本文介绍适用于表服务解决方案的一些模式。 此外,还将了解如何实际解决其他表存储设计文章中提出的一些问题和权衡。 下图总结了不同模式之间的关系:
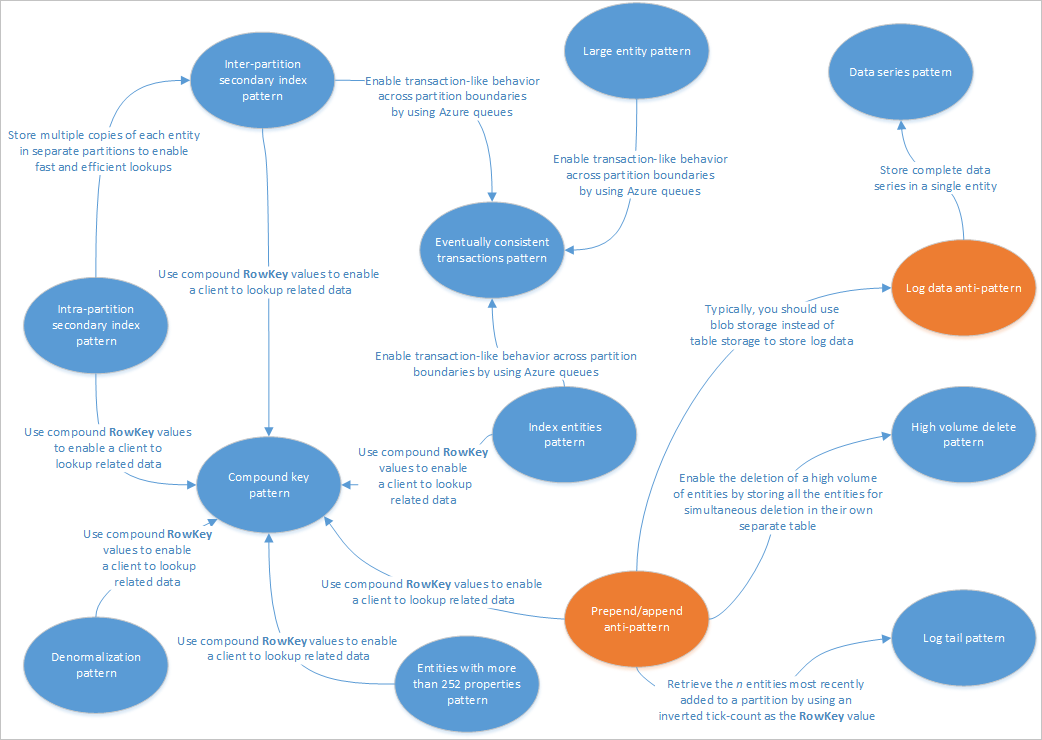
上面的模式映射突出显示了本指南中介绍的模式(蓝色)和反模式(橙色)之间的某些关系。 另外,还有许多其他值得考虑的模式。 例如,一种重要的表服务方案是使用命令查询职责分离 (CQRS) 模式中的具体化视图模式。
分区内辅助索引模式
在同一分区利用不同的 RowKey 值存储每个实体的多个副本,实现快速高效的查找,并通过使用不同 RowKey 值替换排序顺序。 副本之间的更新可以通过实体组事务 (EGT) 保持一致。
上下文和问题
表服务通过 PartitionKey 和 RowKey 值自动编制实体的索引。 这使客户端应用程序可以使用这些值高效地检索实体。 例如,使用下面所示的表结构时,客户端应用程序可使用点查询,通过部门名称和员工 ID(PartitionKey 和 RowKey 值)检索单个员工实体。 客户端还可以在每个部门内检索按员工 ID 排序的实体。
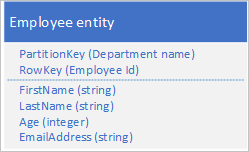
如果还要能够基于另一个属性(例如,电子邮件地址)的值查找员工实体,则必须使用效率较低的分区扫描来查找匹配项。 这是因为表服务不提供辅助索引。 此外,只能按 RowKey 顺序对员工列表排序。
解决方案
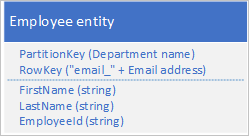
若要解决缺少辅助索引的问题,可存储每个实体的多个副本,每个副本使用不同的 RowKey 值。 如果存储具有如下所示的结构的实体,则可以基于邮件地址或员工 ID 高效地检索员工实体。 通过 RowKey 的前缀值“empid_”和“email_”,用户可使用一定范围的邮件地址或员工 ID 查询单个员工或某范围内的员工。

以下两个筛选条件(一个按员工 ID 查找,一个按电子邮件地址查找)都指定点查询:
- $filter=(PartitionKey eq 'Sales') and (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') and (RowKey eq 'email_jonesj@contoso.com')
如果查询一组员工实体,可使用 RowKey 中相应的前缀查询实体,指定范围按员工 ID 顺序或按电子邮件地址顺序进行排序。
若要查找销售部门中的所有员工,其员工 ID 范围为 000100 到 000199,请使用:$filter=(PartitionKey eq 'Sales') and (RowKey ge 'empid_000100') and (RowKey le 'empid_000199')
要通过以字母“a”开头的邮件地址查找销售部门中的所有雇员,请使用:$filter=(PartitionKey eq 'Sales') and (RowKey ge 'email_a') and (RowKey lt 'email_b')
上述示例中使用的筛选器语法源自表服务 REST API,有关详细信息,请参阅查询实体。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
使用表存储相对比较便宜,因此存储重复数据的成本开销不应是主要考虑因素。 但是,始终应根据预期的存储要求来评估设计成本,并且只通过添加重复的实体来支持客户端应用程序将执行的查询。
由于辅助索引实体与原始实体存储在同一分区,因此应确保不超过单个分区的可伸缩性目标。
可以通过使用 EGT 以原子方式更新实体的两个副本,来使重复的实体彼此保持一致。 这意味着应将实体的所有副本都存储在同一个分区。 有关详细信息,请参阅使用实体组事务部分。
用于每个实体的 RowKey 的值必须唯一。 请考虑使用复合键值。
在 RowKey 中填充数字值(例如员工 ID 000223),实现正确排序并根据上下限进行筛选。
不一定需要重复实体的所有属性。 例如,如果使用 RowKey 中的电子邮件地址查找实体的查询始终不需要员工的年龄,则这些实体可具有以下结构:
通常,最好存储重复数据并确保可以使用单个查询检索所有所需数据,而不是使用一个查询来找到实体,使用另一个查询来查找所需数据。
何时使用此模式
在以下情况下使用此模式:客户端应用程序需要使用各种不同的键检索实体;客户端需要以不同排序顺序检索实体;可以使用各种唯一值确定每个实体。 但是,在使用不同的 RowKey 值执行实体查找时,应确保不超过分区可伸缩性限制。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
分区间辅助索引模式
在单独分区/表格中利用不同 RowKey 值存储每个实体的多个副本,实现快速高效的查找,并借助不同的 RowKey 值替换排序顺序。
上下文和问题
表服务通过 PartitionKey 和 RowKey 值自动编制实体的索引。 这使客户端应用程序可以使用这些值高效地检索实体。 例如,使用下面所示的表结构时,客户端应用程序可使用点查询,通过部门名称和员工 ID(PartitionKey 和 RowKey 值)检索单个员工实体。 客户端还可以在每个部门内检索按员工 ID 排序的实体。
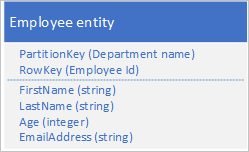
如果还要能够基于另一个属性(例如,电子邮件地址)的值查找员工实体,则必须使用效率较低的分区扫描来查找匹配项。 这是因为表服务不提供辅助索引。 此外,只能按 RowKey 顺序对员工列表排序。
预期针对这些实体的事务量较大,并且想要将表服务限制客户端的风险降到最低。
解决方案
若要解决缺少辅助索引的问题,可存储每个实体的多个副本,每个副本都使用不同的 PartitionKey 和 RowKey 值。 如果存储具有如下所示的结构的实体,则可以基于邮件地址或员工 ID 高效地检索员工实体。 通过 PartitionKey 的前缀值“empid_”和“email_”,用户可识别要用于查询的索引。

