重要
此功能目前处于公开预览状态。 此预览版在提供时没有附带服务级别协议,我们不建议将其用于生产工作负荷。 某些功能可能不受支持或者受限。
有关详细信息,请参阅适用于 Azure 预览版的补充使用条款。
使用 Azure 机器学习托管特征存储可以发现、创建和操作特征。 特征在机器学习生命周期中充当连接组织,该生命周期始于原型制作阶段,在此阶段你可以试验各种特征。 该生命周期会持续到操作化阶段,在此阶段你可以部署模型,并且进行可以查找特征数据的推理步骤。 有关特征平台的详细信息,请参阅特征平台概念。
本教程介绍了如何使用域特定语言开发特征集。 托管特征平台的域特定语言 (DSL) 以一种简单、方便使用的方式来定义最常用的功能聚合。 通过特征平台 SDK,用户可以使用 DSL 表达式来执行最常用的聚合。 与用户定义函数 (UDF) 相比,使用 DSL 表达式的聚合能确保结果一致。 此外,这些聚合可以避免编写 UDF 的开销。
本教程介绍如何
- 创建一个全新的最小特征平台工作区
- 使用域特定语言 (DSL) 在本地开发和测试功能
- 使用用户定义函数 (UDF) 开发特征集,该函数能像使用 DSL 创建的特征集一样执行转换
- 比较分别使用 DSL 和 UDF 创建特征集的结果
- 向功能商店注册功能商店实体
- 将使用 DSL 创建的特征集注册到特征平台
- 使用创建的特征生成示例训练数据
先决条件
注意
本教程将 Azure 机器学习笔记本与无服务器 Spark 计算配合使用。
在继续阅读本教程之前,请确保满足以下先决条件:
- 一个 Azure 机器学习工作区。 如果没有,请参阅快速入门:创建工作区资源了解如何创建。
- 若要执行本文中的步骤,用户帐户必须在待创建特征平台的资源组中持有“所有者”或“参与者”角色。
设置
本教程使用 Python 特征平台的核心 SDK (azureml-featurestore)。 本 SDK 用于在特征平台、特征集和特征平台实体上创建、读取、更新和删除 (CRUD) 操作。
无需为本教程显式安装这些资源,因为在此处所示的设置说明中,conda.yml 文件涵盖了它们。
若要准备用于开发的笔记本环境,请执行以下操作:
使用以下命令将 示例存储库 - (azureml-examples) 克隆到本地计算机上:
git clone --depth 1 https://github.com/Azure/azureml-examples还可以从示例存储库 (azureml-examples) 下载 zip 文件。 在此页中,首先选择
code下拉列表,然后选择Download ZIP。 然后,将内容解压缩到本地计算机上的文件夹中。将特征平台示例目录上传到项目工作区
- 打开 Azure 机器学习工作区的 Azure 机器学习工作室 UI
- 在左侧面板中选择笔记本
- 在目录列表中选择用户名
- 选择省略号 (...),然后选择“上传文件夹”
- 从克隆的目录路径中选择功能商店示例文件夹:
azureml-examples/sdk/python/featurestore-sample
运行教程
- 选项 1:创建新的笔记本,并逐步执行本文档中的说明
- 选项 2:打开现有笔记本
featurestore_sample/notebooks/sdk_only/7.Develop-feature-set-domain-specific-language-dsl.ipynb。 可以将此文档保持打开状态,并参阅此文档以获取更多说明和文档链接
若要配置笔记本环境,则必须上传
conda.yml文件选择左侧面板中的笔记本,然后选择文件标签
导航至
env目录(选择 Users>your_user_name>featurestore_sample>project>env),然后选择conda.yml文件选择“下载”
在顶部的导航“计算”下拉列表中选择“无服务器 Spark 计算”。 此操作可能需要一到两分钟。 等待顶部的状态栏显示“配置会话”
在顶部状态栏中选择“配置会话”
选择“设置”
选择 的“Apache Spark 版本”
Spark version 3.3该操作非必选项,但如果要避免频繁重启无服务器 Spark 会话,请增加 “会话超时”(空闲时间)的数值
在“配置设置”下,定义“属性”
spark.jars.packages和“值”com.microsoft.azure:azureml-fs-scala-impl:1.0.4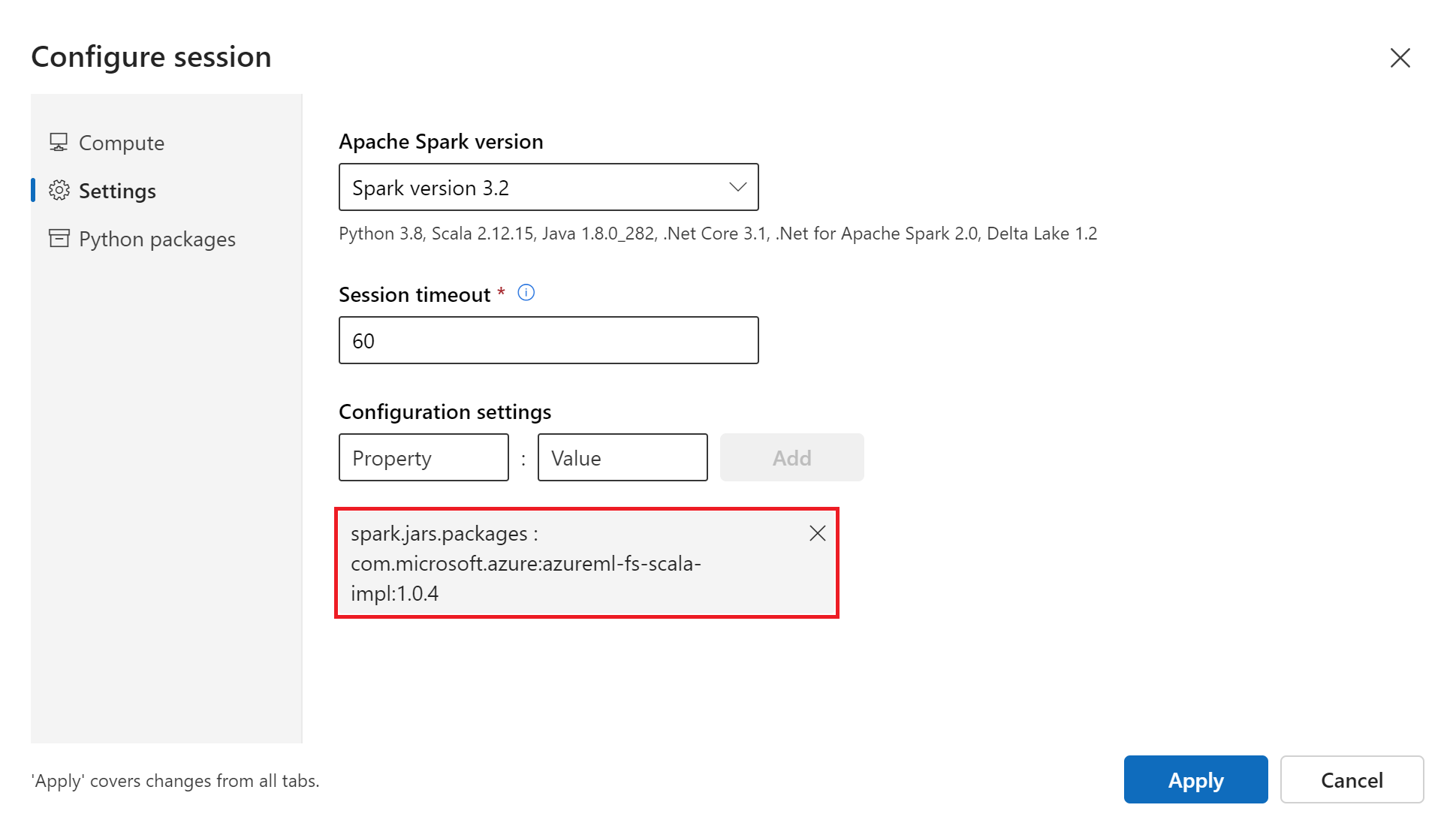
选择“Python 包”
选择“上传 conda 文件”
选择下载到本地设备上的
conda.yml文件选择“应用”
提示
除此该步骤以外,每次启动新的 Spark 会话或会话超时后,都必须运行其他所有步骤。
此代码单元为示例设置根目录并开始 Spark 会话。 安装所有依赖项并启动 Spark 会话大约需要 10 分钟:
import os # Please update your alias USER_NAME below (or any custom directory you uploaded the samples to). # You can find the name from the directory structure in the left nav root_dir = "./Users/USER_NAME/featurestore_sample" if os.path.isdir(root_dir): print("The folder exists.") else: print("The folder does not exist. Please create or fix the path")

预配必要的资源
创建最小的特征平台:
从 Azure 机器学习工作室用户界面上或使用 Azure 机器学习 Python SDK 代码在自选区域中创建特征平台。
选项 1:从 Azure 机器学习工作室用户界面上创建特征平台
- 导航至特征平台用户界面的登陆页面
- 选择“+创建”
- “基本信息”选项卡将会出现
- 选择特征平台的“名称”
- 选择“订阅”
- 选择“资源组”
- 选择“区域”
- 选择“Apache Spark 版本”3.3,然后选择“下一步”
- “具体化”选项卡将会出现
- 切换为“启用具体化”
- 选择“订阅” ,“用户身份”,然后“分配用户托管标识”
- 在“脱机存储”下选择“来自 Azure 订阅”
- 选择“存储名称”和“Azure Date Lake Gen2 文件系统名称”,然后选择“下一步”
- 在“查看”选项卡中查看信息,然后选择“创建”
选项 2:使用 Python SDK 创建特征平台,提供
featurestore_name、featurestore_resource_group_name和featurestore_subscription_id的值,并执行此单元来创建一个最小的特征平台:import os featurestore_name = "<FEATURE_STORE_NAME>" featurestore_resource_group_name = "<RESOURCE_GROUP>" featurestore_subscription_id = "<SUBSCRIPTION_ID>" ##### Create Feature Store ##### from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) featurestore_location = "eastus" fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for featurestore creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())
在脱机存储中为用户标识分配权限:
如果特征数据已具体化,则需要给用户身份分配“存储 Blob 数据读取者”角色,才能从脱机具体化存储中读取特征数据。
- 打开 Azure 机器学习全球登陆页
- 在左侧导航中选择“特征平台”
- 此时会显示可访问的特征平台列表。 选择先前创建的特征平台
- 在“脱机具体化存储”卡选择“帐户名称”下的存储帐户链接,导航到脱机存储的 ADLS Gen2 存储帐户

- 请访问此资源 ,详细了解如何在 ADLS Gen2 的脱机存储帐户为用户身份分配“存储 Blob 数据数据读取者”角色。 等待权限传播。

可用的 DSL 表达式和基准
目前支持以下聚合表达式:
- 平均 -
avg - 求和 -
sum - 计数 -
count - 最小 -
min - 最大 -
max
下表提供的基准可以比较分别使用 DSL 表达式和 UDF 的聚合之间的性能,使用 23.5 GB 大小的代表性数据集,属性如下:
-
numberOfSourceRows: 348,244,374 -
numberOfOfflineMaterializedRows: 227,361,061
| 函数 | 表达式 | UDF 执行时间 | DSL 执行时间 |
|---|---|---|---|
get_offline_features(use_materialized_store=false) |
sum,avg,count |
~2 小时 | < 5 分钟 |
get_offline_features(use_materialized_store=true) |
sum,avg,count |
~1.5 小时 | < 5 分钟 |
materialize() |
sum,avg,count |
~1 小时 | < 15 分钟 |
注意
min 和 max DSL 表达式相较 UDF 没有任何性能改进。 建议对 min 和 max 转换使用 UDF。
使用 DSL 表达式创建特征集规范
执行此代码单元以创建特征集规范,使用 DSL 表达式和 parquet 文件作为源数据。
