适用范围: Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
训练机器学习模型或管道或从模型目录中查找合适的模型后,需要将其部署到生产环境,供其他人用于 推理。 推理是将新的输入数据应用于机器学习模型或管道,再生成输出的过程。 虽然这些输出通常称为“预测”,但推理可以为其他机器学习任务(如分类和聚类分析)生成输出。 在 Azure 机器学习中,使用 终结点执行推理。
终结点和部署
终结点是稳定且持久的 URL,可用于请求或调用模型。 向终结点提供所需的输入并接收输出。 Azure 机器学习支持标准部署、联机终结点和批处理终结点。 终结点提供:
- 稳定且持久的 URL(如 endpoint-name.region.inference.studio.ml.azure.cn)
- 身份验证机制
- 授权机制
部署是托管执行实际推理的模型或组件所需的一组资源和计算。 终结点包含部署。 对于联机终结点和批处理终结点,一个终结点可以包含多个部署。 部署可以托管独立的资产,并根据资产的需求使用不同的资源。 终结点还有一种路由机制,可将请求定向到其任何部署。
Azure 机器学习中的某些类型的终结点在其部署上使用专用资源。 若要运行这些终结点,你必须在 Azure 订阅上具有计算配额。 但是,某些模型支持无服务器部署,这样它们就可以从订阅中不使用配额。 对于无服务器部署,会根据使用情况计费。
直觉
假设你正在处理一个应用程序,该应用程序预测照片中汽车的类型和颜色。 对于此应用程序,具有特定凭据的用户向 URL 发出 HTTP 请求,并在请求中提供了一张汽车图片。 作为回报,用户会收到一个响应,其中包含汽车的类型和颜色作为字符串值。 在这一场景中,URL 起到了终结点的作用。
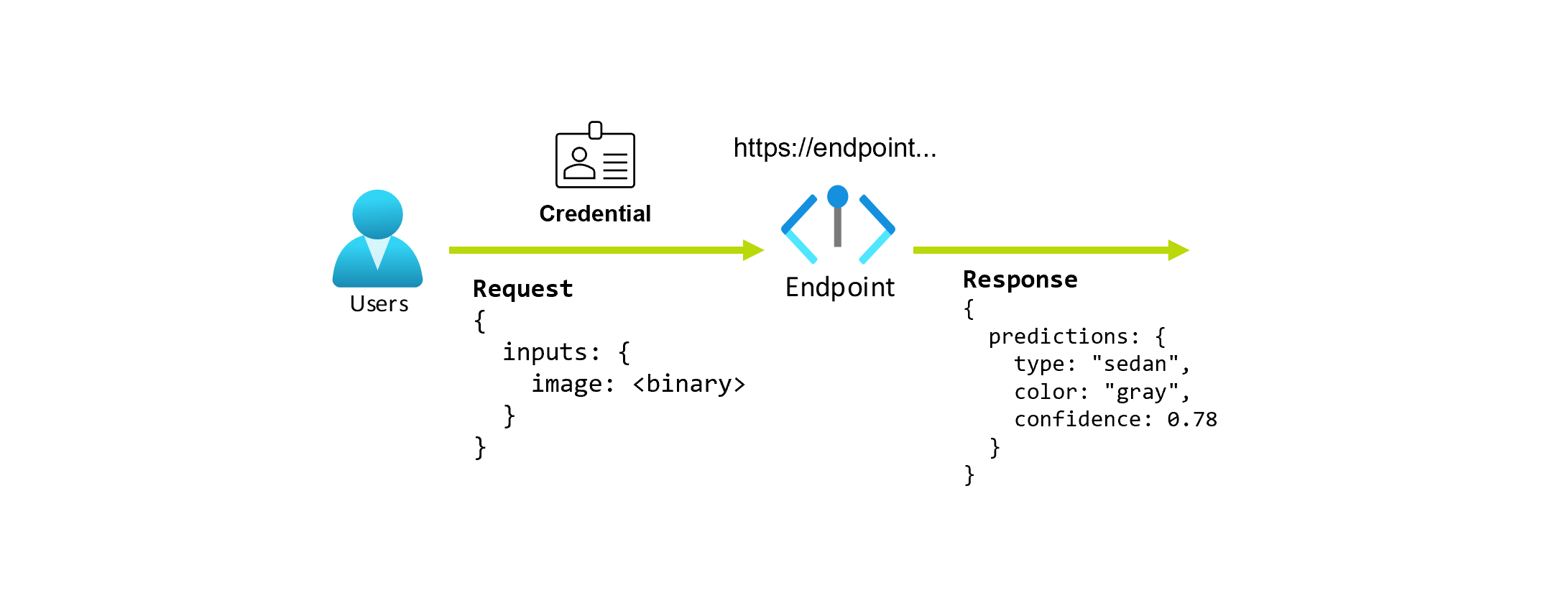
