本文提供了一种高级方法,用于为 Apache Spark 池准备和运行有效的Azure Synapse Analytics概念证明(POC)项目。
注意
本文是Azure Synapse概念验证手册系列文章的一部分。 有关系列概述,请参阅 Azure Synapse 概念验证指南。
准备 POC
POC 项目可帮助你就如何在基于云的平台上实施大数据和高级分析环境做出明智的业务决策,该平台利用 Azure Synapse 中的 Apache Spark 池。
POC 项目将确定基于云的大数据和高级分析平台必须支持的关键目标和业务驱动因素。 它将测试关键指标并证明对数据工程、机器学习模型构建和培训要求的成功至关重要的关键行为。 POC 不适合部署到生产环境。 相反,它是一个关注关键问题的短期项目,其结果可以放弃。
开始规划 Spark POC 项目之前,请执行以下操作:
- 确定组织在将数据移到云方面所要施加的任何限制或要制定的准则。
- 确定大数据和高级分析平台项目的行政或业务发起人。 确保他们为迁移到云提供支持。
- 确定在执行 POC 期间是否有技术专家和业务用户可为你提供支持。
在开始准备 POC 项目之前,我们建议先阅读 Apache Spark 文档。
提示
如果您是 Spark 池的新手,建议您完成使用 Azure Synapse Apache Spark 池执行数据工程的学习路径。
到目前为止,你应该已经确定当前没有阻碍因素,然后你可以开始为 POC 做准备。 如果不熟悉 Azure Synapse Analytics中的 Apache Spark 池,可以参考 本文档可在其中大致了解 Spark 体系结构,并了解它在 Azure Synapse 中的工作原理。
了解这些关键概念:
- Apache Spark 及其分布式体系结构。
- Spark 概念,如弹性分布式数据集 (RDD) 和分区(包括内存和物理层面)。
- Azure Synapse工作区、不同的计算引擎、管道和监视。
- Spark 池中的计算和存储分离。
- Azure Synapse中的身份验证和授权。
- 与 Azure Synapse 专用 SQL 池、Azure Cosmos DB 等集成的本地连接器。
Azure Synapse将计算资源与存储分离,以便更好地管理数据处理需求和控制成本。 Spark 池的无服务器架构允许您在不影响存储的情况下创建、删除、扩展和缩减 Spark 集群。 你可以完全暂停 Spark 群集(或设置自动暂停)。 这样,仅在使用时才需支付计算费用。 不使用时,只需支付存储费用。 你可以扩展 Spark 群集以满足繁重的数据处理需求或大型负载的需求,然后在处理次数不太密集时缩减群集(或完全关闭)。 你可以有效地缩放和暂停群集来降低成本。 Spark POC 测试应包括不同规模(小型、中型和大型)的数据引入和数据处理,以比较不同规模的价格和性能。 有关详细信息,请参阅 自动缩放 Azure Synapse Analytics Apache Spark 池。
务必了解各个 Spark API 之间的差异,以确定哪个最适合你的方案。 你可以选择性能更好或更易于使用的一个,以利用团队现有的技能集。 有关详细信息,请参阅三个 Apache Spark API 的说明:RDD、DataFrames 和 Datasets。
数据和文件分区在 Spark 中的工作方式略有不同。 了解差异将有助于优化性能。 有关详细信息,请参阅 Apache Spark 文档:分区发现和分区配置选项。
设定目标
成功的 POC 项目需要规划。 首先确定为何要执行 POC,以充分了解真正的动机。 动机可能包括现代化、成本节省、性能改进或集成体验。 请务必阐述 POC 的明确目标,以及 POC 成功的条件。 问问你自己:
- 你期望的 POC 输出是什么?
- 如何处理这些输出?
- 谁将会使用这些输出?
- POC 成功的条件是什么?
请记住,POC 应该是快速证明有限一组概念和功能的简短而专注的工作。 这些概念和功能应代表整个工作负载。 如果您有一长串需要验证的项目,可能需要规划多个原型验证(POC)。 在这种情况下,请定义 POC 之间的门,以确定是否需要继续下一个 POC。 鉴于在 Azure Synapse 中,不同的专业角色可能会使用 Spark 池和笔记本,您可以选择执行多个概念验证(POC)。 例如,一个 POC 可以专注于数据工程角色的要求,例如引入和处理。 另一个 POC 可以专注于机器学习 (ML) 模型开发。
在考虑 POC 目标时,请向自己提出以下问题以帮助形成目标:
- 是否要从现有的大数据和高级分析平台(本地或云)迁移?
