机器学习模型训练是一个迭代过程,需要大量的试验。 借助 Azure 机器学习交互式作业体验,数据科学家可以使用 Azure 机器学习 Python SDK、Azure 机器学习 CLI 或 Azure Studio 来访问运行其作业的容器。 访问作业容器后,用户可以远程循环访问训练脚本、监视训练进度或调试作业,就像他们通常在本地计算机上所做的那样。 可以通过不同的训练应用程序(包括 JupyterLab、TensorBoard、VS Code)与作业交互,也可以直接通过 SSH 连接到作业容器来与作业交互。
Azure 机器学习计算群集支持交互式训练。
先决条件
- 请查看 Azure 机器学习上的训练入门。
- 有关详细信息,请参阅 Visual Studio Code 的这个链接,了解如何设置 Azure 机器学习扩展。
- 请确保作业环境中已安装
openssh-server和ipykernel ~=6.0包(默认情况下,所有 Azure 机器学习管护的训练环境都安装了这些包)。 - 对于分布类型并非 Pytorch、TensorFlow 或 MPI 的分布式训练运行,无法启用交互式应用程序。 当前不支持自定义分布式训练设置(在不使用上述分布框架的情况下配置多节点训练)。
- 若要使用 SSH,需要 SSH 密钥对。 使用
ssh-keygen -f "<filepath>"命令生成公钥和私钥对。
与作业容器交互
通过在创建作业时指定交互式应用程序,可以直接连接到运行作业的计算节点上的容器。 一旦有权访问作业容器,就可以在将要运行作业的完全相同的环境中测试或调试作业。 还可以使用 VS Code 附加到正在运行的进程并进行调试,就像在本地一样。
在作业提交期间启用
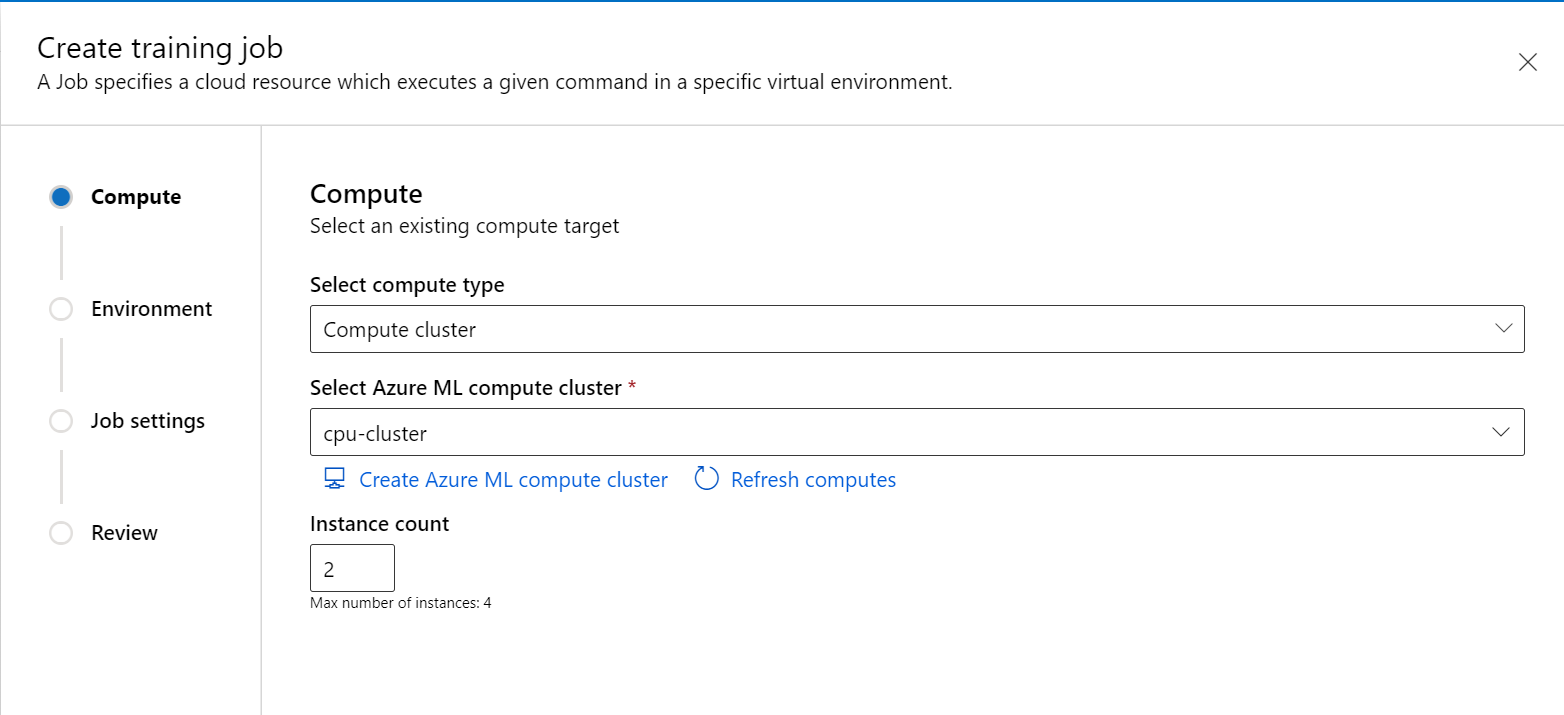
在工作室门户中的左窗格中创建新作业。
选择“计算群集”或“附加计算”(Kubernetes) 作为计算类型,选择计算目标,并在
Instance count中指定所需的节点数。
按照向导操作,选择要启动作业的环境。
在“作业设置”步骤中,添加训练代码(和输入/输出数据),并在命令中引用它以确保它装载到作业中。
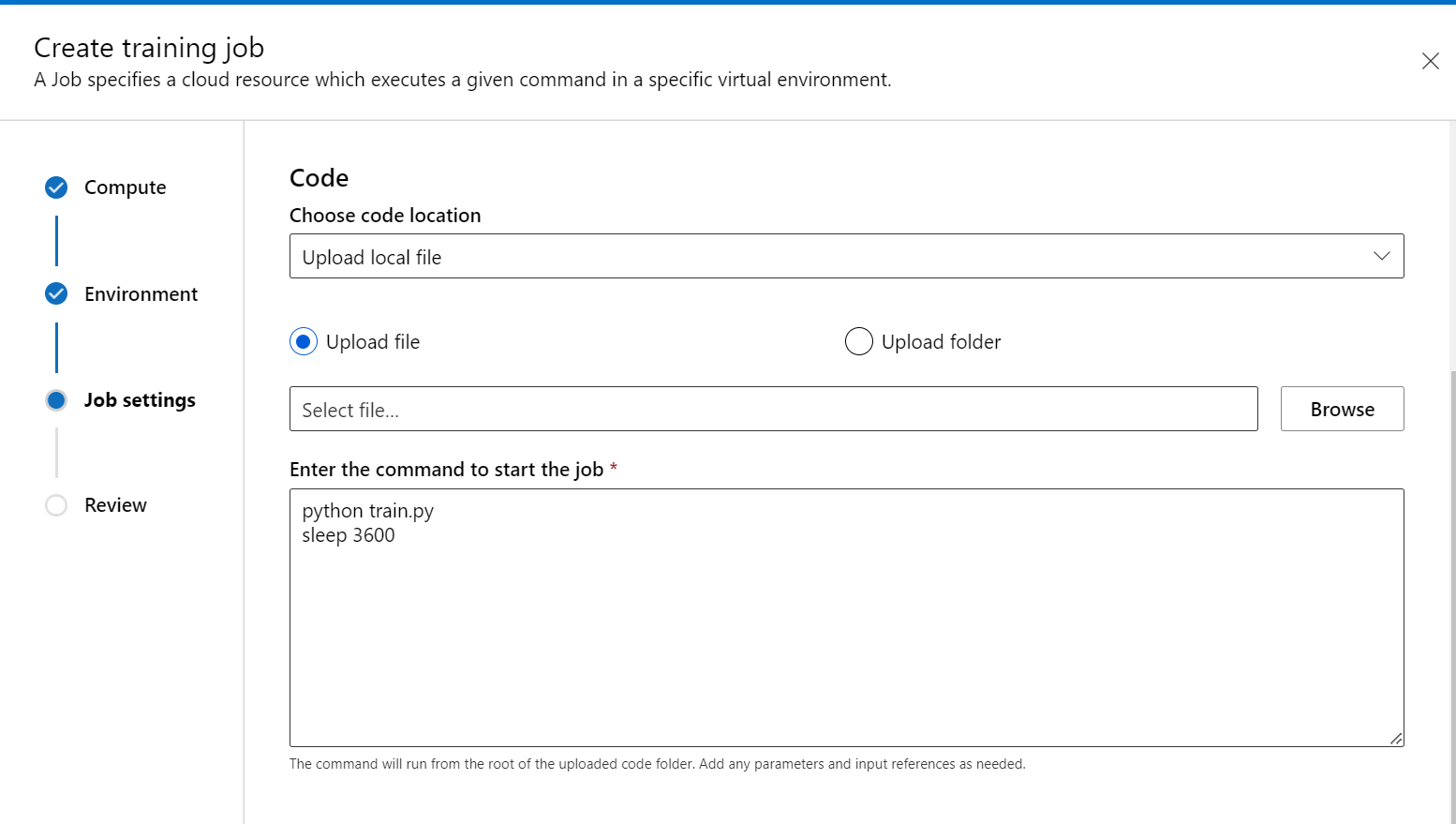
可以将 sleep <specific time> 放在命令的末尾,以指定要保留计算资源的时间量。 格式如下:
- 睡眠 1 秒
- 睡眠 1 分钟
- 睡眠 1 小时
- 睡眠 1 天
还可以使用 sleep infinity 命令使作业无限期保持活动状态。
注意
如果使用 sleep infinity,则需要手动取消作业以释放计算资源(并停止计费)。
- 至少选择一个要用来与作业交互的训练应用程序。 如果不选择应用程序,则调试功能将不可用。
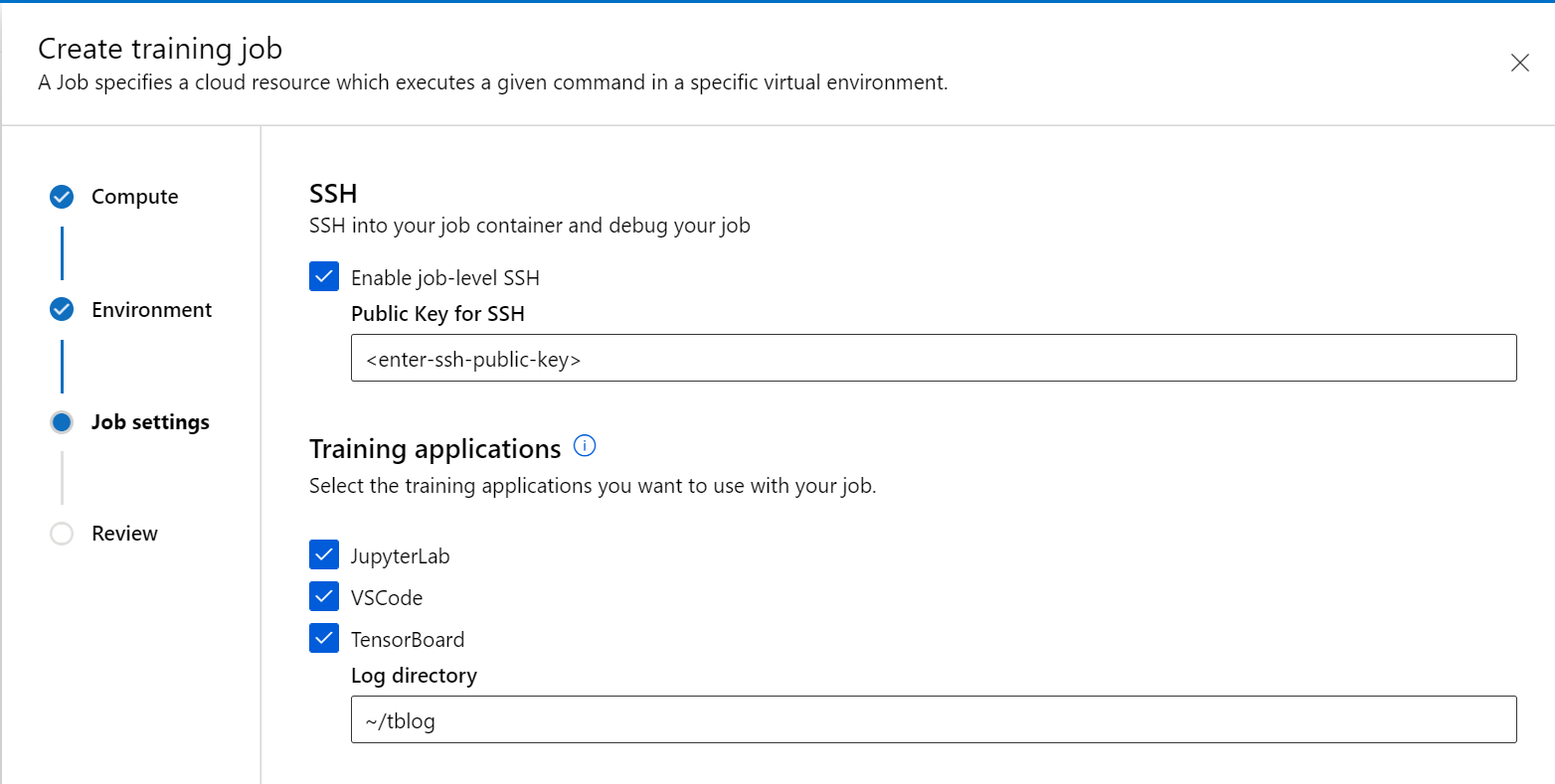
- 查看并创建作业。
连接到终结点
若要与正在运行的作业交互,请选择作业详细信息页上的“调试和监视”按钮。
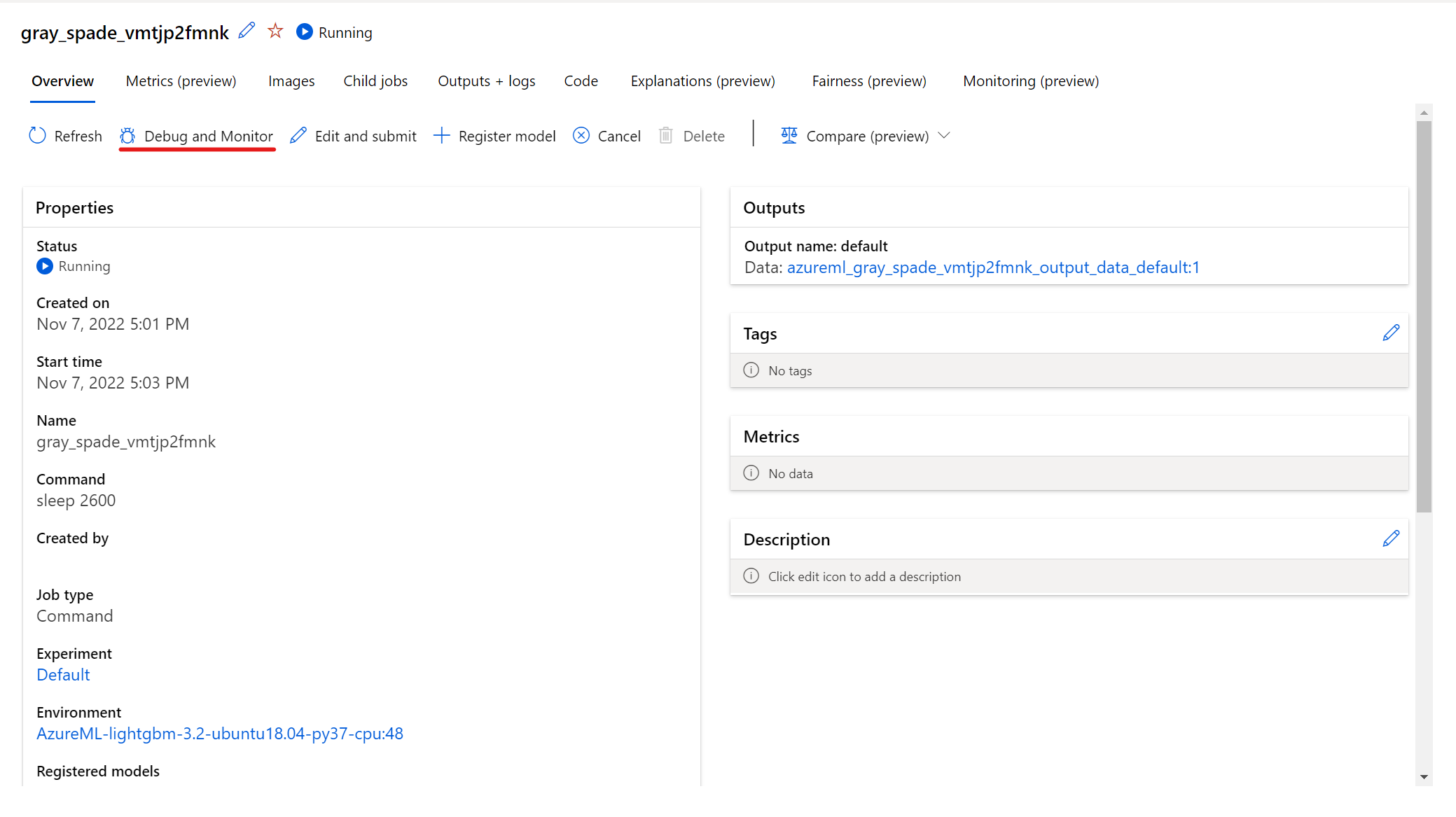
单击面板中的应用程序将打开应用程序的新选项卡。 只有当应用程序处于“正在运行”状态并且“作业所有者”有权访问这些应用程序时,你才能访问这些应用程序。 如果要在多个节点上进行训练,则可以选择要与之交互的特定节点。

启动作业和在创建作业期间指定的训练应用程序可能需要几分钟时间。
