本文介绍 Azure 机器学习设计器中的一个组件。 使用“从文本中提取 N 元特征”组件可以特征化非结构化文本数据。
“从文本中提取 N 元特征”组件的配置
该组件支持以下使用 N 元字典的方案:
从一列自由文本创建新的 N 元语法字典。
使用一组现有文本特征抽取自由文本列的特征。
创建新的 N 元语法字典
将“从文本中提取 N 元特征”组件添加到管道,并连接包含要处理的文本的数据集。
使用“文本列”选择包含要提取的文本的字符串类型列。 由于结果冗长,一次只能处理一个列。
将“词汇模式”设置为“创建”,以指示你正在创建 N 元语法特征的新列表 。
设置“N 元语法大小”,以指示要提取和存储的 N 元语法的最大大小。
例如,如果输入 3,则将创建一元语法、双元语法和三元语法。
加权函数指定如何构建文档特征向量以及如何从文档中提取词汇。
二进制权重:将二进制状态值分配给提取的 N 元语法。 如果文档中存在 N 元语法,则其值为 1;否则为 0。
TF 权重:将词频 (TF) 分数分配给提取的 N 元语法。 每个 N 元语法的值是其在文档中的出现频率。
IDF 权重:将反转文件频率 (IDF) 分数分配给提取的 N 元语法。 每个 N 元语法的值是语料库大小的对数除以其在整个语料库中的出现频率。
IDF = log of corpus_size / document_frequencyTF-IDF 权重:将词频/反转文件频率 (TF/IDF) 分数分配给提取的 N 元语法。 每个 N 元语法的值是其 TF 分数乘以其 IDF 分数。
将“最小字长”设置为可以在 N 元语法的任意单字中使用的最小字符数。
使用“最大字长”设置可在 N 元语法的任意单字中使用的最大字符数。
默认情况下,每个字或令牌最多可包含 25 个字符。
使用“最小 N 元语法文件绝对频率”来设置 N 元语法字典中包含的任何 N 元语法所需的最小出现次数。
