Azure 使用配额和限制来防止由于欺诈导致的预算超支,并遵循 Azure 容量约束。 扩展到生产工作负载时,请考虑这些限制。 本文将介绍:
- 与 Azure 机器学习相关的 Azure 资源的默认限制。
- 创建工作区级配额。
- 查看你的配额和限制。
- 请求增大配额。
除了管理配额和限制外,你还可以了解 Azure 机器学习的服务限制。
特殊注意事项
配额适用于帐户中的每个订阅。 如果有多个订阅,则必须为每个订阅请求增加配额。
配额是 Azure 资源的额度限制,不是容量保证。 如果有大规模容量需求,请与 Azure 支持部门联系来增加你的配额。
配额在订阅中的所有服务(包括 Azure 机器学习)之间共享。 你在评估容量时需计算所有服务中的使用量。
注意
Azure 机器学习计算是一个例外。 它有别于核心计算配额,拥有单独的配额。
默认限制因产品/服务类别类型而异,例如试用、标准和虚拟机(VM)系列(如 Dv2、F 和 G)。
默认资源配额和限制
本部分介绍以下资源的默认配额和最大配额和限制:
- Azure 机器学习资产
- Azure 机器学习计算(包括无服务器 Spark)
- Azure 机器学习共享配额
- Azure 机器学习在线终结点(包括托管终结点和 Kubernetes 终结点)和批处理终结点
- Azure 机器学习管道
- 虚拟机
- Azure 容器实例
- Azure 存储
重要
限制可能会更改。 有关最新信息,请参阅 Azure 机器学习中的服务限制。
Azure 机器学习资产
以下资产限制对每个工作区施加。
| 资源 | 最大限制 |
|---|---|
| 数据集 | 1 千万 |
| 运行次数 | 1 千万 |
| 模型 | 1 千万 |
| 组件 | 1 千万 |
| Artifacts | 1 千万 |
最长 运行时 为 30 天, 每个运行记录的最大指标 数为 100 万。
Azure 机器学习计算
Azure 机器学习计算 对 核心数 和订阅中每个区域允许 的唯一计算资源数 具有默认配额限制。
注意
- 核心数的配额按每个 VM 系列和累积总核心数进行拆分。
- 每个区域唯一计算资源数的配额 与 VM 核心配额不同,因为它仅适用于 Azure 机器学习的托管计算资源。
要提高以下项的限制,可以请求增加配额:
- 虚拟机系列核心配额。 若要详细了解要为哪个 VM 系列请求增加配额,请参阅 Azure 中的虚拟机大小。 例如,GPU VM 系列以其家族名称(如NCasT4_v3系列)中的“N”开头。
- 订阅核心配额总数
- 群集配额
- 本部分中的其他资源
可用资源:
每个区域的专用核心数的默认限制为 24 到 300 个,具体取决于订阅套餐的类型。 可以针对每个 VM 系列,提高每个订阅的专用核心数。 专用 VM 系列(如 NCasT4_v3、NC_A100_v4 或 NDv2 系列)从默认为零核心开始。 GPU 也默认为零核。
每个区域的低优先级核心数的默认限制为 100 到 3000 个,具体取决于订阅套餐的类型。 可以增加每个订阅的低优先级核心数。 此限制是 VM 系列中的单个值。
每个区域的总计算限制 在给定订阅中每个区域的默认限制为 500。 可以将此限制增加到每个区域的最大值 2,500。 此限制在训练群集、计算实例和托管联机终结点部署之间共享。 就配额用途来说,可以将计算实例视为单节点群集。
下表显示了平台中的其他限制。 如需申请例外,请通过技术支持工单联系 Azure 机器学习 产品团队。
| 资源或操作 | 最大限制 |
|---|---|
| 每个资源组的工作区数 | 800 |
| 单个 Azure 机器学习计算 (AmlCompute) 群集中配置为未启用通信的池(也就是说,不能运行 MPI 作业)的节点 | 100 个节点,但最多可配置为 65,000 个节点 |
| Azure 机器学习计算 (AmlCompute) 群集上单个并行运行步骤 run 中的节点 | 100 个节点,但如果群集设置允许上述缩放操作,则最多可配置为 65,000 个节点 |
| 单个 Azure 机器学习计算 (AmlCompute) 群集中设置为支持通信池的节点 | 300 个节点,但最多可配置为 4,000 个节点 |