以下两个筛选条件(一个按员工 ID 查找,一个按电子邮件地址查找)都指定点查询:
- $filter=(PartitionKey eq 'empid_Sales') and (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') and (RowKey eq 'jonesj@contoso.com')
如果查询一组员工实体,可使用 RowKey 中相应的前缀查询实体,指定范围按员工 ID 顺序或按电子邮件地址顺序进行排序。
- 若要查找销售部门中的所有员工,其员工 ID 范围为 000100 到 000199 且按照 ID 序号排列,请使用:$filter=(PartitionKey eq 'empid_Sales') and (RowKey ge '000100') and (RowKey le '000199')
- 要在销售部门中通过以“a”开头的邮件地址并按照邮件地址顺序查找所有员工,请使用:$filter=(PartitionKey eq 'email_Sales') and (RowKey ge 'a') and (RowKey lt 'b')
上述示例中使用的筛选器语法源自表服务 REST API,有关详细信息,请参阅查询实体。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
可以使用 最终一致的事务模式 将重复的实体最终与彼此保持一致,以维护主辅索引实体。
使用表存储相对比较便宜,因此存储重复数据的成本开销不应是主要考虑因素。 但是,始终应根据预期的存储要求来评估设计成本,并且只通过添加重复的实体来支持客户端应用程序将执行的查询。
用于每个实体的 RowKey 的值必须唯一。 请考虑使用复合键值。
在 RowKey 中填充数字值(例如员工 ID 000223),实现正确排序并根据上下限进行筛选。
不一定需要重复实体的所有属性。 例如,如果使用 RowKey 中的电子邮件地址查找实体的查询始终不需要员工的年龄,则这些实体可具有以下结构:
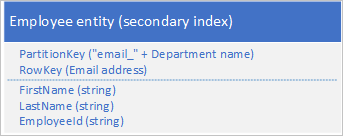
通常,最好存储重复数据并确保可以使用单个查询检索所有所需数据,而不是使用一个查询通过辅助索引找到实体,使用另一个查询通过主索引查找所需数据。
何时使用此模式
在以下情况下使用此模式:客户端应用程序需要使用各种不同的键检索实体;客户端需要以不同排序顺序检索实体;可以使用各种唯一值确定每个实体。 如果在使用不同 RowKey 值执行实体查找时想要避免超过分区可伸缩性限制,请使用此模式。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
最终一致性事务模式
通过使用 Azure 队列跨分区边界或存储系统边界启用最终一致的行为。
上下文和问题
EGT 在多个共享同一分区键的实体之间启用原子事务。 由于性能和伸缩性原因,你可能会决定在不同分区或不同存储系统中存储具有一致性要求的实体:在这种情况下,不能使用 EGT 来维护一致性。 例如,可能需要保持以下对象之间的最终一致性:
- 存储在同一个表的两个不同分区中的实体、存储在不同表中的实体,或存储在不同存储帐户中的实体。
- 存储在表服务中的实体和存储在 Blob 服务中的 blob。
- 表服务中存储的实体和文件系统中的文件。
- 存储在表服务中的实体还使用 Azure 认知搜索服务编制了索引。
解决方案
通过使用 Azure 队列,可以实现一种解决方案,用于在两个或更多个分区或存储系统之间提供最终一致性。 为了说明此方法,假定需要能够将旧员工实体存档。 旧员工实体很少进行查询,并应从处理当前员工的任何活动中排除。 为满足该要求,需将现职员工存储在 Current 表中,将离职员工存储在 Archive 表中。 需要将员工实体从 Current 表中删除再添加到 Archive 表中,才可对该员工存档,但不能使用 EGT 执行这两个操作。 若要避免故障导致实体同时出现在这两个表中或未出现在任一表中的风险,存档操作必须确保最终一致性。 下面的序列图概述了此操作中的步骤。 在随后的文本中提供了有关异常路径的更多详细信息。
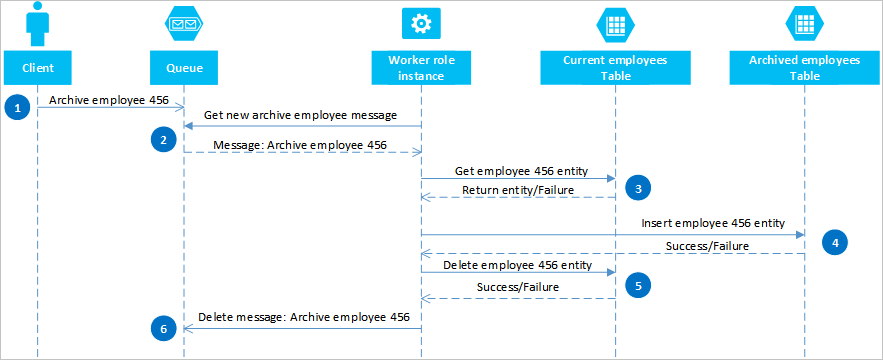
客户端通过在 Azure 队列中放置一条消息来启动存档操作,在此示例中要将员工 #456 存档。 辅助角色在队列中轮询新消息;当它找到一个新消息时,会读取该消息,并在队列上保留一个隐藏的副本。 接下来,辅助角色从 Current 表中获取实体的副本,将该副本插入 Archive 表中,并删除 Current 表中的原始实体。 最后,如果在前面的步骤中没有出现错误,辅助角色将从队列中删除隐藏的消息。
在此示例中,步骤 4 将该员工插入到 Archive 表中。 它可以将该员工添加到 Blob 服务中的 blob 或文件系统中的文件。
从故障中恢复
为避免辅助角色需重启存档操作,有必要确保步骤 4 和 5 中的操作为幂等操作。 如果使用的是表服务,步骤 4 中应使用“插入或替换”操作;步骤 5 中应使用当前所用客户端库中的“如果存在则删除”操作。 如果使用的是其他存储系统,则必须使用相应的幂等操作。
如果辅助角色始终无法完成步骤 6,则在超时后该消息将重新出现在队列中,便于辅助角色尝试重新处理。 辅助角色可以检查已读取队列中的某条消息多少次,如有必要,可通过将该消息发送到单独的队列来将其标记“坏”消息以供调查。 若要深入了解如何读取队列消息和检查取消排队计数,请参阅 Get Messages(获取消息)。
表和队列服务发生的一些错误是暂时性错误,客户端应用程序应包括适当的重试逻辑以处理这些错误。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 此解决方案不提供事务隔离。 例如,当辅助角色执行步骤 4 和步骤 5 之间的操作时,客户端可以读取 Current 和 Archive 表,并查看数据的不一致视图。 数据将最终保持一致。