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts.feature import Feature from azureml.featurestore.transformation import ( TransformationExpressionCollection, WindowAggregation, ) from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource dsl_feature_set_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), index_columns=[Column(name="accountID", type=ColumnType.string)], features=[ Feature(name="f_transaction_3d_count", type=ColumnType.Integer), Feature(name="f_transaction_amount_3d_sum", type=ColumnType.DOUBLE), Feature(name="f_transaction_amount_3d_avg", type=ColumnType.DOUBLE), Feature(name="f_transaction_7d_count", type=ColumnType.Integer), Feature(name="f_transaction_amount_7d_sum", type=ColumnType.DOUBLE), Feature(name="f_transaction_amount_7d_avg", type=ColumnType.DOUBLE), ], feature_transformation=TransformationExpressionCollection( transformation_expressions=[ WindowAggregation( feature_name="f_transaction_3d_count", aggregation="count", window=DateTimeOffset(days=3), ), WindowAggregation( feature_name="f_transaction_amount_3d_sum", source_column="transactionAmount", aggregation="sum", window=DateTimeOffset(days=3), ), WindowAggregation( feature_name="f_transaction_amount_3d_avg", source_column="transactionAmount", aggregation="avg", window=DateTimeOffset(days=3), ), WindowAggregation( feature_name="f_transaction_7d_count", aggregation="count", window=DateTimeOffset(days=7), ), WindowAggregation( feature_name="f_transaction_amount_7d_sum", source_column="transactionAmount", aggregation="sum", window=DateTimeOffset(days=7), ), WindowAggregation( feature_name="f_transaction_amount_7d_avg", source_column="transactionAmount", aggregation="avg", window=DateTimeOffset(days=7), ), ] ), ) dsl_feature_set_spec此代码单元规定特征窗口的开始和结束时间。
from datetime import datetime st = datetime(2020, 1, 1) et = datetime(2023, 6, 1)此代码单元使用
to_spark_dataframe()从上述通过 DSL 表达式定义的特征集规范中获取规定特征窗口的数据帧:dsl_df = dsl_feature_set_spec.to_spark_dataframe( feature_window_start_date_time=st, feature_window_end_date_time=et )打印 DSL 表达式定义的特征集中的一些示例特征值:
display(dsl_df)
使用 UDF 创建特征集规范
创建使用 UDF 执行相同转换的特征集规范:
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) udf_feature_set_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), transformation_code=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], infer_schema=True, ) udf_feature_set_spec此转换代码显示 UDF 定义的转换与 DSL 表达式的相同:
class TransactionFeatureTransformer(Transformer): def _transform(self, df: DataFrame) -> DataFrame: days = lambda i: i * 86400 w_3d = ( Window.partitionBy("accountID") .orderBy(F.col("timestamp").cast("long")) .rangeBetween(-days(3), 0) ) w_7d = ( Window.partitionBy("accountID") .orderBy(F.col("timestamp").cast("long")) .rangeBetween(-days(7), 0) ) res = ( df.withColumn("transaction_7d_count", F.count("transactionID").over(w_7d)) .withColumn( "transaction_amount_7d_sum", F.sum("transactionAmount").over(w_7d) ) .withColumn( "transaction_amount_7d_avg", F.avg("transactionAmount").over(w_7d) ) .withColumn("transaction_3d_count", F.count("transactionID").over(w_3d)) .withColumn( "transaction_amount_3d_sum", F.sum("transactionAmount").over(w_3d) ) .withColumn( "transaction_amount_3d_avg", F.avg("transactionAmount").over(w_3d) ) .select( "accountID", "timestamp", "transaction_3d_count", "transaction_amount_3d_sum", "transaction_amount_3d_avg", "transaction_7d_count", "transaction_amount_7d_sum", "transaction_amount_7d_avg", ) ) return res使用
to_spark_dataframe()从上述 UDF 定义的特征集规范中获取数据帧:udf_df = udf_feature_set_spec.to_spark_dataframe( feature_window_start_date_time=st, feature_window_end_date_time=et )比较结果并验证 DSL 表达式的结果与通过 UDF 执行的转换之间的一致性。 选择一个
accountID值以比较两个数据帧中的值,以此进行验证:display(dsl_df.where(dsl_df.accountID == "A1899946977632390").sort("timestamp"))display(udf_df.where(udf_df.accountID == "A1899946977632390").sort("timestamp"))
将特征集规范导出为 YAML
若要在特征平台中注册特征集规范,则必须以特定格式保存。 若要检查生成的 transactions-dsl 特征集规范,在文件树中打开此文件以查看规范:featurestore/featuresets/transactions-dsl/spec/FeaturesetSpec.yaml
特征集规范包含以下元素:
-
source:对存储资源的引用;在本例中是 blob 存储中的 parquet 文件 -
features:包含特征及其数据类型的列表。 如果提供转换代码,该代码必须返回映射到特征和数据类型的数据帧 -
index_columns:访问特征集数值所需的联接键
有关更多信息,请参阅顶级特征平台实体文档和特征集规范 YAML 引用资源。
坚持使用特征集规范的另一个好处是它可以由源代码管理。
执行此代码单元以使用 parquet 数据源和 DSL 表达式为特征集编写 YAML 规范文件:
dsl_spec_folder = root_dir + "/featurestore/featuresets/transactions-dsl/spec" dsl_feature_set_spec.dump(dsl_spec_folder, overwrite=True)执行此代码单元以使用 UDF 为特征集编写 YAML 规范文件:
udf_spec_folder = root_dir + "/featurestore/featuresets/transactions-udf/spec" udf_feature_set_spec.dump(udf_spec_folder, overwrite=True)
初始化 SDK 客户端
本教程中的以下步骤使用两个 SDK。
特征平台 CRUD SDK:Azure 机器学习 (AzureML) SDK
MLClient(包名称azure-ai-ml),类似于 Azure 机器学习工作区使用的 SDK。 此 SDK 能够辅助特征平台的 CRUD 操作,- 创建
- 读取
- 更新
- 删除
适合特征平台和特征集实体,因为特征平台是作为 Azure 机器学习工作区类型实现的
特征平台核心 SDK:此 SDK (