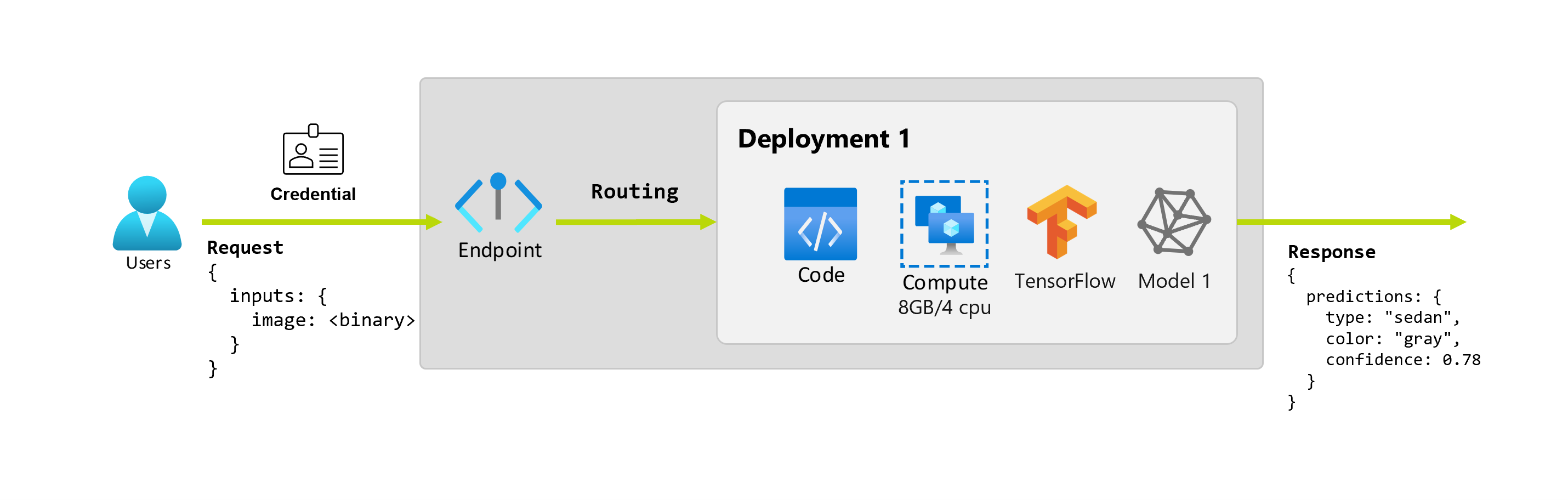
现在假设数据科学家 Alice 正在实现该应用程序。 Alice 具有广泛的 TensorFlow 体验,并决定使用来自 TensorFlow 中心的 ResNet 体系结构的 Keras 顺序分类器实现模型。 测试模型后,Alice 对其结果感到满意,并决定使用模型来解决汽车预测问题。 该模型很大,需要 8 GB 内存和 4 个核心才能运行。 在此方案中,Alice 的模型和资源(如代码和计算)需要在 终结点下运行模型。
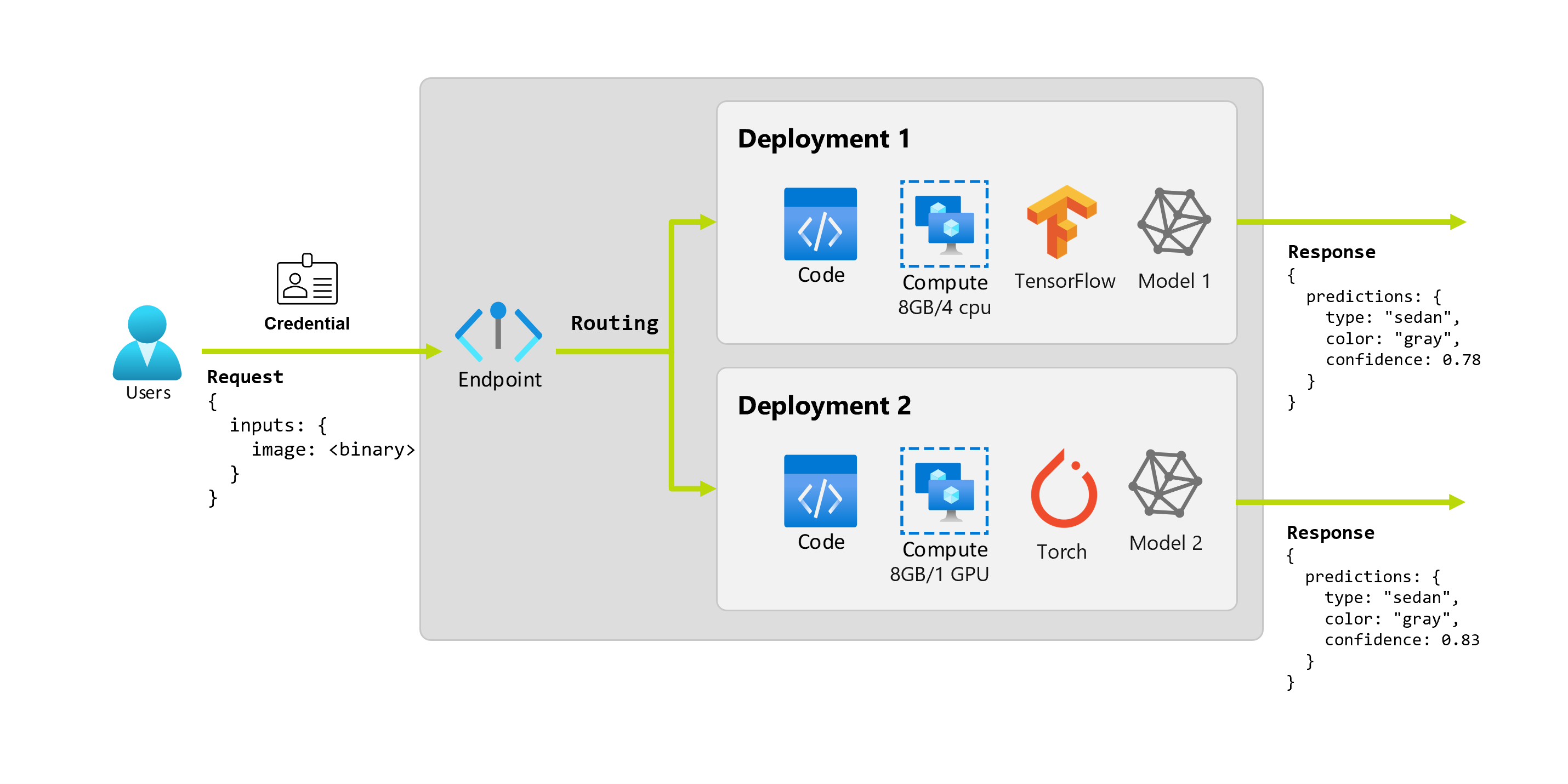
几个月后,组织发现应用程序在照明条件不佳的图像上表现不佳。 另一位数据科学家 Bob 在数据扩充技术方面具有专业知识,可帮助模型为这一因素构建稳健性。 但是,Bob 更喜欢使用 PyTorch 实现模型,并使用 PyTorch 训练新模型。 Bob 希望逐步在生产中测试此模型,直到组织准备好停用旧模型。 新模型在部署到 GPU 时性能也更好,因此部署需要包含 GPU。 在此方案中,Bob 的模型和资源(如代码和计算)在 相同的终结点下构成另一个部署。
终结点:联机和批处理
联机终结点 旨在进行实时推理。 每当调用终结点时,将在终结点的响应中返回结果。 无服务器 API 终结点不消耗订阅中的配额;而是采用即用即付的计费方式。
批处理终结点是为长时间运行的批量推理设计的。 调用批处理终结点时,会生成执行实际工作的批处理作业。
何时使用联机终结点和批处理终结点
联机终结点:
使用联机终结点来操作处理同步低延迟请求中的实时推理的模型。 建议在下列情况下使用它们:
- 你没有低延迟要求。
- 你的模型可以在相对较短的时间内响应请求。
- 模型的输入适合请求的 HTTP 有效负载。
- 你需要根据请求数量进行纵向扩展。
批处理终结点:
使用批处理终结点来使模型或管道可操作化,以便处理长时间运行的异步推理。 建议在下列情况下使用它们:
- 你具有需要较长时间才能运行的高开销模型或管道。
- 你希望操作机器学习管道并重用组件。
- 需要对分布在多个文件中的大量数据执行推理。
- 没有低延迟要求。
- 你的模型的输入存储在存储帐户或 Azure 机器学习数据资产中。
- 可以利用并行化。
联机终结点和批处理终结点对比图
联机终结点和批处理终结点都基于终结点的概念,因此,你可轻松地从一个终结点过渡到另一个终结点。 联机终结点和批处理终结点还能够管理同一终结点的多个部署。
终结点
下表显示了联机终结点和批处理终结点中不同功能的总结。
| 功能 | 联机终结点 | Batch 终结点 |
|---|---|---|
| 稳定的调用 URL | 是 | 是 |
| 支持多部署 | 是 | 是 |
| 部署的路由 | 流量拆分 | 切换到默认值 |
| 镜像流量以安全推出 | 是 | 否 |
| Swagger 支持 | 是 | 否 |
| 身份验证 | 密钥和 Microsoft Entra ID(预览版) | Microsoft Entra ID |
| 专用网络支持(旧版) | 是 | 是 |
| 托管网络隔离 | 是 | 是(请参阅所需的其他配置) |
| 客户管理的密钥 | 是 | 是 |
| 成本基础 | 无 | 无 |
部署
下表显示了在部署级别联机终结点和批处理终结点中不同功能的总结。 这些概念适用于终结点下的每个部署。
| 功能 | 联机终结点 | Batch 终结点 |
|---|---|---|
| 部署类型 | 模型 | 模型和管道组件 |
| MLflow 模型部署 | 是 | 是 |
| 自定义模型部署 | 是,使用评分脚本 | 是,使用评分脚本 |
