适用范围: Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
Azure CLI ml 扩展 v2(最新版)Python SDK azure-ai-ml v2(最新版)
本文介绍如何在 Azure 机器学习中使用 NVIDIA Triton 推理服务器 和 联机终结点。
Triton 是针对推理优化的多框架开源软件。 它支持常用的机器学习框架,如 TensorFlow、ONNX 运行时、PyTorch 和 NVIDIA TensorRT。 可以将它用于 CPU 或 GPU 工作负载。
将 Triton 模型部署到联机终结点时,可以使用两种主要方法:无代码部署或全代码(自带容器)部署。
- Triton 模型的无代码部署是一种简单的部署方法,因为只需将 Triton 模型引入部署即可。
- Triton 模型的全代码部署是部署它们的更高级方法,因为你可以完全控制自定义可用于 Triton 推理服务器的配置。
对于这两个选项,Triton Inference Server 基于 NVIDIA 定义的 Triton 模型执行推理。 例如,系综模型可用于更高级的方案。
托管联机终结点和 Kubernetes 联机终结点都支持 Triton。
本文介绍如何使用 Triton 的无代码部署将模型部署到 托管联机终结点。 提供了有关使用 Azure CLI、Python SDK v2 和 Azure 机器学习工作室的信息。 若要直接使用 Triton 推理服务器的配置进一步自定义,请参阅 使用自定义容器部署模型 和 Triton 的 BYOC 示例(部署定义 和 端到端脚本)。
先决条件
一个可运行的 Python 3.10 及以上版本的环境。
必须安装其他 Python 包才能评分。 可以使用以下代码安装它们。 它们包括:
- NumPy。 数组和数值计算库。
-
Triton 推理服务器客户端。 简化对 Triton 推理服务器的请求。
- 枕头。 用于图像操作的库。
- 格文特 用于连接到 Triton 服务器的网络库。
pip install numpy
pip install tritonclient[http]
pip install pillow
pip install gevent
访问 Azure 订阅的 NCv3 系列虚拟机。
重要
可能需要为订阅请求增加配额,然后才能使用此系列虚拟机。 有关详细信息,请参阅 NCv3 系列。
NVIDIA Triton 推理服务器要求特定的模型存储库结构,其中每个模型都有一个目录,以及用于模型版本的子目录。 每个模型版本子目录的内容由模型的类型以及支持模型的后端的要求决定。 有关所有模型的结构的信息,请参阅 模型文件。
本文档中的信息基于使用以 ONNX 格式存储的模型,因此模型存储库的目录结构为 <model-repository>/<model-name>/1/model.onnx。 具体而言,此模型执行图像识别。
本文中的信息基于 azureml-examples 存储库中包含的代码示例。 若要在不复制/粘贴 YAML 和其他文件的情况下在本地运行命令,请克隆存储库,然后将目录更改为存储库中的 cli 目录:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples
cd cli
如果尚未为 Azure CLI 指定默认设置,则应保存默认设置。 若要避免多次传入订阅、工作区和资源组的值,请使用以下命令。 将以下参数替换为特定配置的值:
- 将
<subscription> 替换为你的 Azure 订阅 ID。
- 将
<workspace> 替换为 Azure 机器学习工作区名称。
- 将
<resource-group> 替换为包含你的工作区的 Azure 资源组。
- 将
<location> 替换为包含你的工作区的 Azure 区域。
提示
可以使用 az configure -l 命令查看当前的默认值。
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
适用范围:Python SDK azure-ai-ml v2(最新版)
Azure 机器学习工作区。 有关创建工作区的步骤,请参阅 “创建工作区”。
适用于 Python v2 的 Azure 机器学习 SDK。 若要安装 SDK,请使用以下命令:
pip install azure-ai-ml azure-identity
要将 SDK 的现有安装更新到最新版本,请使用以下命令:
pip install --upgrade azure-ai-ml azure-identity
有关详细信息,请参阅 适用于 Python 的 Azure 机器学习包客户端库。
一个可运行的 Python 3.10 及以上版本的环境。
必须安装其他 Python 包才能评分。 可以使用以下代码安装它们。 它们包括:
- NumPy。 数组和数值计算库。
-
Triton 推理服务器客户端。 简化对 Triton 推理服务器的请求。
- 枕头。 用于图像操作的库。
- 格文特 用于连接到 Triton 服务器的网络库。
pip install numpy
pip install tritonclient[http]
pip install pillow
pip install gevent
访问 Azure 订阅的 NCv3 系列虚拟机。
重要
可能需要为订阅请求增加配额,然后才能使用此系列虚拟机。 有关详细信息,请参阅 NCv3 系列。
本文中的信息基于 azureml-examples 存储库中包含的 online-endpoints-triton.ipynb 笔记本内容。 若要在本地运行命令,而无需复制和粘贴文件,请克隆存储库,然后将目录更改为 sdk/endpoints/online/triton/single-model/ 存储库中的目录:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/sdk/python/endpoints/online/triton/single-model/
