Service Fabric 群集资源管理器支持动态加载更改,对节点或服务的添加或删除做出反应。 它还会自动更正约束冲突,并主动重新平衡群集。 但这些动作的频率是多少,它们是由什么引发的?
群集资源管理器执行的三种不同的工作类别:
- 放置 - 此阶段将处理放置缺少的任何有状态副本或无状态实例。 部署包括新服务的放置和处理已失败的有状态副本或无状态实例。 此处处理删除和丢弃副本或实例。
- 约束检查 - 此阶段检查并更正系统中不同放置约束(规则)的违反情况。 规则的示例包括确保节点不超出容量,并且满足服务的放置约束。
- 均衡 - 此阶段检查是否需要重新均衡,具体取决于针对不同指标配置的所需平衡级别。 如果是这样,它会尝试在群集中找到更平衡的排列方式。
配置群集资源管理器计时器
围绕均衡的第一组控件是一组计时器。 这些计时器控制群集资源管理器检查群集的频率并采取纠正措施。
群集资源管理器可以进行的每种不同类型的更正都由控制其频率的不同计时器控制。 当每个计时器触发时,任务会被安排。 默认情况下,资源管理器:
- 扫描其状态并应用更新(如记录节点已关闭)每 1/10 秒
- 每秒设置位置检查标志
- 每秒设置约束检查标志
- 每隔 5 秒设置一次均衡标志
控制这些计时器的配置示例如下:
ClusterManifest.xml:
<Section Name="PlacementAndLoadBalancing">
<Parameter Name="PLBRefreshGap" Value="0.1" />
<Parameter Name="MinPlacementInterval" Value="1.0" />
<Parameter Name="MinConstraintCheckInterval" Value="1.0" />
<Parameter Name="MinLoadBalancingInterval" Value="5.0" />
</Section>
通过用于独立部署的 ClusterConfig.json 或用于 Azure 托管群集的 Template.json:
"fabricSettings": [
{
"name": "PlacementAndLoadBalancing",
"parameters": [
{
"name": "PLBRefreshGap",
"value": "0.10"
},
{
"name": "MinPlacementInterval",
"value": "1.0"
},
{
"name": "MinConstraintCheckInterval",
"value": "1.0"
},
{
"name": "MinLoadBalancingInterval",
"value": "5.0"
}
]
}
]
目前,群集资源管理器一次只执行其中一项作,按顺序执行。 因此,我们将这些计时器称为“最小间隔”,而将计时器触发时执行的动作称为“设置标志”。 例如,群集资源管理器负责处理创建服务挂起请求,然后再均衡群集。 如指定的默认时间间隔所示,群集资源管理器会频繁扫描需要执行的任务。 通常,这意味着每个步骤所涉及的更改数量较少。 小型频繁更改允许群集资源管理器在群集中发生情况时做出响应。 默认计时器提供一些批处理,因为许多相同类型的事件往往同时发生。
例如,当节点发生故障时,它们可能会同时影响整个容错域。 所有这些失败都是在 PLBRefreshGap 之后的下一个状态更新期间捕获的。 修正将在以下放置、约束检查和均衡运行中确定。 默认情况下,群集资源管理器不会扫描群集中数小时的更改,并尝试一次解决所有更改。 这样做将导致流失激增。
