本文介绍在 Azure HDInsight 群集中使用 Apache Spark 组件时出现的问题的故障排除步骤和可能的解决方案。
场景:Apache Spark 的 OutOfMemoryError 异常
问题
Apache Spark 应用程序失败并出现 OutOfMemoryError 未经处理的异常。 你可能会收到如下所示的错误消息:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
原因
此异常的最可能原因是未将足够的堆内存分配给 Java 虚拟机 (JVM)。 这些 JVM 作为 Apache Spark 应用程序的执行程序或驱动程序启动。
解决方法
确定 Spark 应用程序要处理的数据大小上限。 根据输入数据的最大大小、转换输入数据时生成的中间数据,以及进一步转换中间数据时生成的输出数据来估算大小。 如果初始估算值不足,请略微增大大小并反复调整,直到内存错误消减。
请确保要使用的 HDInsight 群集具有足够的内存和核心资源,以便能够适应 Spark 应用程序。 若要确定资源是否足够,可以在群集的 YARN UI 的“群集指标”部分查看“已用内存”、“内存总计”、“已用 VCore 数”和“VCore 总数”的值 。

将以下 Spark 配置设置为适当的值。 使应用程序要求与群集中的可用资源相互平衡。 这些值不应超过 YARN 所识别到可用内存和核心数的 90%,此外应满足 Spark 应用程序的最低内存要求:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)所有执行程序使用的内存总量 =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)驱动程序使用的内存总量 =
spark.driver.memory + spark.yarn.driver.memoryOverhead
场景:尝试打开 Apache Spark 历史记录服务器时出现 Java 堆空间错误
问题
打开 Spark 历史记录服务器中的事件时收到以下错误:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
原因
此问题的常见原因是打开大型 Spark 事件文件时缺少资源。 Spark 堆大小默认设置为 1 GB,但大型 Spark 事件文件所需的大小可能超过此值。
若要验证你要尝试加载的文件的大小,可执行以下命令:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
解决方法
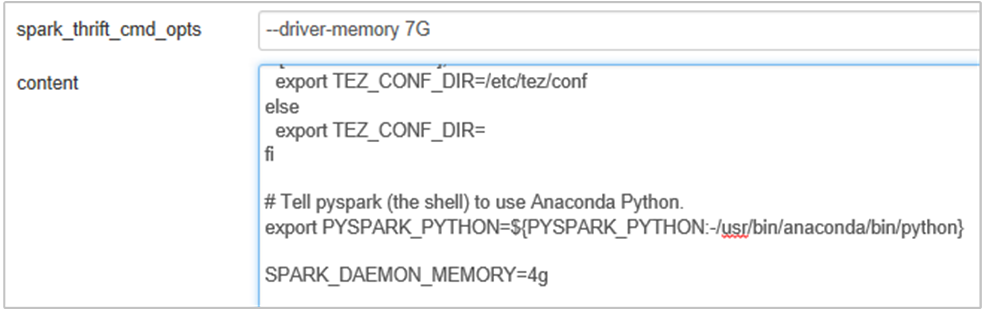
可以通过编辑 Spark 配置中的 SPARK_DAEMON_MEMORY 属性并重启所有服务,来增大 Spark 历史记录服务器的内存。
为此,可在 Ambari 浏览器 UI 中选择“Spark2/Config/Advanced spark2-env”部分。
添加以下属性,以将 Spark 历史记录服务器内存从 1G 更改为 4G:SPARK_DAEMON_MEMORY=4g。
请确保在 Ambari 中重启所有受影响的服务。
场景:Livy 服务器无法在 Apache Spark 群集上启动
问题
Livy 服务器无法在 Apache Spark [Linux 上的 Spark 2.1 (HDI 3.6)] 上启动。 尝试重启会在 Livy 日志中导致以下错误堆栈:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.chinacloudapp.cn:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.chinacloudapp.cn:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.chinacloudapp.cn:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
原因
java.lang.OutOfMemoryError: unable to create new native thread 突出显示了 OS 无法将更多的本机线程分配给 JVM。 已确认此异常是由于违反每个进程的线程计数限制而导致的。
当 Livy 服务器意外终止时,与 Spark 群集建立的所有连接也会终止,这意味着,所有作业和相关数据都会丢失。 HDP 2.6 中引入了会话恢复机制,Livy 现在会将会话详细信息存储到 Zookeeper 中,Livy 服务器恢复正常后,可以恢复这些信息。
如果通过 Livy 提交了大量作业,Livy 服务器的高可用性功能会将这些会话状态存储到 ZK 中(在 HDInsight 群集上),并在 Livy 服务重启后恢复这些会话。 意外终止后重启时,Livy 将为每个会话创建一个线程,这会累积一些待恢复会话,从而导致创建过多的线程。
解决方法
使用以下步骤删除所有条目。
使用以下命令获取 Zookeeper 节点的 IP 地址
grep -R zk /etc/hadoop/conf上述命令列出了群集的所有 Zookeeper
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.chinacloudapp.cn:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.chinacloudapp.cn:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.chinacloudapp.cn:2181</value>使用 ping 获取 Zookeeper 节点的所有 IP 地址,或者使用 Zookeeper 名称从头节点连接到 Zookeeper
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181连接到 Zookeeper 后,执行以下命令列出尝试重启的所有会话。
在大多数情况下,此列表可能包含 8000 个以上的会话####
ls /livy/v1/batch以下命令删除所有待恢复会话。 #####
rmr /livy/v1/batch
等待以上命令完成并且光标返回到提示符,然后在 Ambari 中重启 Livy 服务。这应该可以解决问题。
注意
在 Livy 会话完成其执行后,对其运行 DELETE。 Spark 应用完成后,不会立即自动删除 Livy 批处理会话,这是设计使然。 Livy 会话是 POST 请求针对 Livy REST 服务器创建的实体。 需要调用 DELETE 才能删除该实体。 或者,我们应等待 GC 介入。
后续步骤
如果你的问题未在本文中列出,或者无法解决问题,请访问以下渠道之一获取更多支持:
如果需要更多帮助,可以从 Azure 门户提交支持请求。 从菜单栏中选择“支持” ,或打开“帮助 + 支持” 中心。 有关更多详细信息,请参阅如何创建 Azure 支持请求。 Microsoft Azure 订阅中带有对订阅管理和计费支持的访问权限,技术支持通过 Azure 支持计划之一提供。