- 必须确保步骤 4 和步骤 5 是幂等的,才能确保最终是一致的。
- 可以通过使用多个队列和辅助角色实例来扩展此解决方案。
何时使用此模式
当需要保证不同分区或表中存在的实体之间的最终一致性时,请使用此模式。 可以扩展此模式,以便确保表服务和 Blob 服务及其他非 Azure 存储数据源(如数据库或文件系统)中的操作的最终一致性。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
- 实体组事务
- 合并或替换
注意
如果事务隔离对解决方案很重要,应考虑重新设计表,以便能够使用 EGT。
索引实体模式
维护索引实体以启用返回实体列表的高效搜索。
上下文和问题
表服务通过 PartitionKey 和 RowKey 值自动编制实体的索引。 这使客户端应用程序可以使用点查询高效地检索实体。 例如,使用下面所示的的表结构时,客户端应用程序可通过部门名称和员工 ID(PartitionKey 和 RowKey)高效检索单个员工实体。

如果还要能够根据另一个非唯一的属性(如姓氏)的值检索员工实体的列表,则必须使用效率较低的分区扫描来查找匹配项,而不是使用索引来直接查找。 这是因为表服务不提供辅助索引。
解决方案
要实现使用上面所示的实体结构按姓氏查找,必须维护员工 ID 的列表。 如果要检索具有特定姓氏(例如 Jones)的员工实体,必须首先找到姓氏为“Jones”的员工的员工 ID 列表,再检索这些员工实体。 有三个主要选项,用于存储员工 ID 列表:
- 使用 blob 存储。
- 在员工实体所在的同一分区中创建索引实体。
- 在不同分区或表中创建索引实体。
选项 #1:使用 blob 存储
使用第一个选项时,应为每个唯一的姓氏创建一个 blob,并在每个 blob 中存储具有该姓氏的员工的 PartitionKey(部门)和 RowKey(员工 ID)值的列表。 在添加或删除员工时,应确保相关 blob 的内容与员工实体是最终一致的。
选项 #2:在同一个分区中创建索引实体
对于第二个选项,请使用存储以下数据的索引实体:
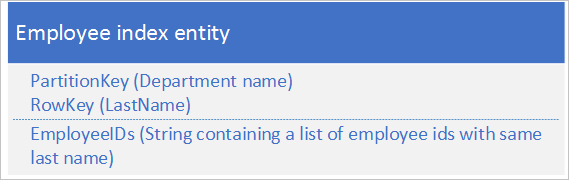
EmployeeIDs 属性包含一个员工 ID 列表,其中员工的姓氏存储在 RowKey 中。
以下步骤概述了在添加新员工时,如果使用第二个选项应遵循的过程。 在此示例中,我们要在 Sales 部门中添加 ID 为 000152、姓氏为 Jones 的员工:
- 使用 PartitionKey 值“Sales”和 RowKey 值“Jones”检索索引实体。保存此实体的 ETag 以便在步骤 2 中使用。
- 创建实体组事务(即批量操作),该项通过将新员工 ID 添加到 EmployeeIDs 字段的列表中,插入新的员工实体(PartitionKey 值“Sales”和 RowKey 值“000152”),并更新索引实体(PartitionKey 值“Sales”和 RowKey 值“Jones”)。 有关实体组事务的详细信息,请参阅“实体组事务”。
- 如果实体组事务由于开放式并发错误(其他人刚修改了索引实体)而失败,则需要从步骤 1 重新开始。
如果使用的是第二个选项,则可以使用类似的方法删除员工。 更改员工的姓氏会稍微复杂一些,你需要执行更新三个实体的实体组事务:员工实体、旧姓氏的索引实体和新姓氏的索引实体。 必须在进行任何更改之前检索每个实体以便检索 ETag 值,并可以使用该值利用开放式并发执行更新。
如果使用的是第二个选项,以下步骤概述了在需要查找部门中具有给定姓氏的所有员工时应遵循的过程。 在此示例中,我们要在 Sales 部门中查找姓氏为 Jones 的所有员工:
- 使用 PartitionKey 值“Sales”和 RowKey 值“Jones”检索索引实体。
- 分析 EmployeeIDs 字段中的员工 ID 列表。
- 如需了解其中每个员工的其他信息(如电子邮件地址),请通过 PartitionKey 值“Sales”和 RowKey 值,在步骤 2 中获得的员工列表中检索每个员工实体。
选项 #3:在不同分区或表中创建索引实体
对于第三个选项,请使用存储以下数据的索引实体:

EmployeeDetails 属性包含一个员工 ID 和部门名称对列表,其中员工的姓氏存储在 RowKey 中。
使用第三个选项时,不能使用 EGT 来保持一致性,因为索引实体位于与员工实体不同的分区中。 确保索引实体与员工实体是最终一致的。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 此解决方案至少需要两个查询来检索匹配的实体:一个用于查询索引实体来获取 RowKey 值的列表,另一个用于检索列表中的每个实体。
- 鉴于单个实体的最大大小为 1 MB,此解决方案中的选项 #2 和选项 #3 假定任何给定姓氏的员工 ID 列表永远不会超过 1 MB。 如果员工 ID 列表的大小有可能大于 1 MB,请使用选项 #1,并将索引数据存储在 Blob 存储中。
- 如果使用选项 #2(使用 EGT 处理添加和删除员工,以及更改员工的姓氏),则必须评估事务量是否会接近给定分区的伸缩性限制。 如果将接近,应考虑使用最终一致解决方案(选项 #1 或选项 #3),该方案使用队列来处理更新请求,并使你能够将索引实体存储在与员工实体所在的分区不同的分区中。
- 此解决方案中的选项 #2 假定你要在部门内按姓氏进行查找:例如,要在销售部门中检索姓氏为 Jones 的员工的列表。 如果要能够在整个组织内查找姓氏为 Jones 的所有员工,请使用选项 #1 或选项 #3。
- 可实现基于队列且实现最终一致性的解决方案,更多详细信息请参阅最终一致的事务模式。
何时使用此模式
要查找所有共享一个公用属性值的实体集(如姓氏为 Jones 的所有员工)时,请使用此模式。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
反规范模式
将相关数据组合在一起放置在单个实体中,使你能够使用单个点查询检索所有所需的数据。
上下文和问题
在关系数据库中,通常会规范化数据以消除从多个表中检索数据的查询产生的重复项。 如果规范化 Azure 表中的数据,则必须从客户端到服务器进行多次往返才能检索相关数据。 例如,使用下面所示的表结构需要两次往返,才能检索某个部门的详细信息:一次用于提取包括经理 ID 的部门实体,另一次请求提取员工实体中的经理详细信息。

解决方案
不是将数据存储在两个不同的实体中,而是对数据进行反规范化,并在部门实体中保留经理详细信息的副本。 例如:
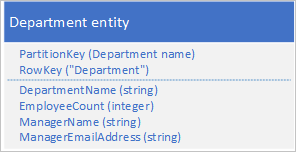
通过使用这些属性存储部门实体,现在可以使用点查询检索有关某个部门的所有所需详细信息。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 将一些数据存储两次会有一些相关的成本开销。 性能优势(由于向存储服务发生的请求数减少而产生)的重要性通常高于存储成本的轻微增长(并且通过减少提取某个部门的详细信息时所需的事务数可以部分抵消这一开销)。
- 必须维护存储经理相关信息的两个实体的一致性。 可以通过使用 EGT 在单个原子事务中更新多个实体来处理一致性问题:在这种情况下,部门经理所在的部门实体和员工实体存储在同一个分区中。
何时使用此模式
经常需要查找相关信息时,请使用此模式。 此模式减少了客户端要检索它所需的数据必须执行的查询数。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
Compound key pattern
使用复合 RowKey 值可让客户端使用单个点查询查找相关数据。
上下文和问题
在关系数据库中,自然会在查询中使用联接以便在单个查询中向客户端返回相关的数据片段。 例如,可能会使用员工 ID 来查找包含该员工的绩效和评价数据的相关实体的列表。
假定使用以下结构在表服务中存储员工实体:
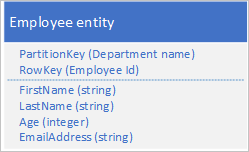
还需要存储有关员工为组织工作的每年的评价和绩效的历史数据,并且需要能够按年份访问此信息。 一种选择是创建另一个表,该表存储具有以下结构的实体:
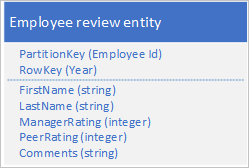
请注意,使用此方法时,你可能会决定在新实体中重复一些信息(如名字和姓氏),以便可以使用单个请求检索数据。 但是,无法保持强一致性,你不能使用 EGT 以原子方式更新这两个实体。
解决方案
在原始表中使用具有以下结构的实体存储新的实体类型:
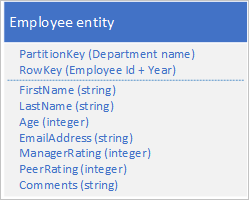
请注意,RowKey 现在是由员工 ID 和评价数据年份组成的复合键,使用它只需针对单个实体发出单个请求,即可检索员工的绩效和评价数据。
下面的示例概述了如何检索特定员工的所有评价数据(如 Sales 部门中的员工 000123):
$filter=(PartitionKey eq 'Sales') and (RowKey ge 'empid_000123') and (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 应使用适当的分隔符,轻松分析 RowKey 值(如 000123_2012)。
- 也将此实体存储在与包含同一员工的相关数据的其他实体在同一分区中,这意味着可以使用 EGT 来维护强一致性。
- 应考虑将查询数据的频率,以确定此模式是否合适。 例如,如果不经常访问评价数据但经常访问主要员工数据,则应将它们保存为不同的实体。
何时使用此模式
当需要存储一个或多个经常查询的相关实体时,请使用此模式。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
日志结尾模式
通过按日期时间倒序方式排序的 RowKey 值,检索最近添加到分区中的 n 个实体。
上下文和问题
一个常见的需求是能够检索最近创建的实体,例如某个员工提交的最近 10 个费用报销单。 表查询支持 $top 查询操作,可返回一个集中的前 n 个实体:没有可返回集中最后 n 个实体的等效查询操作。
解决方案
利用按日期/时间倒序顺序自然排序的 RowKey 存储实体,由此使最新条目始终显示为表格中的第一条。
例如,若要能够检索某个员工提交的最近 10 个费用报销单,可以使用从当前日期/时间派生的反向时点值。 下面的 C# 代码示例显示了一种方法,可用于为 RowKey 创建合适的“反向时点”值,使其按从最新到最旧的顺序排序:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
可以使用以下代码恢复日期时间值:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
表查询如下所示:
https://myaccount.table.core.chinacloudapi.cn/EmployeeExpense(PartitionKey='empid')?$top=10
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 必须使用前导零填充反向时点值,以确保字符串值按预期方式排序。
- 必须要注意分区级别的可伸缩性目标。 请注意不要创建热点分区。
何时使用此模式
当需要按反向日期/时间顺序访问实体或需要访问最近一次添加的实体时,请使用此模式。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
高容量删除模式
通过将要同时删除的所有实体都存储在它们自己的单独表中来实现删除大量实体;通过删除表来删除这些实体。
上下文和问题
许多应用程序会删除不再需要向客户端应用程序提供或已归档到其他存储介质的旧数据。 通常按日期标识此类数据:例如,需要删除 60 天以前的所有登录请求的记录。
可以使用 RowKey 中登录请求的日期和时间:
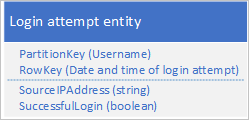
此方法可避免产生分区热点,因为应用程序可以在一个单独的分区中插入和删除每个用户的登录实体。 但是,如果有大量实体,此方法可能成本高昂且非常耗时,因为首先需要执行表扫描以便确定所有要删除的实体,然后必须删除每个旧实体。 可以通过在 EGT 中成批处理多个删除请求来减少到服务器的往返次数。
解决方案
对每天的登录尝试使用一个单独的表。 在插入实体时可以使用上面的实体设计避免产生热点,而删除旧实体现在只是每天删除一个表的问题(单个存储操作),而不用每天查找并删除成百上千个单个登录实体。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 设计支持应用程序将使用数据的其他方式(如查找特定实体、与其他数据链接或生成聚合信息)吗?
- 插入新实体时,设计会避免产生热点吗?
- 如果要在删除某个表后重用同一表名,应会出现延迟。 最好始终使用唯一表名。
- 首次使用一个新表时,应会有某种限制,因为在此期间表服务将了解访问模式,并在节点上分配分区。 应考虑需要创建新表的频率。
何时使用此模式
有大量必须同时删除的实体时,请使用此模式。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
- 实体组事务
- 修改实体
数据系列模式
将完整的数据系列存储在单个实体中,以最大限度地减少发出请求的次数。
上下文和问题
一个常见方案用于要存储一系列数据的应用程序,该应用程序通常需要一次检索所有这些数据。 例如,用户的应用程序可能会记录每个员工每小时发送的 IM 消息数,并使用此信息来绘制每个用户在过去 24 小时内发送的消息数。 一个设计可以是为每个员工存储 24 个实体:
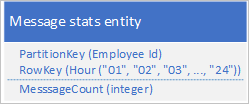
利用此设计,在应用程序需要更新消息计数值时,可以方便地找到并更新要为每个员工更新的实体。 但是,为了检索信息以绘制过去 24 小时的活动图,必须检索 24 个实体。
解决方案
使用以下设计,其中使用单独的属性来存储每小时的消息计数:
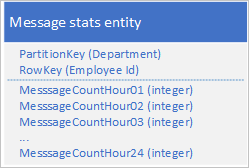
利用此设计,可以使用合并操作来更新某个员工在特定小时内的消息计数。 现在,可以使用对单个实体的请求检索绘制图表所需的所有信息。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 如果单个实体容纳不下完整的数据系列(一个实体最多可具有 252 个属性),请使用备用数据存储(如 blob)。
- 如果多个客户端同时更新实体,则需使用 ETag 实现开放式并发。 如果有许多客户端,则可能会遇到大量争用。
何时使用此模式
当需要更新和检索与单个实体关联的数据序列时,请使用此模式。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
宽实体模式
使用多个物理实体来存储具有多于 252 个属性的逻辑实体。
上下文和问题
单个实体不能具有超过 252 个的属性(不包括必需的系统属性),并且总共不能存储超过 1 MB 的数据。 在关系数据库中,在遇到行大小限制时,通常可通过添加一个新表并在二者之间强制实施 1 对 1 关系来避开行大小的任何限制。
解决方案
使用表服务,可以存储多个实体来表示具有多于 252 个属性的单个大型业务对象。 例如,如果要存储每个员工在过去 365 天内发送的的 IM 消息计数,可以使用以下设计(该设计使用两个具有不同架构的实体):
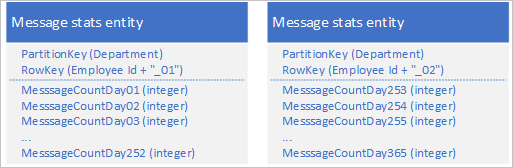
如果需要进行的更改需要更新这两个实体以使它们保持彼此同步,则可以使用 EGT。 否则,可以使用单个合并操作来更新特定天的消息计数。 若要检索单个员工的所有数据,必须检索这两个实体,这可以通过同时使用 PartitionKey 和 RowKey 值的两个有效请求来实现。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 检索完整的逻辑实体至少涉及两个存储事务:其中一个用于检索每个物理实体。
何时使用此模式
当需要存储的实体的大小或属性数超出表服务中单个实体的限制时,请使用此模式。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
- 实体组事务
- 合并或替换
大实体模式
使用 blob 存储来存储大属性值。
上下文和问题
单个实体不能存储总共超过 1 MB 的数据。 如果一个或多个属性存储的值导致实体的总大小超出此值,则无法在表服务中存储整个实体。
解决方案
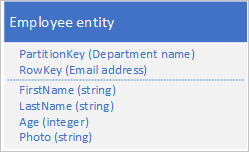
如果由于一个或多个属性包含大量数据而导致实体的大小超过 1 MB,可以将数据存储在 Blob 服务中,然后在实体的属性中存储 blob 的地址。 例如,可在 Blob 存储中存储员工的照片,并在员工实体的 Photo 属性中存储照片链接:
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 若要维护表服务中的实体与 Blob 服务中的数据之间的最终一致性,请使用最终一致事务模式。
- 检索完整实体至少涉及两个存储事务:一个用于检索实体,另一个用于检索 blob 数据。
何时使用此模式
当需要存储的实体大小超出表服务中单个实体的限制时,请使用此模式。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
前置/后置反模式
需要进行大量插入操作时,可将插入操作分散到多个分区,从而提高伸缩性。
上下文和问题
将实体前置或后置于存储实体通常会导致应用程序将新实体添加到分区序列中的第一个分区或最后一个分区。 在这种情况下,对于任何指定时间,所有插入都发生在同一个分区中,从而产生热点,使表服务无法将插入负载均衡分配到多个节点,这可能会导致应用程序达到分区的伸缩性目标。 例如,如果有一个应用程序记录员工对网络和资源的访问,则在事务量达到单个分区的伸缩性目标时,如下所示的实体结构可能会导致当前小时的分区成为热点:

解决方案
以下替代实体结构在应用程序记录事件时可避免在任何特定分区上产生热点:
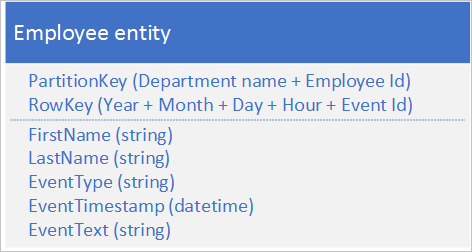
通过此示例,请注意 PartitionKey 和 RowKey 如何作为复合键。 PartitionKey 使用部门和员工 ID 将日志记录分布到多个分区。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 可避免在高效插入时产生热分区的替代键结构是否支持客户端应用程序进行的查询?
- 预期的事务量是否意味着可能会达到单个分区的可伸缩性目标而受存储服务限制?
何时使用此模式
访问热分区时,如果事务量可能会导致受存储服务限制,请避免使用前置/后置反模式。
相关模式和指南
实现此模式时,以下模式和指南也可能相关:
日志数据反模式
通常,应使用 Blob 服务(而不是表服务)来存储日志数据。
上下文和问题
日志数据的一个常见用例是检索针对特定日期/时间范围选择的日志条目:例如,想要查找应用程序在特定日期的 15:04 和 15:06 之间记录的所有错误和关键消息。 不会希望使用日志消息的日期和时间来确定日志实体要保存到的分区:该操作会导致热分区,因为所有日志实体在任意给定时间内均共享同一 PartitionKey 值(请参阅前置/后置反模式部分)。 例如,日志消息的以下实体架构会导致热分区,因为应用程序会将当前日期小时的所有日志消息都写入到该分区:
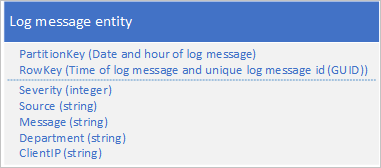
在此示例中,RowKey 包括日志消息的日期和时间以及消息 ID,前者用于确保日志消息存储按日期/时间顺序排序,后者可防止多条日志消息共享同一日期和时间。
还可使用 PartitionKey,确保应用程序在一组分区中写入消息。 例如,如果日志消息的源提供了一种方法可将消息分布到多个分区,则可以使用以下实体架构:
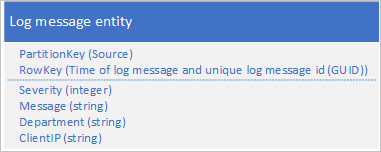
但是,此架构的问题是若要检索特定时间跨度的所有日志消息,必须搜索表中的每个分区。
解决方案
前一部分重点介绍了尝试使用表服务来存储日志条目的问题,并建议了两个并不令人满意的设计。 一种解决方案会导致热分区并具有在写入日志消息时性能不佳的风险;另一种解决方案由于需要扫描表中的每个分区才能检索特定时间跨度的日志消息而导致查询性能不佳。 对于此类方案,Blob 存储提供了更好的解决方案,这就是 Azure Storage Analytics 存储它收集的日志数据的方式。
本部分通过概述 Storage Analytics 如何在 blob 存储中存储日志数据说明了此方法如何存储通常按范围查询的数据。
Storage Analytics 以带分隔符格式将日志消息存储在多个 blob 中。 使用带分隔符的格式,客户端应用程序可以轻松地分析日志消息中的数据。
存储分析使用 blob 的命名约定,使你可以找到包含要搜索的日志消息的一个或多个 blob。 例如,名为“queue/2014/07/31/1800/000001.log”的 blob 包含与从 2014 年 7 月 31 日 18:00 开始的 1 小时的队列服务相关的日志消息。 “000001”指示这是此期间的第一个日志文件。 Storage Analytics 还会记录该文件中存储的第一条和最后一条日志消息的时间戳作为 blob 的元数据的一部分。 使用 Blob 存储的 API 可以根据名称前缀在容器中查找 Blob:若要查找包含从 18:00 开始的 1 小时的队列日志数据的所有 Blob,可以使用前缀“queue/2014/07/31/1800”。
存储分析在内部缓存日志消息,并定期更新相应的 blob 或使用最新一批日志条目创建新的 blob。 这会减少它必须执行的写入 blob 服务的次数。
如果要在应用程序中实现类似的解决方案,则必须考虑如何管理可靠性(在事件发生时向 blob 存储写入每个日志条目)与成本和伸缩性(在应用程序中缓冲更新,然后批量将其写入到 blob 存储)之间的权衡。
问题和注意事项
在决定如何存储日志数据时,请考虑以下几点:
- 如果创建了可避免潜在热分区的表设计,则可能会发现无法高效地访问日志数据。
- 若要处理日志数据,客户端通常需要加载多个记录。
- 虽然日志数据通常结构化,但 blob 存储可能会是更好的解决方案。
实现注意事项
本部分讨论在实现前面的部分中所述的模式时,需要牢记的一些注意事项。 本部分的大部分内容使用以 C# 编写的示例,其中使用了存储客户端库(在撰写本文时为版本 4.3.0)。
检索实体
如“针对查询的设计”部分所述,最高效的查询是点查询。 但是,在某些情况下,可能需要检索多个实体。 本部分介绍使用存储客户端库检索实体的一些常用方法。
使用存储客户端库执行点查询
执行点查询的最简单方法是使用 GetEntityAsync 方法,如以下 C# 代码段中所示,该代码片段检索 PartitionKey 值为“Sales”并且 RowKey 值为“212”的实体 :
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
请注意此示例如何将它检索的实体要求为 EmployeeEntity 类型。
使用 LINQ 检索多个实体
使用 Azure Cosmos DB 表标准库时,可以使用 LINQ 从表服务中检索多个实体。
dotnet add package Azure.Data.Tables
要使下面的示例正常工作,需要包含命名空间:
using System.Linq;
using Azure.Data.Tables