定义部署配置
适用于:Azure CLI ml 扩展 v2(当前)
本部分介绍如何使用 Azure CLI 和机器学习扩展(v2)部署到托管联机终结点。
要避免在多个命令中键入路径,请使用以下命令设置 BASE_PATH 环境变量。 此变量指向模型和关联的 YAML 配置文件所在的目录:
BASE_PATH=endpoints/online/triton/single-model
使用以下命令设置要创建的终结点的名称。 在此示例中,将为终结点创建一个随机名称:
export ENDPOINT_NAME=triton-single-endpt-`echo $RANDOM`
为终结点创建 YAML 配置文件。 以下示例配置终结点的名称和身份验证模式。 以下命令中使用的文件位于 /cli/endpoints/online/triton/single-model/create-managed-endpoint.yml 前面克隆的 azureml 示例存储库中:
create-managed-endpoint.yaml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: aml_token
为部署创建 YAML 配置文件。 以下示例将一个名为 blue 的部署配置到上一步中定义的终结点。 以下命令中使用的文件位于 /cli/endpoints/online/triton/single-model/create-managed-deployment.yml 前面克隆的 azureml 示例存储库中:
重要
为了让 Triton 的无代码部署正常工作,您需要将 type 设置为 triton_model: type: triton_model。 有关详细信息,请参阅 CLI (v2) 模型 YAML 架构。
此部署使用 Standard_NC6s_v3 虚拟机。 可能需要为订阅请求增加配额,然后才能使用此虚拟机。 有关详细信息,请参阅 NCv3 系列。
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
name: sample-densenet-onnx-model
version: 1
path: ./models
type: triton_model
instance_count: 1
instance_type: Standard_NC6s_v3
适用范围:Python SDK azure-ai-ml v2(最新版)
本部分介绍如何使用 Azure 机器学习 Python SDK (v2)定义用于部署到托管联机终结点的 Triton 部署。
若要连接到工作区,需要标识符参数:订阅、资源组和工作区名称。
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace_name = "<WORKSPACE_NAME>"
使用以下命令设置要创建的终结点的名称。 在此示例中,将为终结点创建一个随机名称:
import random
endpoint_name = f"endpoint-{random.randint(0, 10000)}"
使用前面配置的azure.ai.mlMLClient标识符参数来获取 Azure 机器学习所需工作区的句柄。 有关如何配置凭据和连接到工作区的更多详细信息,请参阅 配置笔记本 。
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id,
resource_group,
workspace_name,
)
创建一个 ManagedOnlineEndpoint 对象以配置终结点。 以下示例配置终结点的名称和身份验证模式。
from azure.ai.ml.entities import ManagedOnlineEndpoint
endpoint = ManagedOnlineEndpoint(name=endpoint_name, auth_mode="key")
创建一个 ManagedOnlineDeployment 对象以配置部署。 以下示例配置一个名为blue的部署到上一步中定义的终结点,并以内联方式定义本地模型。
from azure.ai.ml.entities import ManagedOnlineDeployment, Model
model_name = "densenet-onnx-model"
model_version = "1"
deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=endpoint_name,
model=Model(
name=model_name,
version=model_version,
path="./models",
type="triton_model"
),
instance_type="Standard_NC6s_v3",
instance_count=1,
)
本部分介绍如何使用 Azure 机器学习工作室在托管联机终结点上定义 Triton 部署。
使用以下 YAML 和 CLI 命令以 Triton 格式注册模型。 YAML 使用 azureml-examples/cli/endpoints/online/triton/single-model 中的 densenet-onnx 模型。
create-triton-model.yaml
name: densenet-onnx-model
version: 1
path: ./models
type: triton_model
description: Registering my Triton format model.
az ml model create -f create-triton-model.yaml
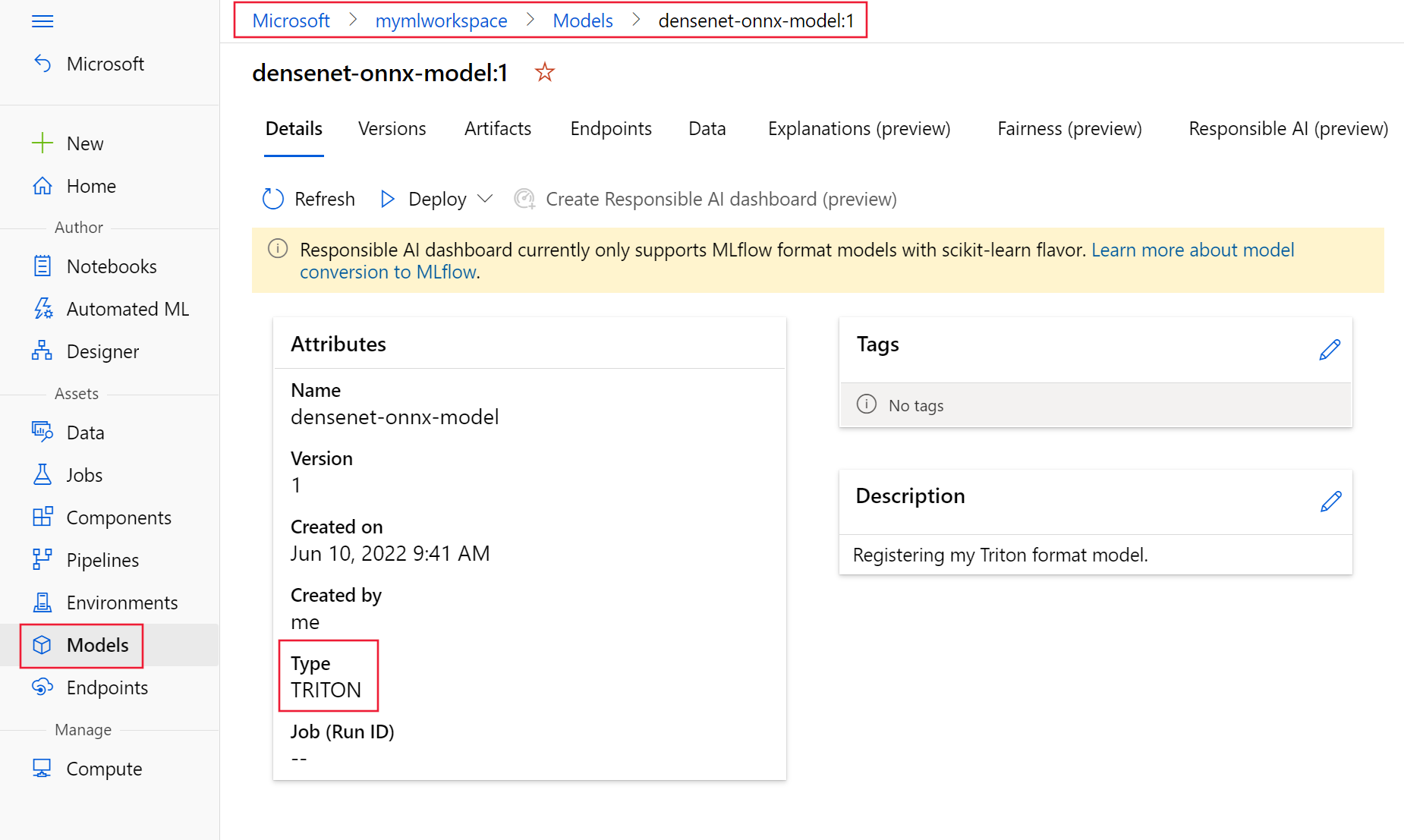
以下屏幕截图显示了已注册的模型在 Azure 机器学习工作室的 “模型 ”页上的外观。
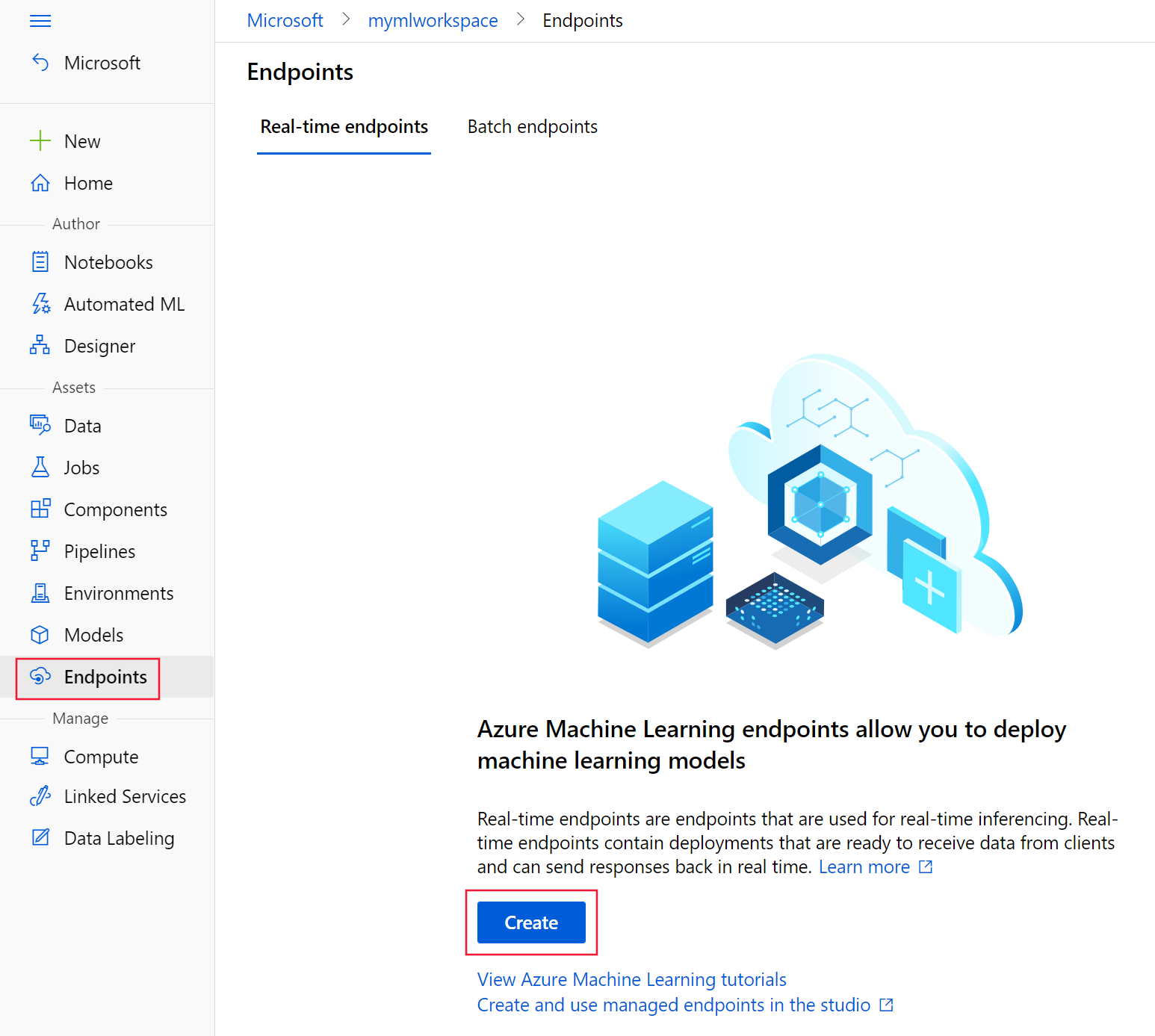
在 工作室中,选择工作区,然后使用 “终结点 或 模型 ”页创建终结点部署:
在 “终结点 ”页上,选择“ 创建”。
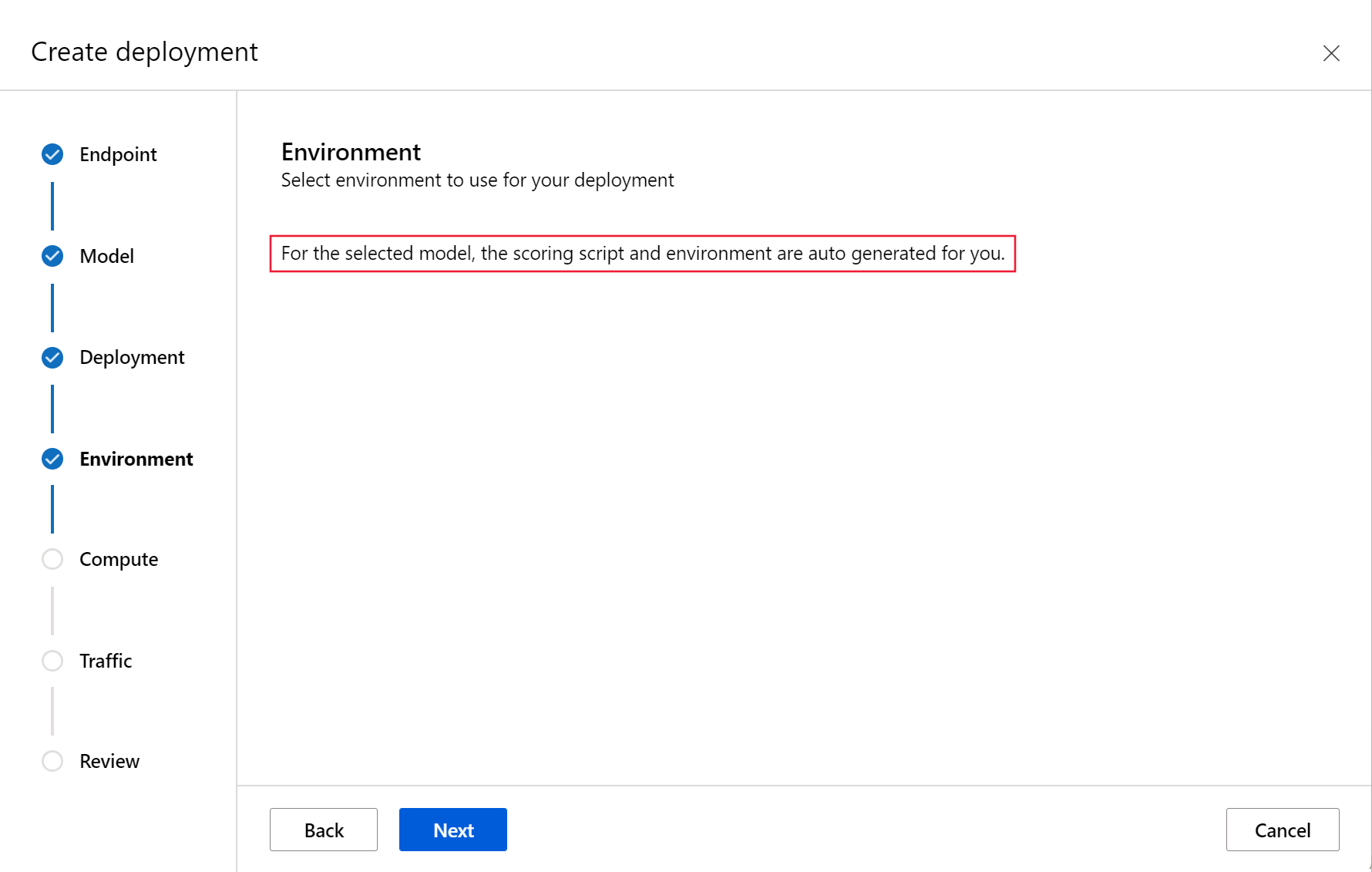
选择之前注册的 Triton 模型,然后单击 “选择”。
选择以 Triton 格式注册的模型时,不需要评分脚本或环境。
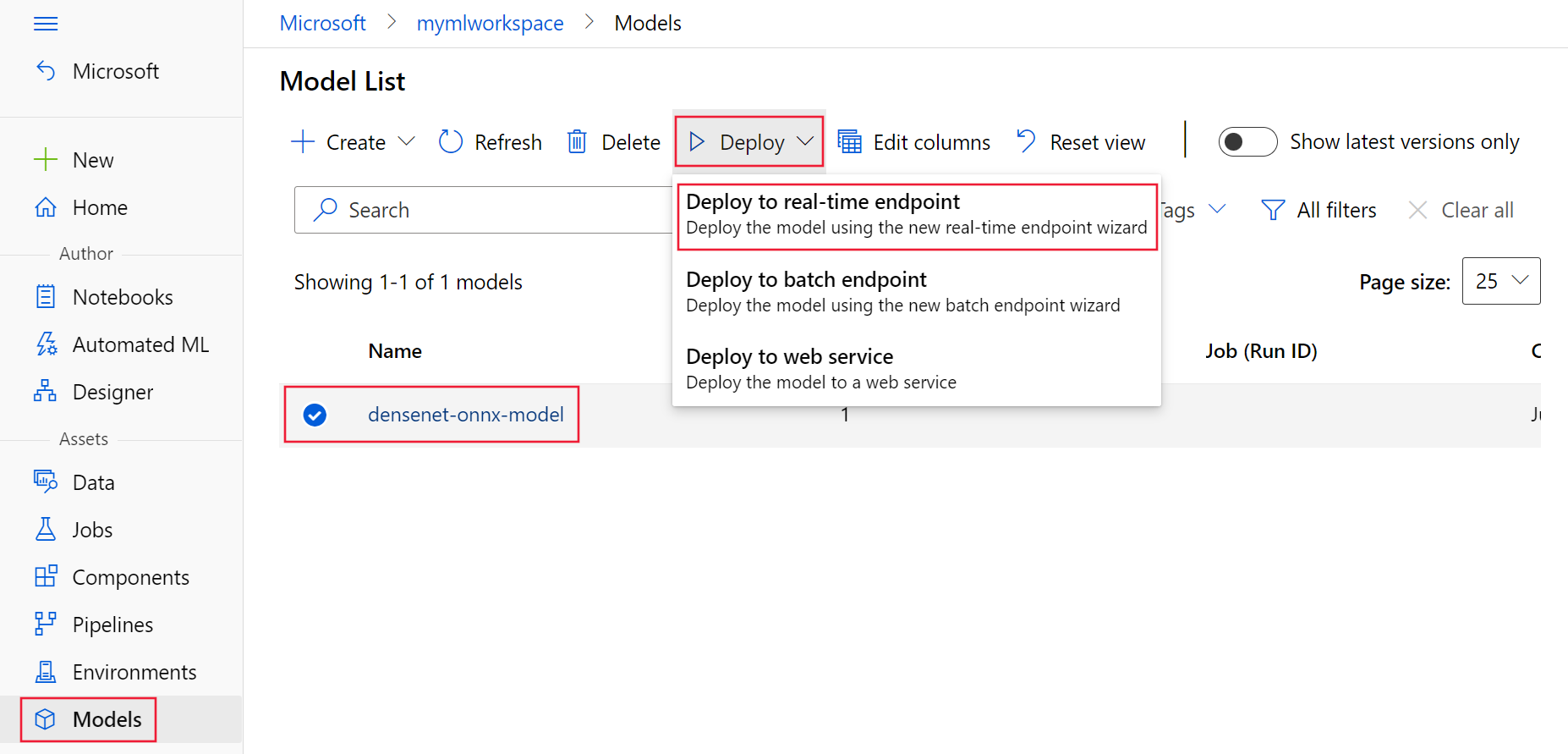
选择 Triton 模型,然后选择“ 使用此模型>实时终结点”。
“部署到 Azure”
适用于:Azure CLI ml 扩展 v2(当前)
若要使用 YAML 配置创建终结点,请使用以下命令:
az ml online-endpoint create -n $ENDPOINT_NAME -f $BASE_PATH/create-managed-endpoint.yaml
若要使用 YAML 配置创建部署,请使用以下命令:
az ml online-deployment create --name blue --endpoint $ENDPOINT_NAME -f $BASE_PATH/create-managed-deployment.yaml --all-traffic
适用范围:Python SDK azure-ai-ml v2(最新版)
若要使用 ManagedOnlineEndpoint 对象创建终结点,请使用以下命令:
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint)
若要使用 ManagedOnlineDeployment 对象创建部署,请使用以下命令:
ml_client.online_deployments.begin_create_or_update(deployment)
部署完成后,其 traffic 值将设置为 0%。 将 traffic 值更新为 100%:
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint)
在 “部署 ”窗格中,选择“ 部署”。
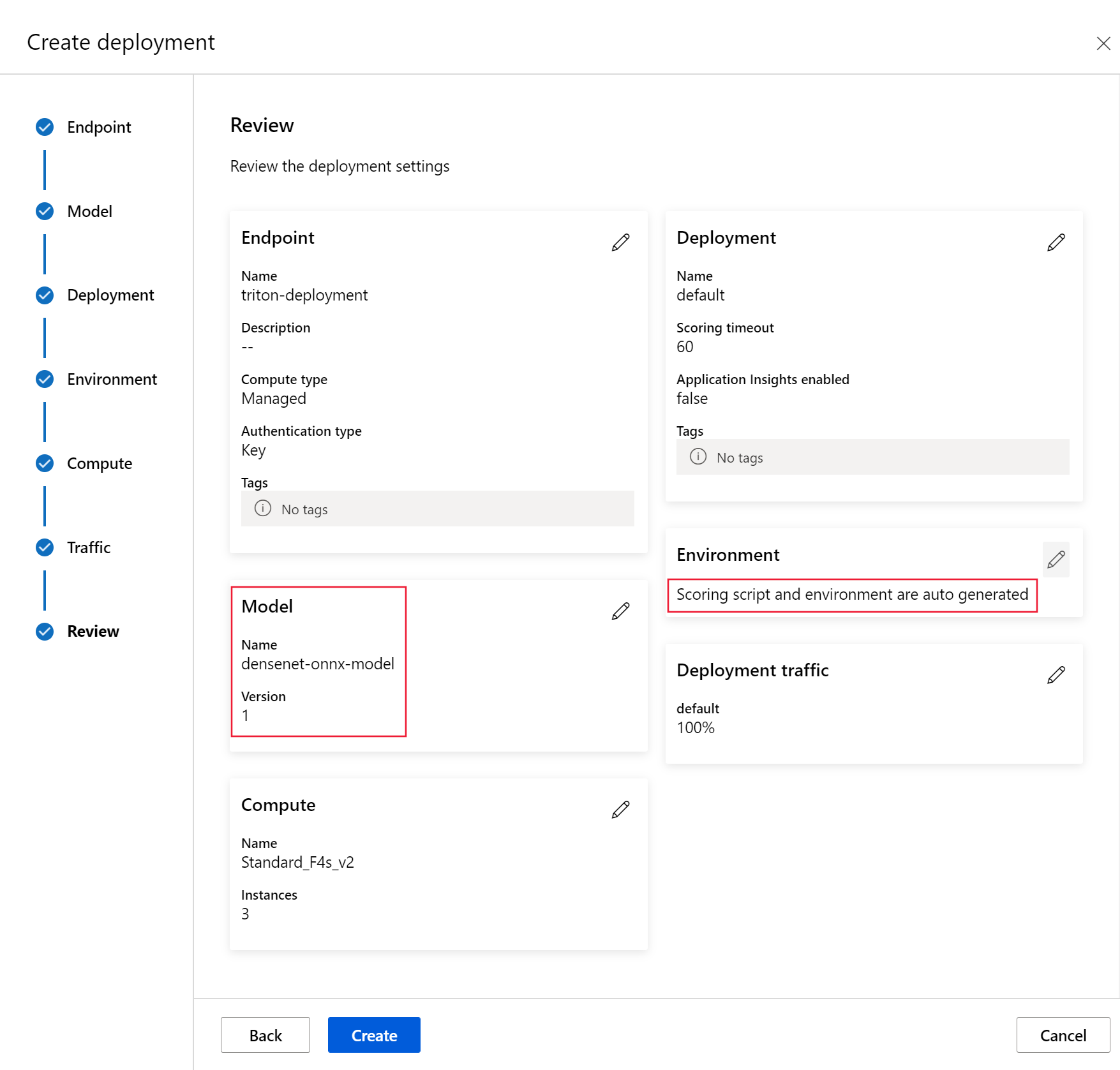
部署完成后,其流量值将设置为 0%。 通过选择终结点页面上的 “更新流量 ”,将流量值更新为 100%。
测试终结点
适用于:Azure CLI ml 扩展 v2(当前)
部署完成后,使用以下命令向已部署的终结点发出评分请求。
提示
azureml-examples 存储库中的 /cli/endpoints/online/triton/single-model/triton_densenet_scoring.py 文件用于评分。 传递给终结点的图像需要预处理以满足大小、类型和格式要求,以及后期处理才能显示预测的标签。 该文件 triton_densenet_scoring.py 使用 tritonclient.http 库与 Triton 推理服务器通信。 此文件在客户端上运行。
若要获取终结点评分 URI,请使用以下命令:
scoring_uri=$(az ml online-endpoint show -n $ENDPOINT_NAME --query scoring_uri -o tsv)
scoring_uri=${scoring_uri%/*}
要获取身份验证密钥,请使用以下命令:
auth_token=$(az ml online-endpoint get-credentials -n $ENDPOINT_NAME --query accessToken -o tsv)
要使用终结点对数据进行评分,请使用以下命令。 它将 孔雀 的图像提交到终结点:
python $BASE_PATH/triton_densenet_scoring.py --base_url=$scoring_uri --token=$auth_token --image_path $BASE_PATH/data/peacock.jpg
来自脚本的响应类似于以下响应:
Is server ready - True
Is model ready - True
/azureml-examples/cli/endpoints/online/triton/single-model/densenet_labels.txt
84 : PEACOCK
适用范围:Python SDK azure-ai-ml v2(最新版)
若要获取终结点评分 URI,请使用以下命令:
endpoint = ml_client.online_endpoints.get(endpoint_name)
scoring_uri = endpoint.scoring_uri
要获取身份验证密钥,请使用以下命令:
keys = ml_client.online_endpoints.get_keys(endpoint_name)
auth_key = keys.primary_key
以下评分代码使用 Triton 推理服务器客户端将孔雀的图像提交到终结点。 本示例的配套笔记本中提供了此脚本: 使用 Triton 将模型部署到联机终结点。
# Test the blue deployment with some sample data
import requests
import gevent.ssl
import numpy as np
import tritonclient.http as tritonhttpclient
from pathlib import Path
import prepost
img_uri = "http://aka.ms/peacock-pic"
# Remove the scheme from the URL
url = scoring_uri[8:]
# Initialize the client handler
triton_client = tritonhttpclient.InferenceServerClient(
url=url,
ssl=True,
ssl_context_factory=gevent.ssl._create_default_https_context,
)
# Create headers
headers = {}
headers["Authorization"] = f"Bearer {auth_key}"
# Check the status of the Triton server
health_ctx = triton_client.is_server_ready(headers=headers)
print("Is server ready - {}".format(health_ctx))
# Check the status of the model
model_name = "model_1"