群集资源管理器还需要一些附加信息来确定群集是否不平衡。 为此,我们还有另外两段配置: BalancingThresholds 和 ActivityThresholds。
均衡阈值
均衡阈值是触发重新均衡的主要控件。 指标的均衡阈值是一个 比率。 如果最加载节点上指标的负载除以最小加载节点上的负载量超过该指标的 BalancingThreshold,则群集将不平衡。 因此,下次群集资源管理器检查时会触发均衡。 MinLoadBalancingInterval 计时器定义群集资源管理器检查是否需要重新均衡的频率。 检查并不意味着发生任何事情。
均衡阈值是按指标定义的,作为群集定义的一部分。 有关指标的详细信息,请查看 指标文章。
ClusterManifest.xml
<Section Name="MetricBalancingThresholds">
<Parameter Name="MetricName1" Value="2"/>
<Parameter Name="MetricName2" Value="3.5"/>
</Section>
通过用于独立部署的 ClusterConfig.json 或用于 Azure 托管群集的 Template.json:
"fabricSettings": [
{
"name": "MetricBalancingThresholds",
"parameters": [
{
"name": "MetricName1",
"value": "2"
},
{
"name": "MetricName2",
"value": "3.5"
}
]
}
]
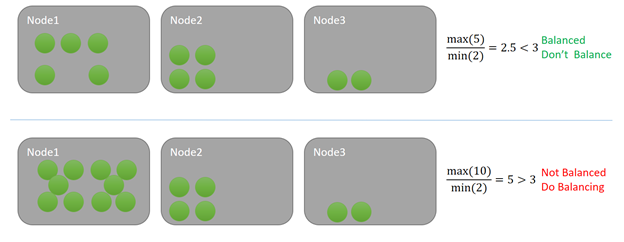
在此示例中,每个服务都消耗了某种指标的一个单位。 在顶部示例中,节点上的最大负载为 5,最小值为 2。 假设此指标的均衡阈值为 3。 由于群集中的比率为 5/2 = 2.5,并且小于指定的 3 个均衡阈值,因此群集是均衡的。 群集资源管理器检查时不会触发均衡。
在底部示例中,节点上的最大负载为 10,最小负载为 2,导致比率为 5。 5 大于该指标的指定均衡阈值 3。 因此,下次均衡计时器触发时,将安排重新平衡操作。 在这种情况下,某些负载通常分发到节点 3。 由于 Service Fabric 群集资源管理器不使用贪婪方法,因此某些负载也可以分发到节点 2。
注释
“均衡”处理两种不同的策略来管理群集中的负载。 群集资源管理器使用的默认策略是跨群集中的节点分配负载。 另一种策略是 碎片整理。 在同一均衡运行期间执行碎片整理。 均衡和碎片整理策略可用于同一群集中的不同指标。 服务可以同时具有均衡和碎片整理指标。 对于碎片整理指标,当负载 低于 均衡阈值时,群集中的负载比率会触发重新均衡。
低于均衡阈值不是显式目标。 均衡阈值只是一个 触发器。 均衡运行时,群集资源管理器会确定它可以做出哪些改进(如果有)。 仅因为启动了平衡搜索,并不意味着会有任何变化。 有时群集不平衡,但过于受限,无法更正。 或者,改进需要成本过高的措施。
活动阈值
有时,尽管节点相对不平衡,但群集中的 总 负载量较低。 缺少负载可能是暂时性下降,或者因为群集是新的,只是被启动。 无论哪种情况,你可能都不想花时间去平衡集群,因为几乎没有收益。 如果群集进行了均衡,你可能会消耗网络和计算资源来重新分配工作,但不会产生任何重大的 绝对 差异。 为了避免不必要的移动,还有另一个称为“活动阈值”的控件。 活动阈值允许为活动指定一些绝对下限。 如果没有节点超过此阈值,即使满足均衡阈值,也不会触发均衡。
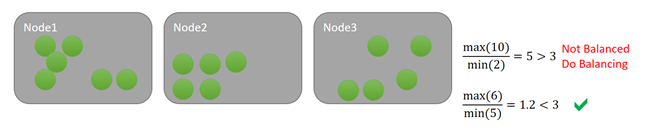
假设我们保留此指标的均衡阈值为 3。 我们也假设活动阈值为 1536。 在第一种情况下,当群集根据均衡阈值不平衡时,没有任何节点满足该活动阈值,因此不会发生任何作。 在底部示例中,节点 1 超过活动阈值。 由于指标的均衡阈值和活动阈值均被超出,因此会安排均衡。 例如,让我们看看下图:

与均衡阈值一样,活动阈值是通过群集定义按指标定义的。
ClusterManifest.xml
<Section Name="MetricActivityThresholds">
<Parameter Name="Memory" Value="1536"/>
</Section>
通过用于独立部署的 ClusterConfig.json 或用于 Azure 托管群集的 Template.json:
"fabricSettings": [
{
"name": "MetricActivityThresholds",
"parameters": [
{
"name": "Memory",
"value": "1536"
}
]
}
]
均衡和活动阈值都绑定到特定指标 - 仅当针对同一指标超出均衡阈值和活动阈值时,才会触发均衡。
注释
如果未指定,则指标的均衡阈值为 1,活动阈值为 0。 这意味着群集资源管理器将尝试为任何给定负载保持该指标完全均衡。 如果使用自定义指标,建议为指标显式定义自己的均衡和活动阈值。
将服务均衡在一起
群集是否不平衡是涉及整个群集的决策。 但是,我们通过移动各个服务副本和实例来修复此问题。 这很有意义,对吗? 如果内存堆积在一个节点上,则多个副本或实例可能会为其做出贡献。 修复不平衡可能需要移动任何使用不均衡指标的有状态副本或无状态实例。
不过,偶尔会移动一项本身并不失衡的服务(记得之前讨论过的本地和全球权重)。 当服务的所有指标都均衡时,为何会移动服务? 请看以下示例:
- 假设有四个服务:服务 1、服务 2、服务 3 和服务 4。
- 服务 1 报告指标 1 和指标 2。
- 服务 2 报告指标 2 和指标 3。
- 服务 3 报告指标 3 和指标 4。
- 服务 4 报告指标 99。
我们实际上没有四个独立的服务,我们有三个相关服务,一个是自行关闭的。
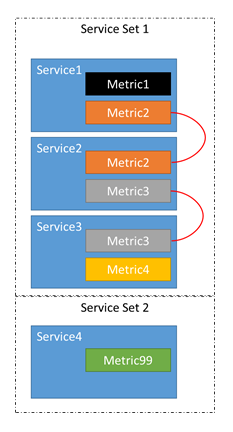
由于此链,指标 1-4 中的不平衡可能导致属于服务 1-3 的副本或实例四处移动。 我们还知道,指标 1、2 或 3 中的不平衡无法导致服务 4 出现变化。 由于移动属于服务 4 的副本或实例绝对不会影响指标 1-3 的平衡,因此没有任何意义。
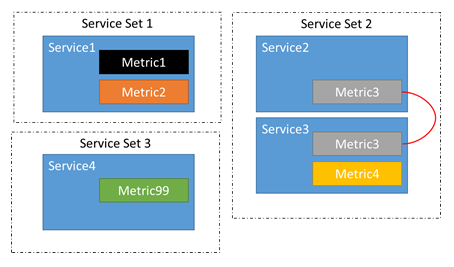
群集资源管理器会自动确定与哪些服务相关。 添加、删除或更改服务的指标可能会影响其关系。 例如,在两次执行服务 2 的负载均衡之间,服务 2 可能已被更新以删除指标 2。 这会中断服务 1 和服务 2 之间的链。 现在,有三个服务组,而不是两组相关服务:
均衡每种节点类型的群集
如前面部分所述,触发重新均衡的主要控制是 活动阈值、 均衡阈值 和 计时器。 Service Fabric 群集资源管理器通过为每个节点类型指定参数并允许仅在不均衡的节点类型上移动,对触发重新平衡提供更精细的控制。 每个节点类型均衡的主要好处是允许对需要更严格的均衡规则的节点类型进行性能改进,而不会在其他节点类型上降低性能。 此功能包含两个主要部分:
- 检测不平衡是按节点类型完成的。 以前是针对每种节点类型单独计算不平衡的全局值。 如果所有节点类型都已均衡,CRM 不会触发均衡阶段。 否则,如果至少有一个节点类型不平衡,则需要均衡阶段。
- 均衡操作仅在不均衡的节点类型上移动副本,其他节点类型不会受到均衡阶段的影响。
每个节点类型的均衡如何影响群集
在对每个节点类型的群集进行均衡期间,Service Fabric 群集资源管理器会计算每个节点类型的不平衡状态。 如果至少有一个节点类型不平衡,则会触发均衡阶段。 均衡阶段在不平衡的节点类型上不会移动副本,当这些节点类型暂停均衡时(例如,自上一个均衡阶段以来尚未超过最小均衡间隔)。 检测不平衡状态使用已可用于经典群集均衡的通用机制,但提高了配置粒度和灵活性。 以下列表中提供了用于对每个节点类型进行均衡以检测不平衡的机制:
- 各节点类型的指标均衡阈值是类似于经典平衡中使用的全局定义平衡阈值的值。 计算每个节点类型的最小和最大指标负载比率。 如果节点类型的比率高于节点类型的定义的均衡阈值,则节点类型将标记为不平衡。 有关每个节点类型的指标活动阈值配置的更多详细信息,请查看 每个节点类型的均衡阈值部分。
- 每个节点类型的指标活动阈值是具有与经典均衡中使用的全局定义活动阈值类似的值。 计算每种节点类型的最大度量负载。 如果节点类型的最大负载高于该节点类型的定义的活动阈值,则节点类型将标记为不平衡。 有关每个节点类型的指标活动阈值配置的更多详细信息,请查看 activity-thresholds-per-node-type 部分。
- 每个节点类型的最小均衡间隔具有类似于全局定义的最小均衡间隔的角色。 对于每个节点类型,群集资源管理器将保留上次均衡的时间戳。 无法在定义的最小均衡间隔内的节点类型上执行两个连续均衡阶段。 有关每个节点类型的最小均衡间隔配置的更多详细信息,请查看 每个节点类型的最低均衡间隔部分。
描述每个节点类型的均衡
若要启用按节点类型的均衡,需要在群集清单中启用SeparateBalancingStrategyPerNodeType参数。 此外,还需要启用子聚集功能。 用于启用该功能的群集清单 PlacementAndLoadBalancing 部分的示例:
<Section Name="PlacementAndLoadBalancing">
<Parameter Name="SeparateBalancingStrategyPerNodeType" Value="true" />
<Parameter Name="SubclusteringEnabled" Value="true" />
<Parameter Name="SubclusteringReportingPolicy" Value="1" />
</Section>
适用于独立部署的 ClusterConfig.json 或适用于 Azure 托管群集的 Template.json:
"fabricSettings": [
{
"name": "PlacementAndLoadBalancing",
"parameters": [
{
"name": "SeparateBalancingStrategyPerNodeType",
"value": "true"
},
{
"name": "SubclusteringEnabled",
