本文介绍开发流分析查询的常见问题以及如何进行故障排除。
本文介绍了编写 Azure 流分析查询时遇到的常见问题,以及如何排查和更正查询问题。 许多故障排除步骤都需要为流分析作业启用资源日志。 如果没有启用资源日志,请参阅使用资源日志对 Azure 流分析进行故障排除。
查询未生成预期输出
通过本地测试检查错误:
- 在 Azure 门户的“查询”选项卡上,选择“测试” 。 使用下载的示例数据测试查询。 检查并尝试修正所有错误。
如果使用了 Timestamp By,请验证事件的时间戳是否大于作业开始时间。
避免常犯的错误,例如:
确保按预期方式配置事件排序策略。 转到“设置”,选择“事件排序” 。 使用“测试”按钮测试查询时,不会应用此策略。 这是在浏览器中测试与在生产中运行作业之间的一个差别。
使用活动和资源日志进行调试:
资源利用率高
确保利用 Azure 流分析中的并行化。 可以学习通过配置输入分区和调整分析查询定义来使用查询并行化对流分析作业进行缩放。
如果资源利用率始终超过 80%,则水印延迟增加,积压事件的数量增加,请考虑增加流单元。 高利用率指示作业使用接近分配的最大资源。
逐步调试查询
在实时数据处理中,掌握查询过程中数据的状态是十分有用的。 可以使用 Visual Studio 中的作业关系图来查看此状态。 如果没有 Visual Studio,可以执行其他步骤来输出中间数据。
由于可以多次读取 Azure 流分析作业的输入或步骤,因此可以编写额外的 SELECT INTO 语句。 这样做会将中间数据输出至存储,并允许你检查数据的正确性,就如调试程序时的监视变量一样。
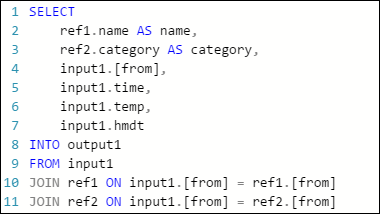
下列 Azure 流分析作业中的示例查询具有一个流输入、两个引用数据输入和一个向 Azure 表存储的输出。 查询联接数据中心和两个引用 Blob 中的数据,以获取名称和类别信息:
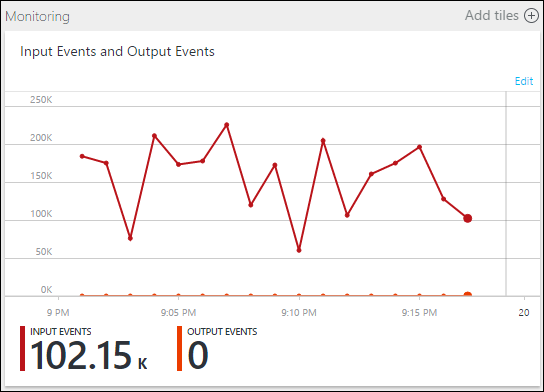
请注意,虽然作业正在运行,但在输出中未生成任何事件。 在“监视”磁贴上,可以看见输入正在生成数据,但不知道 JOIN 的哪个步骤导致所有事件被删除。
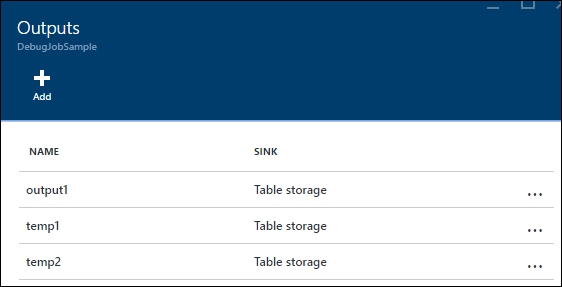
在此情况下,可添加几个额外的 SELECT INTO 语句,用于“记录”中间 JOIN 结果,以及从输入中读取的数据。
在此示例中,我们添加了两个新的“临时输出”。它们可以是你喜欢的任何接收器。 此处使用 Azure 存储作为示例:
然后,可以重写查询,如下所示:
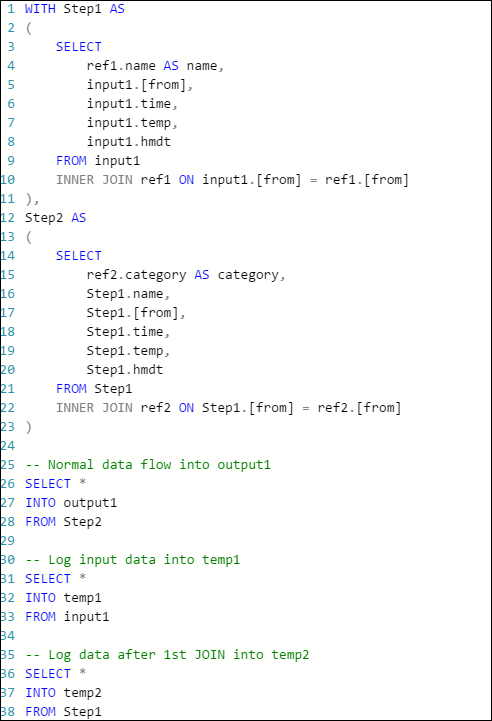
现在再次启动作业,并运行数分钟。 查询 temp1 和 temp2 通过 Visual Studio 云资源管理器生成下列各表:
temp1 表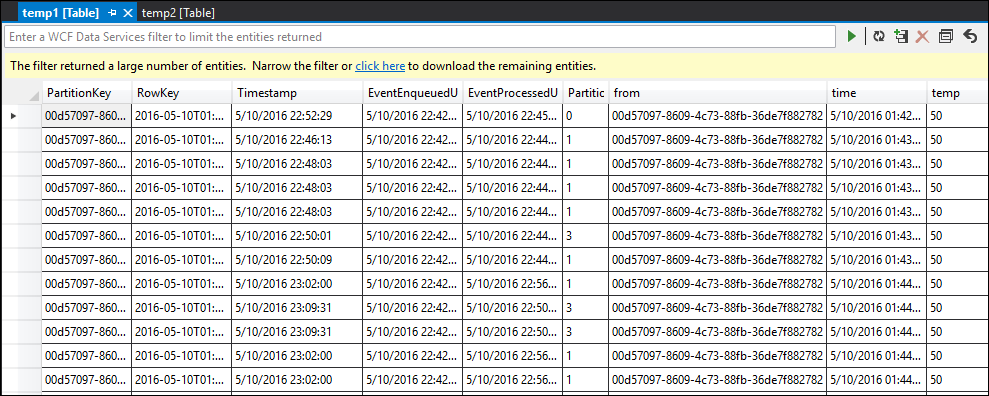
temp2 表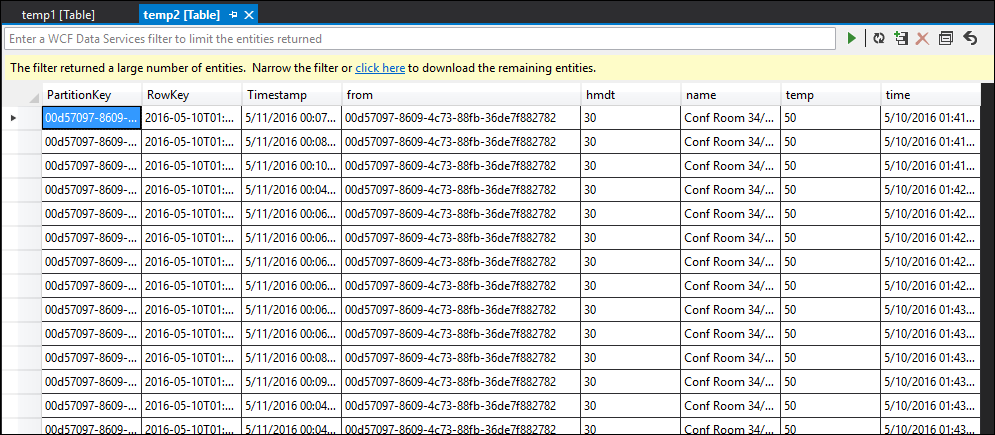
可以看到,temp1 和 temp2 都拥有数据,且 temp2 中正确填充了名称列。 但是,由于输出中没有数据,因此存在问题:
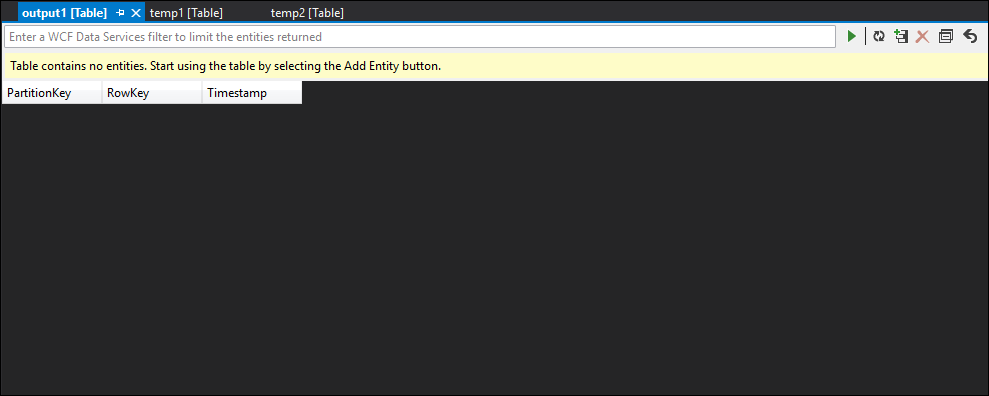
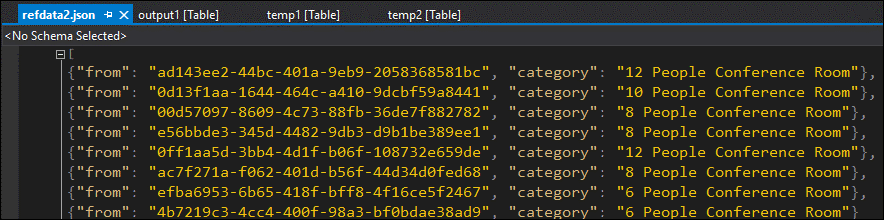
通过数据采样,几乎可以确定此问题与第二个 JOIN 有关。 可以从 Blob 下载并查看引用数据:
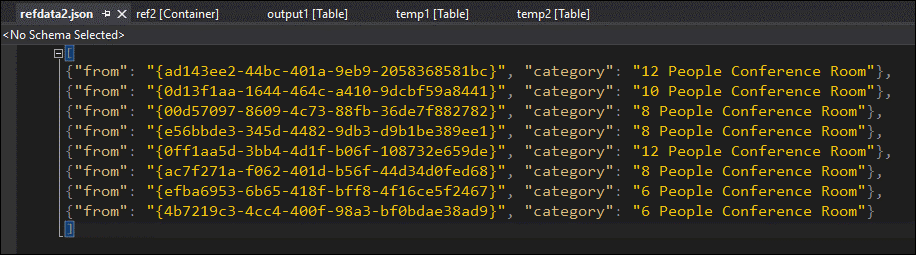
可以看到,此引用数据中的 GUID 的格式与 temp2 中 [来自] 列的格式不同。 这就是数据无法按预期到达 output1 的原因。
可以修复数据格式,将其上传至引用 Blob,然后再重新尝试:
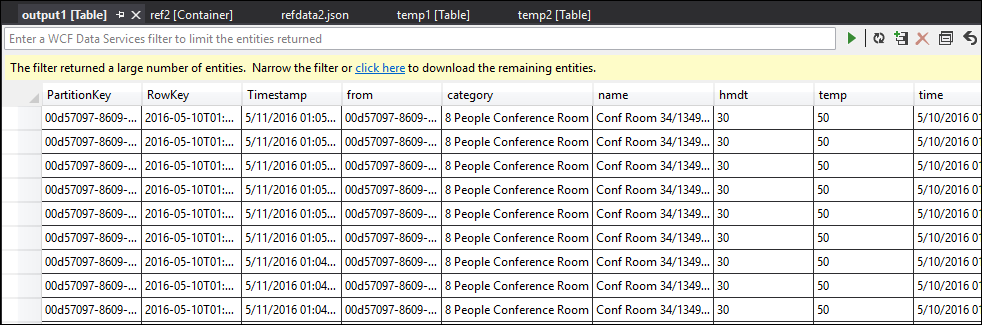
此时,输出中的数据按预期格式化和填充。
获取帮助
如需获取进一步的帮助,可前往 Azure 流分析的 Microsoft 问答页面。