azureml-featurestore) 能够辅助特征集的开发和使用:from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential from azureml.featurestore import FeatureStoreClient fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, ) featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )
在特征平台中注册 account 实体
创建帐户实体,该实体具有 accountID 类型的联接键 string:
from azure.ai.ml.entities import DataColumn
account_entity_config = FeatureStoreEntity(
name="account",
version="1",
index_columns=[DataColumn(name="accountID", type="string")],
)
poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config)
print(poller.result())
将 特征集注册到特征存储
将(使用 DSL的)
transactions-dsl特征集注册到特征平台,并启用脱机具体化以及使用导出的特征集规范:from azure.ai.ml.entities import ( FeatureSet, FeatureSetSpecification, MaterializationSettings, MaterializationComputeResource, ) materialization_settings = MaterializationSettings( offline_enabled=True, resource=MaterializationComputeResource(instance_type="standard_e8s_v3"), spark_configuration={ "spark.driver.cores": 4, "spark.driver.memory": "36g", "spark.executor.cores": 4, "spark.executor.memory": "36g", "spark.executor.instances": 2, }, schedule=None, ) fset_config = FeatureSet( name="transactions-dsl", version="1", entities=["azureml:account:1"], stage="Development", specification=FeatureSetSpecification(path=dsl_spec_folder), materialization_settings=materialization_settings, tags={"data_type": "nonPII"}, ) poller = fs_client.feature_sets.begin_create_or_update(fset_config) print(poller.result())具体化特征集以将转换的特征数据持续存储到脱机存储中:
poller = fs_client.feature_sets.begin_backfill( name="transactions-dsl", version="1", feature_window_start_time=st, feature_window_end_time=et, spark_configuration={}, data_status=["None", "Incomplete"], ) print(poller.result().job_ids)执行此代码单元以跟踪具体化作业的进度:
# get the job URL, and stream the job logs (the back fill job could take 10+ minutes to complete) fs_client.jobs.stream(poller.result().job_ids[0])打印特征集中的示例数据。 输出信息显示数据是从具体化存储中检索的。
get_offline_features()方法用于检索训练/推理数据,默认情况下也使用具体化存储:# look up the featureset by providing name and version transactions_featureset = featurestore.feature_sets.get("transactions-dsl", "1") display(transactions_featureset.to_spark_dataframe().head(5))
使用注册好的特征集生成训练数据帧
加载观察数据
观察数据通常是训练和推理步骤中使用的核心数据。 然后,观察数据与特征数据联接,以创建完整的训练数据资源。 观察数据是在事件发生期间捕获的数据。 这种情况具有核心事务数据,包括事务 ID、帐户 ID 和事务金额值。 由于该数据用于训练,它也追加了目标变量 (is_fraud)。
