指标是服务关切的、由群集中的节点提供的资源 。 指标是要进行管理以提升或监视服务性能的任何信息。 例如,可能需要监视内存消耗量以了解服务是否过载。 另一个用途是确定服务是否可以移动到内存较少受限的其他位置,以便获得更佳性能。
内存、磁盘、CPU 使用率等信息都是指标的示例。 这些指标是物理指标,即对应于节点上需要管理的物理资源的资源。 指标也可以是(且通常是)逻辑指标。 逻辑指标是类似于“MyWorkQueueDepth”、“MessagesToProcess”或“TotalRecords”的信息。 逻辑指标是应用程序定义的,并间接对应于某些物理资源消耗。 逻辑指标很常见,因为可能难以在每个服务的基础上测量和报告物理资源消耗量。 测量和报告自己的物理指标的复杂度也是 Service Fabric 提供一些默认指标的原因。
默认指标
假设你要开始编写和部署服务。 但此时不知道该服务要消耗哪些物理或逻辑资源。 没有任何问题! 未指定其他任何指标时,Service Fabric 群集资源管理器会使用一些默认指标。 它们具有以下特点:
- PrimaryCount - 节点上的主要副本计数
- ReplicaCount - 节点上的有状态副本总计数
- Count - 节点上的所有服务对象(无状态和有状态)计数
| 指标 | 无状态实例负载 | 有状态辅助负载 | 有状态主要负载 | 重量 |
|---|---|---|---|---|
| 主要计数 | 0 | 0 | 1 | 高 |
| 副本数量 | 0 | 1 | 1 | 中型 |
| 计数 | 1 | 1 | 1 | 低 |
对于脚本工作负荷,默认指标实现群集中的适当工作分布。 在以下示例中,让我们看看创建两个服务并依赖默认指标进行均衡时会发生什么情况。 第一个服务是具有 3 个分区的有状态服务,目标副本集大小为 3。 第二个服务是具有 1 个分区的无状态服务,实例数为 3。
结果如下:
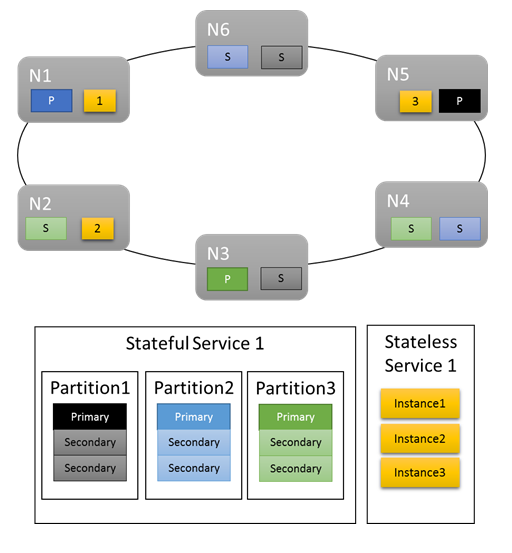
需要注意的一些事项:
- 有状态服务的主要副本分布在多个节点上
- 同一分区的副本分布在不同节点上
- 主副本与辅助副本的总数在群集中分布
- 服务对象的总数平均分配在每个节点上
很好!
开始时,默认指标能够良好运作。 但默认指标的作用有限,对于某些问题,就不那么好用了。 例如:所选择的分区方案实现所有分区完全平均使用的可能性有多大? 指定服务的负载在一段时间内保持不变的几率有多大,甚或是在现在的多个分区中保持相同的几率有多大?