例如,如果使用默认值 5,则任何 N 元语法都必须在语料库中至少出现 5 次,才会被包含在 N 元语法字典中。
将“最大 N 元语法文件比率”设置为包含一种特定 N 元语法的行数占语料库中总行数的最大比率。
例如,比率为 1,则表示即使每行中都有特定的 N 元语法,也可以将 N 元语法添加到 N 元语法字典中。 通常,将每一行中都出现的字视为干扰词,需将其删除。 若要筛选掉领域相关干扰词,请尝试降低此比率。
重要
特定字的出现率不一致。 它因文件而异。 例如,如果要分析有关特定产品的客户评论,则产品名的频率可能会非常高且接近干扰词,但它在其他上下文中是一个重要的术语。
选择选项“标准化 N 元语法特征向量”以标准化特征向量。 如果启用此选项,则每个 N 元语法特征向量除以其 L2 范数。
提交管道。
使用现有的 N 元语法字典
将“从文本中提取 N 元特征”组件添加到管道,并将包含要处理的文本的数据集连接到“数据集”端口。
使用“文本列”选择包含要抽取特征的文本的文本列。 默认情况下,该组件会选择字符串类型的所有列。 为了获得最佳结果,请一次处理一个列。
添加已保存的数据集,其中包含之前生成的 N 元语法字典,并将其连接到“输入词汇”端口。 还可以连接“从文本中提取 N 元特征”组件的上游实例的“结果词汇”输出。
对于“词汇模式”,请从下拉列表中选择“只读”更新选项 。
“只读”选项表示输入词汇的输入语料库。 按原样应用输入词汇中的 N 元语法权重,而不是从新文本数据集(左侧输入)计算词频。
提示
如果要对文本分类器进行评分,请使用此选项。
对于所有其他选项,请参阅上一节中的属性说明。
提交管道。
构建使用 N 元语法的推理管道来部署实时终结点
一个训练管道包含“从文本提取 N 元语法特征”和用于对测试数据集进行预测的“评分模型”,该管道采用以下结构 :
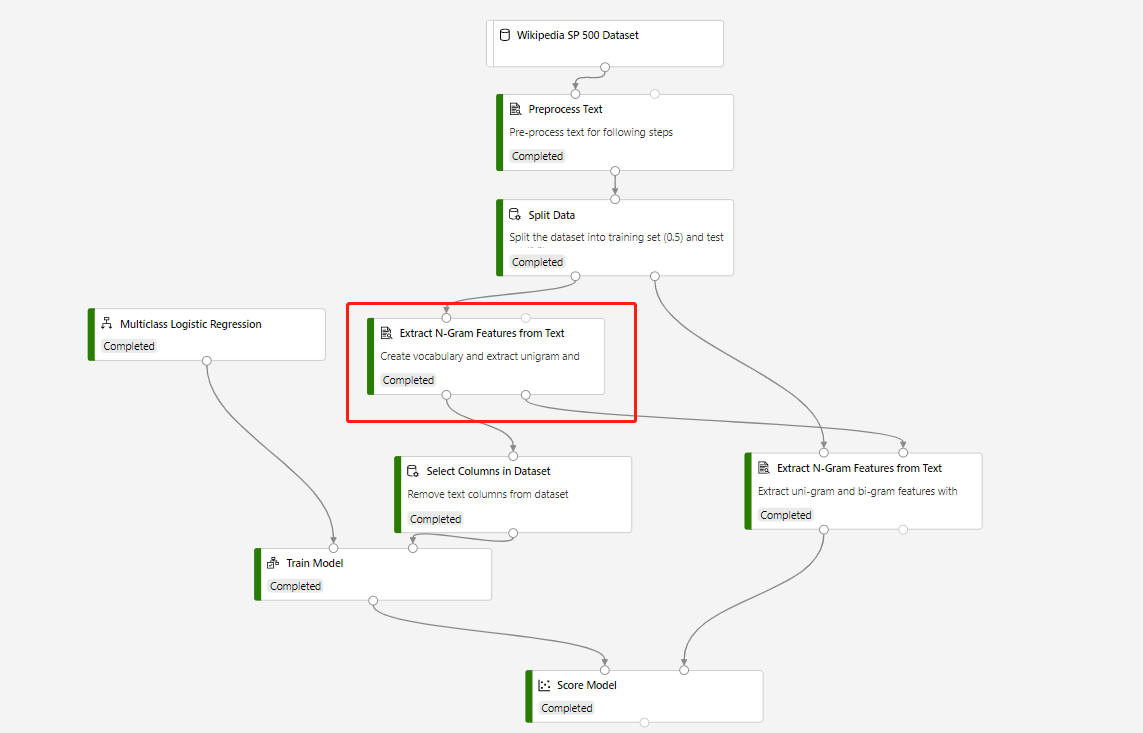
圈住的“从文本中提取 N 元特征”组件的“词汇模式”为“创建”,连接到“评分模型”组件的组件的“词汇模式”为“只读” 。
