本文逐步介绍如何使用 Azure Toolkit for IntelliJ 中的 HDInsight 工具远程调试 HDInsight 群集上的应用程序。
先决条件
HDInsight 上的 Apache Spark 群集。 请参阅创建 Apache Spark 群集。
对于 Windows:在 Windows 计算机上运行本地 Spark Scala 应用程序时,可能会发生 SPARK-2356 中所述的异常。 发生此异常的原因是 Windows 中缺少 WinUtils.exe。
若要解决此错误,请将 Winutils.exe 下载到某个位置(例如 C:\WinUtils\bin)。 然后,必须添加环境变量 HADOOP_HOME,并将其值设置为 C:\WinUtils。
IntelliJ IDEA(社区版免费)。
SSH 客户端。 有关详细信息,请参阅使用 SSH 连接到 HDInsight (Apache Hadoop)。
创建 Spark Scala 应用程序
启动 IntelliJ IDEA,选择“创建新项目”打开“新建项目”窗口。
在左窗格中选择“Apache Spark/HDInsight”。
在主窗口中选择“带示例的 Spark 项目(Scala)”。
在“生成工具”下拉列表中选择下列其中一项:
- Maven:支持 Scala 项目创建向导。
- SBT:用于管理依赖项和生成 Scala 项目。
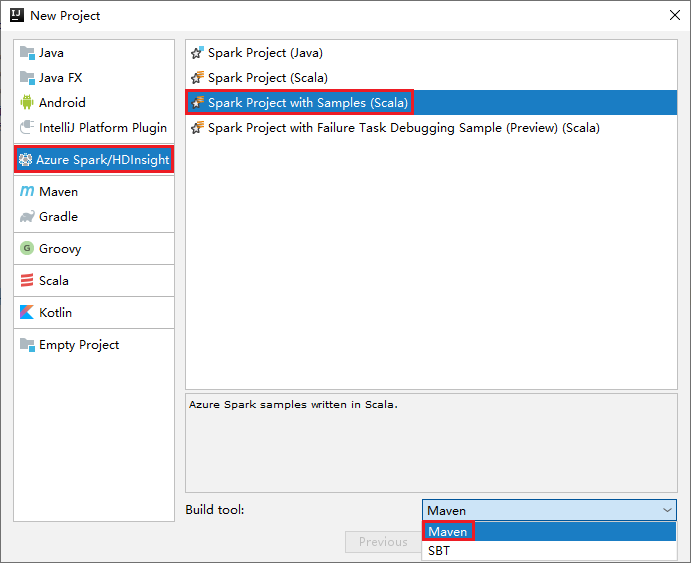
选择下一步。
在下一个“新建项目”窗口中提供以下信息:
属性 说明 项目名称 输入名称。 本演练使用 myApp。项目位置 输入所需的位置用于保存项目。 项目 SDK 如果为空,请选择“新建...”并导航到 JDK。 Spark 版本 创建向导集成了适当版本的 Spark SDK 和 Scala SDK。 如果 Spark 群集版本低于 2.0,请选择“Spark 1.x”。 否则,选择“Spark 2.x.”。 本示例使用“Spark 2.3.0 (Scala 2.11.8)”。 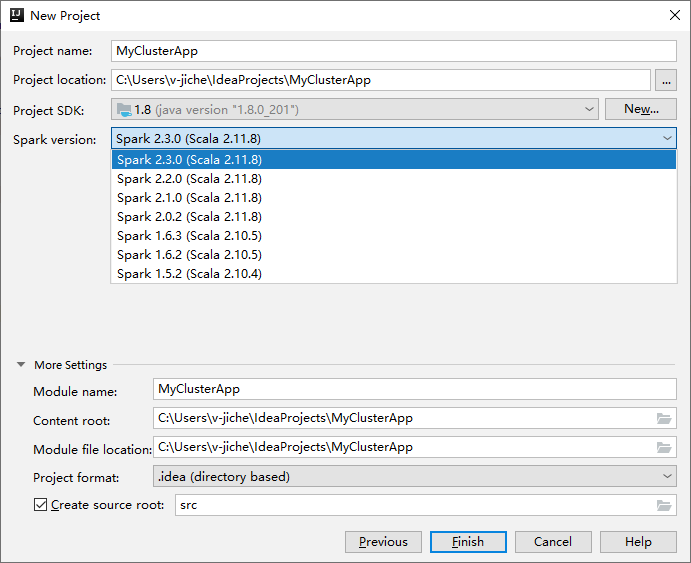
