Service Fabric 群集资源管理器是在群集中运行的中心服务。 它管理群集中服务所需的状态,对资源消耗和任何放置规则而言尤其如此。
为了管理群集中的资源,Service Fabric 群集资源管理器必须包含一些相关的信息:
- 当前存在的服务
- 每个服务的当前(或默认)资源消耗
- 剩余的群集容量
- 群集中节点的容量
- 每个节点可消耗的资源量
给定服务的资源消耗量可随时间更改,服务通常关注多种类型的资源。 在不同的服务之间,可能会同时测量实际物理资源和物理资源。 服务可能会跟踪内存和磁盘使用情况等物理指标。 更普遍的是,服务可能会关注“WorkQueueDepth”或“TotalRequests”等逻辑指标。 逻辑指标和物理指标都可用于同一群集。 指标可在许多服务间共享,也可特定于特定服务使用。
其他注意事项
有时,群集的所有者和操作员与服务和应用程序创建者不同,或至少是一人身兼多职。 开发应用程序时,需要知道有关应用程序需求的一些内容。 需要估计应用程序将占用的资源以及不同服务的部署方法。 例如,Web 层需要在连接到 Internet 的节点上运行,而数据库服务则不必。 再举一例,Web 服务可能会受 CPU 和网络限制,而数据层服务更关注内存和磁盘使用情况。 但是,处理该服务在生产环境中的实时站点事件的人员,或者管理服务升级的人员,需要执行不同的作业,并且需要不同的工具。
群集和服务都是动态的:
- 群集中的节点数可以增加和缩减
- 不同大小和类型的节点可以变化不定
- 可以创建、删除服务,并更改其所需的资源分配和放置规则
- 升级或其他管理操作可以在基础结构级别的应用程序中运行
- 随时可能发生失败。
群集 Resource Manager 组件和数据流
群集资源管理器必须跟踪每个服务的需求以及这些服务中每个服务对象的资源消耗。 群集资源管理器具有两个概念部件:在每个节点上运行的代理和容错服务。 每个节点上的代理跟踪服务的负载报告、聚合这些报告,并定期报告它们。 群集 Resource Manager 服务会聚合来自本地代理的所有信息,并根据当前配置做出反应。
让我们看看下图:
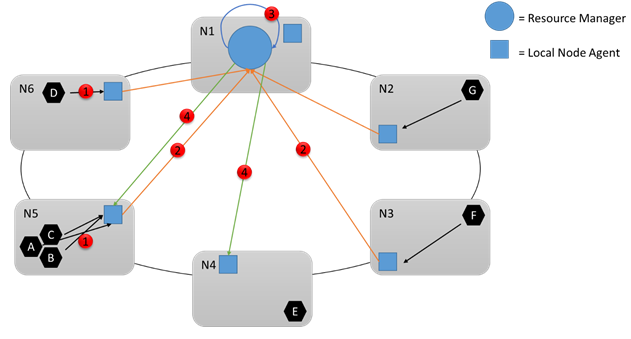
在运行时,有很多更改可能会发生。 例如,假设某些服务消耗的资源量发生变化,某些服务出现故障,某些节点加入或离开群集。 节点上的所有更改都要进行汇总,并定期发送到群集 Resource Manager 服务(1、2),并在其中再次聚合、分析和存储。 每隔几秒钟,服务就查看更改,并确定是否需要任何操作 (3)。 例如,它可能注意到某些空节点已添加到群集。 因此,确定要将某些服务移到这些节点。 群集资源管理器可能还注意到特定节点已超载,或者某些服务已失败或删除,在其他位置释放资源。
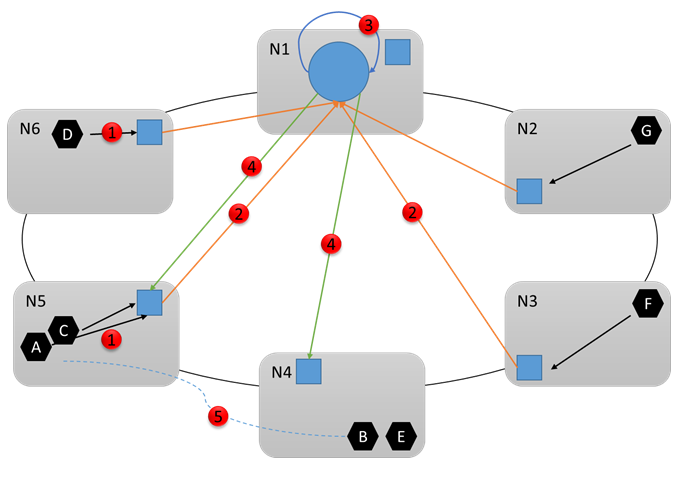
让我们看看下图,看看接下来会发生什么。 假设群集资源管理器确定需要进行更改。 它与其他系统服务(尤其是故障转移管理器)进行协调,进行必要的更改。 然后将所需命令发送到相应节点 (4)。 例如,假设资源管理器注意到 Node5 已超载,因此确定要将服务 B 从 Node5 移到 Node4。 重新配置 (5) 结束时,群集看起来像这样:
后续步骤
- 群集 Resource Manager 提供许多用于描述群集的选项。 若要详细了解这些选项,请查看这篇描述 Service Fabric 群集的文章
- 群集资源管理器的主要职责是重新均衡群集,并强制执行放置规则。 有关如何配置这些行为的详细信息,请参阅均衡 Service Fabric 群集