| 单个 Azure 机器学习计算 (AmlCompute) 群集中的节点,这些节点在已启用 RDMA 的 VM 系列虚拟机上配置为支持通信的池 | 100 个节点 |
| 在 Azure 机器学习计算 (AmlCompute) 群集上运行的单个 MPI 中的节点 | 100 个节点 |
| 作业生存期 | 21 天1 |
| 每个节点的参数服务器数 | 1 |
1 最大生存期是指从作业开始到作业完成之间的持续时间。 已完成的作业无限期保留。 在最大生命周期内未完成的作业的数据无法访问。
Azure 机器学习共享配额
Azure 机器学习提供一个共享配额池,用户跨各个区域可以访问该池,以在有限的时间内执行测试,具体取决于可用性。 具体持续时间取决于用例。 如果暂时使用配额池中的配额,则无需为短期提高配额而提交支持票证,也无需等待配额请求获得批准,即可继续处理工作负载。
可以使用共享配额池在短时间内运行 Spark 作业和测试来自模型目录的模型推理。 在通过共享配额部署这些模型之前,必须具有企业协议订阅。
仅使用共享配额创建临时测试终结点,而不是生产终结点。 对于生产中的终结点,请 通过提交支持票证请求专用配额。 共享配额的计费基于使用量,就像专用虚拟机系列的计费方式一样。 要选择退出 Spark 作业的共享配额,请填写Azure 机器学习共享容量分配选择退出表单。
Azure 机器学习联机终结点和批处理终结点
Azure 机器学习联机终结点和批处理终结点具有下表中所述的资源限制。
重要
这些限制是 区域性限制,这意味着,对于所使用的每个区域,最多可以使用这些限制。 例如,如果每个订阅的当前终结点数限制为 100,则可以在“中国东部 2”区域中创建 100 个终结点,在“中国北部 3”区域中创建 100 个终结点,单个订阅中每个支持区域的 100 个终结点。 相同的原则适用于所有其他限制。
若要确定终结点的当前使用情况,请查看指标。
若要向 Azure 机器学习产品团队请求例外,请使用终结点限制提高中的步骤。
| 资源 | 限制 1 | 允许例外情况 | 适用于 |
|---|---|---|---|
| 终结点名称 | 端点名称必须 |
- | 所有类型的终结点 3 |