与应用程序交互
当选择终结点以与作业进行交互时,会转到工作目录下的用户容器,可在其中访问代码、输入、输出和日志。 如果在连接到应用程序时遇到任何问题,可以从“输出 + 日志”选项卡下的 system_logs->interactive_capability 找到交互式功能和应用程序日志。
可以从 Jupyter Lab 打开终端并开始在作业容器中交互。 还可以使用 Jupyter Lab 直接循环访问训练脚本。
还可以在 VS Code 中与作业容器交互。 若要在作业提交期间将调试程序附加到作业并暂停执行,请在此处导航。
注意
使用 VS Code 与作业容器交互时,当前不支持启用专用链接的工作区。
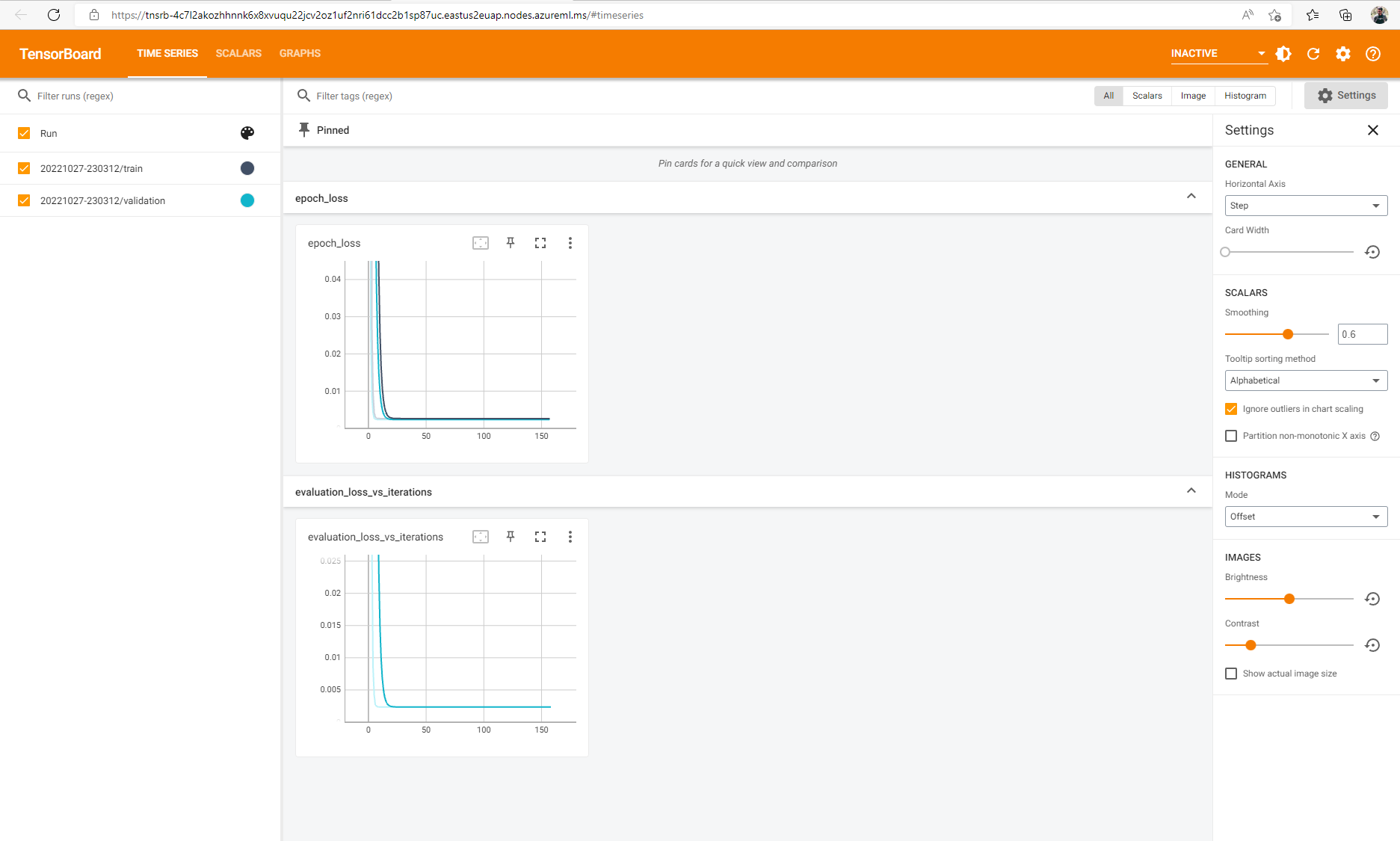