可以只运行默认指标。 但这样做通常意味着群集利用率比预期更低且更不均衡。 这是因为默认指标并非自适应,并假定一切都是等效的。 例如,正在使用的主节点和不会同时向 PrimaryCount 指标贡献“1”个单位的节点。 在最坏的情况下,仅使用默认指标也可能导致过度安排的节点引起性能问题。 若要充分利用群集并避免性能问题,需使用自定义指标和动态负载报告。
自定义指标
创建服务时,可根据命名服务实例配置指标。
任何指标都有一些描述它的属性:名称、权重和默认负载。
- 指标名称:指标的名称。 从资源管理器的角度看,指标名称是群集中指标的唯一标识符。
注意
自定义指标名称不应是任何系统指标名称(即 servicefabric:/_CpuCores 或 servicefabric:/_MemoryInMB),因为它可能导致未定义的行为。 从 Service Fabric 版本 9.1 开始,对于具有这些自定义指标名称的现有服务,系统会发出运行状况警告以指示指标名称不正确。
- 权重:指标权重定义指标对于此服务的重要程度(相对于其他指标)。
- 默认负载:默认负载根据服务是无状态还是有状态服务以不同的方式表示。
- 对于无状态服务,每个指标包含名为 DefaultLoad 的单个属性
- 对于有状态服务,可以定义:
- PrimaryDefaultLoad:此服务充当主副本时消耗此指标的默认数量
- SecondaryDefaultLoad:此服务充当辅助副本时消耗此指标的默认数量
注意
如果定义了自定义指标,并且希望同时使用默认指标,则需重新显式添加默认指标并为其定义权重和值 。 这是因为必须定义默认指标和自定义指标之间的关系。 例如,与主要分布相比,也许更关心 ConnectionCount 或 WorkQueueDepth。 默认情况下,PrimaryCount 指标的权重为“高”,因此需要在添加其他指标时将其降低至“中”,以确保优先处理其他指标。
为服务定义指标 - 示例
假设需要以下配置:
- 服务报告一个名为“ConnectionCount”的指标
- 还想使用默认指标
- 已完成一些测量,并且知道该服务的主要副本通常占用 20 个单位的“ConnectionCount”
- 辅助副本占用 5 个单位的“ConnectionCount”
- 已了解“ConnectionCount”是管理此特定服务性能的最重要指标,
- 但仍希望主要副本是均衡的。 无论如何,均衡主要副本通常都是一个好主意。 这有助于防止某些节点或容错域的损失影响到与之相关的大部分主要副本。
- 否则,使用默认指标即可
可以编写以下代码来创建包含该指标配置的服务:
代码:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -Metric @("ConnectionCount,High,20,5","PrimaryCount,Medium,1,0","ReplicaCount,Low,1,1","Count,Low,1,1")
注意
上述示例以及本文其余部分描述了如何根据每个命名服务管理指标。 也可以在服务类型级别为服务定义指标 。 可通过在服务清单中指定它们来实现此目的。 出于以下几个原因,不建议定义类型级别指标。 第一个原因是指标名称通常是特定于环境的。 除非有明确协定,否则无法确定某一环境中的指标“Cores”不是其他环境中的“MiliCores”或“CoReS”。 如果在清单中定义指标,则需为每个环境创建新的清单。 这通常会导致只有细微差异的不同清单激增,从而增加管理难度。
通常基于每个命名服务实例来分配指标负载。 例如,假设为客户 A 创建一个服务实例,该客户计划较少使用此实例。 同时为拥有较大工作负荷的客户 B 创建了另一服务实例。 在此情况下,很可能需要为这些服务调整默认负载。 如果通过清单定义指标和负载,并想要支持此方案,则需为每位客户提供不同的应用程序和服务类型。 创建服务时所定义的值会替代清单中定义的值,因此可以使用它来设置特定的默认值。 但是,这样做会导致清单中声明的值与服务实际运行时使用的值不相符。 这可能会造成混淆。