| 部署名称 | 部署名称必须 |
- | 所有类型的终结点 3 |
| 每个订阅的端点数 | 100 | 是 | 所有类型的终结点 3 |
| 每个群集的终结点数量 | 六十 | - | Kubernetes 联机终结点 |
| 每个订阅的部署数量 | 500 | 是 | 所有类型的终结点 3 |
| 每个终结点的部署数量 | 20 | 是 | 所有类型的终结点 3 |
| 每个群集的部署数 | 100 | - | Kubernetes 联机终结点 |
| 每个部署的实例数 | 50 4 | 是 | 托管联机端点 |
| 端点级最大请求超时 | 180 秒 5 | - | 托管联机端点 |
| 端点级最大请求超时 | 300 秒 | - | Kubernetes 联机终结点 |
| 终结点级别所有部署的每秒请求总数 | 500 6 | 是 | 托管联机端点 |
| 终结点级别所有部署的每秒连接总数 | 500 6 | 是 | 托管联机端点 |
| 终结点级别所有部署的活动连接总数 | 500 6 | 是 | 托管联机端点 |
| 终结点级别所有部署的总带宽 | 5 Mbps 6 | 是 | 托管联机端点 |
1 这是区域限制。 例如,如果当前终结点数限制为 100,则在单个订阅中可以在中国北部 3 区域创建 100 个终结点、在中国东部 2 区域创建 100 个终结点,以及在其他每个受支持的区域创建 100 个终结点。 相同的原则适用于所有其他限制。
终结点和部署名称中可以使用单个短划线如my-endpoint-name。
3 终结点和部署可以是不同类型的,但限制适用于所有类型的总和。 例如,默认情况下,每个订阅下的托管联机终结点、Kubernetes 联机终结点和批处理终结点的总和不能超过每个区域 100 个。 同样,默认情况下,每个订阅下的托管联机部署、Kubernetes 联机部署和批处理部署的总和不能超过 500 个/区域。
4 Azure 机器学习保留 20% 额外的计算资源来执行升级。 例如,如果要在部署中请求 10 个实例,则必须有 12 个实例的配额。 否则,你将收到错误。 某些 VM SKU 不受额外配额限制。 有关配额分配的更多信息,请参阅部署的虚拟机配额分配。
