适用范围: Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
本文介绍如何在 Azure 机器学习中创建和管理数据资产。
当你需要以下功能时,可以使用数据资产:
- 版本控制:数据资产支持数据版本控制。
- 可再现性:数据资产版本一经创建,便是不可变的, 无法修改或删除。 因此,可再现使用数据资产的训练作业或管道。
- 可审核性:由于数据资产版本是不可变的,因此可跟踪资产版本以及更新版本的人员/时间。
- 世系:对于任何给定的数据资产,可查看哪些作业或管道使用了数据。
- 易于使用:Azure 机器学习数据资产与 Web 浏览器书签(收藏夹)类似。 可以创建数据资产版本,然后使用易记名称(例如 )访问该资产版本,而不必记住引用 Azure 存储上的常用数据的长存储路径 (URI)。
提示
若要在交互式会话(例如 Notebook)或作业中访问数据,无需提前创建数据资产。 可以使用数据存储 URI 来访问数据。 数据存储 URI 提供了一种访问数据以开始使用 Azure 机器学习的简单方法。
先决条件
若要创建和使用数据资产,需要做好以下准备:
创建数据资产
创建数据资产时,需要设置数据资产类型。 Azure 机器学习支持三种数据资产类型:
| 类型 | API | 规范场景 |
|---|---|---|
|
File 引用单个文件 |
uri_file |
读取 Azure 存储上的单个文件(该文件可采用任何格式)。 |
|
文件夹 引用文件夹 |
uri_folder |
将 parquet/CSV 文件的文件夹读取到 Pandas/Spark 中。 读取文件夹中的非结构化数据(图像、文本、音频等)。 |
|
表 引用数据表 |
mltable |
架构很复杂,可能会频繁更改,或者需要大型表格数据的一部分。 使用表的 AutoML。 读取分布在多个存储位置的非结构化数据(图像、文本、音频等)。 |
注意
仅当将数据注册为 MLTable 时,才在 csv 文件中使用嵌入式换行符。 阅读数据时,csv 文件中嵌入的换行符可能会导致字段值不对齐。 MLTable 在 support_multi_line 转换中具有 ,以便将带引号的换行符解释为一条记录。
在 Azure 机器学习作业中使用数据资产时,可以将资产 装载 或 下载 到计算节点。 有关详细信息,请访问模式。
此外,还必须指定指向数据资产位置的 path 参数。 支持的路径包括:
| 位置 | 示例 |
|---|---|
| 本地计算机上的路径 | ./home/username/data/my_data |
| 数据存储上的路径 | azureml://datastores/<data_store_name>/paths/<path> |
| 公共 https 服务器上的路径 | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Azure 存储上的路径 | (Blob) wasbs://<containername>@<accountname>.blob.core.chinacloudapi.cn/<path_to_data>/(ADLS gen2) abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/<path> (ADLS gen1) adl://<accountname>.azuredatalakestore.net/<path_to_data>/ |
