Azure AI 搜索提供了两种以不同方式处理容量的定价模型:
专用:通过调整副本和分区大小并选择服务层级来规划容量。
- 使用副本和分区直接预配容量。
- 估计所需的存储(分区)和所需的吞吐量(副本)。
- 选择服务层级,根据预期的峰值需求预配所需的容量。
- 提前配置容量后,无论使用情况如何,都按搜索单位(SU)支付每小时费率。
无服务器(预览版):服务根据使用情况和服务限制自动管理容量。 无需预预配容量。 相反,请优化工作负荷效率以管理成本。
- 容量随需求自动缩放(空闲时可缩放为零)。
- 您将按计算单位(CU)和存储的实际用量计费。
- 规划关注的不是基础设施,而是以下成本驱动因素:查询模式、索引大小及其增长,以及数据引入方式。 请参阅 “针对无服务器模型优化成本”。
| Dimension | 专属 | Serverless |
|---|---|---|
| 容量模型 | 预配量(副本 × 分区) | 基于用量 |
| 规模化 | 手动 | 自动 |
| 用户控件 | 显式(配置副本和分区) | 间接(受工作负荷特征影响) |
| Billing | 每个搜索单位 (SU) 的固定小时费率 | 计算单位 (CU) 和存储的基于用量的付费 |
| 空闲成本 | 始终产生(最低预配容量) | 空闲时可缩减至零 |
| 优化重点 | 基础设施容量规划 | 工作负荷效率 |
| 最适用于 | 可预测且稳定的工作负荷 | 波动性的、突发性的或多租户工作负载,包括代理驱动的场景 |
| 容量规划方法 | 调整和扩展基础设施规模(副本和分区) | 优化工作负荷效率和使用模式 |
| 效率低下的影响 | 延迟与扩展压力 | 直接成本增加 |
要了解更多信息,请参阅操作方法:
规划专用模型的容量
在专用模型中,使用 搜索单位(SU)预配容量:
- 搜索单元 (SU) = 副本 × 分区
- 副本:搜索引擎的副本。 提供查询吞吐量和高可用性。
- 分区:存储单位。 提供存储和索引吞吐量。
| 概念 | 定义 |
|---|---|
| 搜索单位 | 可用容量总量的单个增量。 运行服务至少需要一个搜索单元。 根据定价层,最大范围为 1 到 36 个单位。 搜索单位数等于副本数乘以分区数:R × P = SU。 每个服务都从一个副本和一个分区开始,这种组合消耗一个单位:1 × 1 = 1。 添加第二个副本消耗两个单位:2 个× 1 = 2。 搜索单位也是搜索服务的计费单位。 |
| 副本 | 是搜索服务的实例,主要用于对查询操作进行负载均衡。 每个副本包含索引的一个拷贝。 如果分配三个副本,则可以使用索引的三个副本来为查询请求提供服务。 |
| 分区 | 提供物理存储和 I/O 以支持读/写操作(例如,在重建或刷新索引时)。 每个分区都有总体索引的一个部分。 如果分配三个分区,则索引将划分为三个部分。 |
审核分区和副本表,寻找在 36 个单位限制下的可能组合。
副本和分区(例如处理速度和磁盘 IO)的物理特征因 服务层而异。 在标准搜索服务中,标准服务的副本和分区比基本服务中的副本和分区更快、更大。
何时为专用模型添加容量
请考虑在以下情况下添加副本或分区:
- 查询延迟增加,或者未满足服务级别协议(SLA)要求。
- HTTP 503(服务不可用)错误的频率会增加。
- HTTP 429(请求过多)错误的频率增加,指示请求限制。
- 预计会有大量的查询量。
- 索引作业速度缓慢或落后。
- 存储或索引吞吐量不足。
缩放指南:
- 添加 副本 以提高查询吞吐量和可用性。
- 添加 分区 以提高存储和索引性能。
- 查询密集型工作负荷通常需要更多副本。
- 大型索引可能需要额外的副本来维持性能。
重要
缩放操作可能需要一段时间才能完成并增加成本。 始终使用性能测试和定价估算来验证更改。
选择的服务层确定分区大小和速度。 每个层针对一组适合各种方案的特征进行了优化。 如果选择更高端的层,与使用 S1 时相比,所需的分区数可能更少。 需要通过自我定向测试回答的一个问题是,更大且更昂贵的分区是否比在较低层预配的服务上的两个更便宜的分区产生更好的性能。
单个服务必须具有足够的资源才能处理所有工作负荷(索引和查询)。 没有任何工作负荷在后台运行。 可以为查询请求自然频率较低的时间计划索引,但服务不会将一个任务优先于另一个任务。 此外,在内部更新服务或节点时,一定程度的冗余也会销蚀查询性能。
根据惯例,搜索应用程序所需的副本数往往多过分区数,尤其是在服务操作偏向于查询工作负荷的情况下。 每个副本都是索引的一个副本,因此服务可以在多个副本之间对请求进行负载均衡。 Azure AI 搜索管理索引的所有负载均衡和复制。 您可以随时更改为您的服务分配的副本数量。 最大可在一个标准搜索服务中分配 12 个副本,并在一个基本搜索服务中分配 3 个副本。 可以从 Azure 门户或编程选项之一进行副本分配。
额外的分区对密集型索引工作负荷很有用。 额外的分区将读取和写入操作分散到更多计算资源中。
最后,索引越大,查询所需的时间就越长。 因此,可能发现,每次增加分区都需要按比例少量增加副本。 查询的复杂性和查询量影响查询执行的速度。
有关服务限制和有效的缩放范围,请参阅:
注意
添加更多的副本或分区会增加运行服务的成本,并可能在结果的排序方式上引入细微变化。 请务必查看定价计算器来了解添加更多节点对计费造成的影响。 分区和副本组合表可帮助你交叉引用特定配置所需的搜索单位数。 有关额外副本如何影响查询处理的详细信息,请参阅 “排序结果”。
如何管理和调整容量
更改容量不会即时生效。 根据数据量和操作类型,缩放可能需要几分钟到几小时。
缩放搜索服务时,可从下列工具和方法中进行选择:
注意
如果在 2024 年 4 月或 5 月之前创建了搜索服务,则它可能有资格升级到具有更大分区大小的较新的基础结构,无需额外付费。 此升级可以增加每个分区的可用存储,并减少工作负荷所需的分区数。
若要增加或减少服务的容量,有两个选项:
添加或删除分区和副本
在 Azure 门户中,转到你的搜索服务。
在左窗格中,选择“设置”>“缩放”。
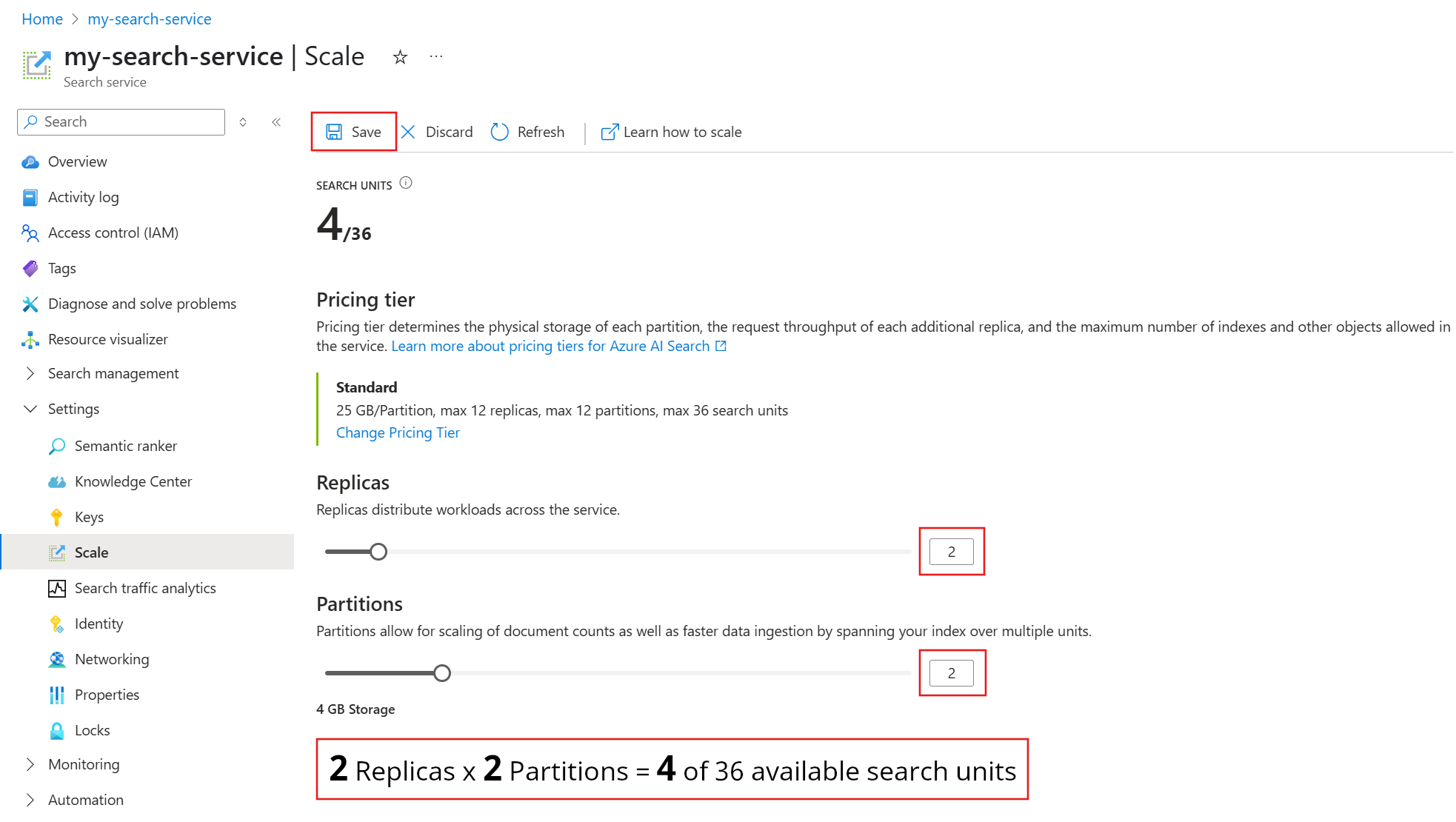
以下屏幕截图显示了预配有一个副本和分区的标准服务。 底部的公式指示正在使用多少个搜索单位 (1)。 如果单位价格为 $100(非实际价格),则运行此服务的每月成本平均为 $100。

使用滑块增加或减少分区数,然后选择“ 保存”。
此示例添加第二个副本和分区。 请注意搜索单位计数;现在有 4 个搜索单位,因为计费公式是副本数乘以分区数 (2 x 2)。 翻倍增加容量会导致运行服务的成本超过翻倍。 如果搜索单位的成本是 $100,则新的每月费用将是 $400。
有关每个层的当前单位成本,请访问 定价页。
检查通知以确认操作是否已启动。

此作可能需要几个小时才能完成。 它发生在后台,因此搜索服务保持完全正常运行,可用于读写操作。
无法取消操作或监视其进度。 但是,在更改过程中,会显示以下消息。





更改定价层
注意
Azure 门户和 Services - Update (REST API)支持基本层和标准层(S1、S2 和 S3)层之间的更改。 可以升级或降级层,前提是当前服务配置不超过目标层的限制。 你的区域也不能有目标层容量约束。
您的定价档次决定了搜索服务的最大存储容量。 如果需要更多或更少的容量,可以切换到满足存储需求的其他定价层。
除了容量,定价层还决定了索引、索引器和其他搜索对象的限制。 在继续操作之前,请比较当前层的服务限制和所需层。 通常情况下,切换到更高的层会提高存储限制和矢量限制、增加请求吞吐量并降低延迟,而切换到更低的层则会产生相反的效果。
切换到更高的定价层也会增加运行搜索服务的成本。 有关详细信息,请参阅定价页。
若要更改价格层级,请执行以下步骤:
在 Azure 门户中,转到你的搜索服务。
在左窗格中,选择“设置”>“缩放”。
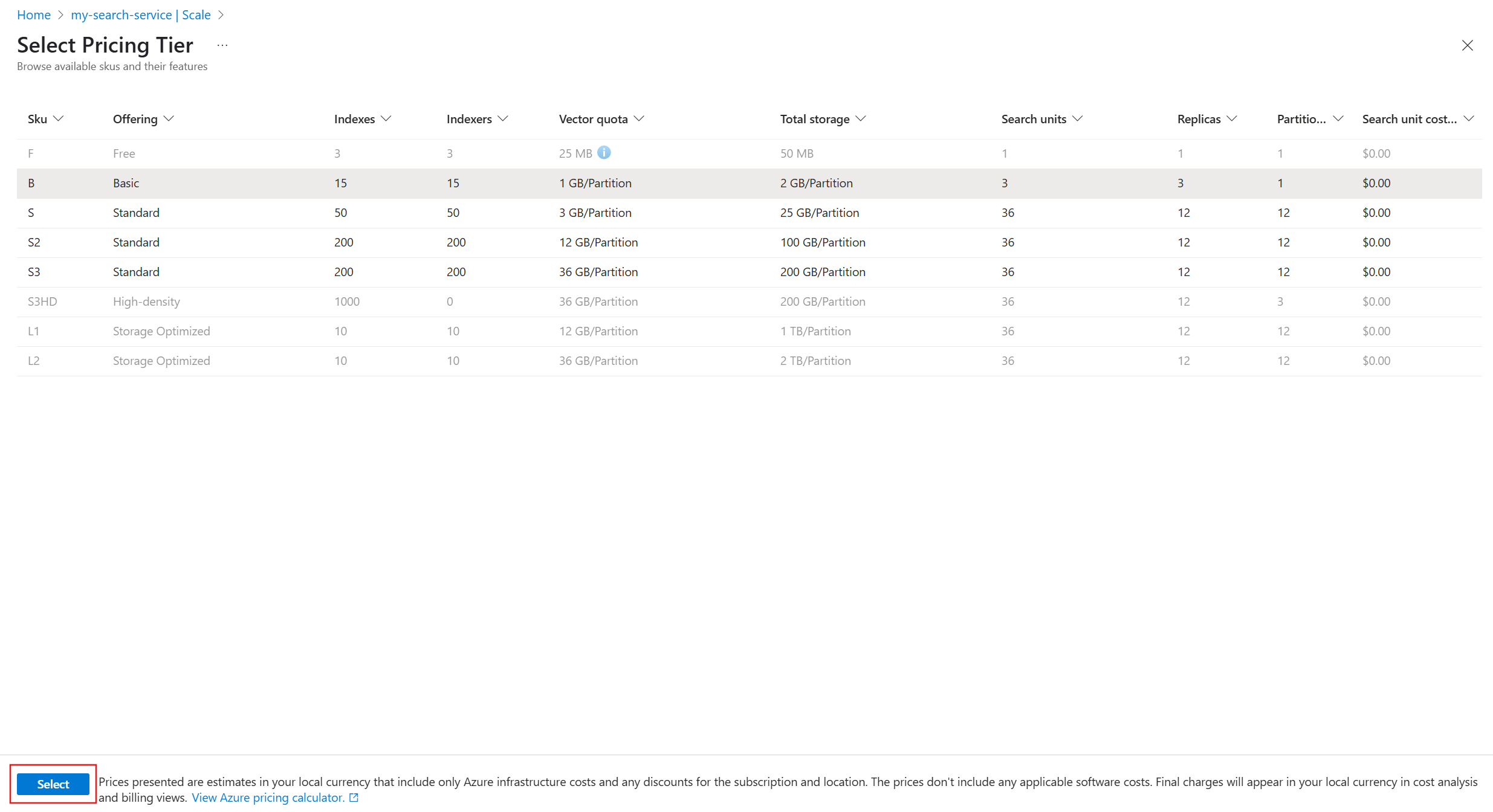
在当前层下,选择“ 更改定价层”。

在“选择定价层”页上,从列表中选择不同的层。
可以在“基本”、“S1”、“S2”和“S3”之间切换,但不能切换到“免费”、“S3HD”、“L1”或“L2”。 这些层不可选择,显示为灰暗状态。
若要启动缩放操作,请选择“保存”。
Azure portal 中“保存”按钮的截图。 此作可能需要几个小时才能完成。 它发生在后台,因此搜索服务保持完全正常运行,可用于读写操作。
无法取消操作或监视其进度。 但是,在更改过程中,会显示以下消息。


如何为专用模型处理缩放请求
当搜索服务收到缩放请求时,它会:
- 检查请求是否有效。
- 开始备份数据和系统信息。
- 检查服务是否已处于预配状态(当前正在添加或消除副本或分区)。
- 启动预配。
缩放服务可能需要几分钟到几个小时,具体取决于服务的大小和请求的范围。 备份持续时间也因数据量和分区数和副本数而异。
前面的步骤不是完全连续的。 例如,系统在可安全进行配置时开始预配,这可能是在备份逐渐结束的时候。
缩放期间出错
下表列出了缩放操作期间可能发生的错误的原因和解决方案。
| 错误消息 | 原因 | 解决方案 |
|---|---|---|
| “目前不允许服务更新操作,因为我们正在处理以前的请求。” | 另一缩放操作正在进行中。 | 在 Azure 门户中检查 Overview 页,或使用 Search Management REST API、Azure PowerShell 或 Azure CLI 获取搜索服务的状态。 如果状态为“正在预配”,请等待它变为“成功”或“失败”,然后重试。 1, 2 |
| “无法缩放搜索服务 servicename。 错误: Object 计数 ActualCount 超出了允许的限制 MaximumCount。” | 当前服务配置超出了目标定价层的限制。 | 检查存储使用情况、矢量使用情况、索引、索引器和其他对象是否遵循较低层的服务限制。 例如,基本层最多支持 15 个索引,因此,如果索引为 16 个,则无法从“S1”切换到“基本”。 在重试之前调整资源。 |
1 备份没有状态,这些备份是不太可能中断缩放练习的内部操作。
2 如果搜索服务似乎停滞在预配状态,请检查不可用、查询量为零且没有索引更新的孤立索引。 不可用的索引可能会阻止对服务容量的更改。 具体而言,请查找其密钥不再有效的 CMK 加密索引。 删除索引或还原密钥,使索引回到联机状态并取消阻止缩放操作。
分区和副本组合
以下图表适用于标准层和更高层。 它显示所有可能的分区和副本组合,每个服务的搜索单元数最多为 36。
| 1 个分区 | 2 个分区 | 3 个分区 | 4 个分区 | 6 个分区 | 12 个分区 | |
|---|---|---|---|---|---|---|
| 1 个副本 | 1 个 SU | 2 个 SU | 3 个 SU | 4 个 SU | 6 个 SU | 12 个 SU |
| 2 个副本 | 2 个 SU | 4 个 SU | 6 个 SU | 8 个 SU | 12 个 SU | 24 个 SU |
| 3 个副本 | 3 个 SU | 6 个 SU | 9 个 SU | 12 个 SU | 18 个 SU | 36 SU |
| 4 个副本 | 4 个 SU | 8 个 SU | 12 个 SU | 16 个 SU | 24 个 SU | 不适用 |
| 5 副本 | 5 个 SU | 10 SU | 15 个 SU | 20 个 SU | 30 个 SU | 不适用 |
| 6 个副本 | 6 个 SU | 12 个 SU | 18 个 SU | 24 个 SU | 36 SU | 不适用 |
| 12 副本 | 12 个 SU | 24 个 SU | 36 SU | 不适用 | 不适用 | 不适用 |
基本搜索服务具有较低的搜索单位计数。
- 在 2024 年 4 月 3 日之前创建的搜索服务上,基本服务只能有一个分区和最多三个副本,最大限制为 3 个 SU。 唯一可调整的资源是副本。
- 在 2024 年 4 月 3 日之后在 受支持的区域中创建的搜索服务上,基本服务最多可以有三个分区和三个副本。 最大 SU 限制为 9,以支持分区和副本的全面配置。
对于任何计费层上的搜索服务(无论创建日期如何),至少需要两个副本才能在查询上实现高可用性。
有关每个层和货币的计费费率,请参阅Azure AI 搜索定价页。
使用专用定价模型层估算容量
存储需求取决于要生成的索引的大小。 没有任何可靠的经验法则或通用指导原则可以帮助进行估算。 确定索引大小的唯 一方法是生成索引。 其大小取决于标记化和嵌入,以及是启用建议器、筛选和排序,还是可以利用 矢量压缩。
在可计费层级(基本层或更高层级)上估算容量。 免费层在多个客户共享的物理资源上运行,受不可控因素影响。 只有计费搜索服务的专用资源才能容纳更大的采样和处理时间,以便在开发期间更现实地估计索引数量、大小和查询量。
检查每个层级的服务限制以确定较低层级是否可以支持需要的索引数量。 请考虑是否需要索引的多个副本才能用于活动开发、测试和生产。
搜索服务受对象限制(最大索引数、索引器、技能集等)和存储限制的约束。 先达到的限制是有效限制。
在可计费层中创建服务。 针对某些工作负载,层级进行了优化。 例如,存储优化层的限制为 10 个索引,因为它旨在支持少量的大型索引。
如果你不确定预计负载有多大,请从较低的“基本”或“S1”层着手。
起点高,如果测试包括大规模索引和查询负载,请从 S2 甚至 S3 开始。
如果你要为大量的数据编制索引并且查询负载相对较低(例如,使用与内部商务应用程序时),请从“优化存储”层 L1 或 L2 着手。
生成初始索引以确定将源数据转换为索引的方式。 这是估计索引大小的唯一方法。 字段定义的属性会影响物理存储要求:
对于关键字搜索,将字段标记为可筛选且可排序会增加索引大小。
对于矢量搜索,可以设置参数以减小矢量大小。
在 Azure 门户中监视存储、服务限制、查询量和延迟。 Azure门户显示每秒查询数、受限查询和搜索延迟。 这些值可以帮助你确定是否选择了正确的层。
添加副本以实现高可用性或缓解查询性能缓慢。
没有关于应该需要多少个副本来承载查询负载的指导。 查询性能取决于查询复杂性和争用资源的工作负荷。 尽管添加副本会明显提高性能,但结果不一定有线性改善:添加三个副本并不保证带来三倍的吞吐量。 有关估算解决方案 QPS 的指导,请参阅分析性能和监视查询。
对于倒排索引,大小和复杂度由内容决定,不一定是输入的数据量。 具有高度冗余的大型数据源可能会导致比包含高度可变内容的较小数据集更小的索引。 因此,很难根据原始数据集的大小来推断索引大小。
如果包含从未搜索过的数据,则可以夸大存储要求。 理想情况下,文档仅包含搜索体验所需的数据。
服务级别协议注意事项
服务级别协议(SLA) 不包括免费层和预览功能。 对于所有可计费的级别,在您为服务提供足够的冗余时,服务水平协议(SLA)将会生效。
满足查询(读取)服务级别协议的条件是两个或多个副本。
三个或多个副本满足查询和索引(读写)SLA。
分区数不影响SLAs。