特此提醒:如果只想要使用默认指标,则完全不需要处理指标集合,或者在创建服务时执行任何特殊操作。 未定义其他指标时,系统自动使用默认指标。
现在来详细了解一下每项设置及其所影响的行为。
加载
定义指标的整个要点就是表示某种负载。 “负载”指给定节点上某个服务实例或副本对给定指标的消耗量。 可在几乎任意时间配置负载。 例如:
- 创建服务后,可以定义负载。 此类负载配置称为默认负载。
- 创建服务后,可更新服务的指标信息(包括默认负载)。 此指标更新是通过更新服务来完成的。
- 可将给定分区的负载重置为该服务的默认值。 此指标更新称为“重置分区负载”。
- 在运行时,可动态报告每个服务对象的负载。 此指标更新称为“报告负载”。
- 也可以通过 Fabric API 调用来报告负载值,从而更新分区副本或实例的负载。 此指标更新称为“报告分区负载”。
可在同一服务的生存期内使用所有这些策略。
默认负载
默认负载是此服务的每个服务对象(无状态实例或有状态副本)对该指标的消耗量。 群集资源管理器将此数值用于服务对象的负载,直至收到动态负载报告等其他信息。 对于较简单的服务,默认负载是一种静态定义。 默认负载从不更新,并用于服务的整个生存期。 默认负载对于简单容量规划方案而言非常有用,其中一定量的资源专用于不同的工作负载且不发生更改。
注意
若要深入了解容量管理以及如何在群集中定义节点的容量,请参阅此文。
群集资源管理器允许有状态服务为其主要副本和次要副本指定不同的默认负载。 无状态服务只能指定一个值,该值适用于所有实例。 对于有状态服务,主要副本和次要副本的默认负载通常不同,因为副本在每个角色中执行不同类型的工作。 例如,主要副本通常服务于读取和写入,并处理大部分计算负担,而次要副本则不同。 通常,主要副本的默认负载高于次要副本的默认负载。 实数应取决于你自己的度量值。
动态负载
假设我们已运行服务一段时间。 使用某种监视功能后,我们发现:
- 给定服务的某些分区或实例比其他分区或实例消耗更多的资源
- 某些服务的负载随时间而变化。
很多因素都会导致此类的负载波动。 例如,不同服务或分区与具有不同需求的不同客户相关联。 负载也可能发生变化,因为服务的工作量会在一天中发生变化。 无论是什么原因,通常都无法为默认负载使用单个值。 如果要充分利用群集,这一点尤其如此。 在某些情况下,为默认负载选择任何值都会出错。 不正确的默认负载会导致群集资源管理器分配的资源过量或不足。 因此,即使群集资源管理器认为群集已均衡,节点也处于过度使用或未充分使用状态。 默认负载仍然有用,因为它们会提供初始放置的一些信息,但它们并不是实际工作负载的全貌。 为了准确捕获不断变化的资源需求,群集资源管理器允许每个服务对象在运行时更新其自身的负载。 这称作动态负载报告。
动态负载报告可让副本或实例在其生存期中调整其分配/报告的指标负载。 空闲且未运行任何工作的服务副本或实例通常会报告其使用少量的给定指标。 而繁忙的副本或实例则报告他们使用较多的指标。
通过报告每个副本或实例的负载,群集资源管理器可以重新组织群集中的各个服务对象。 重新组织服务有助于确保服务获得所需的资源。 繁忙的服务会有效地从其他副本或当前空闲或执行较少工作的实例“回收”资源。
在 Reliable Services 中,动态报告负载的代码如下所示:
代码:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
服务可在创建时报告为其定义的任何指标。 如果服务针对未配置为要使用的指标报告负载,则 Service Fabric 会忽略该报告。 如果同时报告了其他有效指标,则接受这些报告。 服务代码可以测量和报告其了解并知道如何操作的所有指标,并且操作者可以指定要使用的指标配置,而不必更改服务代码。
报告分区负载
上一部分介绍了服务副本或实例如何报告负载。 还有一个附加选项,用于通过 Service Fabric API 动态报告分区副本或实例的负载。 报告分区负载时,可以同时报告多个分区。
将采用来自副本或实例本身的负载报表的使用方式来使用这些报表。 在通过副本或实例或通过报告分区的新负载值来报告新的负载值之前,已报告的值将一直有效。
使用此 API 可以以多种方式更新群集中的负载:
- 有状态服务分区可以更新其主副本负载。
- 无状态服务和有状态服务均可更新其所有辅助副本或实例的负载。
- 无状态服务和有状态服务均可更新节点上特定副本或实例的负载。
此外,还可以同时合并每个分区的任意个更新。 应通过 PartitionMetricLoadDescription 对象指定特定分区的负载更新组合,该对象可包含相应的负载更新列表,如下例所示。 负载更新通过 MetricLoadDescription 对象表示,该对象可包含指标的当前或预测负载值(已指定指标名称) 。
注意
预测的指标负载值当前是一项预览功能 。 通过它,可在 Service Fabric 端报告和使用预测的负载值,但该功能当前未启用。
可以使用单个 API 更新多个分区的负载,在这种情况下,输出将包含每个分区的响应。 如果由于某种原因未能成功应用分区更新,则将跳过该分区的更新,并提供相应的目标分区的错误代码:
- PartitionNotFound - 指定的分区 ID 不存在。
- ReconfigurationPending - 分区目前正在重新配置。
- InvalidForStatelessServices - 试图更改属于无状态服务的分区的主副本的负载。
- ReplicaDoesNotExist - 指定的节点上不存在辅助副本或实例。
- InvalidOperation - 在以下两种情况下可能会出现:更新属于系统应用程序的分区的负载,或未启用更新预测负载。
如果返回了其中一些错误,可更新特定分区的输入,然后重试其更新。
代码:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
在此示例中,你将更新分区 53df3d7f-5471-403b-b736-bde6ad584f42 的最新报告负载。 指标 CustomMetricName0 的主副本加载将更新为值 100。 同时,位于节点 NodeName0 的特定辅助副本的同一指标的负载将更新为值 200。
更新服务的指标配置
可在服务处于活动状态时,动态更新与该服务关联的指标列表以及这些指标的属性。 这样就可以进行试验并增加灵活性。 下面是一些适用的情况示例:
- 针对一项特定服务禁用报出错误的指标
- 基于所需行为重新配置指标的权重
- 仅在通过其他机制部署并验证代码之后启用新指标
- 根据观察到的行为和消耗量,更改服务的默认负载
用于更改指标配置的主要 API 是 C# 中的 FabricClient.ServiceManagementClient.UpdateServiceAsync 和 PowerShell 中的 Update-ServiceFabricService。 使用这些 API 指定的任何信息会立即替换服务的现有指标信息。
混用默认负载值和动态负载报告
默认负载和动态负载可用于同一服务。 服务同时利用默认负载和动态负载报告时,默认负载将充当估计值,直到显示动态报告。 默认负载非常好,因为它为群集资源管理器分配了一些工作。 默认负载允许群集资源管理器在创建服务对象时将其放置在合理位置。 如果没有提供默认负载信息,则服务会有效地随机放置。 当负载报告稍后传入时,初始的随机放置通常是错误的,群集资源管理器不得不移动服务。
让我们沿用前一示例,了解在添加一些自定义指标和动态负载报告时会发生什么情况。 在此示例中,使用“MemoryInMb”作为示例指标。
注意
