本部分介绍了如何创建和使用视图,以便包装无服务器 SQL 池查询。 可以通过视图重复使用这些查询。 如果希望将 Power BI 之类的工具与无服务器 SQL 池结合使用,也需使用视图。
先决条件
第一步是创建一个数据库,将在该数据库中创建视图,并通过对该数据库执行安装脚本来初始化在 Azure 存储上进行身份验证所需的对象。 本文中的所有查询将在示例数据库上执行。
基于外部数据的视图
可以采用与创建常规 SQL Server 视图相同的方式来创建视图。 下面的查询创建一个视图,该视图读取 population.csv 文件。
注意
更改查询中的第一行(即 [mydbname]),以便使用你创建的数据库。
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
该视图将 EXTERNAL DATA SOURCE 与你的存储的根 URL 一起用作 DATA_SOURCE,并添加文件的相对文件路径。
Delta Lake 视图
如果要基于 Delta Lake 文件夹创建视图,则需要在 BULK 选项后指定根文件夹的位置,而不是指定文件路径。
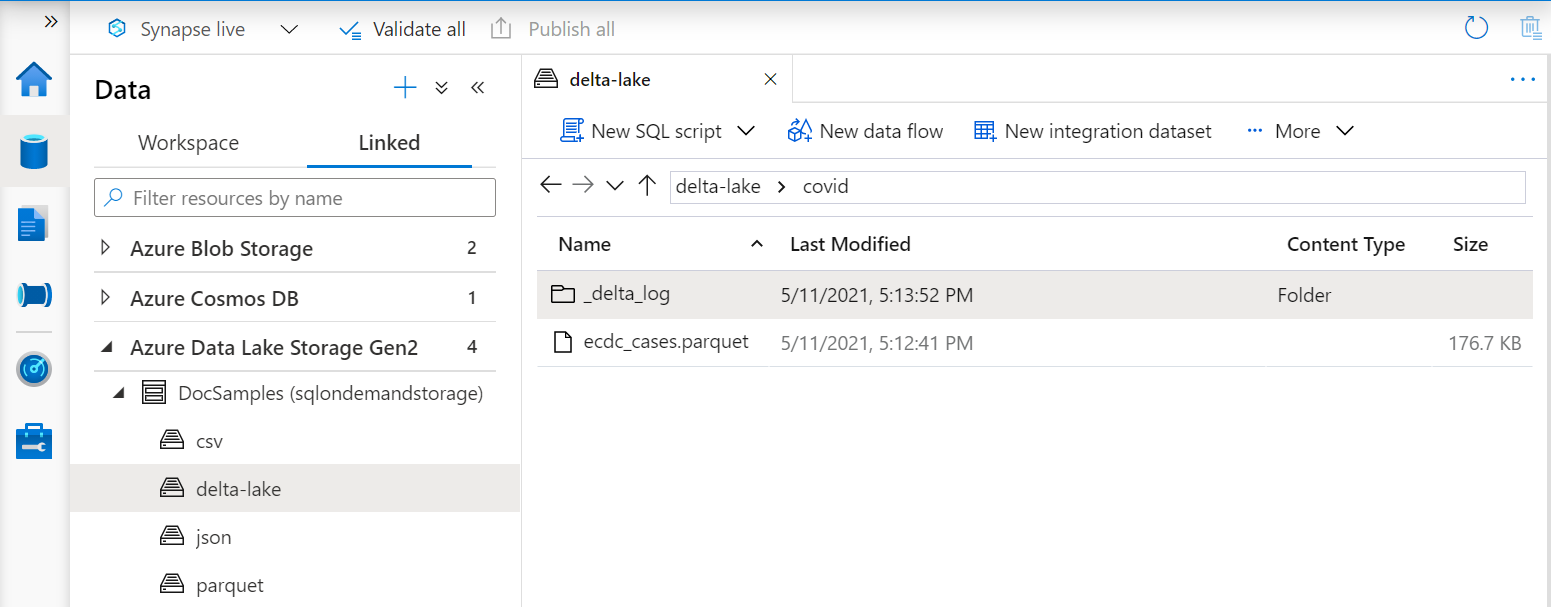
从 Delta Lake 文件夹读取数据的 OPENROWSET 函数会检查文件夹结构并自动识别文件位置。
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
有关详细信息,请查看 Synapse 无服务器 SQL 池自助页和 Azure Synapse Analytics 已知问题。
分区视图
如果你有一组在分层文件夹结构中分区的文件,则可以在文件路径中使用通配符来描述分区模式。 使用 FILEPATH 函数可以将文件夹路径的一部分公开为分区列。
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
使用分区列上的筛选器查询时,分区视图可以通过分区消除来提高查询性能。 但并非所有查询都支持分区消除,因此请务必遵循某些最佳做法。
若要确保分区消除,请避免在筛选器中使用子查询,因为它们可能会干扰消除分区的能力。 而是将子查询的结果以变量的形式传递给筛选器。
在 SQL 查询中使用 JOIN 时,请将筛选器谓词声明为 NVARCHAR,以降低查询计划的复杂性并提高正确消除分区的概率。 分区列通常被推断为 NVARCHAR(1024),因此对谓词使用相同类型可避免隐式强制转换的需要,而隐式强制转换会增加查询计划的复杂性。
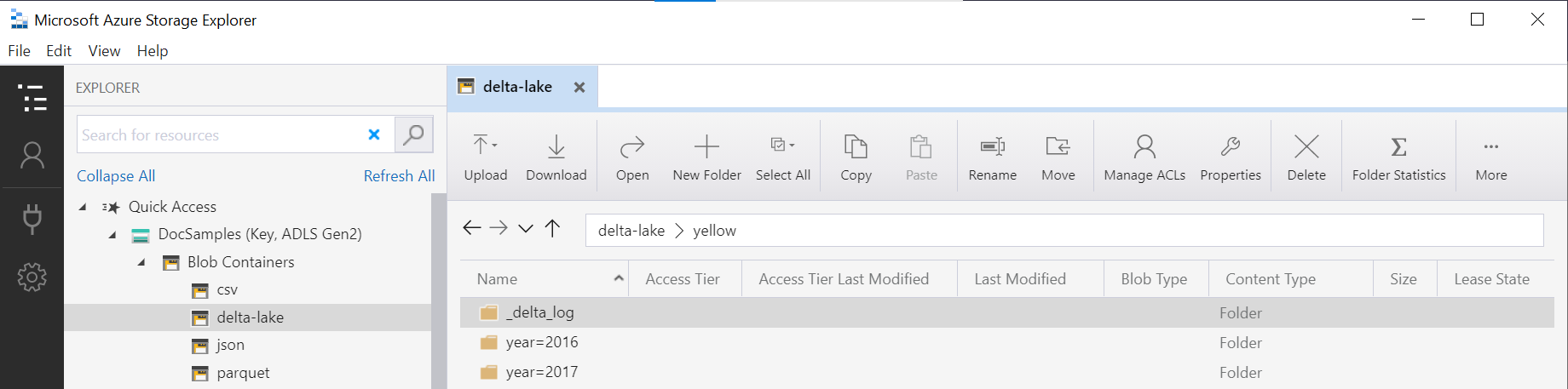
Delta Lake 分区视图
如果要基于 Delta Lake 存储创建分区的视图,则可以仅指定一个根 Delta Lake 文件夹,而无需使用 FILEPATH 函数显式公开分区列:
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
OPENROWSET 函数会检查底层 Delta Lake 文件夹的结构,自动标识并公开分区列。 如果将分区列放在查询的 WHERE 子句中,则会自动执行分区排除操作。
OPENROWSET 函数中的、与 yellow 数据源中定义的 LOCATION URI 连接的文件夹名称(在本示例中为 DeltaLakeStorage),必须引用包含名为 _delta_log 的子文件夹的 Delta Lake 根文件夹。
有关详细信息,请查看 Synapse 无服务器 SQL 池自助页和 Azure Synapse Analytics 已知问题。
JSON 视图
如果需要在从文件提取的结果集的基础上进行一些额外的处理,则视图是不错的选择。 例如分析 JSON 文件,我们需要应用 JSON 函数以从 JSON 文档中提取值:
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
OPENJSON 函数分析 JSONL 文件的每一行,该文件每行包含一个文本格式的 JSON 文档。
Azure Cosmos DB 容器视图
如果在容器上启用了 Azure Cosmos DB 分析存储,则可以在 Azure Cosmos DB 容器之上创建视图。 Azure Cosmos DB 帐户名称、数据库名称和容器名称应添加到视图中,并且只读访问密钥应放置在视图引用的数据库范围凭据中。
此示例脚本使用数据库和容器,你可以按照这些说明对该数据库和容器进行设置。
重要
在脚本中,将以下值替换为你自己的值:
- your-cosmosdb - Cosmos DB 帐户的名称
- access-key - Cosmos DB 帐户密钥
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
有关详细信息,请参阅在 Azure Synapse Link 中使用无服务器 SQL 池查询 Azure Cosmos DB 数据。
使用视图
可以在查询中使用视图,其方式与在 SQL Server 查询中使用视图的方式相同。
以下查询演示了如何使用在创建视图中创建的 population_csv 视图。 它按降序返回国家/地区名称及其 2019 年的人口。
注意
更改查询中的第一行(即 [mydbname]),以便使用你创建的数据库。
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
查询视图时,可能会遇到错误或意外结果。 这可能意味着该视图引用了已修改或不再存在的列或对象。 需要手动调整视图定义,以便与基础架构更改保持一致。
相关内容
若要了解如何查询不同的文件类型,请参阅以下文章:查询单个 CSV 文件、查询 Parquet 文件和查询 JSON 文件。