注意
从本地路径创建数据资产时,它将自动上传到默认的 Azure 机器学习云数据存储。
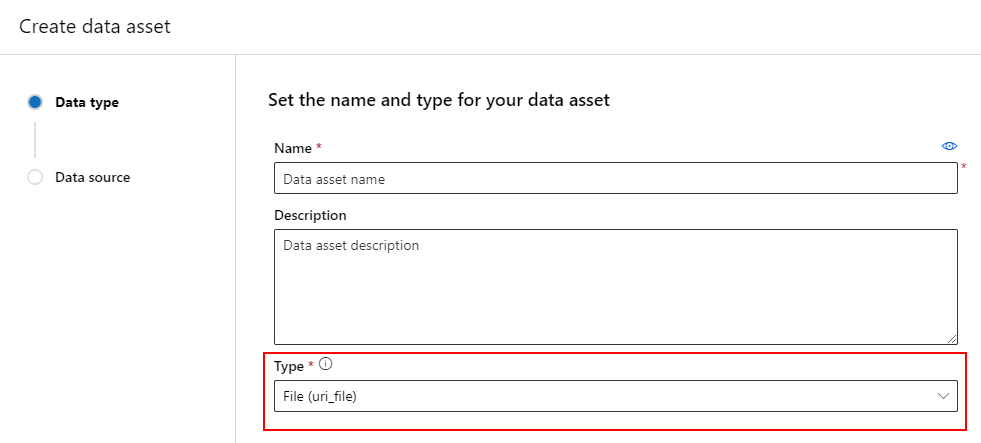
创建数据资产:文件类型
类型为“文件”(uri_file) 的数据资产指向存储上的单个文件(例如 CSV 文件)。 可使用以下方法创建文件类型的数据资产:
创建 YAML 文件并复制粘贴以下代码片段。 请务必使用以下内容更新 <> 占位符:
- 数据资产的名称
- 版本
- description
- 指向支持位置上的单个文件的路径
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.chinacloudapi.cn/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
接下来,在 CLI 中执行以下命令。 请务必将 <filename> 占位符更新为 YAML 文件名。
az ml data create -f <filename>.yml
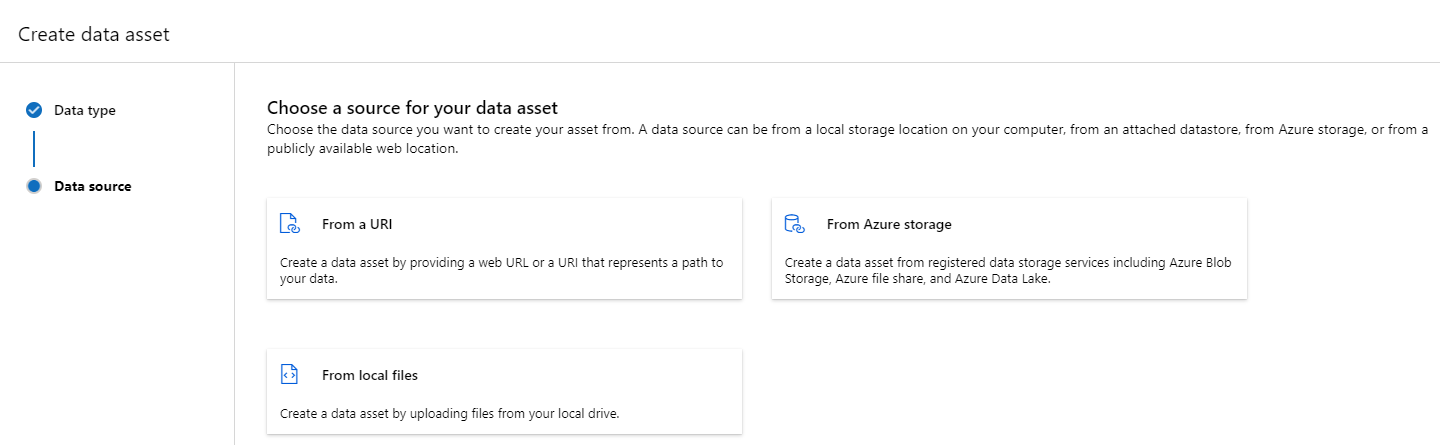
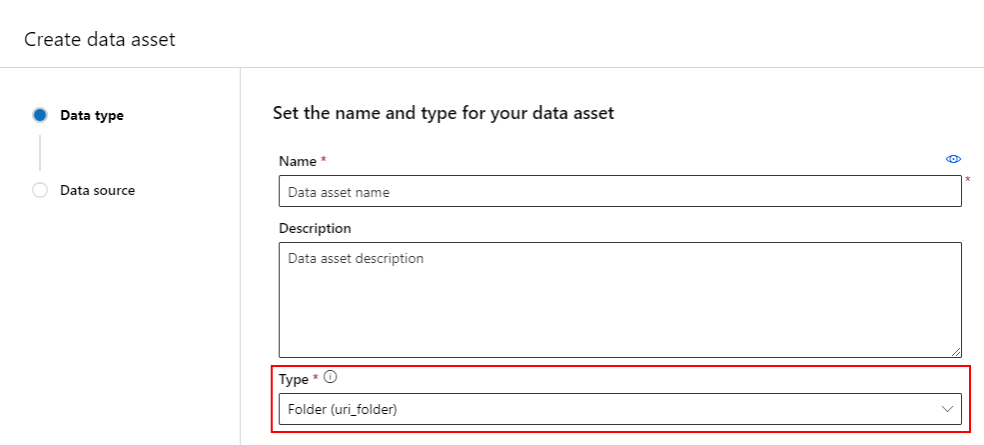
创建数据资产:文件夹类型
文件夹 (uri_folder) 类型的数据资产指向存储资源中的文件夹 - 例如,包含多个图像子文件夹的文件夹。 可以使用以下方式创建文件夹类型的数据资产:
将以下代码复制并粘贴到新的 YAML 文件中。 请务必使用以下内容更新 <> 占位符:
- 数据资产的名称
- 版本
- 说明
- 受支持位置上的文件夹的路径
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<folder>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.chinacloudapi.cn/<path>/<folder>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/<path>/<folder>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<folder>'
type: uri_folder
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
path: <SUPPORTED PATH>
接下来,在 CLI 中执行以下命令。 请务必将 <filename> 占位符更新为 YAML 文件名。
az ml data create -f <filename>.yml
创建数据资产:表类型
Azure 机器学习表 (MLTable) 具有丰富的功能,更多详情请参阅在 Azure 机器学习中使用表。 无需在此重复该文档,请阅读此示例,其中描述了如何创建“表格”类型的数据资产,其中 Titanic 数据位于公开可用的 Azure Blob 存储帐户中。
