适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
有时,你需要执行从数据湖或企业数据仓库 (EDW) 到 Azure 的大规模数据迁移。 其他时候,你需要将来自不同源的大量数据引入 Azure 来进行大数据分析。 在每个情况下,实现最佳性能和可伸缩性至关重要。
Azure 数据工厂和 Azure Synapse Analytics 管道提供了一种引入数据的机制,这种机制具有以下优势:
- 处理大量数据
- 具有高性能
- 具有成本效益
这些优势非常适合于想要构建高性能的可伸缩数据引入管道的数据工程师。
阅读本文之后,能够回答以下问题:
- 将复制活动用于数据迁移和数据引入方案时,可以实现什么级别的性能和可扩展性?
- 应执行哪些步骤来优化复制活动的性能?
- 单次复制活动运行可以采用哪些性能优化?
- 优化复制性能时需要考虑哪些其他外部因素?
注意
如果你对常规复制活动不熟悉,在阅读本文前请参阅复制活动概述。
使用 Azure 数据工厂和 Synapse 管道可实现的复制性能和可扩展性
Azure 数据工厂和 Synapse 管道提供无服务器体系结构,可以实现不同级别的并行性。
通过此体系结构,可开发能最大程度地提高环境数据移动吞吐量的管道。 这些管道充分利用以下资源:
- 源数据存储与目标数据存储之间的网络带宽
- 源或目标数据存储的每秒输入/输出操作数 (IOPS) 和带宽
这种充分利用意味着你可通过测量以下资源可用的最小吞吐量来估计总体吞吐量:
- 源数据存储
- 目标数据存储
- 源数据存储与目标数据存储之间的网络带宽
下表显示了数据移动持续时间的计算。 根据给定的网络和数据存储带宽以及给定的数据有效负载大小来计算每个单元中的持续时间。
注意
下面提供的持续时间旨在表示端到端数据集成解决方案中可实现的性能,方法是使用复制性能优化功能中描述的一种或多种性能优化技术,包括使用 ForEach 对多个并发复制活动进行分区和生成。 建议执行性能优化步骤中列出的步骤,以优化特定数据集和系统配置的复制性能。 应将性能优化测试中获取的数字用于生产部署计划、容量计划和计费计划。
| 数据大小/ 带宽 |
50 Mbps | 100 Mbps | 500 Mbps | 1 Gbps | 5 Gbps | 10 Gbps | 50 Gbps |
|---|---|---|---|---|---|---|---|
| 1 GB | 2.7 分钟 | 1.4 分钟 | 0.3 分钟 | 0.1 分钟 | 0.03 分钟 | 0.01 分钟 | 0.0 分钟 |
| 10 GB | 27.3 分钟 | 13.7 分钟 | 2.7 分钟 | 1.3 分钟 | 0.3 分钟 | 0.1 分钟 | 0.03 分钟 |
| 100 GB | 4.6 小时 | 2.3 小时 | 0.5 小时 | 0.2 小时 | 0.05 小时 | 0.02 小时 | 0.0 小时 |
| 1 TB | 46.6 小时 | 23.3 小时 | 4.7 小时 | 2.3 小时 | 0.5 小时 | 0.2 小时 | 0.05 小时 |
| 10 TB | 19.4 天 | 9.7 天 | 1.9 天 | 0.9 天 | 0.2 天 | 0.1 天 | 0.02 天 |
| 100 TB | 194.2 天 | 97.1 天 | 19.4 天 | 9.7 天 | 1.9 天 | 1 天 | 0.2 天 |
| 1 PB | 64.7 个月 | 32.4 个月 | 6.5 个月 | 3.2 个月 | 0.6 个月 | 0.3 个月 | 0.06 个月 |
| 10 PB | 647.3 个月 | 323.6 个月 | 64.7 个月 | 31.6 个月 | 6.5 个月 | 3.2 个月 | 0.6 个月 |