5 请求超时最大值为 180 秒。
每秒 6 个请求、连接、带宽和相关限制。 如果请求增加上述任何限制,请确保一起估算或计算其他相关限制。
用于部署的虚拟机配额分配
对于托管联机终结点,Azure 机器学习会保留 20% 的计算资源,以便在某些 VM SKU 上执行升级。 如果你在某个部署中为这些 VM SKU 请求给定数量的实例,则为了避免收到错误,你必须有 ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU 配额可用。 例如,如果在部署中请求 Standard_DS3_v2 VM(带有 4 个内核)的 10 个实例,则应该为 48 个内核 (12 instances * 4 cores) 提供可用配额。 此额外配额是为系统启动的操作(如 OS 升级和 VM 恢复)保留的,除非此类操作运行,否则不会产生费用。
某些 VM SKU 可以免除额外的配额预留。 要查看完整列表,请参阅《托管在线终结点 SKU 列表》。 若要查看使用情况和请求增加配额,请参阅在 Azure 门户中查看使用情况和配额。 若要查看运行托管联机终结点的成本,请参阅查看托管联机终结点的费用。
Azure 机器学习管道
Azure 机器学习管道具有以下限制。
| 资源 | 限制 |
|---|---|
| 管道内的步骤 | 30,000 |
| 每个资源组的工作区数 | 800 |
虚拟机
每个 Azure 订阅都对所有服务中的虚拟机数量进行了限制。 虚拟机核心数既有区域总数限制,又有按大小系列的区域限制。 这两种限制单独实施。
例如,假设某个订阅在中国东部 2 的 VM 总核心数限制为 30,A 系列核心数限制为 30,D 系列核心数限制也为 30。 可以部署 30 A1 VM 或 30 D1 VM,或两个 VM 的组合,总共不超过 30 个核心。
不能将对虚拟机的限制提升至高于下表中显示的值。
| 资源 | 限制 |
|---|---|
| 与 Microsoft Entra 租户关联的 Azure 订阅 | 无限制 |