如果已记录作业的 tensorflow 事件,则可以在作业正在运行时使用 TensorBoard 监视指标。
结束作业
完成交互式训练后,还可以转到作业详细信息页来取消将要释放计算资源的作业。 或者,在 CLI 中使用 az ml job cancel -n <your job name> 或在 SDK 中使用 ml_client.job.cancel("<job name>")。

将调试程序附加到作业
若要提交附加了调试程序并暂停了执行的作业,可以使用 debugpy 和 VS Code(debugpy 必须安装在你的作业环境中)。
注意
在 VS Code 中将调试程序附加到作业时,当前不支持启用专用链接的工作区。
- 在作业提交(通过 UI、CLI 或 SDK)期间使用 debugpy 命令运行 python 脚本。 例如,下面的屏幕截图显示了一个示例命令,该命令使用 debugpy 为 tensorflow 脚本附加调试程序(
tfevents.py可以替换为你的训练脚本的名称)。

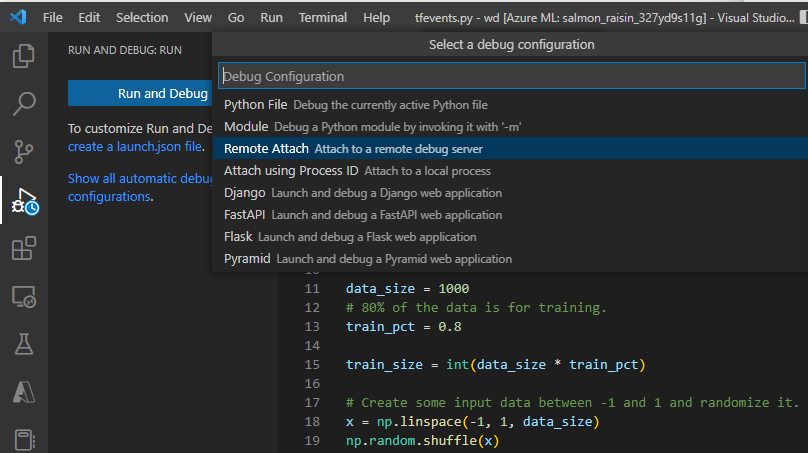
提交作业后,连接到 VS Code,然后选择内置调试程序。

使用“远程附加”调试配置附加到提交的作业,并传入在作业提交命令中配置的路径和端口。 也可以在作业详细信息页上找到此信息。

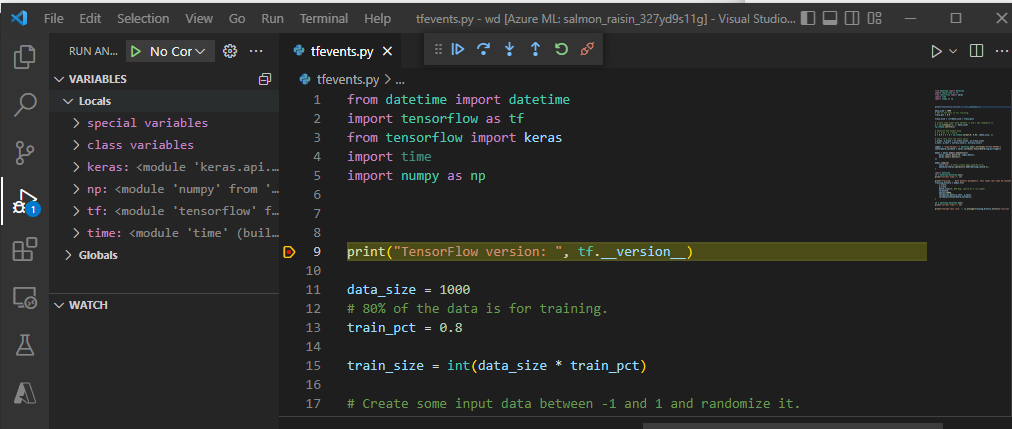
设置断点并演练作业执行,就像在本地的调试工作流中一样。
注意
如果使用 debugpy 启动作业,则作业将不会执行,除非在 VS Code 中附加调试程序并执行脚本。 如果未执行此操作,则将保留计算,直到作业取消。
后续步骤
- 详细了解如何以及在何处部署模型。