| 推理服务器 2 | - Azure 机器学习推理服务器 -海卫一 - 自定义(使用 BYOC) |
批量推理 |
| 消耗的计算资源 | 实例或精细资源 | 群集实例 |
| 计算类型 | 托管计算和 Kubernetes | 托管计算和 Kubernetes |
| 低优先级计算 | 否 | 是 |
| 将计算缩放为零 | 否 | 是 |
| 自动缩放计算3 | 是,基于资源使用情况 | 是,基于作业计数 |
| 产能过剩管理 | 限制 | 队列 |
| 成本基础4 | 每个部署:正在运行的计算实例 | 每个作业:作业中使用的计算实例(限制为群集的最大实例数)。 |
| 部署的本地测试 | 是 | 否 |
2推理服务器 是指采用请求、处理请求和创建响应的服务技术。 推理服务器还规定输入和预期输出的格式。
3自动缩放 是能够根据部署的负载动态纵向扩展或缩减部署的已分配资源。 联机部署和批处理部署使用不同的自动缩放策略。 联机部署根据资源利用率(如 CPU、内存、请求等...)进行纵向扩展和缩减,而批处理终结点根据创建的作业数进行纵向扩展或缩减。
4 由消耗的资源收取联机部署和批量部署费用。 在联机部署中,资源是在部署时预配的。 在批处理部署中,资源不会在部署时使用,而是在作业运行时使用。 因此,批部署本身没有相关的成本。 同样,已排队的作业也不会消耗资源。
开发人员接口
终结点旨在帮助组织在 Azure 机器学习中操作生产级工作负载。 终结点是可靠且可缩放的资源,提供实现 MLOps 工作流的最佳能力。
可以使用多个开发人员工具来创建和管理批处理终结点与联机终结点:
- Azure CLI 和 Python SDK
- Azure 资源管理器/REST API
- Azure 机器学习工作室 Web 门户
- Azure 门户(IT/管理员)
- 使用 Azure CLI 接口和 REST/ARM 接口支持 CI/CD MLOps 管道