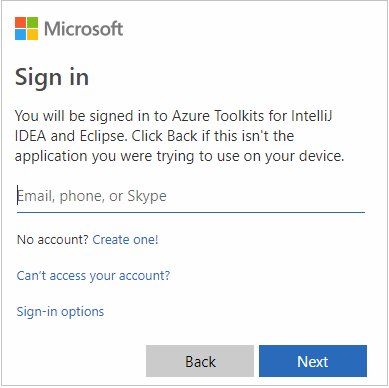
登录之后,“选择订阅”对话框会列出与凭据关联的所有 Azure 订阅。 选择你的订阅,然后选择“选择”按钮。
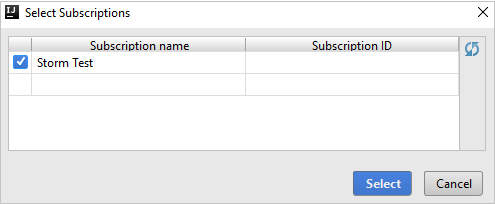
在“Azure 资源管理器”中展开“HDInsight”,查看订阅中的 HDInsight Spark 群集。
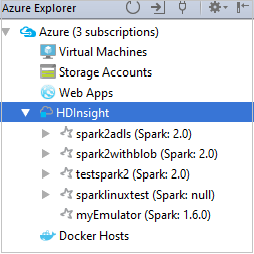
若要查看与群集关联的资源(例如存储帐户),可以进一步展开群集名称节点。
链接群集
可以使用 Apache Ambari 管理的用户名链接 HDInsight 群集。 同样,对于已加入域的 HDInsight 群集,也可使用这种域和用户名(例如 user1@contoso.com)进行链接。 也可链接 Livy 服务群集。
在菜单栏中,导航到“视图”>“工具窗口”>“Azure 资源管理器”。
在 Azure 资源管理器中右键单击“HDInsight”节点,然后选择“链接群集”。
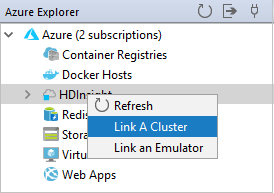
“链接群集”窗口中提供的选项根据在“链接资源类型”下拉列表中选择的值而异。 请输入自己的值,然后选择“确定”。
HDInsight 群集。
属性 Value 链接资源类型 从下拉列表中选择“HDInsight 群集”。 群集名称/URL 输入群集名称。 身份验证类型 保留“基本身份验证” 用户名 输入群集用户名,默认为 admin。 密码 输入用户名的密码。 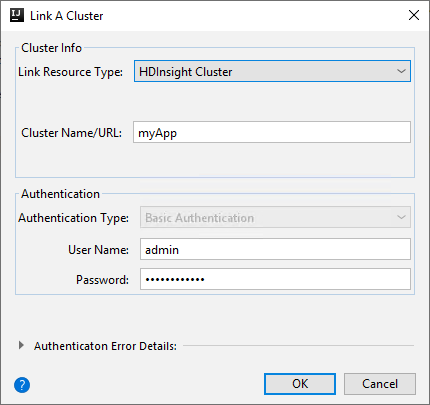
Livy 服务
属性 Value 链接资源类型 从下拉列表中选择“Livy 服务”。 Livy 终结点 输入 Livy 终结点 群集名称 输入群集名称。 Yarn 终结点 可选。 身份验证类型 保留“基本身份验证” 用户名 输入群集用户名,默认为 admin。 密码 输入用户名的密码。 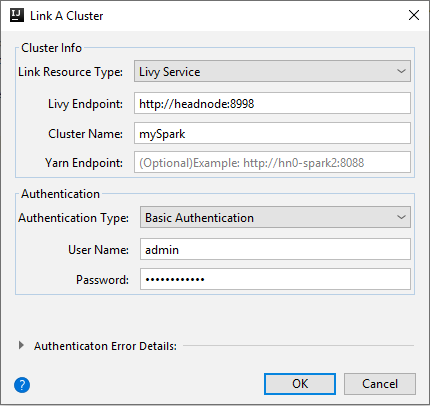