"value": "true"
},
{
"name": "SubclusteringReportingPolicy",
"value": "1"
},
]
}
]
如 上一部分所述,可以为每个节点类型指定阈值和间隔。 有关更新特定参数的更多详细信息,请查看以下部分:
均衡每个节点类型的阈值
可以为每个节点类型定义度量指标均衡阈值,以便从均衡配置中提高细粒度。 均衡阈值具有浮点类型,因为它们表示特定节点类型中最大负载和最小负载值的比率的阈值。 均衡阈值在 PlacementAndLoadBalancingOverrides 节中为每个节点类型定义:
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MetricBalancingThresholdsPerNodeType>
<BalancingThreshold Name="Metric1" Value="2.5">
<BalancingThreshold Name="Metric2" Value="4">
<BalancingThreshold Name="Metric3" Value="3.25">
</MetricBalancingThresholdsPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
如果未为节点类型定义指标的均衡阈值,阈值将继承 在 PlacementAndLoadBalancing 节中全局定义的指标均衡阈值的值。 否则,如果未为节点类型定义指标的均衡阈值,也不会在 PlacementAndLoadBalancing 节中全局定义阈值,则阈值的默认值为 1。
每个节点类型的活动阈值
可以为每个节点类型定义指标活动阈值,以提高均衡配置的粒度。 活动阈值具有整数类型,因为它们表示特定节点类型中最大负载值的阈值。 活动阈值在 PlacementAndLoadBalancingOverrides 节中为每个节点类型定义:
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MetricActivityThresholdsPerNodeType>
<ActivityThreshold Name="Metric1" Value="500">
<ActivityThreshold Name="Metric2" Value="40">
<ActivityThreshold Name="Metric3" Value="1000">
</MetricActivityThresholdsPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
如果未为节点类型定义指标的活动阈值,阈值将从 PlacementAndLoadBalancing 节中全局定义的指标活动阈值继承值。 否则,如果未为节点类型定义指标的活动阈值,也不会在 PlacementAndLoadBalancing 节中全局定义,则阈值的默认值为 零。
每个节点类型的最小均衡间隔
可以为每个节点类型定义最小均衡间隔,以提高均衡配置的粒度。 最小均衡间隔具有整数类型,因为它表示在同一节点类型上连续两个平衡轮之前必须经过的最小时间量。 每个节点类型的 PlacementAndLoadBalancingOverrides 节中定义了最小均衡间隔:
<NodeTypes>
<NodeType Name="NodeType1">
<PlacementAndLoadBalancingOverrides>
<MinLoadBalancingIntervalPerNodeType>100</MinLoadBalancingIntervalPerNodeType>
</PlacementAndLoadBalancingOverrides>
</NodeType>
</NodeTypes>
如果未为节点类型定义最小均衡间隔,则间隔将从 PlacementAndLoadBalancing 节中全局定义的最小均衡间隔继承值。 否则,如果未为节点类型定义最小间隔,也不会在 PlacementAndLoadBalancing 节中全局定义最小间隔,则最小间隔的默认值为 零 ,表示不需要连续均衡轮之间的暂停。
例子
示例 1
假设群集包含两种节点类型:节点类型 A 和节点类型 B。所有服务都报告相同的指标,它们在这些节点类型之间拆分,因此负载统计信息对他们不同。 在此示例中,节点类型 A 的最大负载为 300,最小负载为 100,节点类型 B 的最大负载为 700,最小负载为 500:
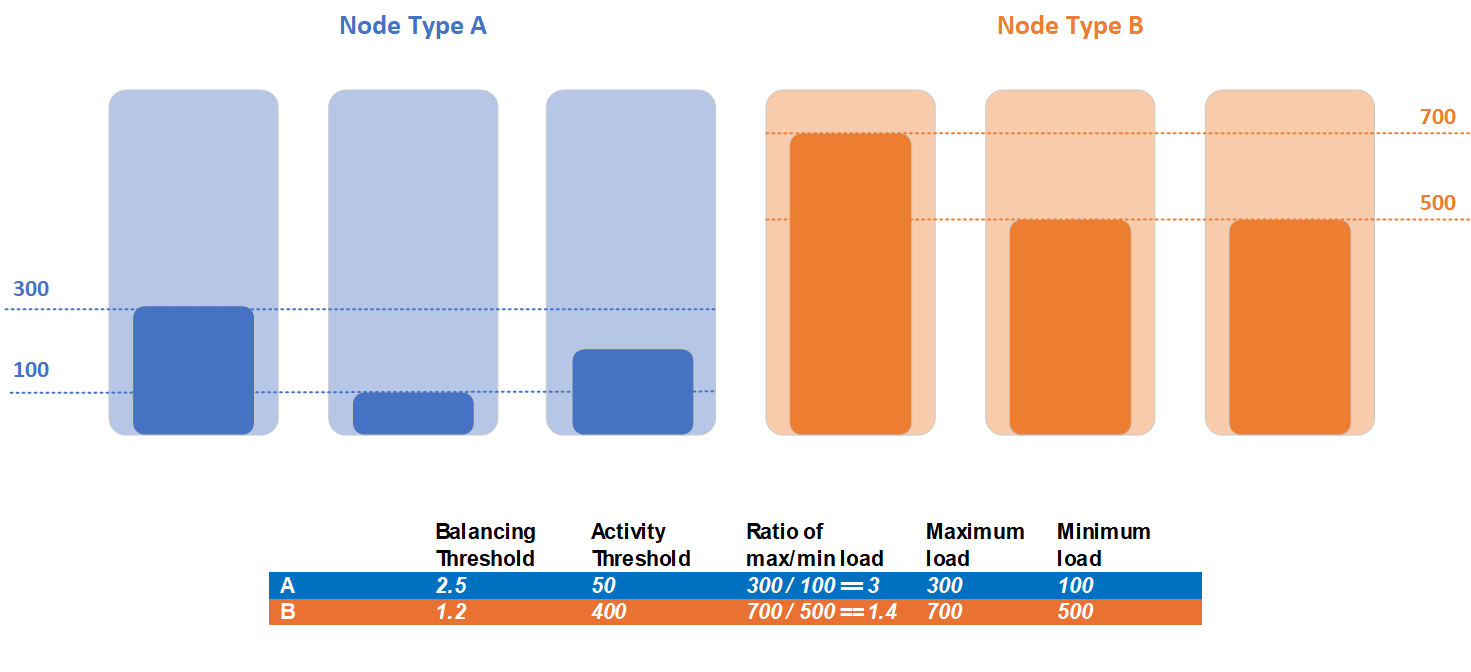
客户检测到,两个节点类型的工作负荷具有不同的均衡需求,并决定为每个节点类型设置不同的均衡和活动阈值。 节点类型 A 的均衡阈值为 2.5,活动阈值为 50。 对于节点类型 B,客户将均衡阈值设置为 1.2,活动阈值设置为 400。
在此示例中检测群集不平衡时,这两种节点类型都违反了活动阈值。 节点类型 A 的最大负载为 300 ,高于定义的活动阈值 50。 节点 类型 B 的最大负载为 700 ,高于定义的活动阈值 400。 节点类型 A 违反了均衡阈值条件,因为最大负载和最小负载的当前比率为 3,并且均衡阈值为 2.5。 相反,节点类型 B 不违反均衡阈值条件,因为此节点类型的最大负载和最小负载的当前比率为 1.2,但均衡阈值为 1.4。 只有节点类型 A 中的副本需要均衡,并且唯一有资格在均衡阶段移动的副本集是放置在节点类型 A 中的副本。
示例 2
假设群集包含三种节点类型、节点类型 A、 B 和 C。所有服务都报告相同的指标,它们在这些节点类型之间拆分,因此负载统计信息对他们不同。 在此示例中,节点类型 A 的最大负载为 600,最小负载为 100,节点类型 B 的最大负载为 900,最小负载为 100,节点类型 C 的最大负载为 600,最小负载为 300:

客户检测到这些节点类型的工作负荷具有不同的均衡需求,并决定为每个节点类型设置不同的均衡和活动阈值。 节点类型 A 的均衡阈值为 5,活动阈值为 700。 对于节点类型 B,客户将均衡阈值设置为 10,活动阈值设置为 200。 对于节点类型 C,客户将均衡阈值设置为 2,活动阈值设置为 300。
节点类型 A 为 600 的最大负载低于定义的活动阈值 700,因此不会均衡节点类型 A 。 节点类型 B 的最大负载为 900 ,高于定义的活动阈值 200。 节点类型 B 违反了活动阈值条件。 节点类型 C 的最大负载为 600 ,高于定义的活动阈值 300。 节点类型 C 违反了活动阈值条件。 节点类型 B 不违反均衡阈值条件,因为此节点类型的最大负载和最小负载的当前比率为 9,但均衡阈值为 10。 节点类型 C 违反均衡阈值条件,因为最大负载和最小负载的当前比率为 2,均衡阈值为 2。 只有节点类型 C 中的副本需要均衡,并且唯一有资格在均衡阶段移动的副本集是放置在节点类型 C 中的副本。