首先,浏览观察数据:
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted value选择会成为训练数据一部分的特征,并使用特征平台 SDK 生成训练数据:
featureset = featurestore.feature_sets.get("transactions-dsl", "1") # you can select features in pythonic way features = [ featureset.get_feature("f_transaction_amount_7d_sum"), featureset.get_feature("f_transaction_amount_7d_avg"), ] # you can also specify features in string form: featureset:version:feature more_features = [ "transactions-dsl:1:f_transaction_amount_3d_sum", "transactions-dsl:1:f_transaction_3d_count", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features)get_offline_features()函数使用时间点联接将特征追加到观察数据中。 显示从时间点联接获取的训练数据帧:from azureml.featurestore import get_offline_features training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) display(training_df.sort("transactionID", "accountID", "timestamp"))
使用 DSL 和 UDF 从特征集中生成训练数据帧
将(使用 UDF 的)
transactions-udf特征集注册到特征平台,并使用导出的特征集规范。 为此特征集启用脱机具体化并在特征平台中注册:fset_config = FeatureSet( name="transactions-udf", version="1", entities=["azureml:account:1"], stage="Development", specification=FeatureSetSpecification(path=udf_spec_folder), materialization_settings=materialization_settings, tags={"data_type": "nonPII"}, ) poller = fs_client.feature_sets.begin_create_or_update(fset_config) print(poller.result())从要成为训练数据一部分的特征集(使用 DSL 和 UDF 创建)中选择特征,并使用特征平台 SDK 生成训练数据:
featureset_dsl = featurestore.feature_sets.get("transactions-dsl", "1") featureset_udf = featurestore.feature_sets.get("transactions-udf", "1") # you can select features in pythonic way features = [ featureset_dsl.get_feature("f_transaction_amount_7d_sum"), featureset_udf.get_feature("transaction_amount_7d_avg"), ] # you can also specify features in string form: featureset:version:feature more_features = [ "transactions-udf:1:transaction_amount_3d_sum", "transactions-dsl:1:f_transaction_3d_count", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features)get_offline_features()函数使用时间点联接将特征追加到观察数据中。 显示从时间点联接获取的训练数据帧:from azureml.featurestore import get_offline_features training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) display(training_df.sort("transactionID", "accountID", "timestamp"))
特征通过时间点联接追加到训练数据中。 生成的训练数据可用于后续训练和批量推理步骤。
清理
本系列的教程五将介绍如何删除资源。