Azure AI 搜索中的可靠性
在 Azure 中,可靠性是指在服务中断或降级时保持复原能力和可用性。 在 Azure AI 搜索中,可靠性是通过以下方式实现的:
部署单个搜索服务并纵向扩展以实现高可用性。 可以添加多个副本来处理更高的索引编制和查询工作负载。 如果你的搜索服务支持可用性区域,则会在不同的物理数据中心自动预配副本,以进一步提高复原能力。
跨不同地理区域部署多个搜索服务。 所有搜索工作负载都完全包含在运行于单个地理区域中的单个服务中,但在多服务方案中,你可以选择同步内容,使其在所有服务中保持相同。 你还可以设置负载均衡解决方案,以便在发生服务中断时重新分发请求或进行故障转移。
若要在发生区域级别的灾难时实现业务连续性和恢复,请规划一种跨区域拓扑,该拓扑由具有相同配置和内容的多个搜索服务组成。 如果某个搜索服务突然不可用,自定义脚本或代码可提供“故障转移”到备用搜索服务的机制。
高可用性
在 Azure AI 搜索中,副本是索引的副本。 一项搜索服务至少需要委托一个副本,最多可以有 12 个副本。 添加副本可让 Azure AI 搜索针对一个副本执行计算机重启和维护,同时可继续针对其他副本执行查询。
对于每个单独的搜索服务,Azure 保证满足以下条件的配置至少有 99.9% 的可用性:
对于只读工作负荷(查询),需要有两个副本才能实现高可用性
针对读写工作负载(查询和索引),需要有三个或更多副本才可实现高可用性
系统具有用于监视副本运行状况和分区完整性的内部机制。 如果预配特定的副本和分区组合,系统将确保为服务提供该级别的容量。
没有为免费层提供 SLA。 有关详细信息,请参阅 Azure AI 搜索的 SLA。
可用性区域支持
可用性区域是一种 Azure 平台功能,将一个地区的数据中心分成不同的物理位置组,以在同一地区内提供高可用性。 在 Azure AI 搜索中,单个副本是区域分配单位。 搜索服务在一个区域中运行;其副本在该区域中的不同物理数据中心(或地区)内运行。
将两个或更多个副本添加到搜索服务时,将使用可用性区域。 每个副本将放置在该地区内不同的可用性区域中。 如果你的副本数超过搜索服务区域中的可用性区域数,则副本将尽量均匀地在可用性区域之间分布。 除了在提供可用性区域的区域中创建搜索服务,然后将该服务配置为使用多个副本之外,没有具体要你执行的操作。
先决条件
- 服务层级必须为“标准”或更高。
- 服务区域必须位于具有可用性区域的区域(如以下部分所列)中。
- 配置必须包含多个副本:两个副本用于只读查询工作负载,三个副本用于包含索引的读写工作负载。
以下区域支持 Azure AI 搜索的可用性区域:
| 区域 | 推出 |
|---|---|
| 中国北部 3 | 2022 年 9 月 7 日或之后 |
注意
可用性区域不会更改 Azure AI 搜索服务级别协议的条款。 仍需 3 个或更多个副本来实现查询高可用性。
不同地理区域中的多个服务
如果需要满足以下操作要求,则必须提供服务冗余:
业务连续性和灾难恢复 (BCDR) 要求(发生服务中断时,Azure AI 搜索不会提供即时故障转移)。
全局分布式应用程序的快速性能。 如果查询和索引请求来自世界各地,则离主机数据中心最近的用户可以体验到更快的性能。 在靠近这些用户的地区创建更多服务可以使所有用户的性能一致。
如果你需要两个或更多搜索服务,那么在不同的区域创建它们可以满足应用程序对连续性和恢复的要求,并为全球用户群提供更快的响应时间。