选择“完成”。 可能需要在几分钟后才会显示该项目。 观看右下角的进度。
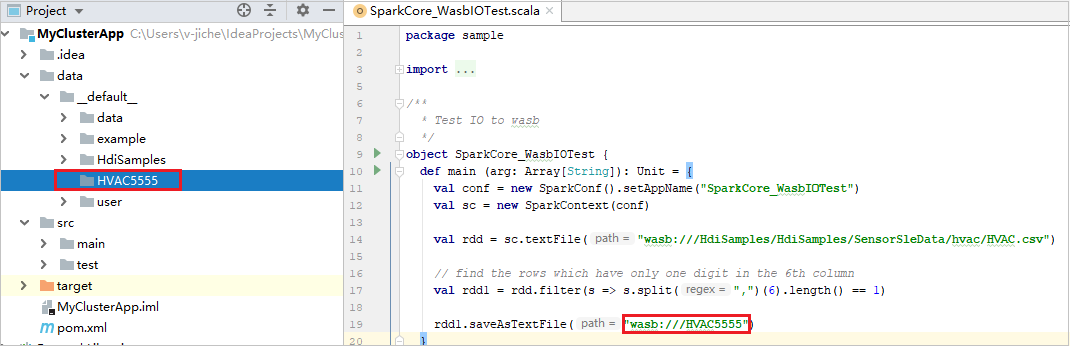
展开项目,然后导航到 src>main>scala>sample。 双击“SparkCore_WasbIOTest”。
执行本地运行
在 SparkCore_WasbIOTest 脚本中,右键单击脚本编辑器,然后选择“运行 'SparkCore_WasbIOTest'”选项来执行本地运行。
本地运行完成后,可以看到输出文件保存到当前的项目资源管理器的“数据”“默认”中 。
执行本地运行和本地调试时,工具已自动设置默认的本地运行配置。 打开右上角的“[HDInsight 上的 Spark] XXX”配置,可以看到已在“HDInsight 上的 Apache Spark”下创建了“[HDInsight 上的 Spark]XXX” 。 切换到“本地运行”选项卡。
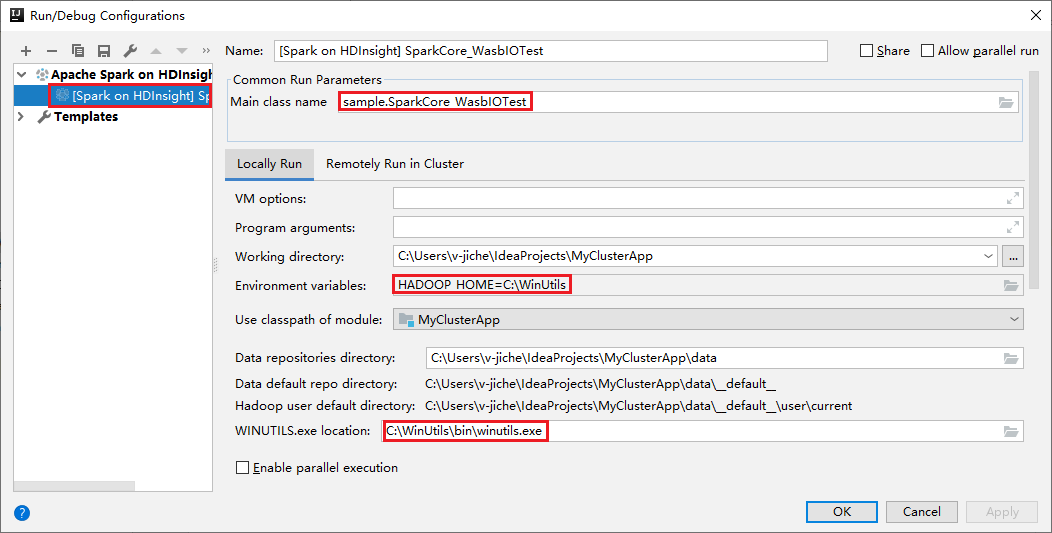
- 环境变量:如果已将系统环境变量 HADOOP_HOME 设置为 C:\WinUtils,则它可自动检测到此设置,而无需手动添加此变量。
- WinUtils.exe 位置:如果尚未设置此系统环境变量,则可单击其按钮找到它的位置。
- 只需选择两个选项之一,在 macOS 和 Linux 上不需要它们。
也可在执行本地运行和本地调试前手动设置此配置。 在前面的屏幕截图中,选择加号(“+”)。 然后选择“HDInsight 上的 Apache Spark”选项。 输入“名称”、“主类名称” 信息并保存,然后单击本地运行按钮。
执行本地调试
打开“SparkCore_wasbloTest”脚本,设置断点。
右键单击脚本编辑器,然后选择“调试‘[HDInsight 上的 Spark]XXX’”选项来执行本地调试。
执行远程运行
导航到“运行”“编辑配置...” 。通过此菜单可以创建或编辑远程调试的相关配置。
在“运行/调试配置”对话框中,选择加号 ()。 然后选择“HDInsight 上的 Apache Spark”选项。