| 每个订阅的协同管理员数 | 无限制 |
| 每个订阅的资源组数 | 980 |
| Azure 资源管理器 API 请求大小 | 4,194,304 字节 |
| 每个订阅的标记数1 | 50 |
| 每个订阅的唯一标签计算2 | 80,000 |
| 按位置划分的订阅级部署 | 8003 |
| 订阅级别部署的部署位置 | 10 |
1可以将最多 50 个标记直接应用于一个订阅。 在订阅中,每个资源或资源组也限制为 50 个标记。 但是,订阅可以包含不限数量的标记,这些标记分散在资源和资源组中。
2仅当唯一标记数少于或等于 80,000 时,资源管理器才返回订阅中标记名称和值的列表。 唯一标记是由资源 ID、标记名称和标记值的组合定义的。 例如,具有相同标记名称和值的两个资源将被计算为两个唯一标记。 当数目超过 80,000 时,仍可通过标记找到资源。
3当部署数量接近上限时,部署将自动从历史记录中删除。 有关详细信息,请参阅从部署历史记录中自动删除。
容器实例
有关详细信息,请参阅容器实例限制。
存储
Azure 存储的限制是每个订阅在每个区域中的存储帐户数不能超过 250 个。 此限制包括标准和高级存储帐户。
工作区级别的配额
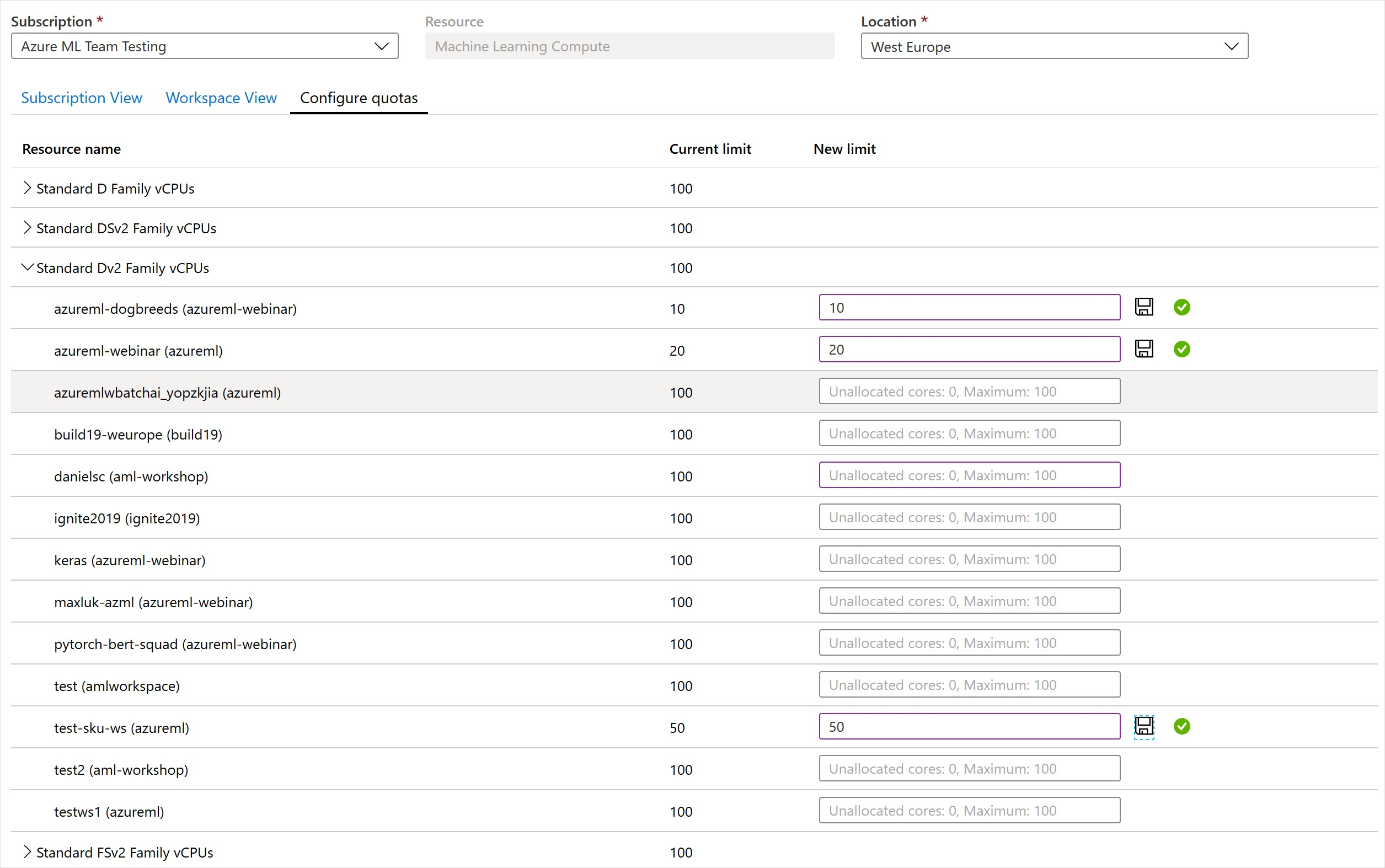
使用工作区级配额来管理同一订阅中多个工作区之间的 Azure 机器学习计算目标分配。
默认情况下,所有工作区的配额与任何 VM 系列的订阅级配额相同。 但是,你可以在订阅中的工作区上设置各个 VM 系列的最大配额。 单个 VM 系列的配额允许共享容量并避免资源争用问题。
- 前往你所订阅的任意工作区。
- 在左侧窗格中,选择“使用量 + 配额”。
- 选择“配置配额”选项卡以查看配额。
- 展开虚拟机系列。
- 对该 VM 系列下列出的任何工作区设置配额上限。
不能设置负值或大于订阅级配额的值。
注意
需要拥有订阅级别的权限才能在工作区级别设置配额。
在工作室查看配额
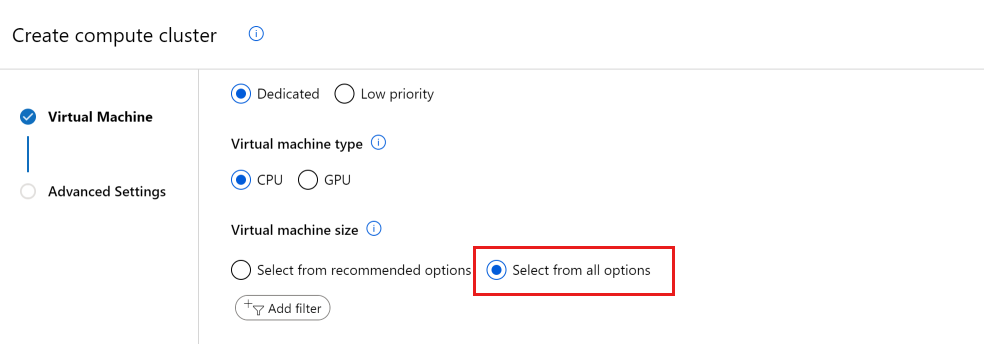