内存是 Service Fabric 可进行资源控制的系统指标之一,自行报告此指标通常很困难。 实际上,不需要自行报告内存消耗量;此处使用内存是为了帮助了解群集资源管理器的功能。
假设最初使用以下命令创建了有状态服务:
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -Metric @("MemoryInMb,High,21,11","PrimaryCount,Medium,1,0","ReplicaCount,Low,1,1","Count,Low,1,1")
注意,此语法是 ("MetricName, MetricWeight, PrimaryDefaultLoad, SecondaryDefaultLoad")。
让我们看一下可能的群集布局情况:
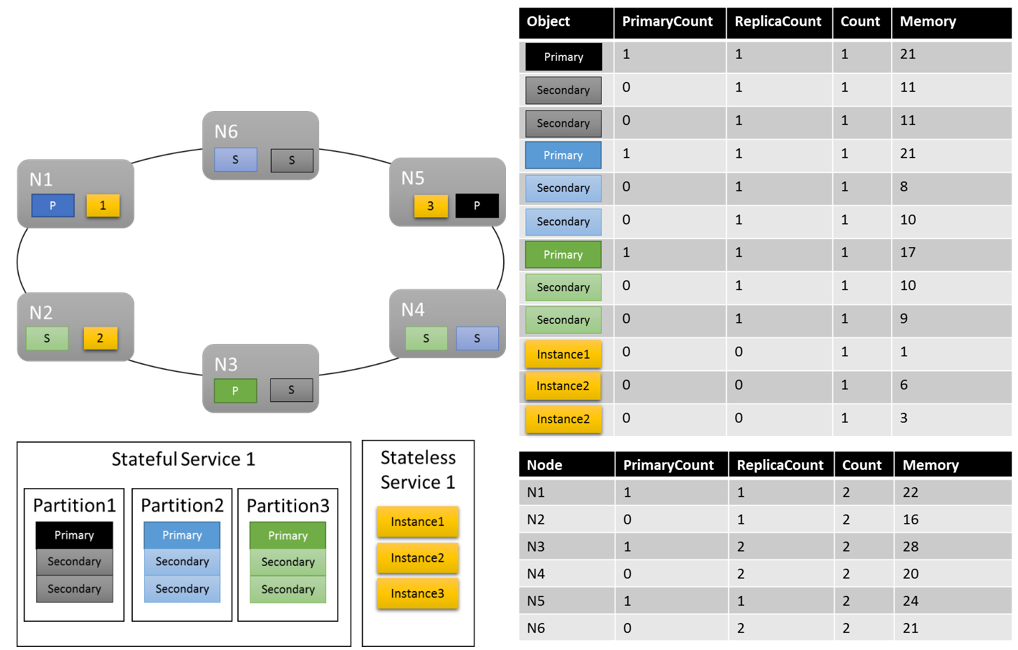
有几个问题值得注意:
- 分区内的每个次要副本都可以有自己的负载
- 总体来说,指标看起来已均衡。 对于内存,最大和最小负载之间的比率为 1.75(最大负载的节点是 N3,最小负载的节点是 N2,且 28/16 = 1.75)。
仍需解释的一些事项:
- 何者确定 1.75 的比率是否合理? 群集资源管理器如何知道此值是否够好,或者还需要再做些什么?
- 何时发生平衡?
- 内存的权重“很高”是什么意思?
指标权重
跨不同服务跟踪相同指标非常重要。 该全局视图允许群集资源管理器跟踪群集中的消耗,均衡节点间的消耗,并确保节点不会超出容量。 但是,相同指标的重要性对于服务而言可能有所差异。 此外,在具有许多指标和大量服务的群集中,对于所有指标而言,可能不存在能完全均衡的解决方案。 群集 Resource Manager 应如何处理这些情况?
在没有完美的解答时,群集资源管理器可以使用指标权重来决定如何均衡群集。 指标权重还允许群集 Resource Manager 以不同方式均衡特定服务。 指标可以有四个不同的权重级别:零、低、中和高。 考虑是否均衡时,权重为“零”的指标没有任何价值。 但是,其负载对于容量管理仍有价值。 权重为“零”的指标仍然有用,且经常用作服务行为和性能监视的一部分。 这篇文章深入介绍了如何使用指标监视和诊断服务。
群集中不同指标权重的真正影响是群集 Resource Manager 会生成不同的解决方案。 指标权重告知群集 Resource Manager 某些指标比其他指标更重要。 当没有完美的解决方案时,群集 Resource Manager 倾向于使用能更好地均衡较高权重指标的解决方案。 如果服务认为特定指标不重要,则可能会发现其对该指标的使用不均衡。 这可使其他服务均匀分布某些对其而言非常重要的指标。
让我们查看一个负载报告示例,以及不同的指标权重如何在群集中造成不同的分配。 在此示例中,我们看到切换指标的相对权重会导致群集资源管理器创建不同的服务排列。
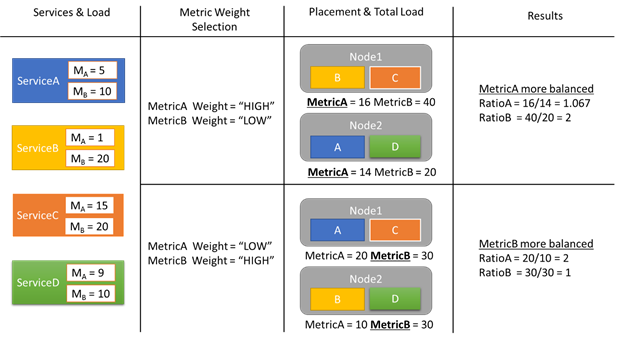
此示例中有 4 种不同的服务,所有服务都针对两个不同指标 MetricA 和 MetricB 报告不同的值。 在其中一个用例中,所有服务定义 MetricA 为最重要的指标(权重 = 高),MetricB 为不重要的指标(权重 = 低)。 因此会看到群集资源管理器在放置服务时会采用使得 MetricA 比 MetricB 更均衡的方式。 “更均衡”意味着 MetricA 具有比 MetricB 更小的标准偏差。 在第二个方案中,我们反转指标权重。 结果,群集资源管理器会交换服务 A 与 B,以产生 MetricB 比 MetricA 更加均衡的分配。
注意
指标权重决定群集资源管理器应该如何均衡,而不是应何时进行均衡。 有关实现均衡的详细信息,请参阅此文
全局指标权重
假设 ServiceA 将 MetricA 的权重定义为“高”,并且 ServiceB 将 MetricA 的权重定义为“低”或“零”。 最终使用的实际权重是多少?