副本可在不同层级进行扩展:
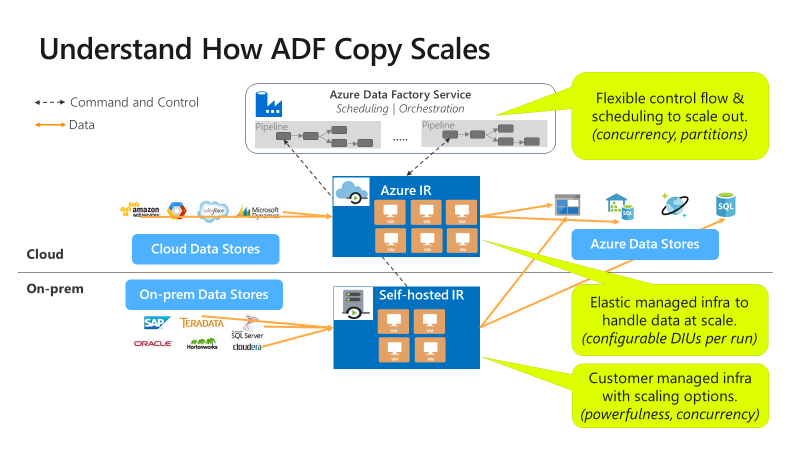
控制流可以并行启动多个复制活动(例如,使用 For Each 循环)。
单个复制活动可以利用可缩放的计算资源。
- 使用 Azure 集成运行时 (IR) 时,能够以无服务器的方式为每个复制活动指定最多 256 个数据集成单元 (DIU)。
- 使用自承载 IR 时,可采用以下方法之一:
- 手动纵向扩展计算机。
- 横向扩展到多台计算机(最多 4 个节点),单个复制活动将跨所有节点对其文件集进行分区。
单个复制活动使用多个线程并行读取和写入数据存储。
性能优化步骤
请执行以下步骤,通过复制活动优化服务的性能:
选取测试数据集并建立基线。
在开发过程中,使用复制活动针对具有代表性的数据样本测试管道。 你选择的数据集应表示典型的数据模式,并具有以下属性:
- 文件夹结构
- 文件模式
- 数据架构
数据集应该足够大,可以评估复制性能。 合适的数据量应使复制活动至少需要 10 分钟才能完成。 在复制活动监控之后收集执行详情和性能特征。
如何最大化单个复制活动的性能:
建议先使用单个复制活动来最大程度提高性能。
如果复制活动在 Azure 集成运行时中执行:
一开始对数据集成单位 (DIU) 和并行复制设置使用默认值。
如果复制活动在自承载集成运行时中执行:
建议使用专用计算机托管 IR。 计算机应与托管数据存储的服务器分开。 先使用默认的并行复制设置,并为自承载 IR 使用单个节点。
进行一次性能测试运行。 记下达到的性能表现。 包括使用的实际值,例如 DIU 和并行副本。 有关如何收集运行结果和所用性能设置,请参阅复制活动监视。 了解如何排查复制活动的性能问题,以识别和解决瓶颈。
根据故障排除和优化指南,迭代进行更多次性能测试的执行。 单个复制活动运行无法实现更高的吞吐量后,请考虑是否通过同时运行多个副本来最大化聚合吞吐量。 下一编号项目中讨论了此选项。
如何通过并行运行多项复制来最大化聚合吞吐量:
至此,你已将单个复制活动的性能最大化。 如果尚未达到环境的吞吐量上限,则可以并行运行多个复制活动。 可使用控制流构造并行运行。 其中一种结构是 For Each 循环。 有关详细信息,请参阅以下关于解决方案模板的文章:
将配置扩展至整个数据集。
对执行结果和性能满意时,可以扩展定义和管道以覆盖整个数据集。
排查复制活动的性能问题
遵循性能优化步骤为方案规划并执行性能测试。 并且通过复制活动性能故障排除来了解如何排除每个复制活动运行的性能问题。
复制性能优化功能
此服务提供以下性能优化功能:
数据集成单元
数据集成单元 (DIU) 是一个度量值,表示单个单位在 Azure 数据工厂和 Synapse 管道中的能力。 性能是 CPU、内存和网络资源分配的组合。 DIU 仅适用于 Azure 集成运行时。 DIU 不适用于 自承载集成运行时。 在此处了解更多信息。
自承载集成运行时扩展能力
你可能希望托管不断增长的并发工作负载。 或者,你可能希望在当前工作负载级别获得更高的性能。 可通过以下方法提高处理规模:
- 可通过增加节点上可运行的并发作业数量,对自承载 IR 进行纵向扩展。
仅当节点的处理器和内存没有得到充分利用时,才能进行纵向扩展。 - 可以通过添加更多节点(计算机)来横向扩展自承载 IR。
有关详细信息,请参阅:
并行复制
可设置 parallelCopies 属性来指示希望复制活动使用的并行度。 将此属性视为复制活动中的最大线程数。 线程并行操作。 线程从源读取,或写入接收器数据存储。
了解详细信息。
已暂存的副本
数据复制操作可将数据直接发送到接收器数据存储。 或者,你也可以选择将 Blob 存储用作中间暂存存储。 了解详细信息。
相关内容
请参阅其他有关复制活动的文章: