本文介绍如何估算和管理 Azure Synapse Analytics 中的无服务器 SQL 池的成本:
- 在发出查询之前估计处理的数据量
- 使用成本控制功能设置预算
了解Azure Synapse Analytics中无服务器 SQL 池的成本只是Azure帐单中每月成本的一部分。 如果使用其他Azure服务,则需针对Azure订阅中使用的所有Azure服务和资源(包括第三方服务)计费。 本文介绍如何在 Azure Synapse Analytics 中规划和管理无服务器 SQL 池的成本。
已处理的数据
处理的数据 量是运行查询时系统临时存储的数据量。 处理的数据包括以下数量:
- 从存储中读取的数据量。 此金额包括:
- 读取数据时读取的数据。
- 读取元数据时读取的数据(适用于包含元数据的文件格式,例如 Parquet)。
- 中间结果中的数据量。 查询运行时,此数据在节点之间传输。 它包括以未压缩格式将数据传输到终结点。
- 写入存储的数据量。 如果使用 CETAS 将结果集导出到存储,则将写入的数据量添加到 CETAS 的 SELECT 部分处理的数据量。
从存储读取文件的流程经过高度优化。 该过程使用:
- 预提取,这可能会给读取的数据量增加一些开销。 如果查询读取整个文件,则不会有开销。 如果文件是部分读取的,就像在 TOP N 查询中一样,则使用预提取来读取更多数据。
- 优化的逗号分隔值(CSV)分析器。 如果使用 PARSER_VERSION='2.0' 读取 CSV 文件,则从存储中读取的数据量会略有增加。 优化的 CSV 分析程序以相同大小的区块并行读取文件。 区块不一定包含整行。 为了确保分析所有行,优化的 CSV 分析器还会读取相邻区块的小片段。 此过程会增加少量的开销。
统计信息
无服务器 SQL 池查询优化器依赖于统计信息来生成最佳的查询执行计划。 可以手动创建统计信息。 否则,无服务器 SQL 池会自动创建它们。 无论哪种方式,统计信息都是通过运行单独的查询来创建的,该查询以提供的采样率返回特定列。 该查询有一个关联的处理数据量。
如果您运行的是相同的查询或其他能够从已创建的统计信息中受益的查询,那么如果可能,将重复使用这些统计信息。 不会处理用于创建统计信息的其他数据。
如果为 Parquet 列创建了统计信息,则仅从文件中读取相关列。 为 CSV 列创建统计信息时,将读取和分析整个文件。
舍入
每个查询的处理数据量会向上舍入为最接近的 MB。 每个查询至少处理 10 MB 的数据。
处理的数据不包括的内容
- 服务器级元数据(如登录名、角色和服务器级凭据)。
- 在终结点中创建的数据库。 这些数据库仅包含元数据(如用户、角色、架构、视图、内联表值函数 [TVF]、存储过程、数据库范围的凭据、外部数据源、外部文件格式和外部表)。
- 如果使用架构推理,则会读取文件片段来推断列名称和数据类型,并将读取的数据量添加到处理的数据量。
- 数据定义语言 (DDL) 语句(CREATE STATISTICS 语句除外),因为它基于指定的示例百分比处理存储中的数据。
- 仅限元数据的查询。
减少已处理的数据量
可以通过对数据进行分区并将数据转换为基于压缩的列格式(如 Parquet)来优化每查询处理的数据量并提高性能。
例子
想象一下三张桌子。
- population_csv 表由 5 TB 的 CSV 文件支持。 这些文件按五个同样大小的列进行组织。
- population_parquet 表的数据与population_csv表相同。 它备有 1 TB 的 Parquet 文件。 此表小于上一个表,因为数据以 Parquet 格式压缩。
- very_small_csv 表备有 100 KB 的 CSV 文件。
查询 1:SELECT SUM(population) FROM population_csv
此查询读取和解析整个文件以获取人口列的值。 节点处理此表的片段,并且每个片段的总体总和在节点之间传输。 最终的总和会传输到你的终结点。
此查询会处理 5 TB 的数据,此外还有用于传输片段总和的少量开销。
查询 2:SELECT SUM(population) FROM population_parquet
查询压缩格式和基于列的格式(如 Parquet)时,读取的数据比查询 1 少。 你会看到此结果,因为无服务器 SQL 池读取单个压缩列而不是整个文件。 在此示例中,将读取 0.2 TB 的数据。 (五个大小相等的数据列,每个数据列为 0.2 TB)。节点处理此表的数据片段,并且每个片段的数据量总和在节点之间传输。 最终的总和会传输到你的终结点。
此查询会处理 0.2 TB 的数据,此外还有用于传输片段总和的少量开销。
查询 3:SELECT * FROM population_parquet
此查询读取所有列并传输未压缩格式的所有数据。 如果压缩格式为 5:1,则查询将处理 6 TB,因为它读取 1 TB 并传输 5 TB 的未压缩数据。
查询 4:SELECT COUNT(*) FROM very_small_csv
此查询读取完整的文件。 此表存储中文件的总大小为 100 KB。 节点处理此表的片段,并且每个片段的总和在节点之间传输。 最终的总和会传输到你的终结点。
此查询处理的数据略高于 100 KB。 为此查询处理的数据量会向上舍入为 10 MB,如本文的舍入部分所述。
成本控制
无服务器 SQL 池中的成本控制功能使你可以设置处理的数据量的预算。 可以设置一天、周和月处理的数据的预算(以 TB 为单位)。 同时,可以设置一个或多个预算。 若要为无服务器 SQL 池配置成本控制,可以使用 Synapse Studio 或 T-SQL。
在 Synapse Studio 中为无服务器 SQL 池配置成本控制
若要在Synapse Studio中为无服务器 SQL 池配置成本控制,请导航到左侧菜单中的“管理”项,而不是选择 Analytics 池下的 SQL 池项。 将鼠标悬停在无服务器 SQL 池上时,你会注意到成本控制图标 - 单击此图标。
单击成本控制图标后,将显示侧边栏:
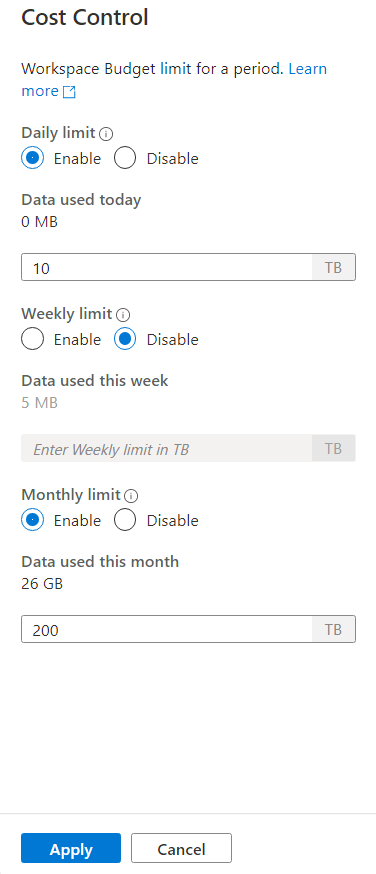
若要设置一个或多个预算,请先单击要设置的预算的“启用单选”按钮,而不是在文本框中输入整数值。 该值的单位为 TB。 配置所需的预算后,单击侧栏底部的“应用”按钮。 就是这样。现在你已设置了预算。
在 T-SQL 中为无服务器 SQL 池配置成本控制
若要在 T-SQL 中为无服务器 SQL 池配置成本控制,需要执行以下一个或多个存储过程。
sp_set_data_processed_limit
@type = N'daily',
@limit_tb = 1
sp_set_data_processed_limit
@type= N'weekly',
@limit_tb = 2
sp_set_data_processed_limit
@type= N'monthly',
@limit_tb = 3334
若要查看当前配置,请执行以下 T-SQL 语句:
SELECT * FROM sys.configurations
WHERE name like 'Data processed %';
若要查看在当前日期、周或月份处理的数据量,请执行以下 T-SQL 语句:
SELECT * FROM sys.dm_external_data_processed
超出成本控制中定义的限制
如果查询执行期间超出任何限制,则不会终止查询。
超出限制后,新查询将被拒绝,并附带一条错误消息,其中包含关于时间段的详细信息、该时间段的定义限制以及该时间段处理的数据。 例如,如果执行新查询,如果每周限制设置为 1 TB 且已超出,则错误消息将为:
Query is rejected because SQL Serverless budget limit for a period is exceeded. (Period = Weekly: Limit = 1 TB, Data processed = 1 TB))
后续步骤
若要了解如何优化查询的性能,请参阅 适用于无服务器 SQL 池的最佳做法。