本文介绍如何优化 Apache Spark 群集的内存管理,以在 Azure HDInsight 上获得最佳性能。
概述
Spark 通过在内存中放置数据来运行。 因此,管理内存资源是优化 Spark 作业执行的关键方面。 可通过以下几种方法来有效地利用群集内存。
- 在分区策略中,优先选择较小的数据分区,并考虑数据的大小、类型和分布。
- 考虑较新的、更高效的
Kryo data serialization,而不是使用默认的 Java 序列化。 - 优先使用 YARN,因为它通过批处理来分隔
spark-submit。 - 监视和优化 Spark 配置设置。
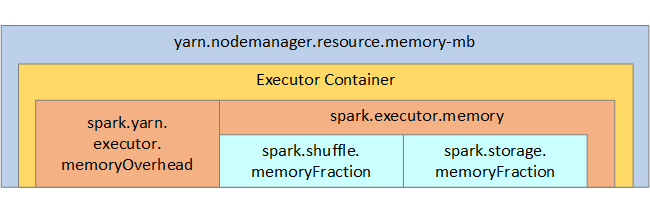
下图展示了 Spark 内存结构和一些键执行程序内存参数供用户参考。
Spark 内存注意事项
如果使用 Apache Hadoop YARN,则 YARN 控制每个 Spark 节点上所有容器使用的内存。 关系图中显示了关键对象及其关系。
若要解决显示“内存不足”消息的问题,请尝试:
- 查看 DAG 管理重排。 通过映射端化简减少内存使用,对源数据进行预分区(或 Bucket 存储化),最大化单个数据重组,以及减少发送的数据量。
- 首选具有固定内存限制的
ReduceByKey,而GroupByKey提供聚合、窗口化和其他功能,但其内存限制是无限的。 - 首选在执行程序或分区上执行更多工作的
TreeReduce,而不是在驱动程序上执行所有工作的Reduce。 - 使用数据帧,而不是较低级别的 RDD 对象。
- 创建用于封装操作(比如“Top N”、各种聚合或窗口化操作)的复杂类型。
有关其他故障排除步骤,请参阅 Azure HDInsight 中 Apache Spark 的 OutOfMemoryError 异常。