首先,创建一个名为 data 的新目录,并创建一个名为“MLTable”的文件:
mkdir data
touch MLTable
接下来,将下面的 YAML 复制粘贴到你在上一步中创建的 MLTable 文件:
注意
不要将 文件重命名为 MLTable 或 MLTable.yaml。 Azure 机器学习需要一个 MLTable 文件。
paths:
- file: wasbs://data@azuremlexampledata.blob.core.chinacloudapi.cn/titanic.csv
transformations:
- read_delimited:
delimiter: ','
empty_as_string: false
encoding: utf8
header: all_files_same_headers
include_path_column: false
infer_column_types: true
partition_size: 20971520
path_column: Path
support_multi_line: false
- filter: col('Age') > 0
- drop_columns:
- PassengerId
- convert_column_types:
- column_type:
boolean:
false_values:
- 'False'
- 'false'
- '0'
mismatch_as: error
true_values:
- 'True'
- 'true'
- '1'
columns: Survived
type: mltable
在 CLI 中执行以下命令。 确保使用数据资产名称和版本值更新 <> 占位符。
az ml data create --path ./data --name <DATA ASSET NAME> --version <VERSION> --type mltable
重要
path 应是包含有效 文件的文件夹。
从作业输出创建数据资产
可以在 Azure 机器学习作业中创建数据资产。 为此,请在输出中设置 name 参数。 在此示例中,你将提交一个作业,该作业将数据从公共 Blob 存储复制到默认的 Azure 机器学习数据存储,并创建名为 job_output_titanic_asset 的数据资产。
创建作业规范 YAML 文件 (<file-name>.yml):
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
# path: Set the URI path for the data. Supported paths include
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.chinacloudapi.cn/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# type: What type of data are you pointing to?