系统会为每个指标跟踪多个权重。 第一个权重是在服务创建时为指标定义的权重。 另一个权重是自动计算的全局权重。 计算解决方案的分数时,群集资源管理器会使用这两个权重。 应同时将这两个权重纳入考虑,这很重要。 这样一来,群集资源管理器可以根据服务自身的优先级平衡每个服务,并确保群集在整体上得到正确分配。
如果群集资源管理器不在乎全局和局部均衡,会发生什么情况? 构造全局均衡的解决方案虽然很简单,但这会导致单个服务的资源不够均衡。 在以下示例中,我们关注仅使用默认指标配置的服务,并了解只考虑全局均衡时会发生什么情况:
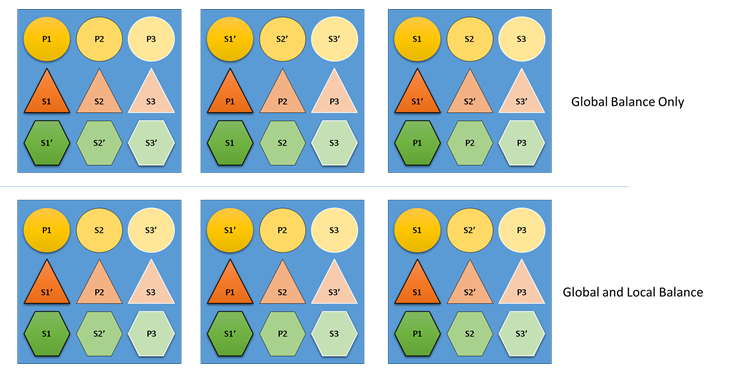
最上面的示例只探讨了全局均衡,群集整体上的确达到均衡。 所有节点的主副本计数和总副本计数都相同。 不过,如果查看此分配的实际影响,就不是那么理想:丢失任何节点对特定工作负荷带来不成比例的影响,因为这除去了其所有的主要副本。 例如,如果第一个节点出现故障,圆形服务的三个不同分区的三个主副本将全部丢失。 相反,三角形和六边形服务的分区丢失一个副本。 这不会导致中断,只是不得不恢复已停止运行的副本。
在最下面的示例中,群集 Resource Manager 已根据全局均衡和按服务的均衡来分发副本。 当计算解决方案的分数时,它将大部分权重分配给全局解决方案,将(可配置的)部分权重分配给单个服务。 指标的全局均衡是根据各服务的指标权重平均值进行计算的。 根据服务自身的定义指标权重平衡每个服务。 这可确保服务根据自身需要在自身内部进行均衡。 因此,如果第一个节点同样发生故障,则所有服务的所有分区都会发生此故障。 这对每个分区的影响都是相同的。
后续步骤
- 有关服务配置的详细信息,请参阅了解如何配置服务(service-fabric-cluster-resource-manager-configure-services.md)
- 定义碎片整理指标是合并(而不是分散)节点上负载的一种方式。若要了解如何配置碎片整理,请参阅此文
- 若要了解群集 Resource Manager 如何管理和均衡群集中的负载,请查看有关均衡负载的文章
- 从头开始并获取 Service Fabric 群集 Resource Manager 简介
- 移动成本是向群集 Resource Manager 发出信号,表示移动某些服务比移动其他服务会产生更高成本的方式之一。 若要了解有关移动成本的详细信息,请参阅此文