成功提交上面的训练管道后,可以将圈住组件的输出注册为数据集。
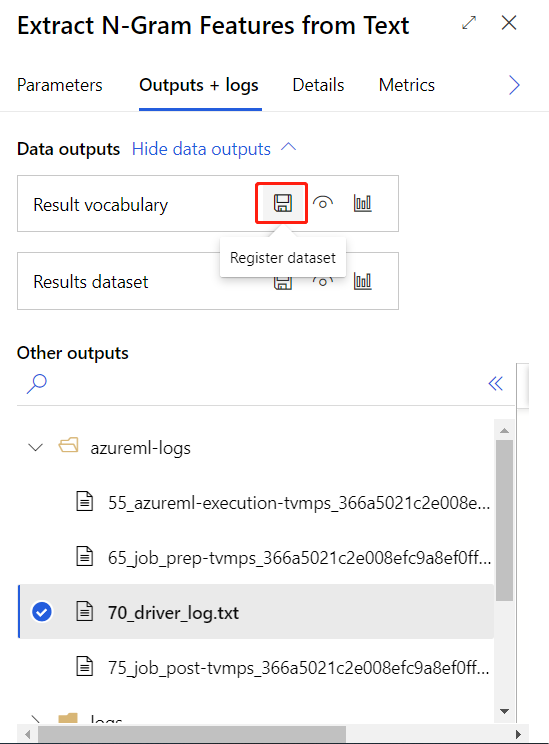
然后便可创建实时推理管道。 创建推理管道后,需要进行手动调整,如下所示:
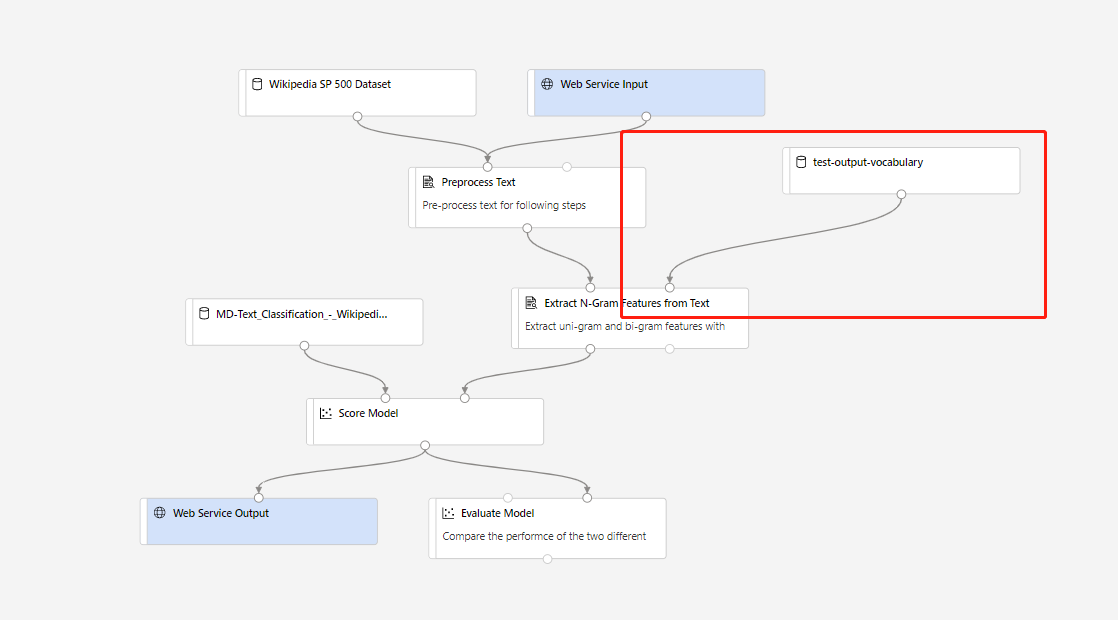
然后,提交推理管道并部署实时终结点。
结果
“从文本中提取 N 元特征”组件创建两种类型的输出:
结果数据集:此输出总结了与提取的 N 元语法结合的经分析文本。 未在“文本列”选项中选择的列选项将传递到输出。 对于分析的每一列文本,该组件会生成以下列:
- N 元实例矩阵:该组件为整个数据集中找到的每个 N 元特征生成一列,并在每列中添加一个分数以指示该行的 N 元权重。
结果词汇:词汇包含实际的 N 元语法字典,以及在分析过程中生成的词频分数。 可保存数据集,以便重用于另一组输入,或用于稍后更新。 还可以重用词汇进行建模和评分。
结果词汇
词汇包含 N 元语法字典,还包含在分析过程中生成的词频分数。 无论其他选项如何,都将生成 DF 和 IDF 分数。
- ID:为每个唯一 N 元语法生成的标识符。
- nGram:N 元语法。 空格或其他断字符将替换为下划线字符。
- DF:原始语料库中 N 元语法的词频分数。
- IDF:原始语料库中 N 元语法的反转文件频率分数。
可以手动更新此数据集,但可能会引入错误。 例如:
- 如果该组件在输入词汇中发现具有相同键的重复行,则会引发错误。 请确保词汇中任意两行都不具有相同的字。
- 词汇数据集的输入架构必须完全匹配,包括列名和列类型。
- ID 列和 DF 列必须是整数类型 。
- IDF 列必须是浮点类型。
注意
请不要将数据输出直接连接到“训练模型”组件。 应删除自由文本列,以免它们被馈送到训练模型。 否则,自由文本列将被视为分类特征。
后续步骤
请参阅 Azure 机器学习可用的组件集。