- 是否在迁移的同时希望对现有引入和数据处理进行尽可能少的更改? 例如,从 Spark 到 Spark 的迁移,或从 Hadoop/Hive 到 Spark 的迁移。
- 是否在迁移的同时希望进行一些广泛的改进? 例如,将 MapReduce 作业重写为 Spark 作业,或将基于旧式 RDD 的代码转换为基于 DataFrame/Dataset 的代码。
- 您是否在全新构建一个大数据与高级分析平台(从零开始的项目)?
- 当前的痛点是什么? 例如,可伸缩性、性能或灵活性。
- 需要支持哪些新的业务要求?
- 你需要满足哪些 SLA 要求?
- 工作负载是什么? 例如,ETL、批处理、流处理、机器学习模型训练、分析、报告查询或交互式查询?
- 拥有项目的用户的技能是什么(是否应实施 POC)? 例如,PySpark 与 Scala 技能、笔记本与 IDE 经验。
下面是一些 POC 目标设定示例:
- 为何要执行 POC?
- 我们需要知道,大数据工作负载的数据引入和处理性能将满足新 SLA 的需求。
- 我们需要知道,接近实时的流处理是否可行,以及它可以支持多大的吞吐量。 (它是否会支持我们的业务需求?)
- 我们需要知道,现有的数据引入和转换流程是否合适,以及需要在哪些方面进行优化。
- 我们需要知道,是否可以缩短数据集成运行时间以及可以缩短多少时间。
- 我们需要知道,数据科学家是否可以根据需要在 Spark 池中构建和训练机器学习模型并利用 AI/ML 库。
- 迁移到基于云的 Synapse Analytics 能否达成成本目标?
- 在此 POC 的结论中:
- 我们将拿到数据,以确定是否可以同时满足批处理和实时流式传输的数据处理性能要求。
- 我们将测试支持用例的所有数据类型(结构化、半结构化和非结构化)的引入和处理。
- 我们将测试一些现有的复杂数据处理,并确定将数据集成组合迁移到新环境所需完成的工作。
- 我们将已经完成数据引入和处理的测试,并将拥有数据点来估计初始迁移及加载历史数据所需的工作量,同时估计迁移我们的数据引入(Azure Data Factory(ADF)、Distcp、Databox 或其他工具)所需的工作量。
- 我们将测试数据引入和处理,并确定是否能够满足 ETL/ELT 处理要求。
- 我们将获得见解,可以更好地估计完成实现项目所需的工作量。
- 我们将对规模和扩展选项进行测试,并将获得数据点,以便更好地配置我们的平台,实现优化性价比设置。
- 我们将获得可能需要进行更多测试的项列表。
计划项目
使用目标来确定特定的测试并提供确定的输出。 必须确保至少执行一项测试来支持每个目标和预期输出。 此外,确定特定的数据引入、批处理或流处理,以及将执行的所有其他流程,以便确定非常特定的数据集和代码库。 该特定数据集和代码库将定义 POC 的范围。
下面是规划中所需具体程度的示例:
- 目标 A:我们需要知道,根据定义的 SLA 是否可以满足对批数据引入和批数据处理的要求。
-
输出 A:我们将拿到数据,以确定批数据引入和处理是否能够满足数据处理要求和 SLA。
- 测试 A1:经确定,处理查询 A、B 和 C 是良好的性能测试,通常由数据工程团队执行。 此外,它们代表了整体数据处理需求。
- 测试 A2:经确定,处理查询 X、Y 和 Z 是良好的性能测试,包含近乎实时的流处理要求。 此外,它们代表了基于事件的整体流处理需求。
- 测试 A3:将这些查询在不同规模的 Spark 群集(不同数量的工作器节点、不同大小的工作器节点 (如小型、中型和大型)、不同数量和大小的执行器)中的性能与从现有系统获得的基准进行比较。 请牢记收益递减规律;添加更多资源(通过纵向扩展或横向扩展)有助于实现并行性,但每一个方案都有针对并行性实现的特有限制。 发现测试中每个已识别用例的最佳配置。
- 目标 B:我们需要知道,数据科学家能否在这个平台上构建和训练机器学习模型。
-
输出 B:我们将测试一些机器学习模型,方法是借助各种机器学习库使用 Spark 池或 SQL 池中的数据对其进行训练。 这些测试将有助于确定哪些机器学习模型可以迁移到新环境
- 测试 B1:将测试特定的机器学习模型。
- 测试 B2:测试 Spark 附带的基础机器学习库 (Spark MLLib) 以及可在 Spark 上安装的附加库(如 scikit-learn),以满足需求。
- 目标 C:我们将测试数据引入,并将具有数据点,以便:
- 估算将初始历史数据迁移到数据湖和/或 Spark 池所需完成的工作量。
- 规划历史数据迁移方法。
-
输出 C:我们将测试并确定环境中可实现的数据引入率,并确定数据引入率是否足以实现在可用时间窗内迁移历史数据。
- 测试 C1:测试各种历史数据迁移方法。 有关详细信息,请参阅 将数据传输到 Azure 和从 Azure 传输数据。
- 测试 C2:确定 ExpressRoute 的已分配带宽,以及基础结构团队是否设置了任何限制。 有关详细信息,请参阅 什么是Azure ExpressRoute?(带宽选项)。
- 测试 C3:测试在线和离线数据迁移的数据传输速率。 有关详细信息,请参阅 Copy activity 性能和可伸缩性指南。
-
测试 C4:使用 ADF、Polybase 或 COPY 命令测试从数据湖到 SQL 池的数据传输。 有关详细信息,请参阅
Azure Synapse Analytics0 中专用 SQL 池的数据加载策略。
- 目标 D:我们将测试增量数据加载的数据引入率,并使用数据点来估计数据湖和/或专用 SQL 池的数据引入和处理时间窗。
-
输出 D:我们将测试数据引入率,并确定已确定的方法是否可以满足数据引入和处理需求。
- 测试 D1:测试每日更新数据引入和处理。
- 测试 D2:测试从 Spark 池加载到专用 SQL 池表的已处理数据。 有关详细信息,请参阅适用于 Apache Spark 的 Azure Synapse专用 SQL 池连接器。
- 测试 D3:在运行最终用户查询的同时执行每日更新加载过程。
务必通过添加多个测试方案来优化测试。 Azure Synapse可以轻松测试不同的规模(不同数量的工作器节点、小型、中型和大型工作器节点的大小)来比较性能和行为。
以下是一些测试方案:
- Spark 池测试 A:我们将对多种节点类型(小型、中型和大型)以及不同数量的工作器节点执行数据处理。
- Spark 池测试 B:我们将使用连接器将处理过的数据从 Spark 池加载/检索到专用 SQL 池。
- Spark 池测试 C: 我们将使用 Azure Synapse Link 把数据从 Spark 池加载至 Azure Cosmos DB。
评估 POC 数据集
使用确定的特定测试,选择一个数据集来支持测试。 花些时间评审此数据集。 应该验证该数据集在内容、复杂性和规模方面是否能够充分代表将来的处理。 不要使用太小的数据集(小于 1TB),因为它不能提供有代表性的性能。 相反,也不要使用太大的数据集,因为 POC 不应该变为完整数据迁移。 请务必从现有系统获取适当的基准,以便可以使用它们进行性能比较。
重要
在将任何数据迁移到云之前,请确保与业务所有者核实是否有任何阻碍因素。 在将数据移动到云之前,确定应处理的任何安全或隐私问题或任何数据混淆需求。
创建高级体系结构