status_ctx = triton_client.is_model_ready(model_name, "1", headers)
print("Is model ready - {}".format(status_ctx))
if Path(img_uri).exists():
img_content = open(img_uri, "rb").read()
else:
agent = f"Python Requests/{requests.__version__} (https://github.com/Azure/azureml-examples)"
img_content = requests.get(img_uri, headers={"User-Agent": agent}).content
img_data = prepost.preprocess(img_content)
# Populate inputs and outputs
input = tritonhttpclient.InferInput("data_0", img_data.shape, "FP32")
input.set_data_from_numpy(img_data)
inputs = [input]
output = tritonhttpclient.InferRequestedOutput("fc6_1")
outputs = [output]
result = triton_client.infer(model_name, inputs, outputs=outputs, headers=headers)
max_label = np.argmax(result.as_numpy("fc6_1"))
label_name = prepost.postprocess(max_label)
print(label_name)
来自脚本的响应类似于以下响应:
Is server ready - True
Is model ready - True
/azureml-examples/sdk/endpoints/online/triton/single-model/densenet_labels.txt
84 : PEACOCK
Triton Inference Server 需要使用 Triton 客户端进行推理,并支持张量类型输入。 Azure 机器学习工作室目前不支持此功能。 请改用 CLI 或 SDK,通过 Triton 调用端点。
删除终结点和模型
适用于:Azure CLI ml 扩展 v2(当前)
完成终结点后,请使用以下命令将其删除:
az ml online-endpoint delete -n $ENDPOINT_NAME --yes
使用以下命令存档模型:
az ml model archive --name sample-densenet-onnx-model --version 1
适用范围:Python SDK azure-ai-ml v2(最新版)
删除终结点。 删除终结点也会删除任何子部署,但不会存档关联的环境或模型。
ml_client.online_endpoints.begin_delete(name=endpoint_name)
使用以下代码存档模型。
ml_client.models.archive(name=model_name, version=model_version)
在终结点的页面上,选择“ 删除”。
在模型的页面上,选择“ 存档”。
后续步骤
若要了解更多信息,请查看下列文章:




