了解如何使用预测机器学习模型轻松扩充专用 SQL 池中的数据。 数据科学家创建的模型现在可供数据专业人员轻松访问,以便进行预测分析。 Azure Synapse Analytics 中的数据专业人员只需从 Azure 机器学习模型注册表中选择模型即可在 Azure Synapse SQL 池中部署,并启动预测来扩充数据。
本教程介绍以下操作:
- 训练一个预测性机器学习模型并在 Azure 机器学习模型注册表中注册该模型。
- 使用 SQL 评分向导在专用 SQL 池中启动预测。
如果没有 Azure 订阅,可在开始前创建一个试用帐户。
先决条件
- Azure Synapse Analytics 工作区,其中 Azure Data Lake Storage Gen2 存储帐户配置为默认存储。 你需要成为所使用的 Data Lake Storage Gen2 文件系统的存储 Blob 数据参与者。
- Azure Synapse Analytics 工作区中的专用 SQL 池。 有关详细信息,请参阅 创建专用 SQL 池。
- Azure Synapse Analytics 工作区中的 Azure 机器学习链接服务。 有关详细信息,请参阅 在 Azure Synapse 中创建 Azure 机器学习链接服务。
登录到 Azure 门户
登录到 Azure 门户。
在 Azure 机器学习中训练模型
在开始之前,请验证 sklearn 版本是否为 0.20.3。
在笔记本中运行所有单元格之前,请检查计算实例是否正在运行。
转到你的 Azure 机器学习工作区。
转到 笔记本>上传文件。 然后选择下载并上传的 Predict NYC Taxi Tips.ipynb 文件。
上传并打开笔记本后,选择“ 运行所有单元格”。
其中一个单元格可能会失败,并要求你向 Azure 进行身份验证。 请在单元格输出中注意此信息,在浏览器中使用以下链接并输入代码进行身份验证。 然后重新运行笔记本。
笔记本将训练 ONNX 模型并将其注册到 MLflow。 转到 “模型 ”,检查新模型是否已正确注册。
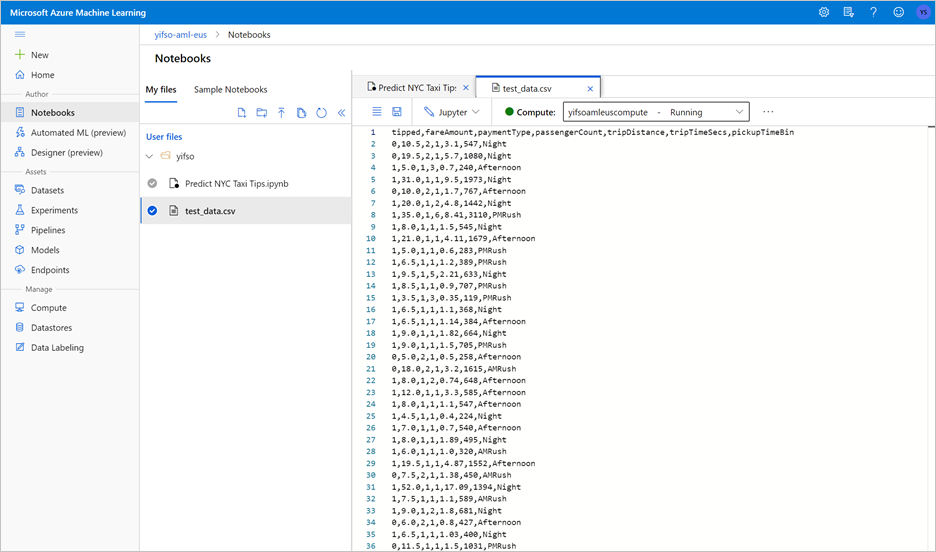
运行笔记本还将测试数据导出到 CSV 文件中。 将 CSV 文件下载到本地系统。 稍后,你将将 CSV 文件导入专用 SQL 池,并使用数据测试模型。
CSV 文件是在笔记本文件所在的同一文件夹中创建的。 如果在文件资源管理器中没有立即看到它,请选择刷新。
使用 SQL 评分向导启动预测
使用 Synapse Studio 打开 Azure Synapse 工作区。
转到 数据>关联>存储帐户。 将文件上传到
test_data.csv默认存储帐户。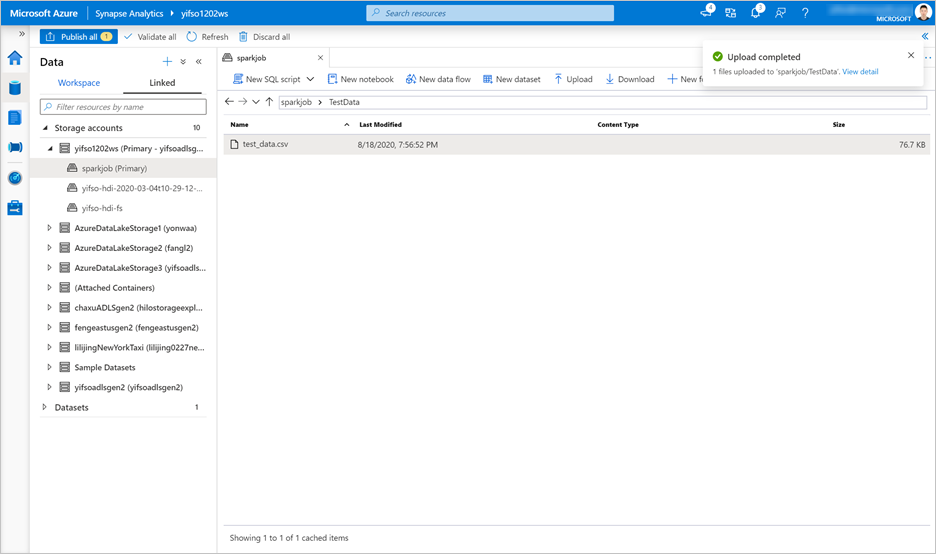
转到 “开发>SQL 脚本”。 创建新的 SQL 脚本以加载
test_data.csv到专用 SQL 池中。注释
在运行此脚本之前,请更新其中的文件 URL。
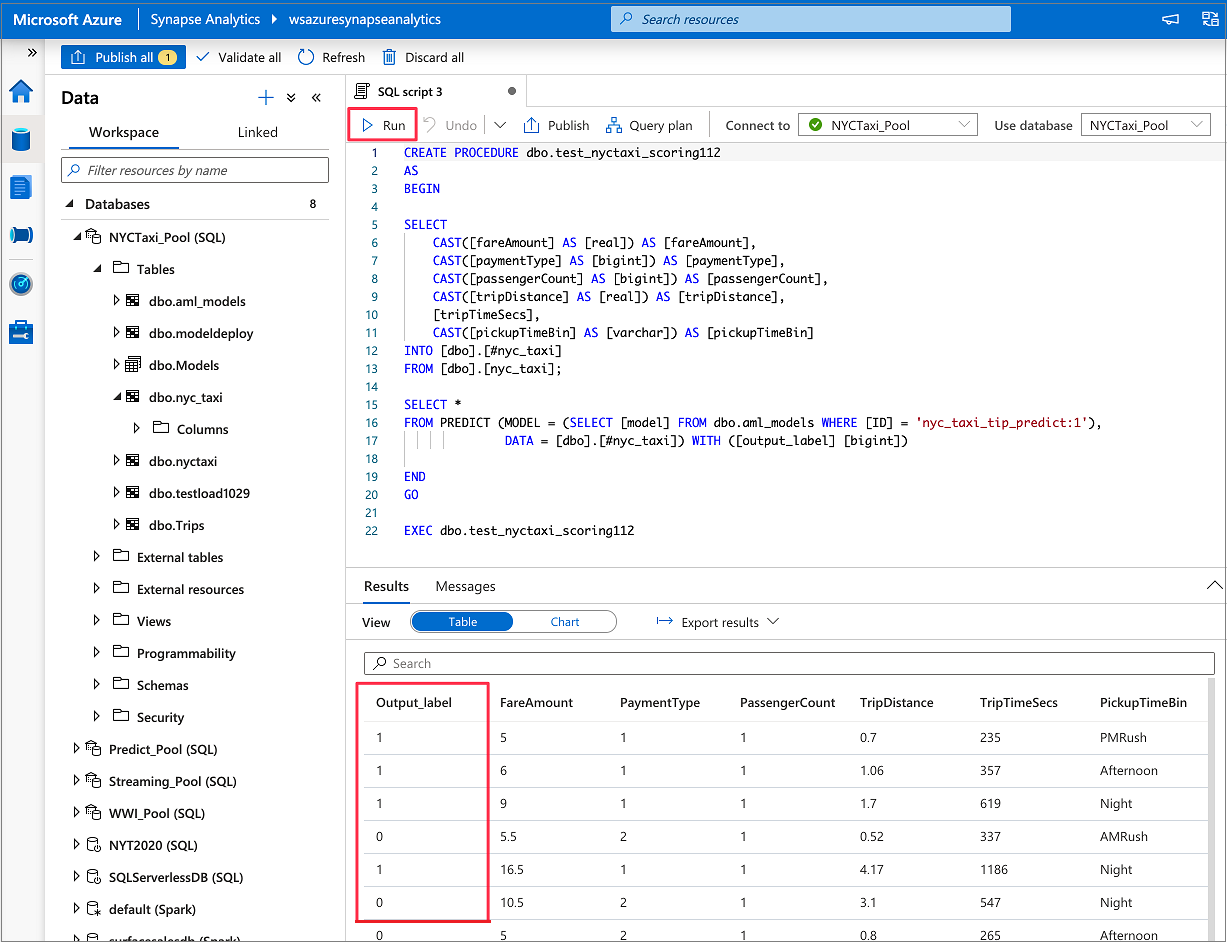
IF NOT EXISTS (SELECT * FROM sys.objects WHERE NAME = 'nyc_taxi' AND TYPE = 'U') CREATE TABLE dbo.nyc_taxi ( tipped int, fareAmount float, paymentType int, passengerCount int, tripDistance float, tripTimeSecs bigint, pickupTimeBin nvarchar(30) ) WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED COLUMNSTORE INDEX ) GO COPY INTO dbo.nyc_taxi (tipped 1, fareAmount 2, paymentType 3, passengerCount 4, tripDistance 5, tripTimeSecs 6, pickupTimeBin 7) FROM '<URL to linked storage account>/test_data.csv' WITH ( FILE_TYPE = 'CSV', ROWTERMINATOR='0x0A', FIELDQUOTE = '"', FIELDTERMINATOR = ',', FIRSTROW = 2 ) GO SELECT TOP 100 * FROM nyc_taxi GO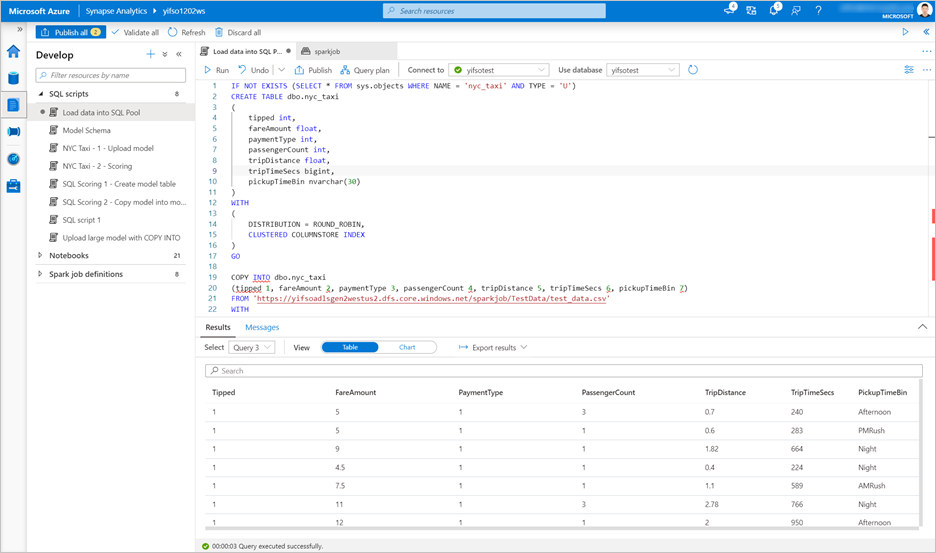
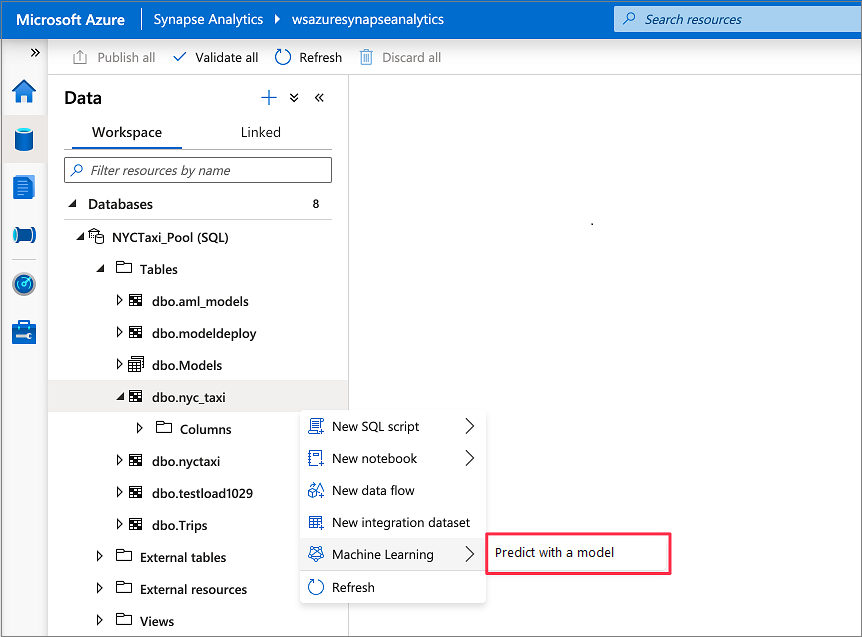
转到 数据>工作区。 右键单击专用 SQL 池表,打开 SQL 评分向导。 选择机器学习>使用模型进行预测。
注释
除非已为 Azure 机器学习创建链接服务,否则不会显示机器学习选项。 (请参阅本教程开头的 先决条件 。
在下拉列表中选择链接的 Azure 机器学习工作区。 此步骤从所选 Azure 机器学习工作区的模型注册表加载机器学习模型列表。 目前仅支持 ONNX 模型,因此此步骤仅显示 ONNX 模型。
选择刚刚训练的模型,然后选择“ 继续”。
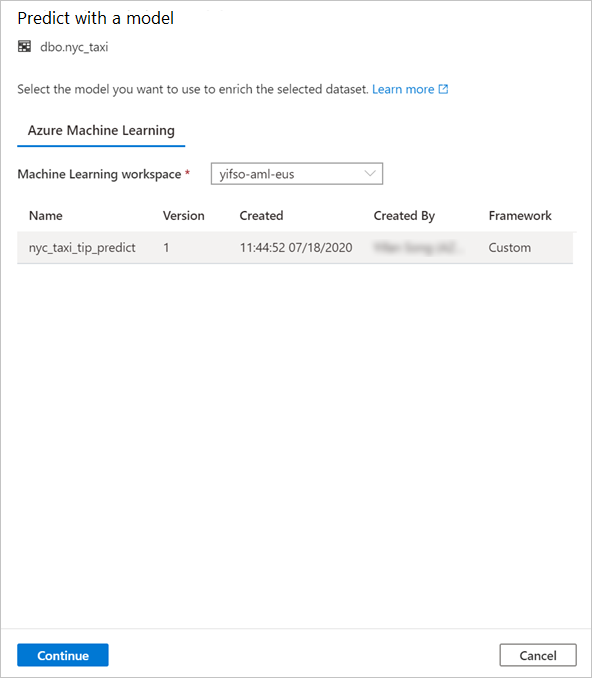
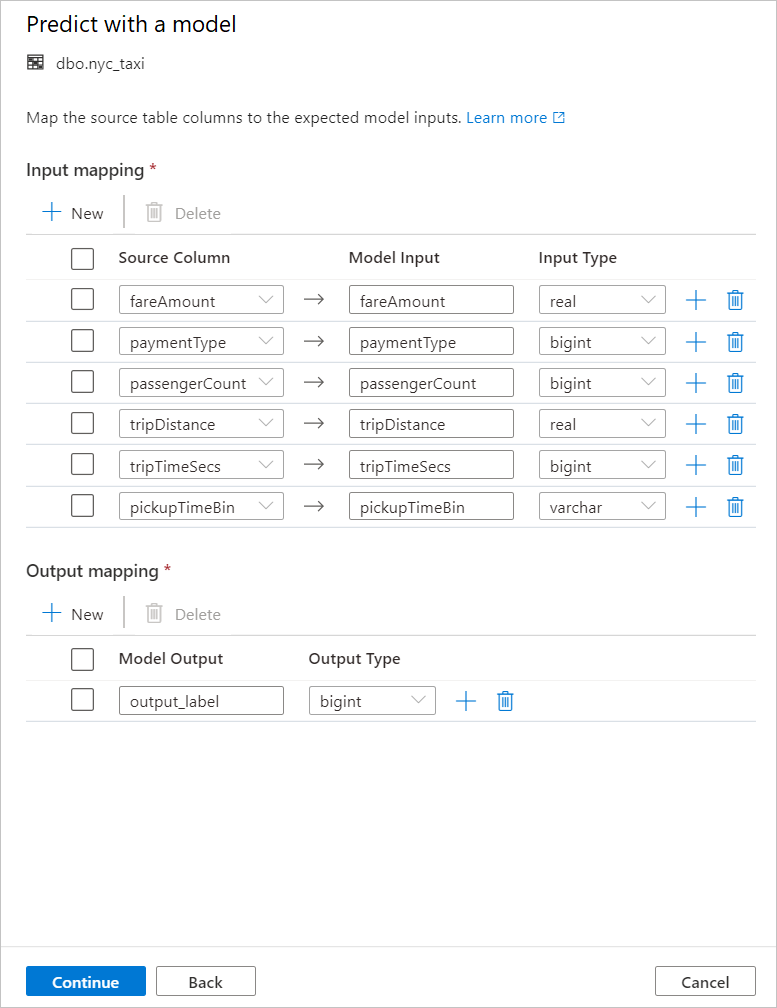
将表列映射到模型输入并指定模型输出。 如果模型是以 MLflow 格式保存的并且模型签名已进行填充,则系统会使用基于名称相似性的逻辑为你自动执行映射。 该接口还支持手动映射。
选择继续。
生成的 T-SQL 代码封装在存储过程内。 这就是为什么需要提供存储过程名称的原因。 模型二进制文件(包括元数据(版本、说明和其他信息)将从 Azure 机器学习物理复制到专用 SQL 池表。 因此,需要指定要在其中保存模型的表。
可以选择 现有表 或 新建表。 完成后,选择“ 部署模型 + 打开脚本 ”以部署模型并生成 T-SQL 预测脚本。
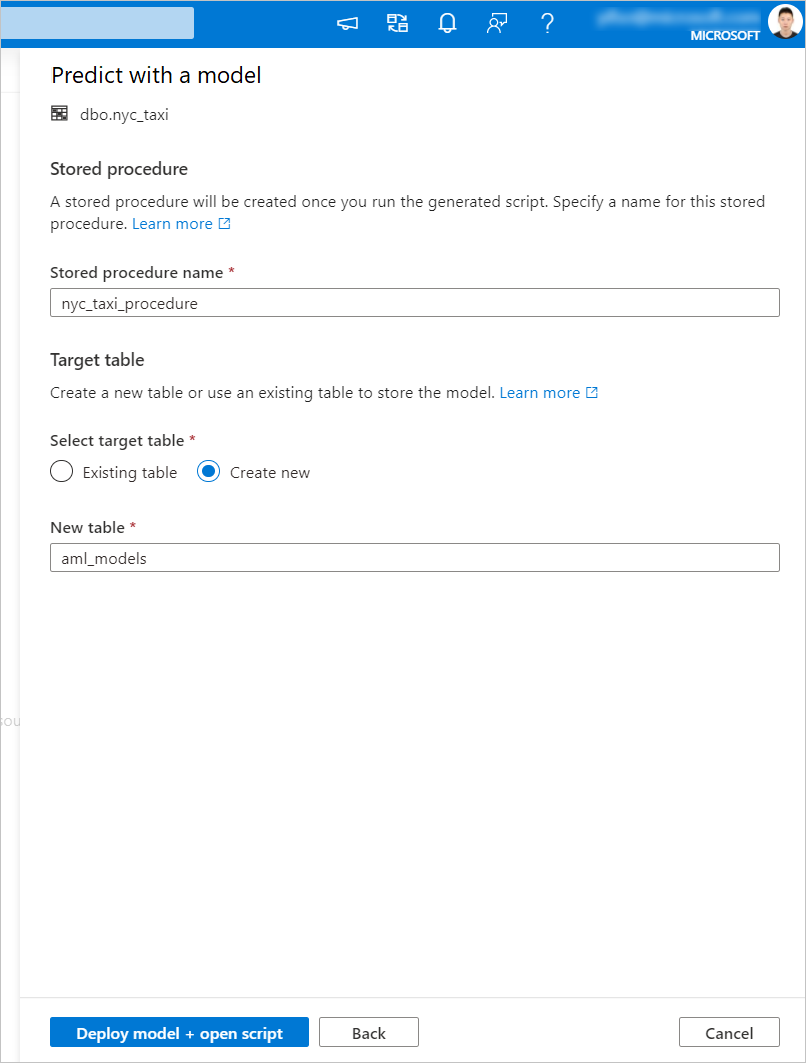
生成脚本后,选择 “运行 ”以执行评分并获取预测。