# uri_file (a specific file)
# uri_folder (a folder)
# mltable (a table)
# mode: Set INPUT mode:
# ro_mount (read-only mount)
# download (download from storage to node)
# mode: Set the OUTPUT mode
# rw_mount (read-write mount)
# upload (upload data from node to storage)
type: command
command: cp ${{inputs.input_data}} ${{outputs.output_data}}
compute: azureml:cpu-cluster
environment: azureml://registries/azureml/environments/sklearn-1.1/versions/4
inputs:
input_data:
mode: ro_mount
path: wasbs://data@azuremlexampledata.blob.core.chinacloudapi.cn/titanic.csv
type: uri_file
outputs:
output_data:
mode: rw_mount
path: azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv
type: uri_file
name: job_output_titanic_asset
接下来,使用 CLI 提交作业:
az ml job create --file <file-name>.yml
管理数据资产
删除数据资产
重要
根据设计,不支持删除数据资产。
如果 Azure 机器学习允许删除数据资产,它将产生以下负面影响和负面影响:
- 使用后来删除的数据资产的生产作业将失败。
- 再现机器学习试验将变得更加困难。
- 作业世系会中断,因为无法查看已删除的数据资产版本。
- 由于版本可能缺失,因此无法正确 跟踪和审核 。
因此,在创建生产工作负载的团队中工作时,数据资产的不可变性提供了一定程度的保护。
对于错误地创建了数据资产的情况(例如,名称、类型或路径错误),Azure 机器学习会提供解决方案来处理这种情况,不会造成删除操作带来的负面影响:
| 我想删除此数据资产,因为... | 解决方案 |
|---|---|
| 名称不正确 | 存档数据资产 |
| 团队不再使用数据资产 | 存档数据资产 |
| 它使数据资产列表变得混乱 | 存档数据资产 |
| 路径不正确 | 使用正确路径创建(同名)数据资产的新版本。 有关详细信息,请浏览创建数据资产。 |
| 其类型不正确 | 目前,Azure 机器学习不允许创建与初始版本类型不同的新版本。 (1) 存档数据资产 (2) 使用正确的类型创建一个不同名的新数据资产。 |
存档数据资产
默认情况下,存档数据资产后,该资产不在列表查询(例如在 CLI az ml data list)中显示,也不在 Studio 用户界面 的数据资产列表中显示。 你仍可继续在工作流中引用和使用已存档的数据资产。 可存档以下任一项:
- 采用给定名称的数据资产的所有版本
或
- 特定数据资产版本
存档数据资产的所有版本
若要存档给定名称下的数据资产的所有版本,请使用:
执行以下命令。 请务必使用信息更新 <> 占位符。
az ml data archive --name <NAME OF DATA ASSET>
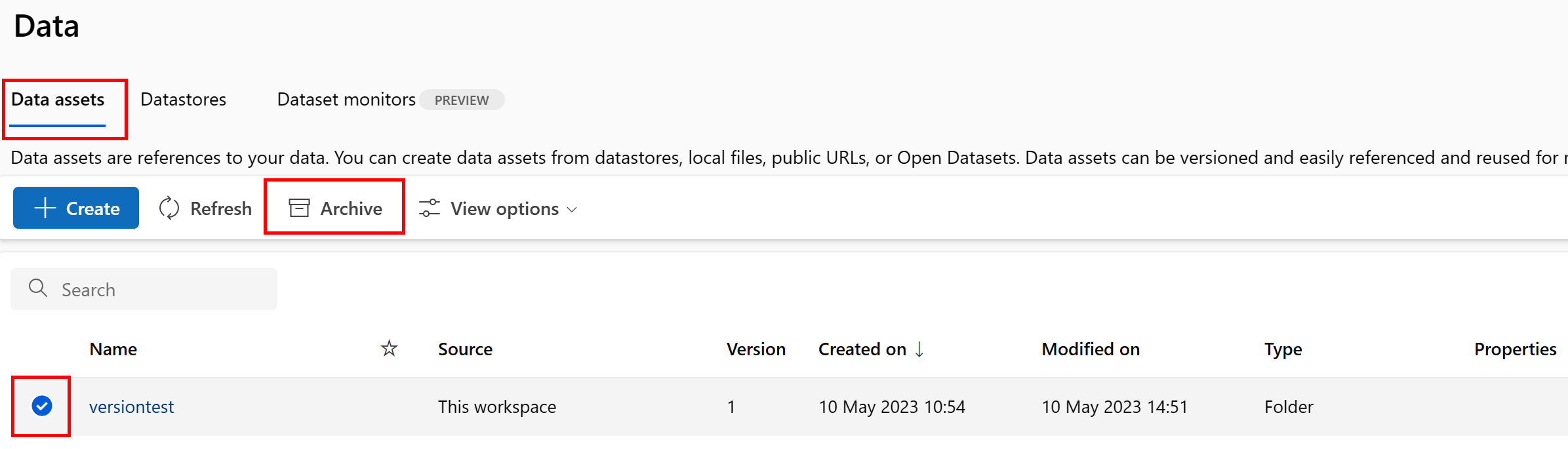
存档特定数据资产版本
若要存档特定数据资产版本,请使用:
执行以下命令。 请务必使用数据资产名称和版本更新 <> 占位符。
az ml data archive --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
还原已存档的数据资产
可还原已存档的数据资产。 如果已存档数据资产的所有版本,则无法还原数据资产的各个版本 - 必须还原所有版本。
还原数据资产的所有版本
若要还原给定名称下的数据资产的所有版本,请使用:
执行以下命令。 请务必使用数据资产名称更新 <> 占位符。