创建新的计算资源时,只会看到已具有要使用的配额的 VM 大小。 将视图切换到“从所有选项中选择”。
向下滚动,直到看到没有配额的 VM 大小的列表。
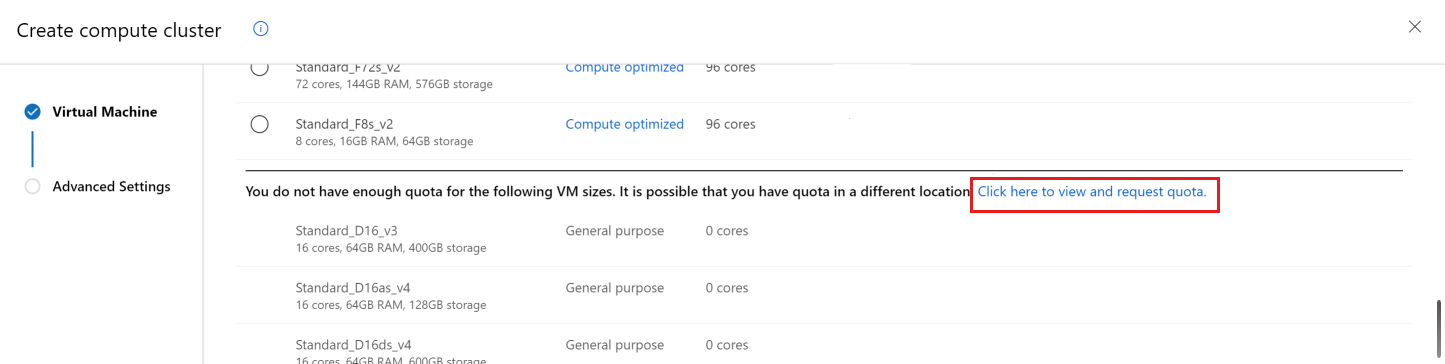
使用该链接可直接前往申请更多配额的在线客户支持页面。
在 Azure 门户中查看使用情况和配额
若要查看各种 Azure 资源(例如虚拟机、存储或网络)的配额,请使用 Azure 门户:
在左窗格上,选择“所有服务”,然后在“一般”类别下选择“订阅” 。
从订阅列表中,选择要查看其配额的订阅。
在 “设置”下,选择 “使用情况 + 配额 ”以查看当前配额限制和使用情况。 使用筛选器选择提供者和位置。
订阅中的 Azure 机器学习计算配额与其他 Azure 配额分开管理:
在 Azure 门户中转到 Azure 机器学习工作区。
在左侧窗格的“支持 + 故障排除”部分中,选择“使用情况 + 配额”以查看当前的配额限制和使用情况 。
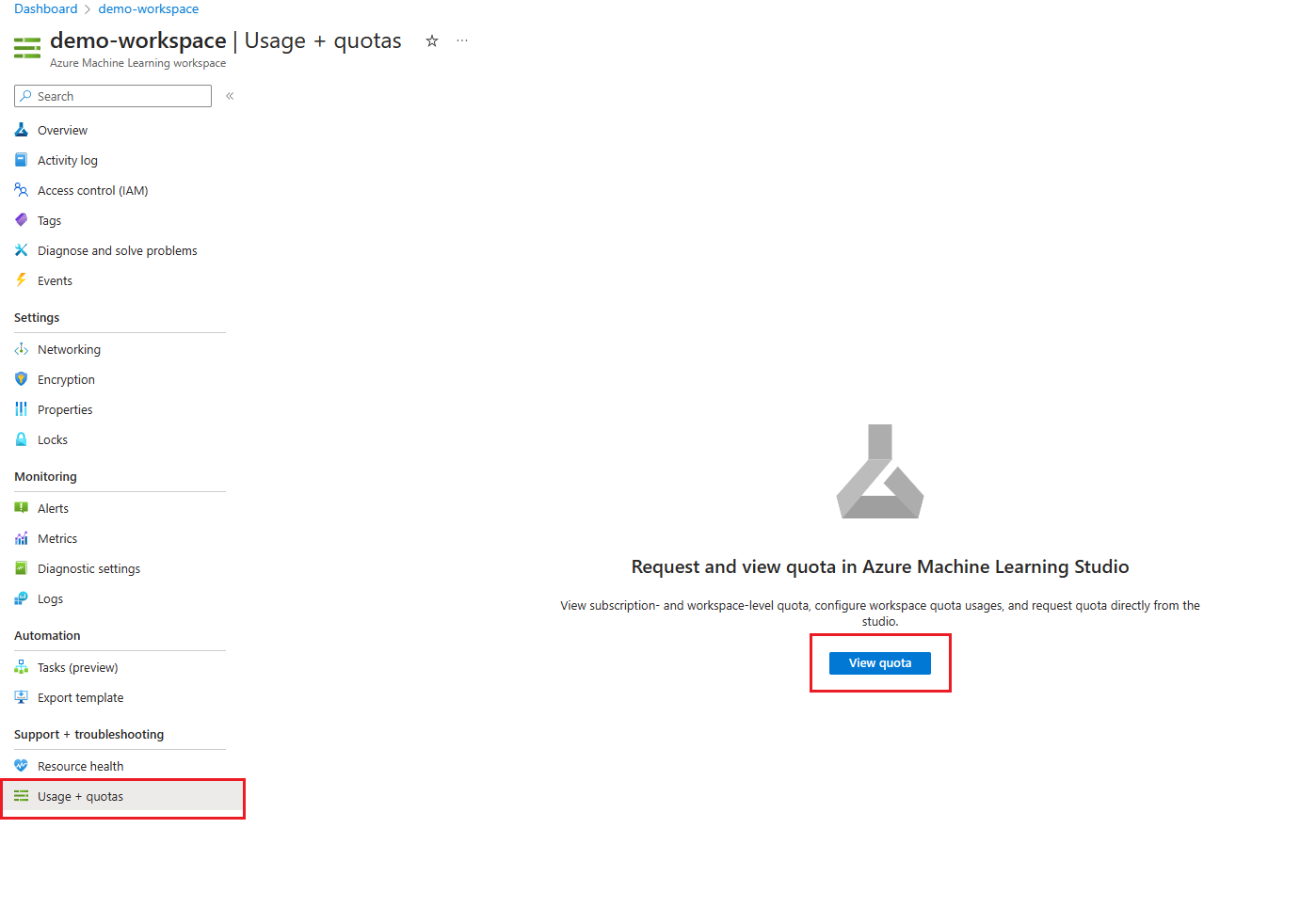
选择订阅以查看配额限制。 筛选出你感兴趣的区域。
你可以在订阅级视图与工作区级视图之间切换。
请求提高配额和限制
VM 配额增加会提高每个区域中每个 VM 系列的核心数。 增加终结点限制会提高每个区域中每个订阅的终结点特定限制。 确保在提交配额提高请求时选择正确的类别,如下一节所述。
虚拟机配额增加
若要提高 Azure 机器学习 VM 配额超出默认限制的限制,请从 “使用情况 + 配额 ”视图请求配额增加,或者从 Azure 机器学习工作室提交配额增加请求。
按照上一部分中的说明转到 “使用情况 + 配额 ”页。 查看当前配额限制。 选择要请求增加配额的 SKU。
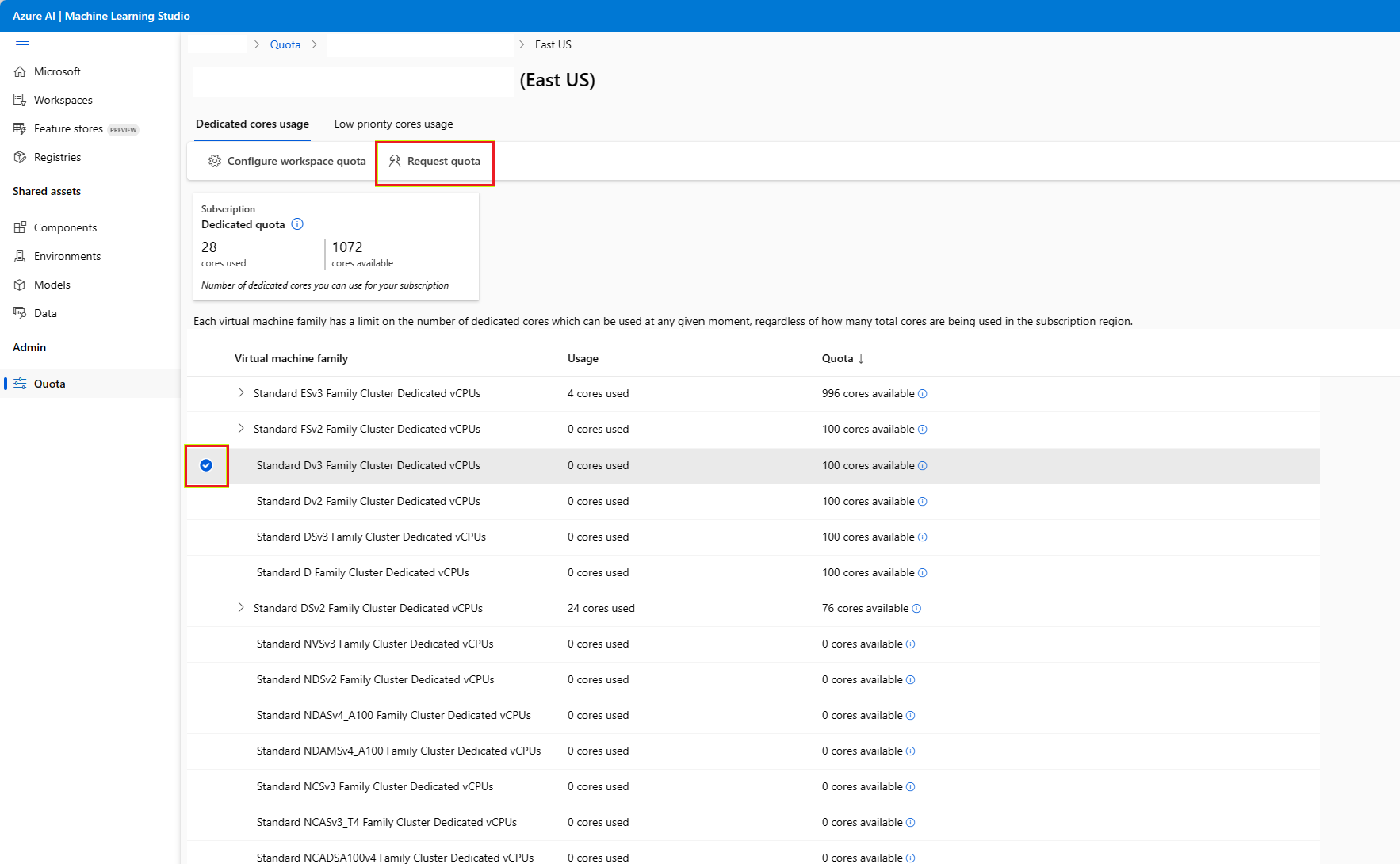
输入要增加的配额和新限制值。 选择“提交”以继续。
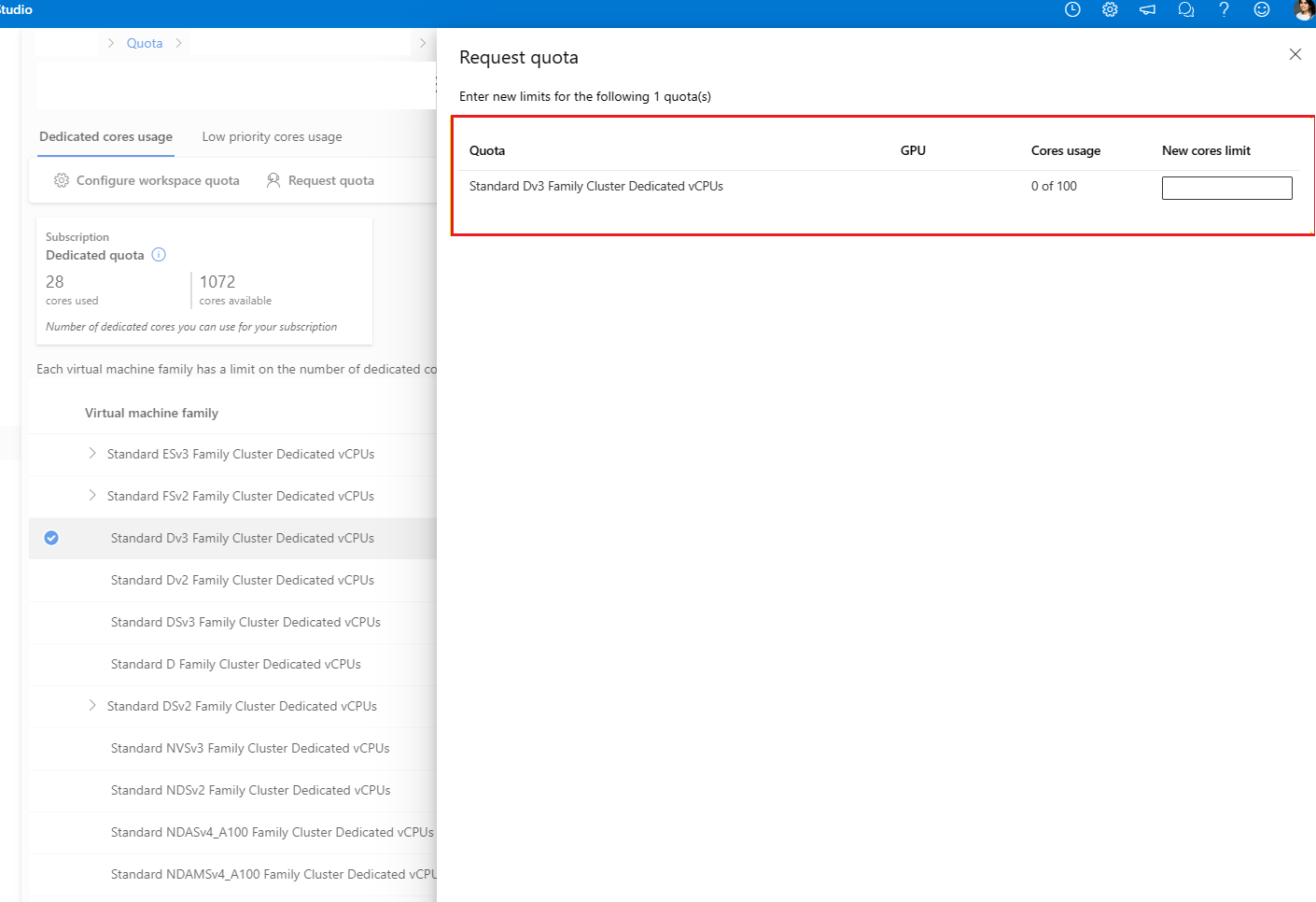
终结点限制提高
若要提高终结点限制, 请提出联机客户支持请求。 请求增加终结点限制时,请提供以下信息:
选择 “服务和订阅限制”(配额) 作为 问题类型。
选择要使用的订阅。
选择“机器学习服务: 终结点限制”作为“配额类型”。
在“ 其他详细信息 ”选项卡上,提供限制增加的详细原因。 选择“输入详细信息”,然后提供你要提高的限制和每个限制的新值、请求提高限制的原因以及需要提高限制的位置。 务必将以下信息添加到提高限制的原因中:
- 场景与工作负荷的说明(如文本、图像等)。
- 请求提高的理由。
- 提供目标吞吐量及其模式(平均/峰值 QPS、并发用户)。
- 提供大规模的目标延迟,以及使用单个实例观察到的当前延迟。
- 提供 VM SKU 和总实例数,以支持目标吞吐量和延迟。 提供计划在每个区域中使用的终结点、部署和实例数。
- 确认是否有基准测试,指示所选 VM SKU 和满足吞吐量和延迟要求的实例数。
- 提供有效负载的类型和单个有效负载的大小。 网络带宽应与负载大小和每秒请求数保持一致。
- 请提供计划时间表(说明你们何时需要提高限额;如果可能,请提供分阶段计划),并确认:(1) 按该规模运行的成本已纳入预算;(2) 目标 VM SKU 已获批准。
选择“保存并继续”。
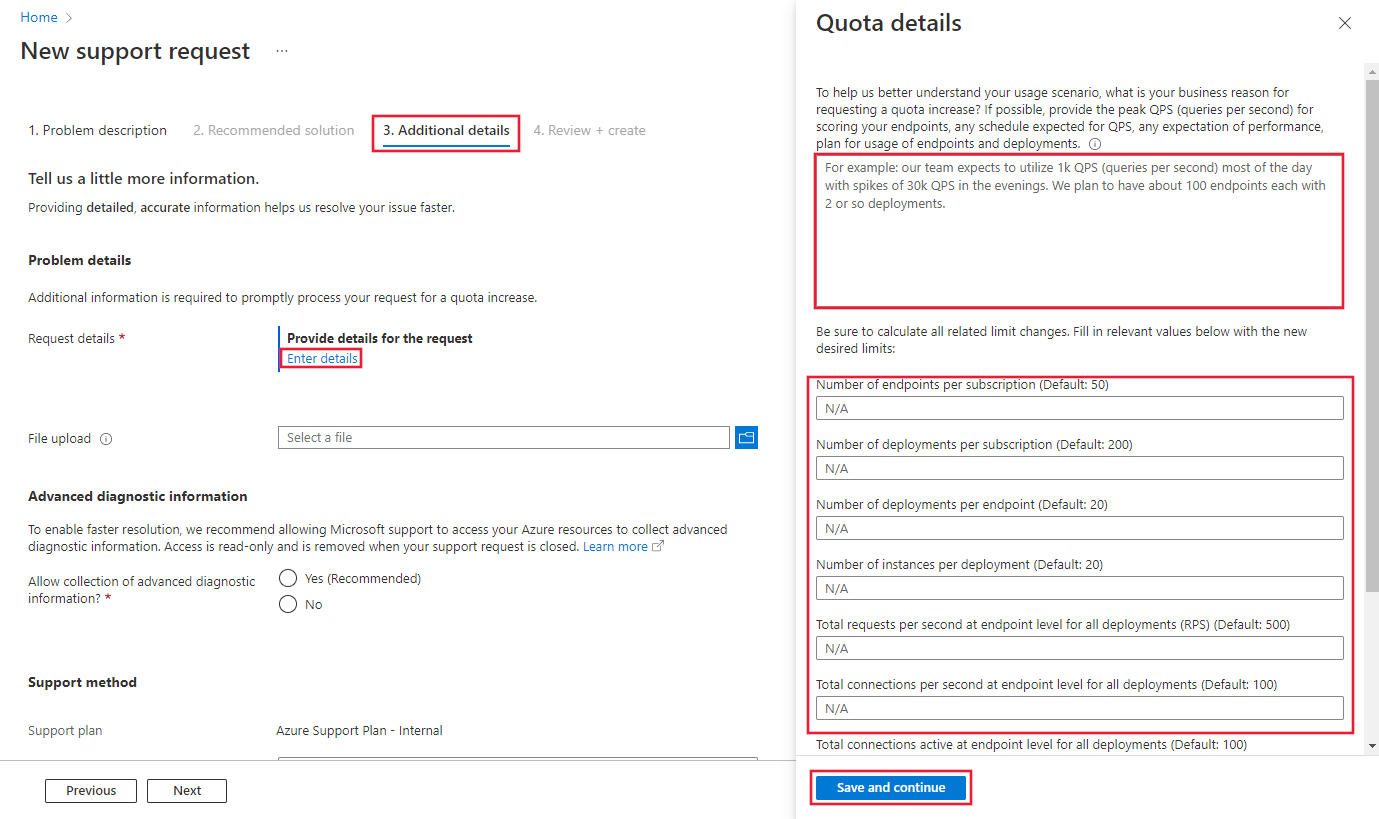
注意
此终结点限制增加请求不同于 VM 配额增加请求。 如果请求与 VM 配额增加相关,请按照 VM 配额增加 部分中的说明进行作。
计算限制增加
若要增加总计算限制, 请提出联机客户支持请求。 提供以下信息:
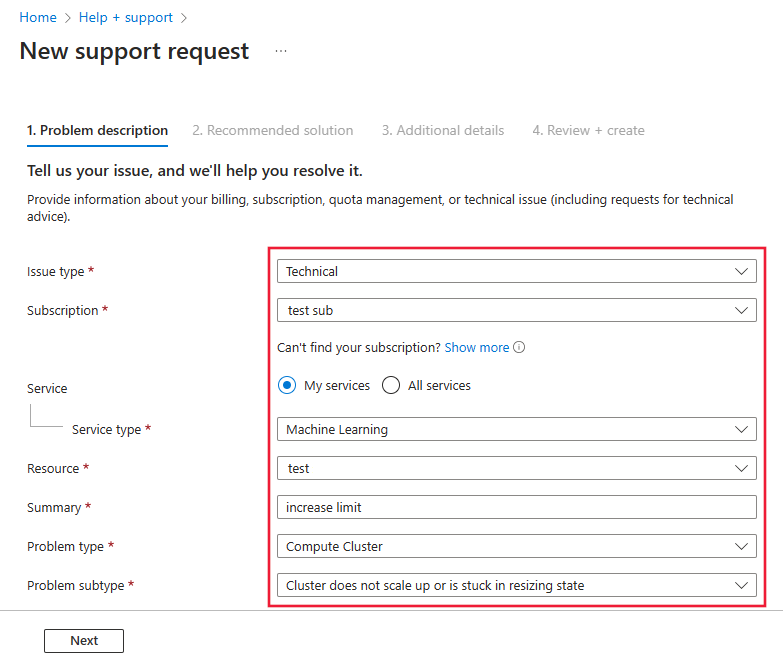
选择 “技术 ”作为 问题类型。
选择要使用的订阅。
选择“机器学习”作为“服务”。
选择要使用的资源。
在摘要中,输入“增加总计算限制”。
选择 计算群集 作为 问题类型,并选择 群集无法增加或卡在调整大小中 作为 问题子类型。
在“ 其他详细信息 ”选项卡上,提供订阅 ID、区域、新限制(介于 500 到 2,500 之间)和业务理由(如果想要增加此区域中的总计算限制)。
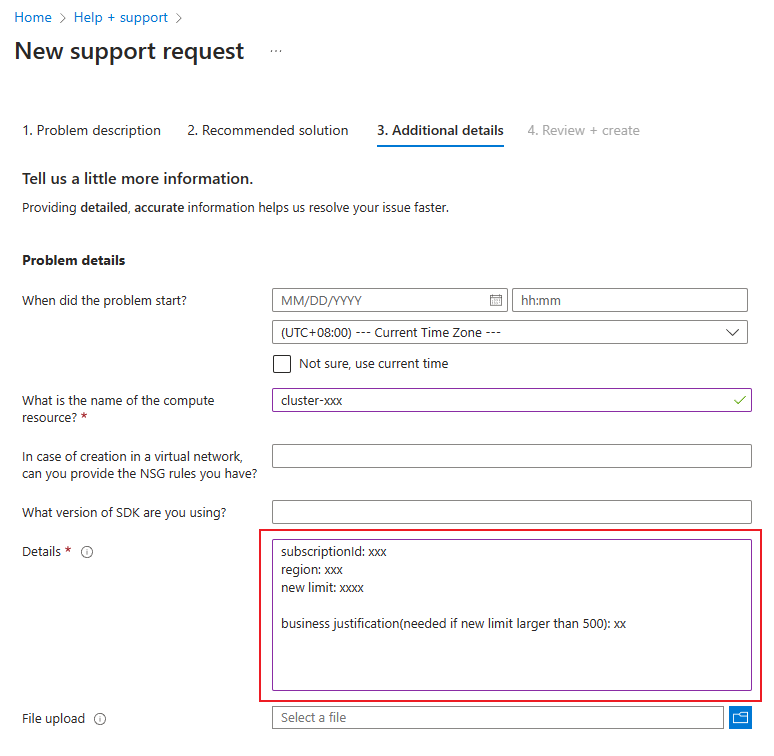
选择“ 创建 ”以创建支持请求票证。