Azure AI 搜索当前不提供自动化方法来跨区域异地复制搜索索引,但有一些技巧,可以用来轻松地实现和管理使此过程。 我们会在下面几节介绍这些技巧。
地理分散的搜索服务集的目标是,让两个或更多索引在两个或更多区域中可用,在这些区域中用户会被路由到 Azure AI 搜索服务,以提供最低延迟:
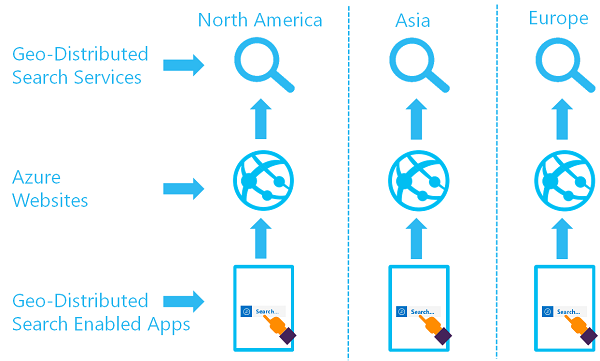
可以通过创建多项服务并设计数据同步策略来实现此体系结构。 可以选择包含资源(如 Azure 流量管理器)来路由请求。
提示
如需有关跨多个区域部署多个搜索服务的帮助,请参阅 GitHub 上的此 Bicep 示例,该示例将部署一个全面配置的多区域搜索解决方案。 该示例提供了两个选项用于通过流量管理器实现索引同步和请求重定向。
跨多个服务同步数据
可以通过两个选项来使两个或更多个不同搜索服务保持同步:
- 使用索引器将内容更新拉取到搜索索引中。
- 使用添加或更新文档 (REST) API 或等效的 Azure SDK API 将内容推送到索引中。
若要配置任一选项,建议使用 azure-search-multiple-region 存储库中的示例 Bicep 脚本,并根据你的区域和索引策略对其进行修改。
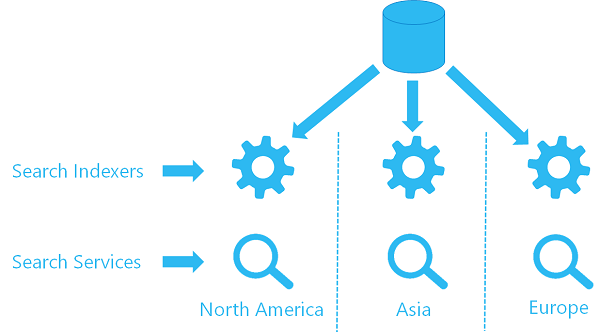
选项 1:使用索引器更新多个服务中的内容
如果已在一个服务中使用索引器,可以在另一个服务中配置另一个索引器,以使用相同的数据源对象,并从相同的位置提取数据。 每个区域中的每个服务都有其自身的索引器和目标索引(搜索索引不会共享,这意味着每个索引都有自身的数据副本),但每个索引器引用相同的数据源。
下面是该体系结构的概要视图。
选项 2:使用 REST API 在多个服务中推送内容更新
如果使用 Azure AI 搜索 REST API 推送搜索索引中的内容,则可以在需要更新时,通过将更改推送到所有搜索服务来保持各种搜索服务同步。 在代码中,请确保处理好这种情况:对一个搜索服务的更新失败,但对于其他搜索服务成功。
故障转移或重定向查询请求
如果你需要请求级别的冗余,可以使用 Azure 提供的多个负载均衡选项:
- Azure 流量管理器,用于将请求路由到多个地理定位的网站,而这些网站由多个搜索服务支持。
- 应用程序网关,用于在区域中应用程序层的服务器之间进行负载均衡。
- Azure Front Door,用于优化 Web 流量的全局路由并提供全局故障转移。
评估负载均衡选项时需要牢记几个要点:
搜索是一项后端服务,它接受来自客户端的查询和索引请求。
客户端向搜索服务发出的请求必须经过身份验证。 若要访问搜索操作,调用方必须具有基于角色的权限或在请求中提供 API 密钥。
默认通过公共 Internet 连接来访问服务终结点。 如果为源自虚拟网络的客户端连接设置专用终结点,请使用应用程序网关。
Azure AI 搜索接受发送至
<your-search-service-name>.search.azure.cn终结点的请求。 如果在主机头中使用不同的 DNS 名称(例如 CNAME)访问同一终结点,则请求将被拒绝。
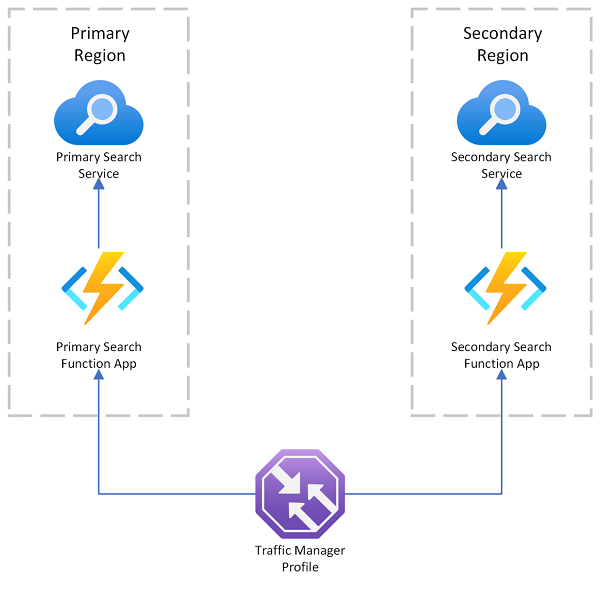
Azure AI 搜索提供了一个多区域部署示例,该示例在主终结点发生故障时使用 Azure 流量管理器进行请求重定向。 当路由到仅调用同一区域中搜索服务的已启用搜索的客户端时,此解决方案非常有用。