通过使用 filter 子句指定查询,可检索多个实体。 若要避免表扫描,应始终在 filter 子句中包括 PartitionKey 值,如有可能也包括 RowKey 值以避免表和分区扫描 。 表服务支持在 filter 子句中使用一组有限的比较运算符(大于、大于等于、小于、小于等于、等于和不等于)。
在以下示例中,employeeTable 是一个 TableClient 对象。 此示例在销售部门(假定 PartitionKey 存储部门名称)中查找姓氏以“B”开头(假定 RowKey 存储姓氏)的所有员工:
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
请注意该查询如何同时指定 RowKey 和 PartitionKey 以确保更佳性能。
以下代码示例显示了不使用 LINQ 语法的等效功能:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
注意
示例 Query 方法包含三个筛选条件。
通过查询检索大量实体
最佳查询根据 PartitionKey 值和 RowKey 值返回单个实体。 但是,在某些情况下,可能需要从同一个分区或者甚至从多个分区返回多个实体。
在这种情况下,应始终充分地测试应用程序的性能。
针对表服务的查询一次最多可以返回 1,000 个实体,并且可以执行时间最长为五秒。 如果结果集包含超过 1,000 个的实体,则当查询未在 5 秒内完成或者查询跨越分区边界时,表服务将返回一个继续标记,客户端应用程序使用该标记可以请求下一组实体。 若要深入了解继续标记的工作方式,请参阅 Query Timeout and Pagination(查询超时和分页)。
如果使用的是 Azure 表客户端库,当它从表服务返回实体时,可以自动处理延续令牌。 以下 C# 代码示例使用客户端库,在表服务于响应中返回延续令牌时将自动处理它们:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
还可以指定每页返回的最大实体数。 以下示例介绍如何通过 maxPerPage 查询实体:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
在更高级的方案中,你可能希望存储从服务返回的延续令牌,以便代码准确控制何时提取下一页。 以下示例演示了如何提取令牌并将其应用于分页结果的基本方案:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
通过显式使用继续标记,可以控制应用程序何时检索下一个数据段。 例如,如果客户端应用程序允许用户翻阅表中存储的实体,用户可能会决定不翻阅查询检索的所有实体,因此应用程序仅当用户翻阅完当前段中的所有实体后才会使用继续标记检索下一段。 此方法具有以下几个优点:
- 它使你能够限制要从表服务中检索的数据量以及通过网络移动的数据量。
- 它使你可以在 .NET 中执行异步 IO。
- 它使你可以将继续标记序列化到持久存储,以便可以在应用程序崩溃时继续。
注意
继续标记通常返回包含 1,000 个实体的段,尽管它可能会更少。 通过使用 Take 返回与查找条件匹配的前 n 个实体来限制查询返回的条目数时,也符合该情况:表服务可能会返回内含实体数少于 n 个的分段和 1 个继续标记,后者可用于检索剩余的实体。
服务器端投影
单个实体最多可以具有 255 个属性,并且大小最多可以为 1 MB。 查询表并检索实体时,可能不需要所有属性,并可以避免不必要地传输数据(以帮助减少延迟和降低成本)。 可以使用服务器端投影来只传输需要的属性。 以下示例只检索查询选择的实体的 Email 属性(与 PartitionKey、RowKey、Timestamp 和 ETag 一起)。
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
请注意如何获得 RowKey 值(即使它未包含在要检索的属性列表中)。
修改实体
使用存储客户端库可以通过插入、删除和更新实体修改存储在表服务中的实体。 可以使用 EGT 将多个插入、更新和删除操作一起批量处理以减少所需的往返次数并提高解决方案的性能。
存储客户端库执行 EGT 时引发的异常通常包含导致批处理失败的实体的索引。 如果正在调试使用 EGT 的代码,这非常有用。
还应考虑设计如何影响客户端应用程序处理并发和更新操作的方式。
管理并发
默认情况下,尽管客户端可强制表服务跳过这些检查,表服务仍会在单个实体级别上执行 Insert、Merge 和 Delete 操作的开放式并发检查。 若要深入了解表服务如何管理并发息,请参阅 在 Microsoft Azure 存储中管理并发。
合并或替换
TableOperation 类的 Replace 方法始终替换表服务中的完整实体。 如果在存储实体中存在某个属性时请求中未包含该属性,则请求将从存储实体中删除该属性。 除非你想要从存储实体中显式删除某一属性,否则必须在请求中包含每个属性。
要更新实体时,可使用 TableOperation 类的 Merge 方法减少发送到表服务的数据量。 Merge 方法会将存储实体的所有属性替换为请求中所含实体的属性值,但请求中未包含的存储实体的所有属性均保持不变。 如果使用大型实体并且只需在请求中更新少量属性,则此方法很有用。
注意
如果该实体不存在,Replace 和 Merge 方法会失败。 作为替代方法,可以使用 InsertOrReplace 和 InsertOrMerge 方法,这两个方法在实体不存在时会创建一个新实体。
处理异类实体类型
表服务是架构灵活的表存储,意味着单个表可以存储多种类型的实体,从而在设计中提供了极大的灵活性。 以下示例说明了同时存储员工实体和部门实体的表:
| PartitionKey | RowKey | 时间戳 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
每个实体仍然必须具有 PartitionKey、RowKey 和 Timestamp 值,但可以具有任何一组属性。 此外,没有任何信息指示实体的类型,除非选择在某处存储该信息。 有两个用于标识实体类型的选项:
- 在 RowKey(或可能是 PartitionKey)前面添加实体类型。 例如,将 EMPLOYEE_000123 或 DEPARTMENT_SALES 作为 RowKey 值。
- 使用一个单独的属性来记录实体类型,如下表中所示。
| PartitionKey | RowKey | 时间戳 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
如果两个不同类型的实体可能具有相同键值,则在 RowKey 前面添加实体类型的第一个选项会很有用。 它还会在分区中将同一类型的实体分组在一起。
此部分中讨论的技术与本指南前面的为关系建模一文中讨论的继承关系密切相关。
注意
应考虑在实体类型值中包含版本号以允许客户端应用程序演变 POCO 对象并处理不同版本。
本部分的剩余部分介绍存储客户端库中便于处理同一表中的多个实体类型的一些功能。
检索异类实体类型
如果使用表客户端库,则可通过三个选项来处理多个实体类型。
如果知道使用特定 RowKey 和 PartitionKey 值存储的实体的类型,则在检索实体时可以指定该实体类型(如前面两个检索 EmployeeEntity 类型的实体的示例所示):使用存储客户端库执行点查询和使用 LINQ 检索多个实体。
第二个选项是使用 TableEntity 类型(属性包)而不是具体的 POCO 实体类型,该选项无需序列化实体和将实体反序列化为 .NET 类型,因此还可提升性能。 以下 C# 代码可能会从表中检索多个不同类型的实体,但会将所有实体作 TableEntity 实例返回。 然后,它使用 EntityType 属性确定每个实体的类型:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
若要检索其他属性,必须对 TableEntity 类的实体使用 GetString 方法。
修改异类实体类型
无需知道实体的类型就可删除该实体,在插入实体时始终知道该实体的类型。 但是,可使用 TableEntity 类型来更新实体,而不必知道其类型,也无需使用 POCO 实体类。 以下代码示例检索单个实体,并在更新该实体前检查 EmployeeCount 属性是否存在。
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
使用共享访问签名控制访问权限
可以使用共享访问签名 (SAS) 令牌允许客户端应用程序修改(和查询)表实体,而无需在代码中包含存储帐户密钥。 通常情况下,在应用程序中使用 SAS 主要有以下三大优点:
- 无需将存储帐户密钥分发到不安全的平台(如移动设备),即可允许该设备访问和修改表服务中的实体。
- 可以卸下 Web 角色和辅助角色在管理传递到客户端设备(如最终用户计算机和移动设备)的实体时执行的一些工作负荷。
- 可以向客户端分配一组受约束且有时间限制的权限(如允许对特定资源进行只读访问)。
若要深入了解如何在表服务中使用 SAS 令牌,请参阅使用共享访问签名 (SAS)。
但是,仍必须生成授权客户端应用程序访问表服务中的实体的 SAS 令牌:应在可安全地访问存储帐户密钥的环境中执行此操作。 通常,使用 Web 角色或辅助角色生成 SAS 令牌并将其传递给需要访问实体的客户端应用程序。 由于生成 SAS 令牌并将其传递到客户端仍有开销,应考虑如何最有效地减少此开销,尤其是在大容量方案中。
可以生成授权访问表中实体子集的 SAS 令牌。 默认情况下,将为整个表创建 SAS 令牌,但也可以指定授权访问一组 PartitionKey 值或一组 PartitionKey 和 RowKey 值的 SAS 令牌。 可以选择为单个系统用户生成 SAS 令牌,使每个用户的 SAS 令牌仅允许他访问表服务中他自己的实体。
异步和并行操作
假设你将请求分布到多个分区,可以通过使用异步或并行查询来提高吞吐量和客户端响应能力。 例如,可以使用两个或更多个辅助角色实例并行访问表。 可以让单个辅助角色负责特定分区集,也可以直接使用多个辅助角色实例,每个辅助角色实例都能访问某个表中的所有分区。
在客户端实例中,可以通过以异步方式执行存储操作来提高吞吐量。 使用存储客户端库,可以轻松地编写异步查询和修改。 例如,可以从用于检索某个分区中的所有实体的同步方法开始,如以下 C# 代码中所示:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
可以轻松地修改此代码,使查询以异步方式运行,如下所示:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
在此异步示例中,可以看到对同步版本进行了以下更改:
- 方法签名现在包括 async 修饰符,并返回 Task 实例。
- 该方法现在并非调用 Query 方法来检索结果,而是调用 QueryAsync 方法,并使用 await 修饰符来以异步方式检索结果 。
客户端应用程序可以多次调用此方法(对 department 参数使用不同值),并且每个查询都会在一个单独的线程中运行。
此外,还可以用异步方式插入、更新和删除实体。 以下 C# 示例说明了一个简单的同步方法,该方法用于插入或替换员工实体:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
可以轻松地修改此代码,使更新以异步方式运行,如下所示:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
在此异步示例中,可以看到对同步版本进行了以下更改:
- 方法签名现在包括 async 修饰符,并返回 Task 实例。
- 不是调用 Execute 方法来更新实体,该方法现在调用 ExecuteAsync 方法,并使用 await 修饰符来以异步方式检索结果。
客户端应用程序可以调用多个类似这样的异步方法,每个方法调用都会在一个单独的线程中运行。