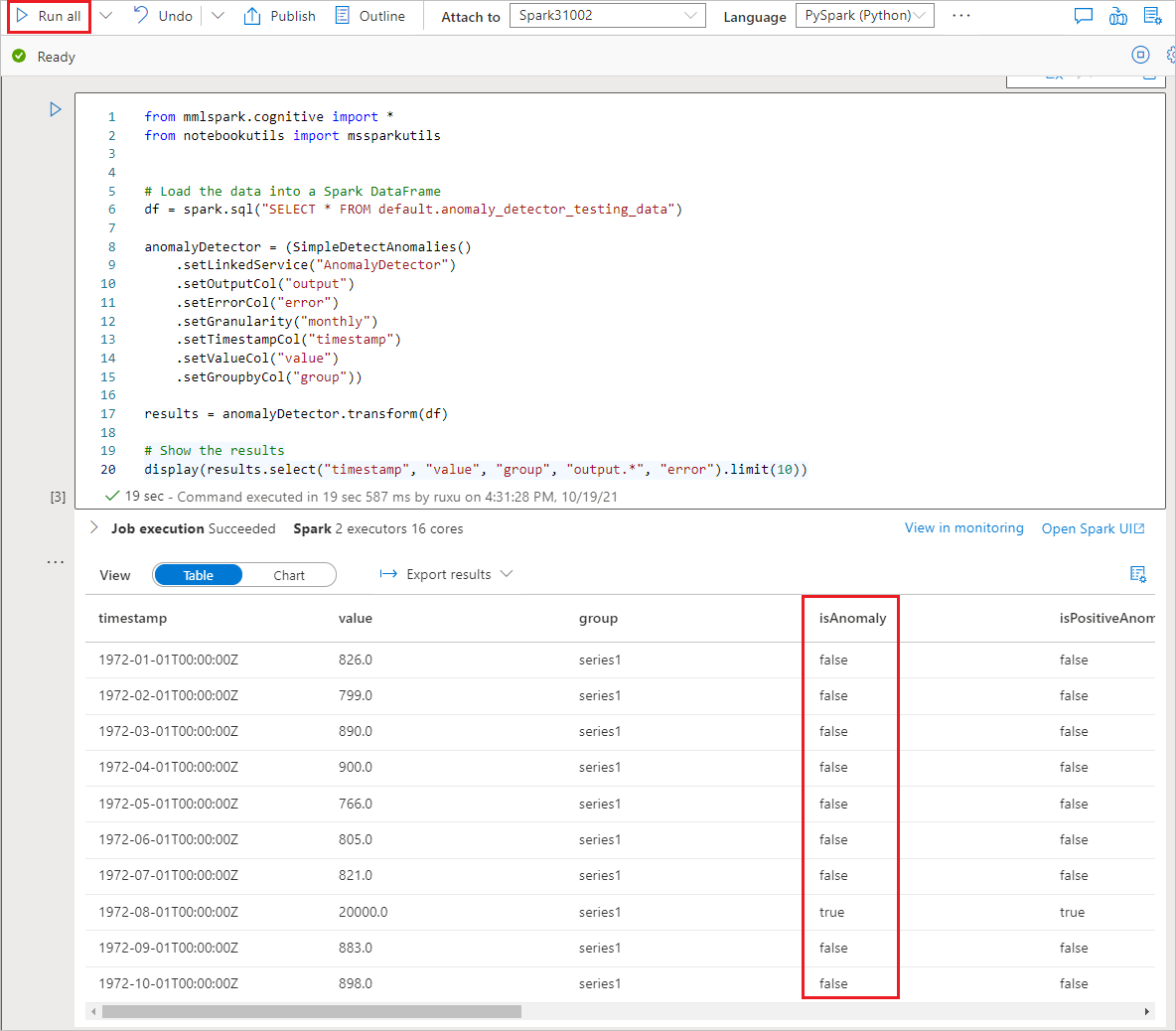
本教程介绍如何使用
本教程涉及:
- 获取包含时序数据的 Spark 表数据集的步骤。
- 使用 Azure Synapse 中的向导式体验,通过异常检测器用于丰富数据。
如果没有Azure订阅,开始前创建试用帐户。
先决条件
- Azure Synapse Analytics 工作区,配置为默认存储的一个 Azure Data Lake Storage Gen2 存储帐户。 你需要成为你所使用的 Data Lake Storage Gen2 文件系统的 Storage Blob 数据参与者。
- Azure Synapse Analytics 工作区中的 Spark 池。 有关详细信息,请参阅
在 Azure Synapse 。 - 完成 在 Azure Synapse 中配置 Foundry 工具 教程中的配置前步骤。
登录到Azure portal
登录到 Azure portal。
创建 Spark 表
本教程需要一个 Spark 表。
创建 PySpark 笔记本并运行以下代码。
from pyspark.sql.functions import lit
df = spark.createDataFrame([
("1972-01-01T00:00:00Z", 826.0),
("1972-02-01T00:00:00Z", 799.0),
("1972-03-01T00:00:00Z", 890.0),
("1972-04-01T00:00:00Z", 900.0),
("1972-05-01T00:00:00Z", 766.0),
("1972-06-01T00:00:00Z", 805.0),
("1972-07-01T00:00:00Z", 821.0),
("1972-08-01T00:00:00Z", 20000.0),
("1972-09-01T00:00:00Z", 883.0),
("1972-10-01T00:00:00Z", 898.0),
("1972-11-01T00:00:00Z", 957.0),
("1972-12-01T00:00:00Z", 924.0),
("1973-01-01T00:00:00Z", 881.0),
("1973-02-01T00:00:00Z", 837.0),
("1973-03-01T00:00:00Z", 9000.0)
], ["timestamp", "value"]).withColumn("group", lit("series1"))
df.write.mode("overwrite").saveAsTable("anomaly_detector_testing_data")
现在,默认的 Spark 数据库中应显示名为 anomaly_detector_testing_data 的 Spark 表。
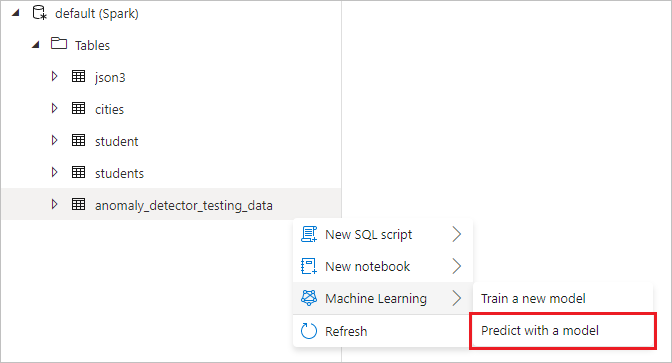
打开 Foundry 工具向导
右键单击在上一步中创建的 Spark 表。 选择Machine Learning>使用模型进行预测以打开向导。
此时会显示配置面板,你需要选择一个预训练模型。 选择 Anomaly Detector。
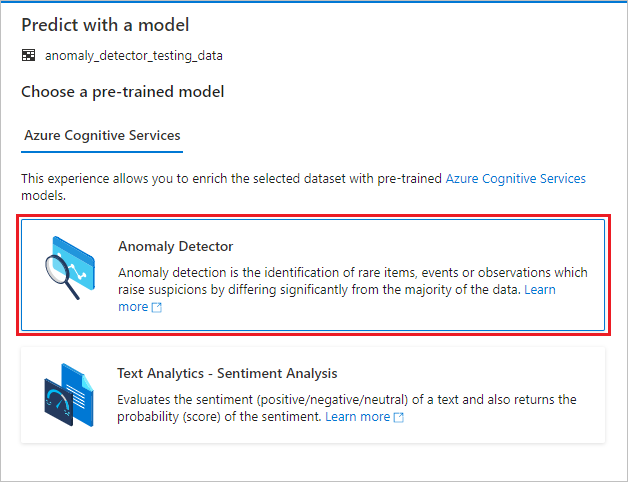
配置异常检测器
提供以下详细信息以配置异常检测器:
Azure 认知服务链接服务:作为先决条件步骤的一部分,你创建了一个链接到 Microsoft Foundry 工具的链接服务。 请在这里选择该服务。
粒度:采样数据的速率。 选择“每月一次”。
时间戳列:表示时序的列。 选择时间戳(字符串)。
时序值列:表示“时间戳”列所指定时间所对应序列值的列。 选择“值 (double)”。
分组列:对系列进行分组的列。 也就是说,在此列中具有相同值的所有行应形成一个时序。 选择组(字符串)。
完成后,选择“打开笔记本”。 这将使用 PySpark 代码生成笔记本,该代码使用 Foundry 工具检测异常。
截图显示异常检测器的配置详细信息。
运行笔记本
刚刚打开的笔记本使用 SynapseML 库连接到 Foundry Tools。 你提供的 Foundry 工具链接服务允许你从此体验中安全地引用 Foundry 工具,而无需透露任何机密。
现在,您可以运行所有单元格以执行异常检测。 选择“全部运行”。 在 Foundry Tools 中了解有关Anomaly Detector的详细信息。