Service Fabric 群集资源管理器用于管理群集中的负载指标的默认策略是分散负载。 确保均匀地使用节点,避免出现导致争用和浪费资源的热点和冷点。 若要幸免于故障,让工作负荷分布在群集中还是最安全的方法,因为它可确保某个故障不会导致给定的工作负荷大部分失效。
Service Fabric 群集资源管理器支持另一种用于管理负载的策略 - 重整。 重整意味着合并指标,而不是尝试将指标的使用分布到群集中。 合并只是默认均衡策略的反转 - 群集资源管理器尝试增加指标负载的平均标准偏差,而不是将偏差最小化。
何时使用重整
在群集中分布负载会使用每个节点上的一些资源。 某些工作负荷会创建使用大多数或全部节点的极大服务。 在这些情况下,创建大型工作负荷后,很可能在任何节点上都没有足够的空间可用于运行这些工作负荷。 大型工作负荷不是 Service Fabric 的问题,在这些情况下,群集资源管理器确定需要重新组织群集,为此大型工作负荷腾出空间。 但是,在此期间该工作负荷必须等待在群集中进行计划。
如果有许多服务和状态来回移动,则可能需要很长时间才能将大型工作负荷放置在群集中。 这更可能是,群集中的其他工作负荷也很大,因此重新组织需要较长时间。 Service Fabric 团队在模拟此情况时测量了创建时间。 我们发现,一旦群集利用率达到 30%-50%,创建大型服务就会花费更长的时间。 为了处理这种情况,我们引入了重整作为一种平衡策略。 我们发现,对于大型工作负荷,尤其是创建时间很重要的大型工作负荷,重整确实可帮助这些新的工作负荷在群集中获得计划。
可以配置重整指标,让群集 Resource Manager 主动尝试将服务负载紧缩到更少的节点上。 这有助于确保(几乎)始终有空间可用于大型服务,而不必重新组织群集。 无需重新组织群集,这样可以快速创建大型工作负荷。
大多数人无需执行重整操作。 服务通常很小,因此不难在群集中为它们找到空间。 如果可以重新组织,则会再次快速地进行,因为大多数服务很小,可以快速地并行移动。 但是,如果需要快速创建大型服务,则适合使用重整策略。 接下来将讨论使用重整的折衷方案。
重整的折衷方案
重整会增加失败的影响力,因为更多服务在发生故障的节点上运行。 重整还会增加成本,因为必须保留群集中的资源作为备用,等待创建大规模的工作负荷。
下图提供了两个群集的直观表示,其中一个已经过重整,另一个则没有经过重整。
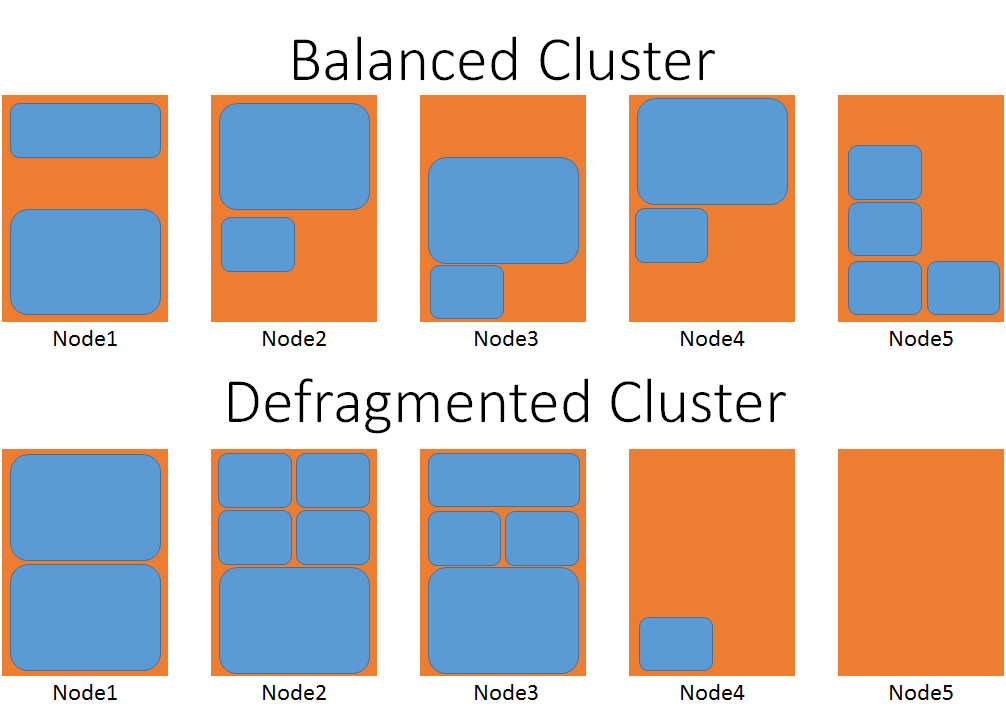
在平衡的情况下,请考虑放置其中一个最大的服务对象所需的移动数。 在经过重整的群集中,大型工作负荷可放置在四个或五个节点上,而无需等待移动任何其他服务。
重整的优点和缺点
从概念上讲,重整有其他哪些利弊呢? 下面是要注意的事项一览表:
| 重整的优点 | 重整的缺点 |
|---|---|
| 能够更快地创建大型服务 | 将负载集中到更少的节点,增大资源争用 |
| 在创建期间实现较少的数据移动 | 故障可能影响更多服务,并导致更多的服务流动 |
| 能够丰富描述要求和空间的回收 | 更复杂的整体资源管理配置 |
可以混合同一群集中的重整指标和标准指标。 群集 Resource Manager 会尝试尽可能多地合并重整指标,同时分配出其他指标。 混合使用重整和均衡策略的结果依赖于多种因素,包括:
- 均衡指标的数目与重整指标的数目
- 是否有任何服务使用这两种类型的指标
- 指标权重
- 当前指标负载
需要进行试验来确定所需的准确配置。 建议先彻底度量工作负荷,然后再启用生产环境中的重整指标。 在同一服务中混合重整和均衡指标时,尤其如此。
配置重整指标
配置重整指标是群集中的全局决策,可以选择单个指标进行重整。 以下配置代码片段演示如何配置重整的指标。 在这种情况下,“Metric1”会配置为重整指标,而“Metric2”将继续按常规方法进行均衡。
ClusterManifest.xml:
<Section Name="DefragmentationMetrics">
<Parameter Name="Metric1" Value="true" />
<Parameter Name="Metric2" Value="false" />
</Section>
通过用于独立部署的 ClusterConfig.json 或用于 Azure 托管群集的 Template.json:
"fabricSettings": [
{
"name": "DefragmentationMetrics",
"parameters": [
{
"name": "Metric1",
"value": "true"
},
{
"name": "Metric2",
"value": "false"
}
]
}
]
后续步骤
- 群集 Resource Manager 提供许多用于描述群集的选项。 若要详细了解这些选项,请查看这篇介绍 Service Fabric 群集的文章
- 指标是 Service Fabric 群集资源管理器在群集中管理消耗和容量的方式。 若要详细了解指标及其配置方式,请查看此文