az ml data restore --name <NAME OF DATA ASSET>

还原特定数据资产版本
重要
如果存档了所有数据资产版本,则无法还原数据资产的各个版本 - 必须还原所有版本。
若要还原特定数据资产版本,请使用:
执行以下命令。 请务必使用数据资产名称和版本更新 <> 占位符。
az ml data restore --name <NAME OF DATA ASSET> --version <VERSION TO ARCHIVE>
数据世系
数据世系被广泛地理解为生命周期,它跨越数据的起源,并随着时间的推移在存储中推进。 不同类型的回顾场景都会用到它,例如
- 故障排除
- 跟踪 ML 管道中的根本原因
- 调试
数据质量分析、合规性和“如果”方案也使用世系。 世系以可视化的方式表示,以显示从源到目标的数据移动,此外还涵盖数据转换。 考虑到大多数企业数据环境的复杂性,如果不对外围数据点进行整合或过滤,这些视图可能很难理解。
在 Azure 机器学习管道中,数据资产显示了数据的来源和处理方式,例如:
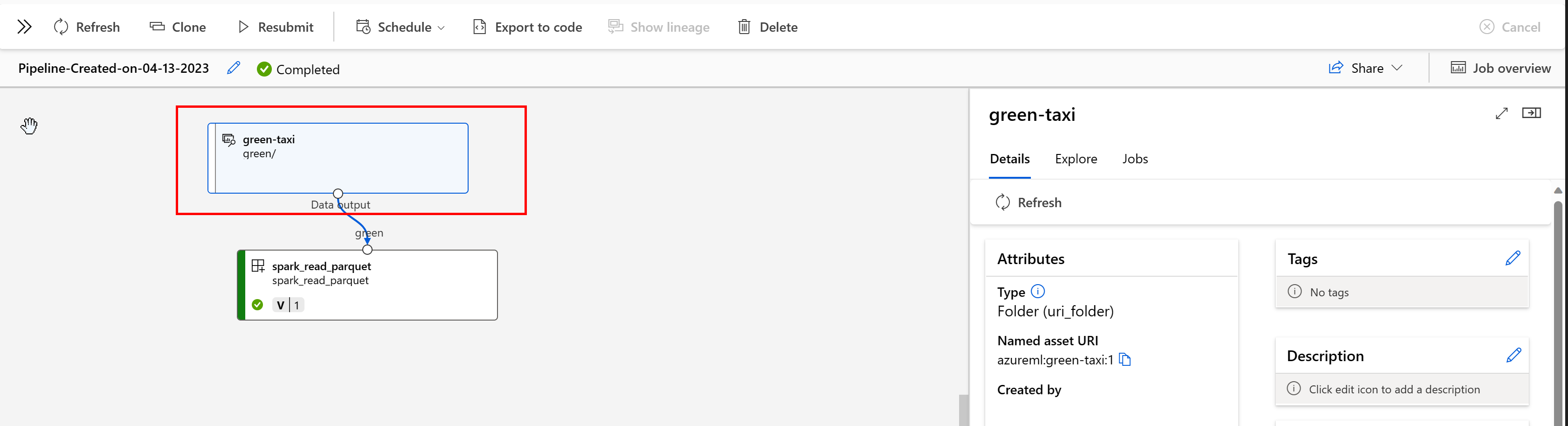
可以在工作室 UI 中查看使用数据资产的作业。 首先,从左侧菜单中选择“数据”,然后选择数据资产名称。 请注意正在使用数据资产的作业:
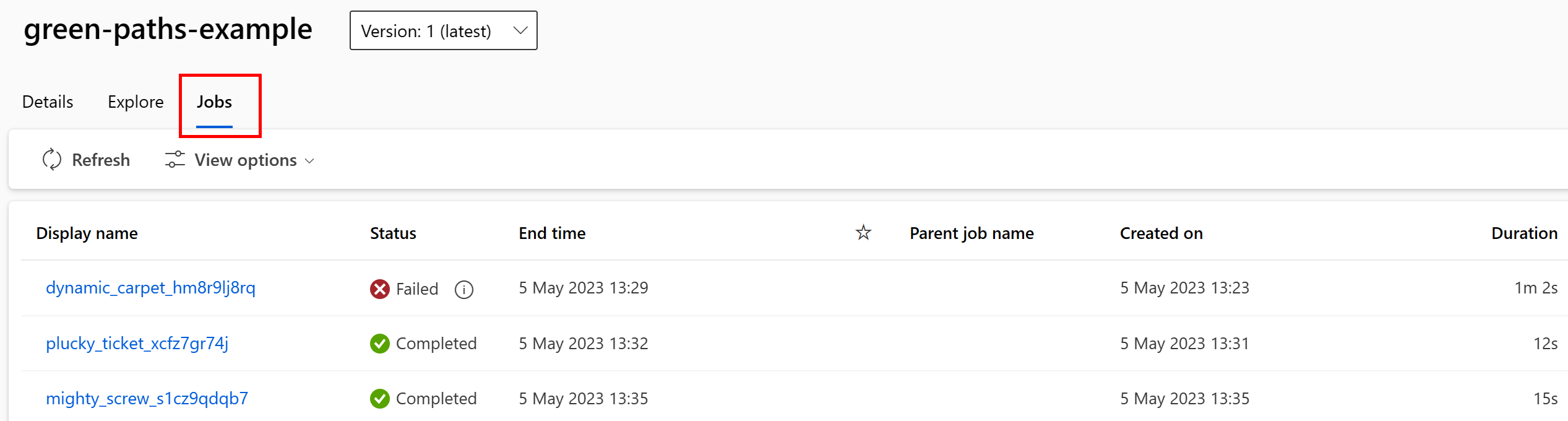
借助数据资产中的作业视图,可以更轻松地在 ML 管道和调试中查找作业失败情况并执行根本原因分析。
数据资产标记
数据资产支持标记,这是以键值对的形式应用于数据资产的额外元数据。 数据标记提供许多优势:
- 数据质量说明。 例如,如果你的组织使用 奖牌湖屋体系结构,则可以使用
medallion:bronze(原始)、medallion:silver(已验证)和medallion:gold(扩充)标记资产。 - 高效搜索和筛选数据,帮助数据发现。
- 识别敏感的个人数据,以正确管理和治理数据访问。 例如
sensitivity:PII/sensitivity:nonPII。 - 确定数据是否由负责任 AI (RAI) 审核批准。 例如
RAI_audit:approved/RAI_audit:todo。
可在数据资产创建流中向数据资产添加标记,也可向现有数据资产添加标记。 此部分同时显示两者:
在数据资产创建流的过程中添加标记
创建 YAML 文件,并复制以下代码,将其粘贴到该 YAML 文件中。 请务必使用以下内容更新 <> 占位符:
- 数据资产的名称
- 版本
- description
- 标记(键值对)
- 指向支持位置上的单个文件的路径
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
# Supported paths include:
# local: './<path>/<file>' (this will be automatically uploaded to cloud storage)
# blob: 'wasbs://<container_name>@<account_name>.blob.core.chinacloudapi.cn/<path>/<file>'
# ADLS gen2: 'abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/<path>/<file>'
# Datastore: 'azureml://datastores/<data_store_name>/paths/<path>/<file>'
# Data asset types, use one of:
# uri_file, uri_folder, mltable
type: uri_file
name: <NAME OF DATA ASSET>
version: <VERSION>
description: <DESCRIPTION>
tags:
<KEY1>: <VALUE>
<KEY2>: <VALUE>
path: <SUPPORTED PATH>
在 CLI 中执行以下命令。 请务必将 <filename> 占位符更新为 YAML 文件名。
az ml data create -f <filename>.yml
向现有数据资产添加标记
在 Azure CLI 中执行以下命令。 请务必使用以下内容更新 <> 占位符:
- 数据资产的名称
- 版本
- 标记的键值对
az ml data update --name <DATA ASSET NAME> --version <VERSION> --set tags.<KEY>=<VALUE>
版本管理最佳实践
通常,ETL 进程在 Azure 存储上按时间整理文件夹结构,例如:
/
└── 📁 mydata
├── 📁 year=2022
│ ├── 📁 month=11
│ │ └── 📄 file1
│ │ └── 📄 file2
│ └── 📁 month=12
│ └── 📄 file1
│ │ └── 📄 file2
└── 📁 year=2023
└── 📁 month=1
└── 📄 file1
│ │ └── 📄 file2
借助时间/版本结构化文件夹与 Azure 机器学习表 () 的组合,你能够构造经过版本控制的数据集。MLTable 假设示例说明了如何使用 Azure 机器学习表存档经过版本控制的数据。 假设你有一个进程,每周将相机图像上传到 Azure Blob 存储中,其结构如下:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
注意
虽然我们演示了如何对图像 (jpeg) 数据进行版本控制,但相同的方法适用于任何文件类型(例如,Parquet、CSV)。
使用 Azure 机器学习表 (mltable),构建包含截至 2023 年第一周结束的数据的路径表。 接着,创建数据资产:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/myimages/year=2023/week=1/**/*.jpeg"
},
]
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AZUREML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-08.",
name="myimages",
version="20230108",
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
在下一周结束时,ETL 已更新数据以包含更多数据:
/myimages
└── 📁 year=2022
├── 📁 week52
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
└── 📁 year=2023
├── 📁 week1
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
├── 📁 week2
│ ├── 📁 camera1
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
│ └── 📁 camera2
│ │ └── 🖼️ file1.jpeg
│ │ └── 🖼️ file2.jpeg
第一个版本 (20230108) 继续仅从 year=2022/week=52 和 year=2023/week=1 装载/下载文件,因为路径是在 MLTable 文件中声明的。 这确保了试验的“可再现性”。 若要创建包含 year=2023/week2 的新版本的数据资产,可使用:
import mltable
from mltable import MLTableHeaders, MLTableFileEncoding, DataType
from azure.ai.ml import MLClient
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
from azure.identity import DefaultAzureCredential
# The ** in the pattern below will glob all sub-folders (camera1, ..., camera2)
paths = [
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/myimages/year=2022/week=52/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/myimages/year=2023/week=1/**/*.jpeg"
},
{
"pattern": "abfss://<file_system>@<account_name>.dfs.core.chinacloudapi.cn/myimages/year=2023/week=2/**/*.jpeg"
},
]
# Save to an MLTable file on local storage
tbl = mltable.from_paths(paths)
tbl.save("./myimages")
# Next, you create a data asset - the MLTable file will automatically be uploaded
# Connect to the AzureML workspace
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AZUREML_WORKSPACE_NAME>"
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# Define the Data asset object
my_data = Data(
path=mltable_folder,
type=AssetTypes.MLTABLE,
description="My images. Version includes data through to 2023-Jan-15.",
name="myimages",
version="20230115", # update version to the date
)
# Create the data asset in the workspace
ml_client.data.create_or_update(my_data)
现在你有两个版本的数据,其中版本的名称与图像上传到存储的日期相对应:
- 20230108:截至 2023 年 1 月 8 日的图像。
- 20230115:截至 2023 年 1 月 15 日的图像。
在这两种情况下,MLTable 都构造一个路径表,其中仅包含截至这些日期的图像。
在 Azure 机器学习作业中,可以使用 eval_download 或 eval_mount 模式将经过版本控制的 MLTable 中的这些路径装载或下载到计算目标:
from azure.ai.ml import MLClient, command, Input
from azure.ai.ml.entities import Environment
from azure.identity import DefaultAzureCredential
from azure.ai.ml.constants import InputOutputModes
# connect to the AzureML workspace
ml_client = MLClient.from_config(
DefaultAzureCredential()
)
# Get the 20230115 version of the data
data_asset = ml_client.data.get(name="myimages", version="20230115")
input = {
"images": Input(type="mltable",
path=data_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
cmd = """
ls ${{inputs.images}}/**
"""
job = command(
command=cmd,
inputs=input,
compute="cpu-cluster",
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4"
)
ml_client.jobs.create_or_update(job)
注意
eval_mount 和 eval_download 模式对 MLTable 来说是唯一的。 在这种情况下,Azure 机器学习数据运行时功能会评估 MLTable 文件并将路径装载到计算目标上。