根据提议的未来状态体系结构的高级体系结构,确定构成 POC 的一部分的组件。 高级未来状态体系结构可能包含许多数据源、大量的数据使用者、大数据组件,以及机器学习和人工智能 (AI) 数据使用者。 POC 体系结构应明确确定 POC 的构成组件。 重要的是,它应该确定不构成 POC 测试的一部分的任何组件。
如果已在使用 Azure,请确定在 POC 期间可以使用的任何资源(Microsoft Entra ID、ExpressRoute 和其他资源)。 另请确定组织使用的Azure区域。 现在是确定 ExpressRoute 连接的吞吐量,并与其他业务用户核实你的 POC 是否消耗其中一部分吞吐量而不会对生产系统造成不利影响的好时机。
有关详细信息,请参阅大数据体系结构。
标识 POC 资源
明确确定支持 POC 所需的技术资源和时间承诺。 POC 将需要:
- 一名业务代表,负责监督要求和结果。
- 一名应用程序数据专家,负责 POC 数据溯源,并提供现有流程和逻辑的知识。
- Apache Spark 和 Spark 池专家。
- 一名专家顾问,负责优化 POC 测试。
- POC 项目的特定组件需要的资源,但不一定需要在 POC 期间使用。 这些资源可能包括网络管理员、Azure管理员、Active Directory管理员、Azure门户管理员和其他资源。
- 确保预配所有必需的Azure服务资源,并授予所需的访问权限级别,包括对存储帐户的访问权限。
- 确保帐户拥有从 POC 范围内的所有数据源检索数据所需的数据访问权限。
提示
建议聘请专家顾问来协助进行 POC。 Microsoft的合作伙伴社区在全球范围内拥有可帮助您评估、评价或实施Azure Synapse的专家顾问。
设置时间线
审查您的 POC 计划详细信息和业务需求,以确定 POC 的时间框架。 对完成 POC 目标所需的时间进行实际的估算。 完成 POC 所需的时间受 POC 数据集大小、测试的数量和复杂性以及要测试的接口数量的影响。 如果你估计 POC 的运行时间超过四周,请考虑缩小 POC 范围,以便注重于优先级最高的目标。 在继续之前,请务必获得所有资源主管和发起人的批准和承诺。
将 POC 付诸实施
我们建议遵循任何生产项目的纪律和严谨性来执行 POC 项目。 根据计划运行项目并管理更改请求流程,以防 POC 范围不受控制地扩大。
下面是一些高级任务的示例:
创建 Synapse 工作区、Spark 池和专用 SQL 池、存储帐户以及 POC 计划中标识的所有Azure资源。
加载 POC 数据集:
- 通过从源提取或通过在Azure中创建示例数据,在Azure中提供数据。 有关详细信息,请参阅。
- 测试 Spark 池和专用 SQL 池的专用连接器。
将现有代码迁移到 Spark 池:
- 如果从 Spark 迁移,则迁移工作可能非常简单,因为 Spark 池利用的是开源 Spark 发行版。 但是,如果在核心 Spark 功能的基础上使用特定于供应商的功能,则需要将这些功能正确映射到 Spark 池功能。
- 如果从非 Spark 系统迁移,则迁移工作将根据所涉及的复杂性而有所不同。
执行测试:
- 许多测试可以跨多个 Spark 池群集并行执行。
- 以易于使用和理解的格式记录结果。
监控故障排除和性能表现。 有关详细信息,请参阅:
通过打开 Spark 历史记录服务器的“诊断”选项卡,来监视数据倾斜、时间倾斜和执行程序使用率百分比。
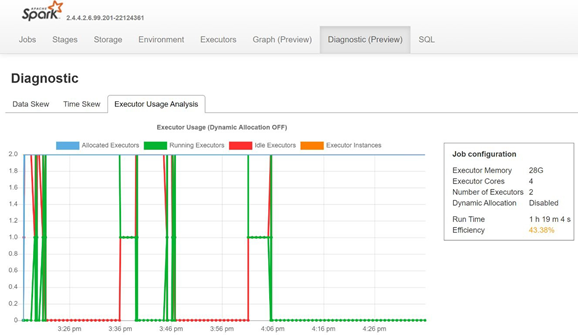
解释概念验证(POC)结果
完成所有 POC 测试后,将对结果进行评估。 首先评估是否满足 POC 目标,并收集了所需的输出。 确定是否需要进行更多测试或者是否有任何问题需要解决。
后续步骤
Azure Synapse Analytics 中使用无服务器 SQL 池探索数据湖