在“HDInsight”节点中可以看到链接的群集。
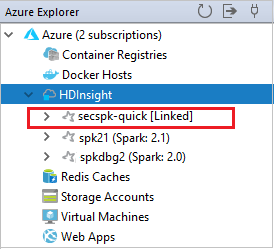
还可以从 Azure 资源管理器取消链接群集。
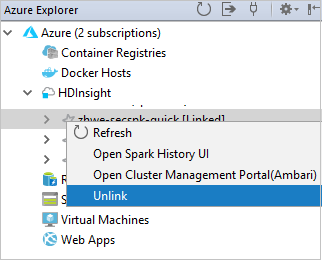
在 HDInsight Spark 群集中运行 Spark Scala 应用程序
创建 Scala 应用程序后,可将其提交到群集。
从项目中,导航到“myApp”>“src”>“main”>“scala”>“myApp” 。 右键单击“myApp”,然后选择“提交 Spark 应用程序”(可能位于列表底部)。
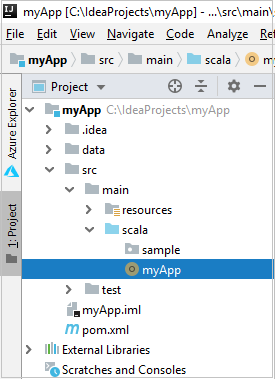
在“提交 Spark 应用程序”对话框窗口中,选择“1. Spark on HDInsight”。
在“编辑配置”窗口中提供以下值,然后选择“确定”:
属性 值 Spark 群集(仅限 Linux) 选择要在其上运行应用程序的 HDInsight Spark 群集。 选择要提交的项目 保留默认设置。 主类名 默认值是所选文件中的主类。 可以通过选择省略号图标 (...) 并选择另一个类来更改类。 作业配置 可以更改默认的键和/或值。 有关详细信息,请参阅 Apache Livy REST API。 命令行参数 如果需要,可为 main 类输入参数并以空格分隔。 引用的 Jar 和引用的文件 可以输入引用的 Jar 和引用的文件的路径(如果有)。 还可以在 Azure 虚拟文件系统中浏览文件,但目前仅支持 ADLS 第 2 代群集。 更多相关信息:Apache Spark 配置。 另请参阅如何将资源上传到群集。 作业上传存储 展开以显示其他选项。 存储类型 从下拉列表中选择“使用 Azure Blob 上传”。 存储帐户 输入存储帐户。 存储密钥 输入存储密钥。 存储容器 输入“存储帐户”和“存储密钥”后,从下拉列表中选择你的存储容器。 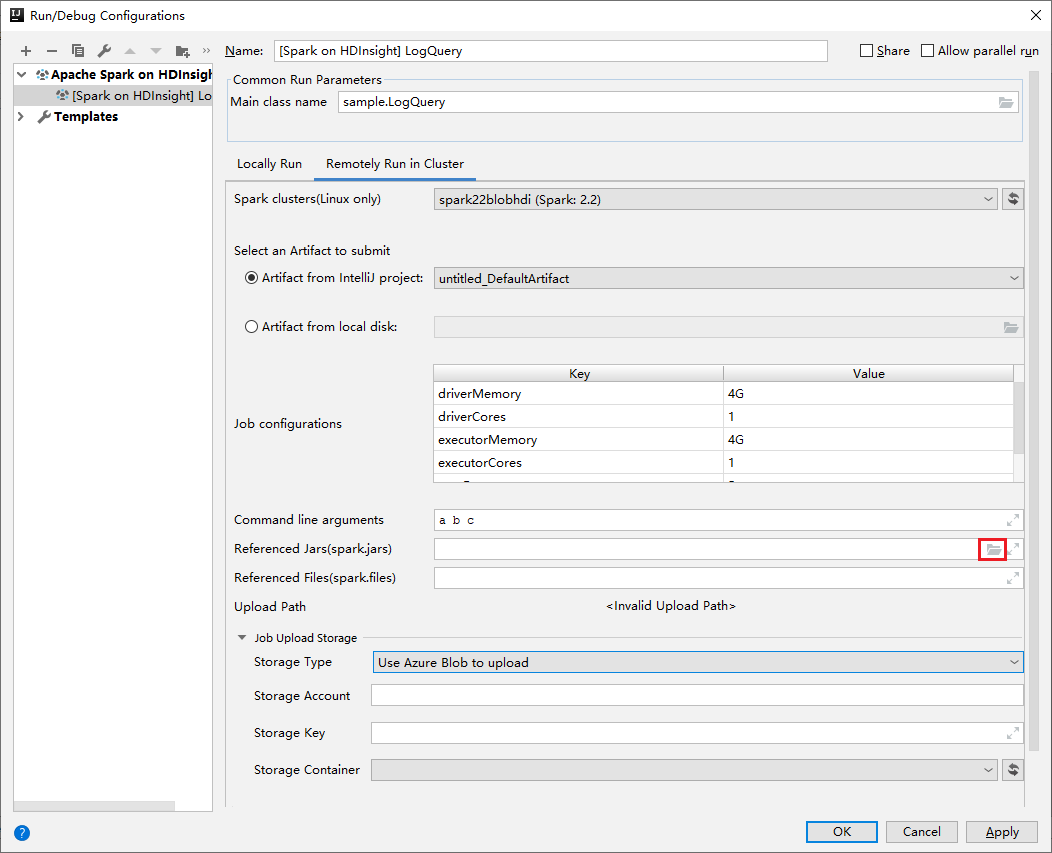