Azure 流量管理器主要用于根据特定路由方法(例如优先级、性能或地理位置)跨不同的终结点路由网络流量。 它在 DNS 级别发挥作用,将传入请求定向到适当的终结点。 如果流量管理器所服务的终结点开始拒绝请求,则流量将路由到另一个终结点。
流量管理器不为终结点提供与 Azure AI 搜索的直接连接,这意味着,你不能将搜索服务直接放在流量管理器的后面。 相反,所做的假设是请求流向流量管理器,然后流向已启用搜索的 Web 客户端,最后流向后端上的搜索服务。 客户端和服务位于同一区域。 如果某个搜索服务发生故障,搜索客户端就会开始发生故障,而流量管理器会重定向到其余客户端。
关于多区域部署中的数据驻留
在不同的地理区域中部署多个搜索服务时,内容将存储在你为每个搜索服务选择的区域中。
Azure AI 搜索不会在未经授权的情况下将数据存储在指定区域之外。 使用如下写入 Azure 存储资源的功能时,授权是隐式的:扩充缓存、调试会话、知识存储。 在所有情况下,存储帐户都是你在所选区域中提供的帐户。
注意
如果存储帐户和搜索服务位于同一区域,则搜索和存储之间的网络流量就会使用专用 IP 地址进行通信并通过 Microsoft Azure 主干网络执行相应操作。 由于使用了专用 IP 地址,因此无法为网络安全配置 IP 防火墙或专用终结点。 相反,当这两个服务都位于同一区域时,请使用受信任的服务异常 作为替代方法。
关于服务中断和灾难性事件
如服务级别协议 (SLA) 中所述,当 Azure AI 搜索服务实例配置有两个或更多副本时,Azure 保证索引查询请求的高可用性,当 Azure AI 搜索服务实例配置有三个或更多副本时,我们保证索引更新请求的高可用性。 但是,没有任何内置的机制可实现灾难恢复。 如果在超出 Azure 控制的灾难性故障中需要连续性服务,建议在其他区域预配另一个服务并实施异地复制策略,以确保索引跨所有服务完全冗余。
使用索引器来填充和刷新索引的客户可以通过从同一数据源检索数据的特定于地区的索引器来处理灾难恢复。 不同区域的两个服务(每个都运行索引器)可对相同数据源进行索引,实现异地冗余。 如果从同样异地冗余的数据源编制索引,请记住 Azure AI 搜索索引器只能从主要副本执行增量索引编制(从新的、已修改的或已删除的文档合并更新)。 在故障转移事件中,请确保将索引器重定向到新的主要副本。
如果不使用索引器,也可使用应用程序代码将对象和数据并行推送到其他搜索服务。 有关详细信息,请参阅在多个服务之间保持数据同步。
备份和还原替代项
数据层的业务连续性策略通常包括“从备份还原”步骤。 由于 Azure AI 搜索不是主数据存储解决方案,因此,Azure 不提供正式的自助备份和还原机制。 但是,你可以使用此 Azure AI 搜索 .NET 示例存储库中的 index-backup-restore 示例代码将索引定义和快照备份到一系列 JSON 文件,然后根据需要使用这些文件来还原索引。 还可以使用此工具在服务层级之间移动索引。
在其他情况下,如果误删索引,用于创建和填充索引的应用程序代码是事实上的还原选项。 要重新生成索引,请删除它(假设其存在),在服务中重新创建该索引,并通过从主数据存储中检索数据来重新加载该索引。
后续步骤
- 查看服务限制以详细了解定价层和每个层的服务限制。
- 查看规划容量以详细了解分区和副本的组合。
- 查看案例研究:使用认知搜索支持复杂的 AI 方案以获取更多配置指导。