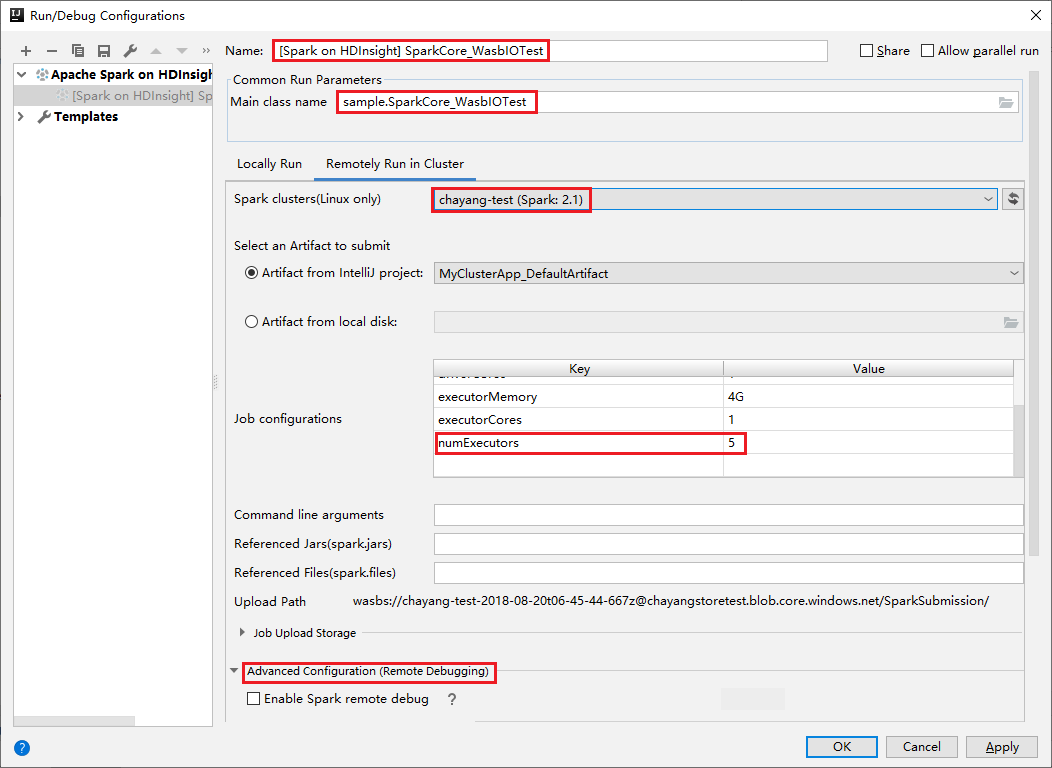
切换到“在群集中远程运行”选项卡。为“名称”、“Spark 群集” 和“Main 类名”输入信息。 然后单击“高级配置(远程调试)”。 工具支持使用“执行器”进行调试。 numExecutors,默认值为 5。 设置的值最好不要大于 3。
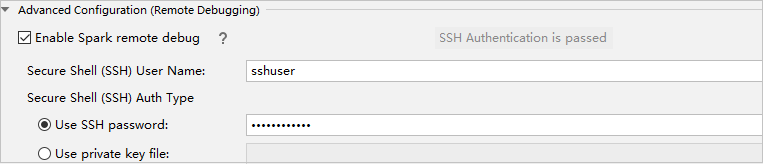
在“高级配置(远程调试)”部分,选择“启用 Spark 远程调试”。 输入 SSH 用户名,然后输入密码或使用私钥文件。 若要执行远程调试,则需要设置它。 若只想使用远程运行,则无需设置它。
现已使用提供的名称保存配置。 若要查看配置详细信息,请选择配置名称。 若要进行更改,请选择“编辑配置”。
完成配置设置后,可以针对远程群集运行项目,或执行远程调试。

单击“断开连接”按钮,这样,提交日志就不显示在左面板中。 但是,它仍在在后端上运行。
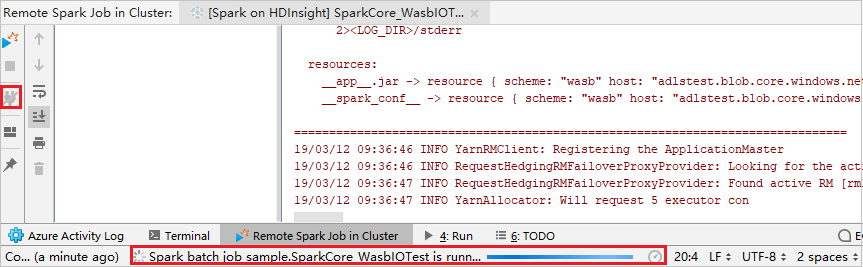
执行远程调试
设置断点,然后单击“远程调试”图标。 与远程提交的区别是需要配置 SSH 用户名/密码。

程序执行到达断点时,会在“调试程序”窗格中显示一个“驱动程序”选项卡和两个“执行程序”选项卡。 选择“恢复程序”图标继续运行代码,这会到达下一个断点。 需要切换到正确的“执行程序”选项卡,以找到目标执行程序来进行调试。 可以在相应的“控制台”选项卡上查看执行日志。
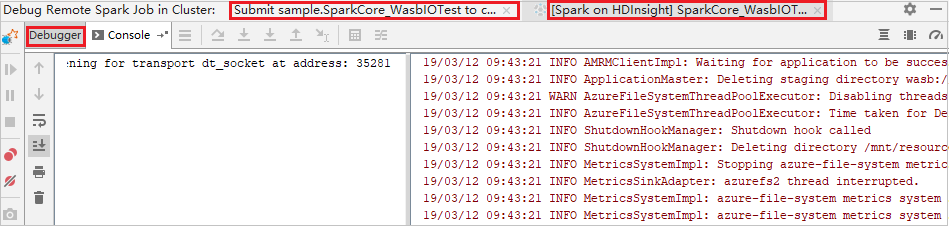
执行远程调试和 bug 修复
设置两个断点,然后选择“调试”图标启动远程调试过程。
代码在第一个断点处停止,“变量”窗格中显示参数和变量信息。
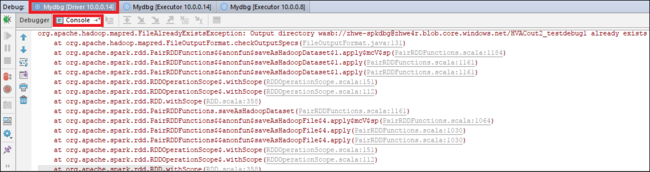
选择“恢复程序”图标继续运行。 代码在第二个断点处停止。 按预期方式捕获异常。
IntelliJ 在调试远程 Spark 作业时引发错误。
再次选择“恢复程序”图标。 “HDInsight Spark 提交”窗口随即显示“作业运行失败”错误。
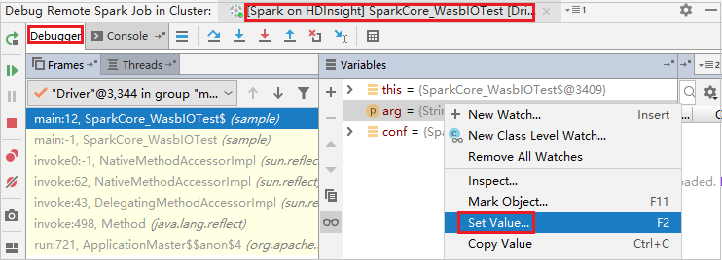
要使用 IntelliJ 调试功能动态更新变量值,请再次选择“调试”。 “变量”窗格会再次出现。
在“调试”选项卡上右键单击目标,选择“设置值”。 接下来,输入变量的新值。 然后按 Enter 保存该值。
选择“恢复程序”图标继续运行程序。 这一次不会捕获到异常。 可以看到,项目已成功运行,未出现任何异常。
IntelliJ 无例外地调试远程 Spark 任务。
后续步骤
方案
- Apache Spark 与 BI:使用 HDInsight 中的 Spark 和 BI 工具执行交互式数据分析
- Apache Spark 与机器学习:通过 HDInsight 中的 Spark 使用 HVAC 数据分析建筑物温度
- Apache Spark 与机器学习:使用 HDInsight 中的 Spark 预测食品检查结果
- 使用 HDInsight 中的 Apache Spark 分析网站日志
创建和运行应用程序
工具和扩展
- 使用 Azure Toolkit for IntelliJ 为 HDInsight 群集创建 Apache Spark 应用程序
- 使用 Azure Toolkit for IntelliJ 通过 VPN 远程调试 Apache Spark 应用程序
- 使用 Azure Toolkit for Eclipse 中的 HDInsight 工具创建 Apache Spark 应用程序
- 在 HDInsight 上的 Apache Spark 群集中使用 Apache Zeppelin 笔记本
- 在 HDInsight 的 Apache Spark 群集中可用于 Jupyter Notebook 的内核
- 将外部包与 Jupyter Notebook 配合使用
- Install Jupyter on your computer and connect to an HDInsight Spark cluster(在计算机上安装 Jupyter 并连接到 HDInsight Spark 群集)