选择“SparkJobRun”将项目提交到所选群集。 底部的“群集中的远程 Spark 任务”选项卡显示作业执行进度。 通过单击红色按钮,即可停止应用程序。
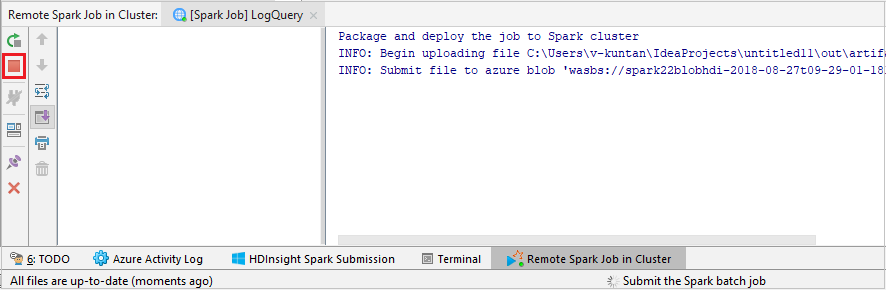
本地或远程调试 HDInsight 群集上的 Apache Spark 应用程序
我们还建议以另一种方式将 Spark 应用程序提交到群集。 为此,可在“运行/调试配置”IDE 中设置参数。 请参阅使用 Azure Toolkit for IntelliJ 通过 SSH 在本地或远程调试 HDInsight 群集上的 Apache Spark 应用程序。
使用用于 IntelliJ 的 Azure 工具包访问和管理 HDInsight Spark 群集
可以使用 Azure Toolkit for IntelliJ 执行各种操作。 大多数操作都是从“Azure 资源管理器”发起的。 在菜单栏中,导航到“视图”>“工具窗口”>“Azure 资源管理器”。
访问作业视图
在 Azure 资源管理器中,导航到“HDInsight”>“你的群集”<>>“作业”。
在右窗格中,“Spark 作业视图”选项卡显示了群集上运行的所有应用程序。 选择想要查看其详细信息的应用程序的名称。
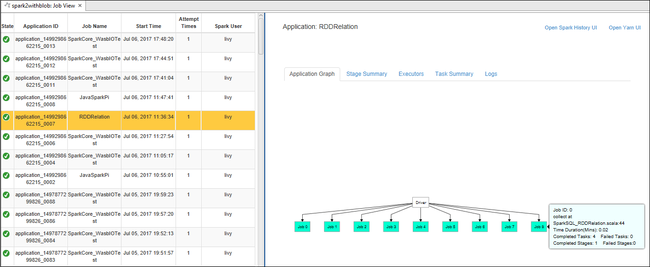
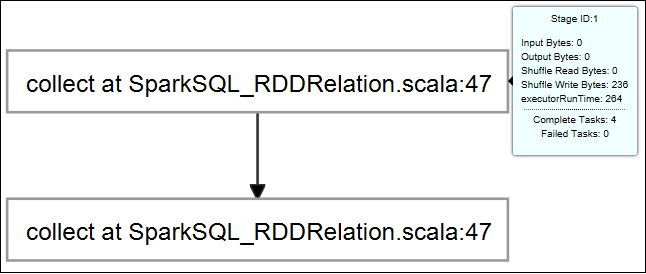
若要显示正在运行的作业的基本信息,请将鼠标悬停在作业图上。 若要查看每个作业生成的阶段图和信息,请在作业图中选择一个节点。
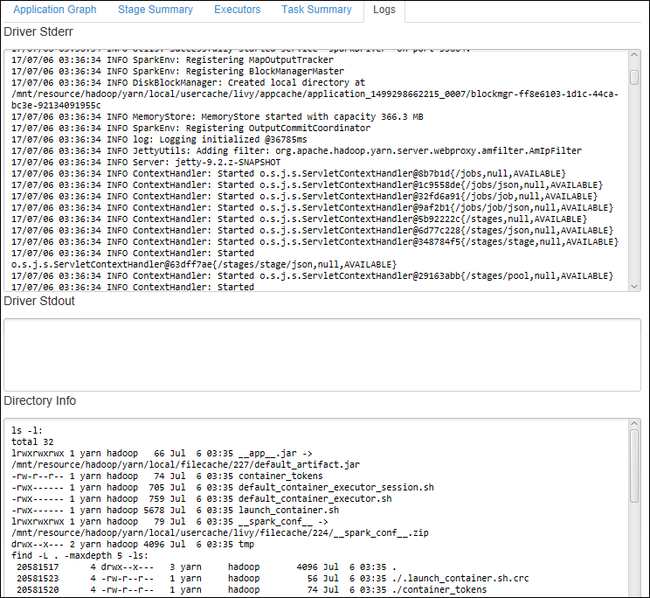
若要查看常用的日志,例如“驱动程序 Stderr”、“驱动程序 Stdout”和“目录信息”,请选择“日志”选项卡。
可以查看 Spark 历史记录 UI 和 YARN UI(应用程序级别)。 选择窗口顶部的链接。
访问 Spark 历史记录服务器
在 Azure 资源管理器中展开“HDInsight”,右键单击 Spark 群集名称,然后选择“打开 Spark 历史记录 UI”。
出现提示时,请输入群集的管理员凭据(在设置群集时已指定)。
在“Spark 历史记录服务器”仪表板上,可以使用应用程序名称查找刚运行完的应用程序。 在上述代码中,已使用
val conf = new SparkConf().setAppName("myApp")设置了应用程序名称。 Spark 应用程序名为 myApp。
启动 Ambari 门户
在“Azure 资源管理器”中展开“HDInsight”,右键单击 Spark 群集名称,然后选择“打开群集管理门户(Ambari)”。
出现提示时,请输入群集的管理员凭据。 在群集设置过程中已指定这些凭据。
管理 Azure 订阅
默认情况下,用于 IntelliJ 的 Azure 工具包将列出所有 Azure 订阅中的 Spark 群集。 如果需要,可以指定想要访问的订阅。
在 Azure 资源管理器中右键单击“Azure”根节点,然后选择“选择订阅”。
在“选择订阅”窗口中,清除不想要访问的订阅旁边的复选框,然后选择“关闭”。
Spark 控制台
可以运行 Spark 本地控制台 (Scala) 或运行 Spark Livy 交互式会话控制台 (Scala)。
Spark 本地控制台 (Scala)
确保符合 WINUTILS.EXE 先决条件。
从菜单栏中,导航到“运行”>“编辑配置...” 。
在“运行/调试配置”窗口中的左窗格内,导航到“HDInsight 上的 Apache Spark”>“[HDInsight 上的 Spark] myApp”。
在主窗口中,选择
Locally Run选项卡。提供以下值,然后选择“确定”:
属性 值 作业主类 默认值是所选文件中的主类。 可以通过选择省略号图标 (...) 并选择另一个类来更改类。 环境变量 请确认 HADOOP_HOME 的值是否正确。 WINUTILS.exe 位置 请确保路径正确。 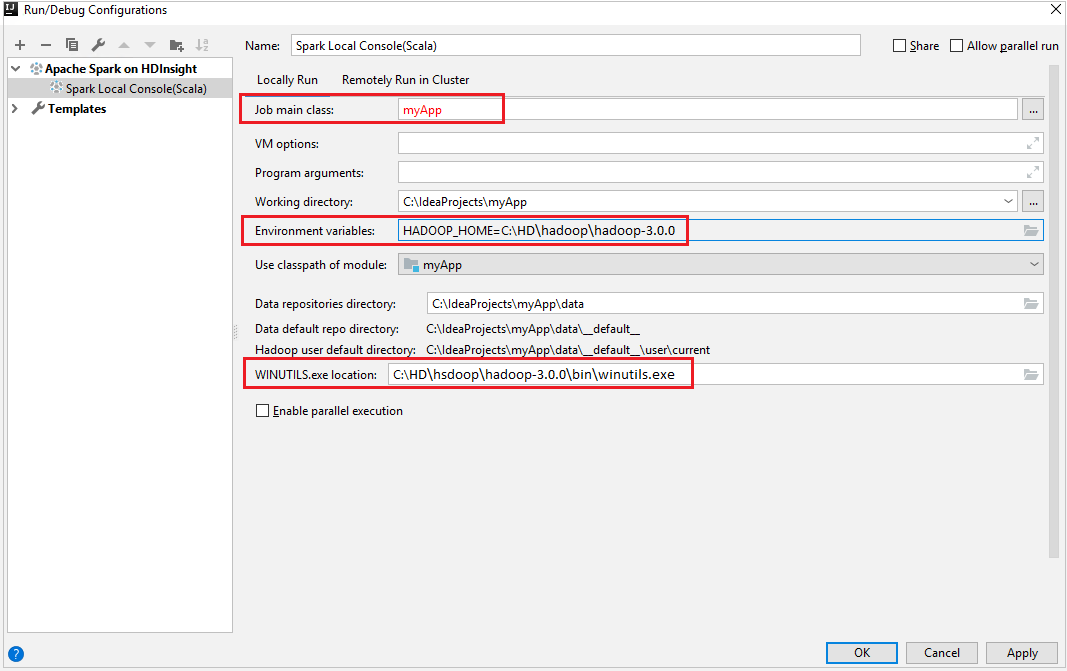
从项目中,导航到“myApp”>“src”>“main”>“scala”>“myApp” 。
从菜单栏中,导航到“工具”>“Spark 控制台”>“运行 Spark 本地控制台(Scala)” 。
然后,系统可能会显示两个对话框,询问你是否要自动修复依赖项。 如果出现对话框,请选择“自动修复”。
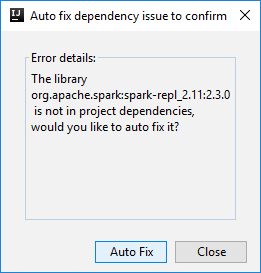
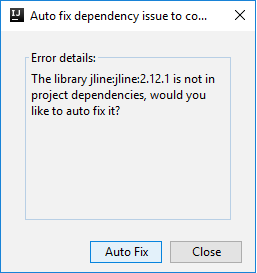
控制台应如下图所示。 在“控制台”窗口中键入
sc.appName,然后按 Ctrl+Enter。 系统将显示结果。 可以单击红色按钮来结束本地控制台。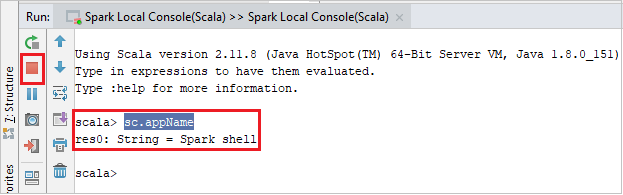
Spark Livy 交互式会话控制台 (Scala)
从菜单栏中,导航到“运行”>“编辑配置...” 。
在“运行/调试配置”窗口中的左窗格内,导航到“HDInsight 上的 Apache Spark”>“[HDInsight 上的 Spark] myApp”。
在主窗口中,选择
Remotely Run in Cluster选项卡。提供以下值,然后选择“确定”:
属性 值 Spark 群集(仅限 Linux) 选择要在其上运行应用程序的 HDInsight Spark 群集。 主类名 默认值是所选文件中的主类。 可以通过选择省略号图标 (...) 并选择另一个类来更改类。 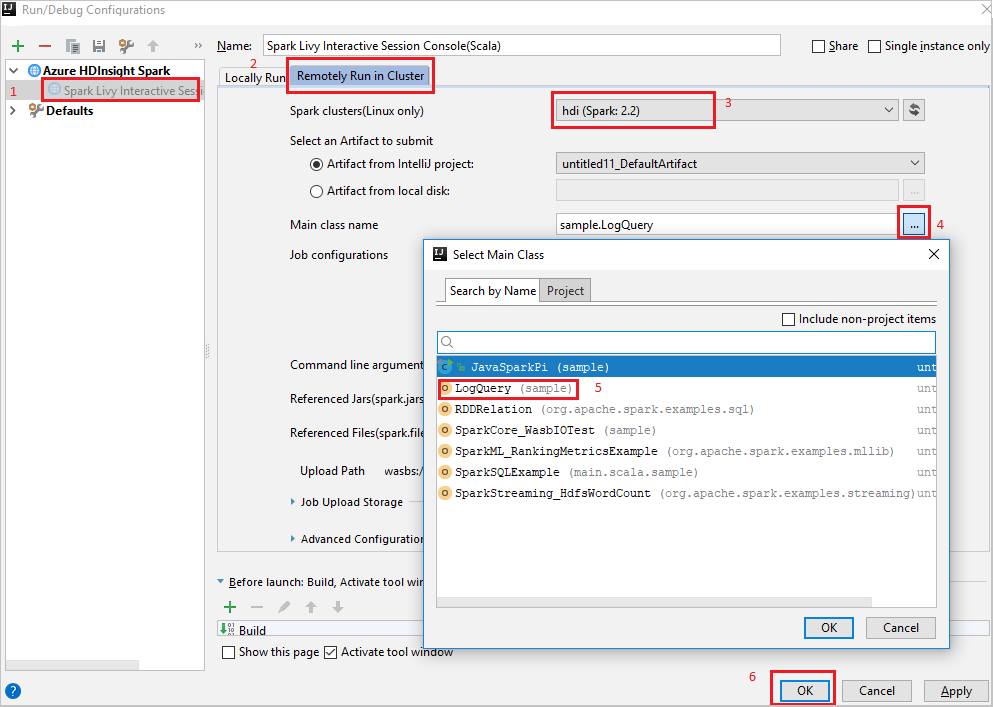
从项目中,导航到“myApp”>“src”>“main”>“scala”>“myApp” 。
从菜单栏中,导航到“工具”>“Spark 控制台”>“运行 Spark Livy 交互式会话控制台(Scala)” 。
控制台应如下图所示。 在“控制台”窗口中键入
sc.appName,然后按 Ctrl+Enter。 系统将显示结果。 可以单击红色按钮来结束本地控制台。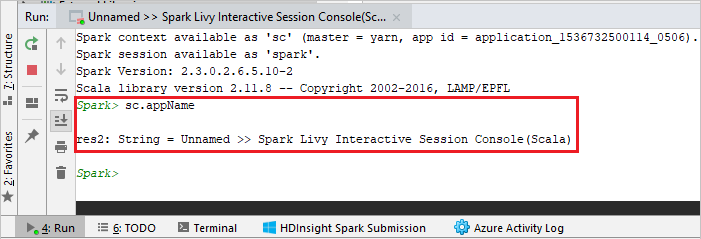
将选定内容发送到 Spark Console
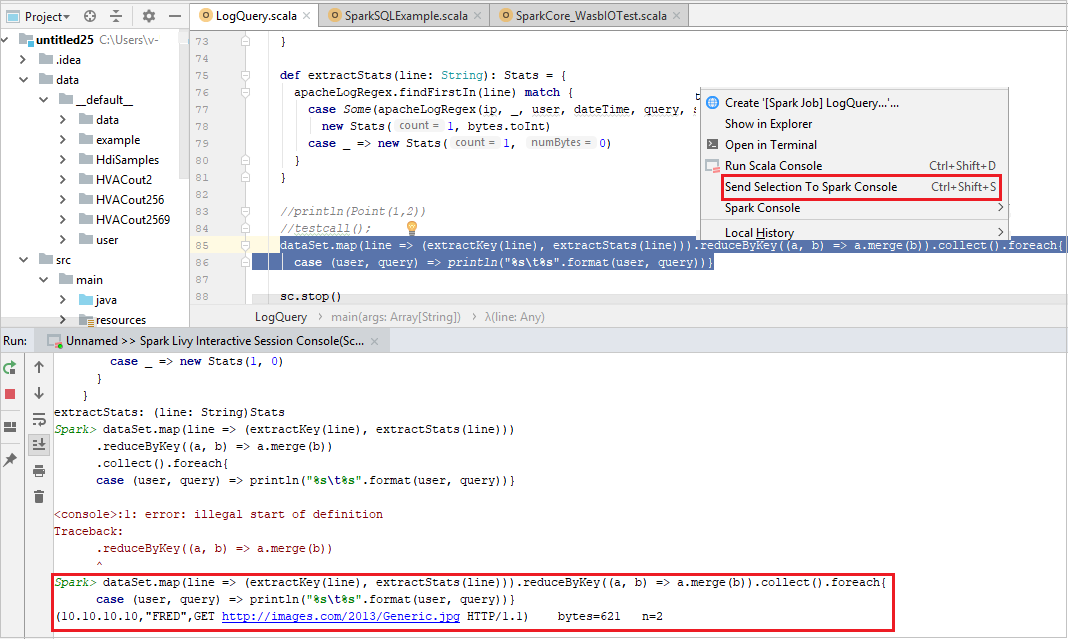
