延迟(有时被称为响应时间)是指应用程序必须等待请求完成的时间。 延迟可能会直接影响应用程序的性能。 对于在循环中有人工操作的情况(如处理信用卡交易或加载网页),低延迟通常很重要。 需要以较高速率处理传入事件(如遥测日志记录或 IoT 事件)的系统,也需要低延迟。 本文介绍如何了解和测量块 blob 上操作的延迟,以及如何针对低延迟设计应用程序。
Azure 存储为块 blob 提供两个不同的性能选项:高级和标准。 与标准块 blob 相比,高级块 blob 可以通过高性能 SSD 磁盘显著降低延迟并提高一致性。 有关详细信息,请参阅高级块 blob 存储帐户。
关于 Azure 存储延迟
Azure 存储延迟与 Azure 存储操作的请求速率相关。 请求速率也称每秒的输入/输出操作 (IOPS)。
若要计算请求速率,请首先确定完成每个请求所需的时间长度,然后计算每秒可处理的请求数。 例如,假设请求需要 50 毫秒 (ms) 才能完成。 如果某个应用程序使用一个线程,并且该线程具有一个未完成的读取或写入操作,则应达到 20 IOPS (每个请求 1 秒或 1000 毫秒/50 毫秒)。 从理论上讲,如果线程计数翻倍变为 2,则应用程序应能够达到 40 IOPS。 如果每个线程的未完成异步读取或写入操作翻倍变为 2,则应用程序应能够达到 80 IOPS。
在实践中,由于客户端中来自任务计划、上下文切换等的开销,请求速率并非总是线性缩放。 在服务端,可能会由于 Azure 存储系统压力、所用存储介质的差异、其他工作负载噪音、维护任务以及其他因素,导致延迟会反复不定。 最后,由于拥塞、重新路由或其他中断,客户端与服务器之间的网络连接可能会影响 Azure 存储延迟。
Azure 存储带宽(也称为吞吐量)与请求速率相关,可通过将请求速率 (IOPS) 乘以请求大小进行计算。 例如,假设每秒 160 个请求,每 256 KiB 的数据会导致每秒 40960 KiB 或每秒 40 MiB 的吞吐量。
块 blob 的延迟指标
Azure 存储为块 blob 提供两个延迟指标。 可以在 Azure 门户中查看这些指标:
端对端 (E2E) 延迟测量 Azure 存储接收到请求的第一个数据包直到 Azure 存储接收到响应的最后一个数据包的客户端确认之间的时间间隔。
服务器延迟测量从 Azure 存储接收到请求的最后一个数据包直到从 Azure 存储返回响应的第一个数据包之间的时间间隔。
下图显示了调用 Get Blob 操作的示例工作负荷的平均成功 E2E 延迟和平均成功服务器延迟:
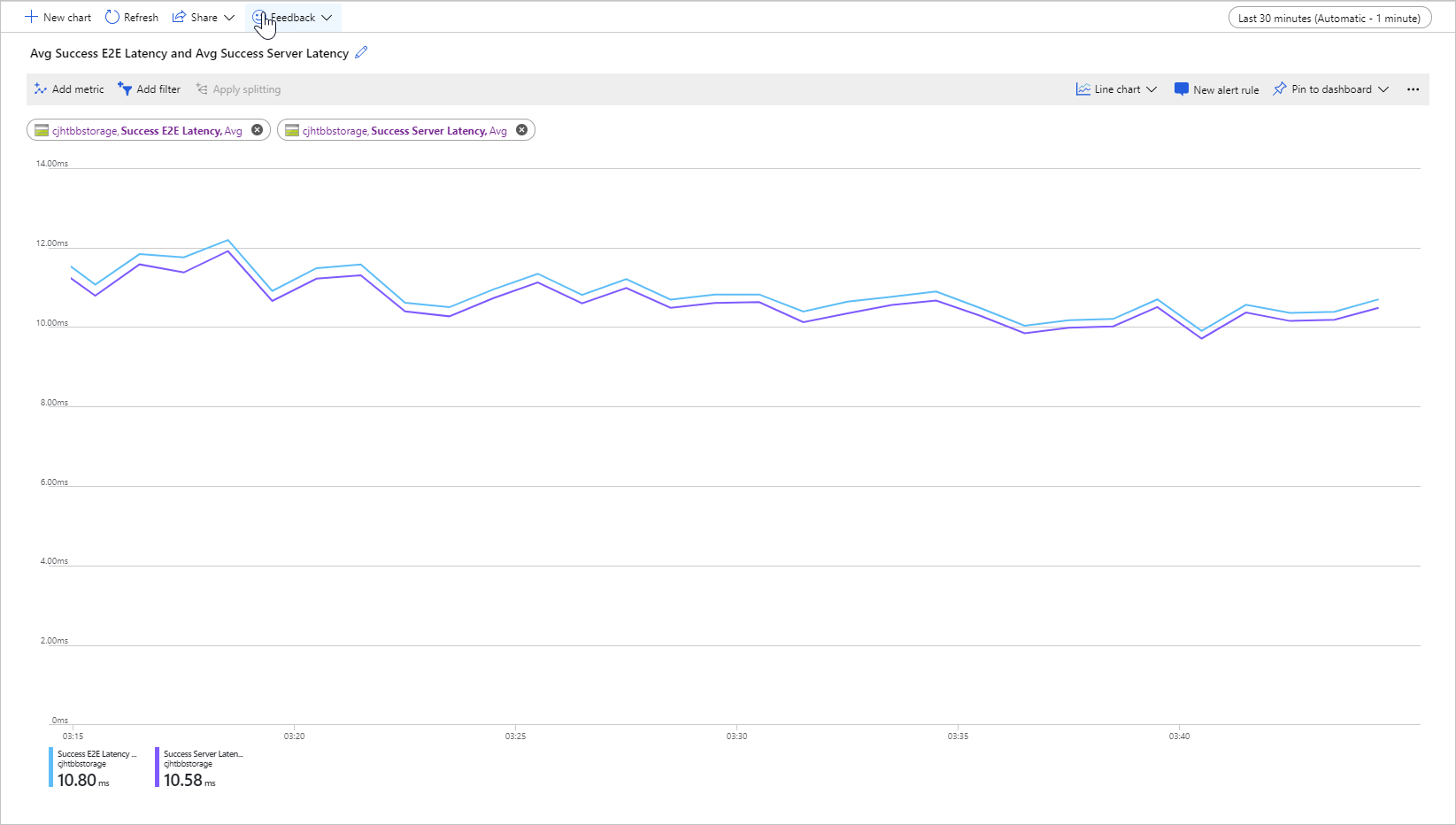
在正常情况下,端到端延迟和服务器延迟之间的间隔很小,这就是图像对示例工作负荷显示的内容。
如果查看端到端和服务器延迟指标,发现端到端延迟明显高于服务器延迟,请调查并解决其他延迟的源。
如果你的端到端和服务器延迟相似,但你需要较低的延迟,则考虑迁移到高级块 blob 存储。
影响延迟的因素
影响延迟的主要因素是操作规模。 由于通过网络传输并由 Azure 存储处理的数据量,完成更大的操作需要更长的时间。
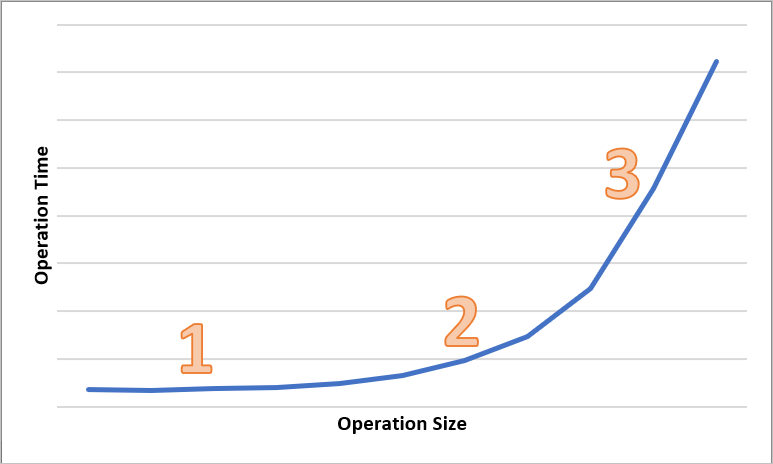
下图显示了各种规模的操作的总时间。 对于少量的数据,延迟时间间隔主要用于处理请求,而不是传输数据。 仅当操作规模增大时延迟时间间隔才会略微增加(下图中标记为 1)。 随着操作规模进一步增大,传输数据需要花费更多时间,以便在请求处理和数据传输之间拆分总延迟时间间隔(在下图中标记为 2)。 对于较大的操作规模,延迟时间间隔几乎都花费在传输数据上,请求处理很大程度上无关紧要(下图中标记为 3)。
诸如并发和线程等客户端配置因素也会影响延迟。 总体吞吐量取决于任意给定时间点在运行的存储请求数,以及应用程序如何处理线程。 包括 CPU、内存、本地存储和网络接口在内的客户端资源也会影响延迟。
处理 Azure 存储请求需要客户端 CPU 和内存资源。 如果客户端由于虚拟机功率不足或系统中某些进程失控而面临压力,则可用来处理 Azure 存储请求的资源较少。 任何争用或缺少客户端资源都会导致端到端的延迟增加,而不会增加服务器延迟,从而增加两个指标之间的差距。
同样重要的是客户端与 Azure 存储之间的网络接口和网络管道。 仅物理距离就会是一个重要因素,例如,客户端 VM 位于 Azure 区域中还是在本地。 其他因素(如网络跃点、ISP 路由和互联网状态)会影响总体存储延迟。
若要评估延迟,请先针对你的情况建立基线指标。 基线指标为你提供应用程序环境上下文中预期的端到端延迟和服务器延迟,具体取决于你的工作负荷配置文件、应用程序配置设置、客户端资源、网络管道以及其他因素。 如果具有基线指标,则可以更轻松地识别异常情况与正常情况。 使用基线指标,还可以观察更改的参数(例如应用程序配置或 VM 大小)的影响。