可以通过将一些代码发送到本地控制台或 Livy 交互式会话控制台 (Scala) 来方便地预测脚本结果。 可以在 Scala 文件中突出显示一些代码,然后右键单击“向 Spark 控制台发送所选内容”。 所选代码会发送到控制台。 结果将显示在控制台中的代码后面。 控制台将检查是否存在错误。
与 HDInsight Identity Broker (HIB) 集成
连接带有 ID 代理的 HDInsight ESP 群集 (HIB)
可以按照常规步骤登录到 Azure 订阅,以连接带有 ID 代理的 HDInsight ESP 群集 (HIB)。 登录后,将在 Azure 资源管理器中看到群集列表。 有关详细信息,请参阅连接到 HDInsight 群集。
在带有 ID 代理的 HDInsight ESP 群集 (HIB) 上运行 Spark Scala 应用程序
可以按照常规步骤将作业提交到带有 ID 代理的 HDInsight ESP 群集 (HIB)。 有关更多说明,请参阅在 HDInsight Spark 群集中运行 Spark Scala 应用程序。
我们会将所需的文件上传到与你的登录帐户同名的文件夹,你还可以在配置文件中看到上传路径。

带有 ID 代理的 HDInsight ESP 群集 (HIB) 上的 Spark 控制台
可以在带有 ID 代理的 HDInsight ESP 群集 (HIB) 上运行 Spark Local Console(Scala) 或运行 Spark Livy Interactive Session Console(Scala)。 如需查看更详尽的说明,请参阅 Spark 控制台。
注意
带有 ID 代理的 HDInsight ESP 群集 (HIB) 目前尚不支持链接群集以及远程调试 Apache Spark 应用程序。
仅限读取者角色
当用户使用仅限读取者的角色权限将作业提交到群集时,必须提供 Ambari 凭据。
从上下文菜单链接群集
使用仅限读取者角色帐户登录。
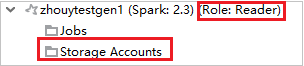
在“Azure 资源管理器”中展开“HDInsight”,查看订阅中的 HDInsight 群集。 标记为“角色:读取者”的群集只有仅限读取者角色权限。
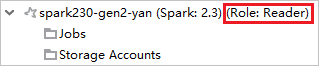
右键单击具有仅限读取者角色权限的群集。 从上下文菜单中选择“链接此群集”以链接群集。 输入 Ambari 用户名和密码。
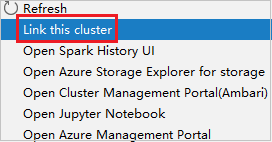
如果已成功链接群集,HDInsight 将会刷新。 群集阶段将变为链接状态。
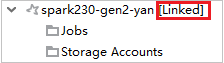
通过展开“作业”节点来链接群集
单击“作业”节点,此时会弹出“群集作业访问被拒绝”窗口。
单击“链接此群集”以链接群集。

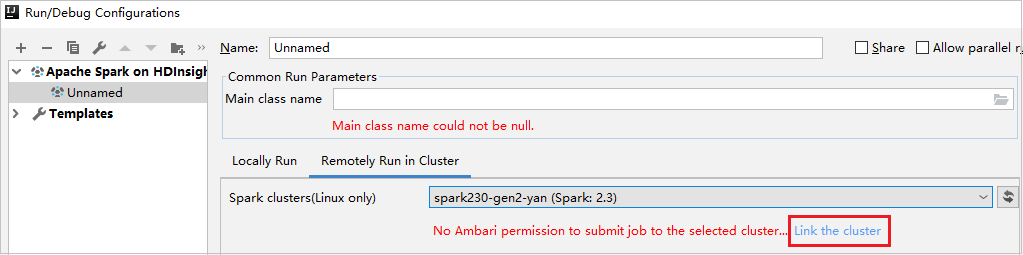
从“运行/调试配置”窗口链接群集
创建一个 HDInsight 配置。 然后选择“在群集中远程运行”。
对于“Spark 群集(仅限 Linux)”,请选择一个具有仅限读取者角色权限的群集。 此时会显示警告消息。可以单击“链接此群集”以链接群集。
查看存储帐户
对于具有仅限读取者角色权限的群集,请单击“存储帐户”节点,此时会弹出“存储访问被拒绝”窗口。 可以单击“打开 Azure 存储资源管理器”以打开存储资源管理器。

对于链接的群集,请单击“存储帐户”节点,此时会弹出“存储访问被拒绝”窗口。 可以单击“打开 Azure 存储”以打开存储资源管理器。

转换现有 IntelliJ IDEA 应用程序以使用用于 IntelliJ 的 Azure 工具包
可以转换在 IntelliJ IDEA 中创建的现有 Spark Scala 应用程序,使其与用于 IntelliJ 的 Azure 工具包兼容。 然后,可以使用该插件将应用程序提交到 HDInsight Spark 群集。
对于通过 IntelliJ IDEA 创建的现有 Spark Scala 应用程序,打开关联的
.iml文件。在根级别有一个 module 元素,如以下文本所示:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">编辑该元素以添加
UniqueKey="HDInsightTool",使 module 元素如以下文本所示:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">保存更改。 现在,应用程序应与用于 IntelliJ 的 Azure 工具包兼容。 可以通过右键单击“项目”中的项目名称来测试此项。 弹出菜单现在将包含选项“将 Spark 应用程序提交到 HDInsight”。
清理资源
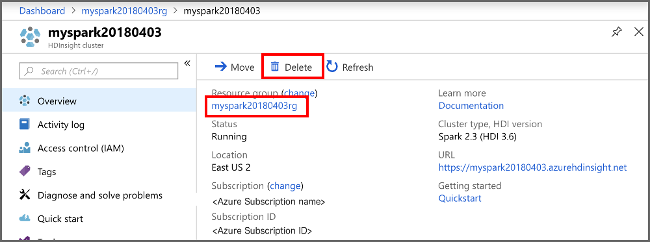
如果不打算继续使用此应用程序,请使用以下步骤删除创建的群集:
登录 Azure 门户。
在顶部的“搜索”框中,键入 HDInsight。
选择“服务”下的“HDInsight 群集” 。
在显示的 HDInsight 群集列表中,选择为本文创建的群集旁边的“…”。
选择“删除” 。 请选择“是”。
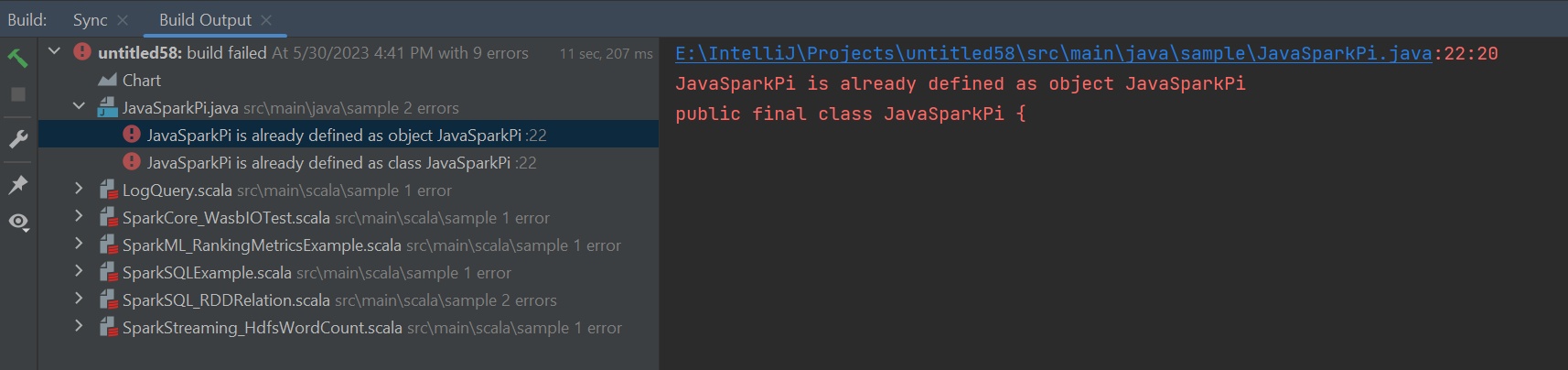
错误和解决方案
如果出现以下生成失败错误,请将 src 文件夹取消标记为“源”:
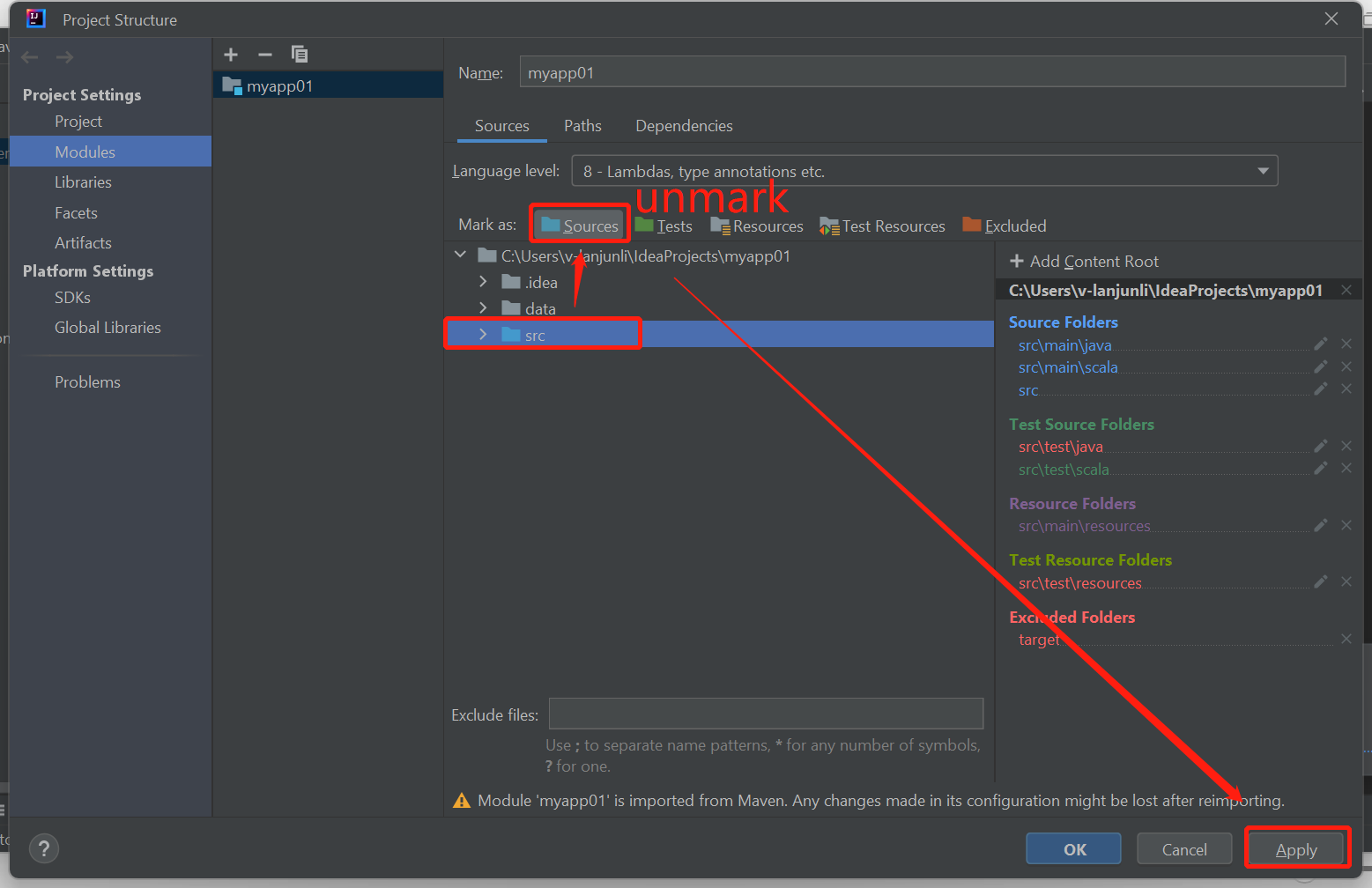
取消将 src 文件夹标记为“源”以解决此问题:
导航到“文件”,然后选择“项目结构”。
选择“项目设置”下的“模块”。
选择 src 文件并取消标记为“源”。
单击“应用”按钮,然后单击“确定”按钮关闭对话框。
后续步骤
在本文中,你已了解如何使用 Azure Toolkit for IntelliJ 插件开发以 Scala 编写的 Apache Spark 应用程序。 然后直接将其从 IntelliJ 集成开发环境 (IDE) 提交到 HDInsight Spark 群集。 请转到下一篇文章,了解如何将在 Apache Spark 中注册的数据拉取到 Power BI 等 BI 分析工具中。