适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
本文概述了如何使用Azure Data Factory中的复制活动从/向 REST 终结点复制数据。 本文基于 Azure Data Factory 中的Copy Activity,并概述了复制活动。
此 REST 连接器、HTTP 连接器和 Web 表连接器之间的区别如下:
- REST connector 连接器专门支持从 RESTful API 复制数据。
- HTTP 连接器是通用的,可从任何 HTTP 终结点检索数据,以执行文件下载等操作。 在使用此 REST 连接器之前,你可能会偶尔使用 HTTP 连接器从 RESTful API 复制数据,虽然 HTTP 连接器受支持,但与 REST 连接器相比功能较少。
- Web 表连接器用于从 HTML 网页中提取表内容。
支持的功能
此 REST 连接器支持以下功能:
| 支持的功能 | IR |
|---|---|
| Copy activity (源/接收器) | (1) (2) |
| 映射数据流(源/汇) | (1) |
(1) Azure集成运行时 (2) 自承载集成运行时
如需可以用作源/接收器的数据存储的列表,请参阅支持的数据存储。
具体而言,此泛型 REST 连接器支持:
- 使用 GET 或 POST 方法从 REST 终结点复制数据,以及使用 POST、PUT 或 PATCH 方法将数据复制到 REST 终结点。
- 使用以下身份验证之一复制数据:“匿名”、“基本”、“服务主体”、“OAuth2 客户端凭据”、“系统分配的托管标识”和“用户分配的托管标识”。
- REST API 中的分页。
- 对于作为源的 REST,按原样复制 REST JSON 响应,或使用架构映射对其进行分析。 仅支持 JSON 格式的响应有效负载。
提示
若要在数据工厂中配置 REST 连接器之前测试数据检索请求,请了解标头和正文的 API 规范要求。 可以使用Visual Studio、PowerShell 的 Invoke-RestMethod 或 Web 浏览器等工具来验证。
先决条件
如果数据存储位于本地网络、Azure虚拟网络或 Amazon 虚拟私有云中,则需要配置自承载集成运行时以连接到它。
如果数据存储是托管的云数据服务,则可以使用Azure Integration Runtime。 如果访问仅限于防火墙规则中批准的 IP,则可以将 Azure Integration Runtime IP 添加到允许列表。
还可以在 Azure Data Factory 中使用 托管虚拟网络集成运行时功能访问本地网络,而无需安装和配置自承载集成运行时。
要详细了解网络安全机制和数据工厂支持的选项,请参阅数据访问策略。
开始
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建 REST 链接服务
使用以下步骤在Azure门户 UI 中创建 REST 链接服务。
浏览到Azure Data Factory或 Synapse 工作区中的“管理”选项卡,然后选择“链接服务”,然后选择“新建”
搜索“REST”并选择 REST 连接器。
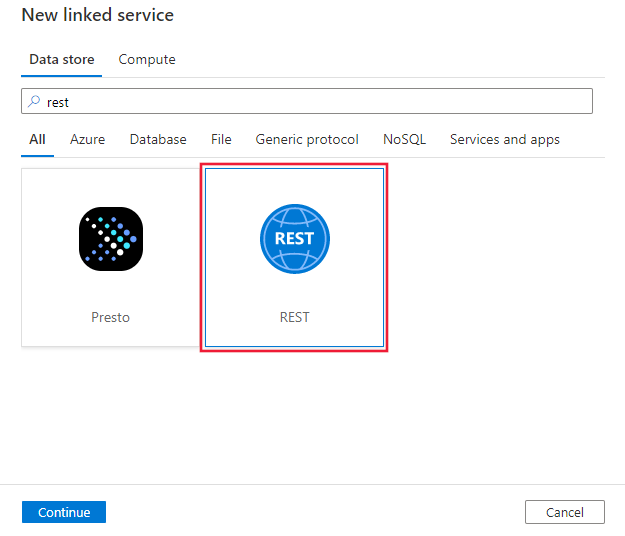
配置服务详细信息、测试连接并创建新的链接服务。
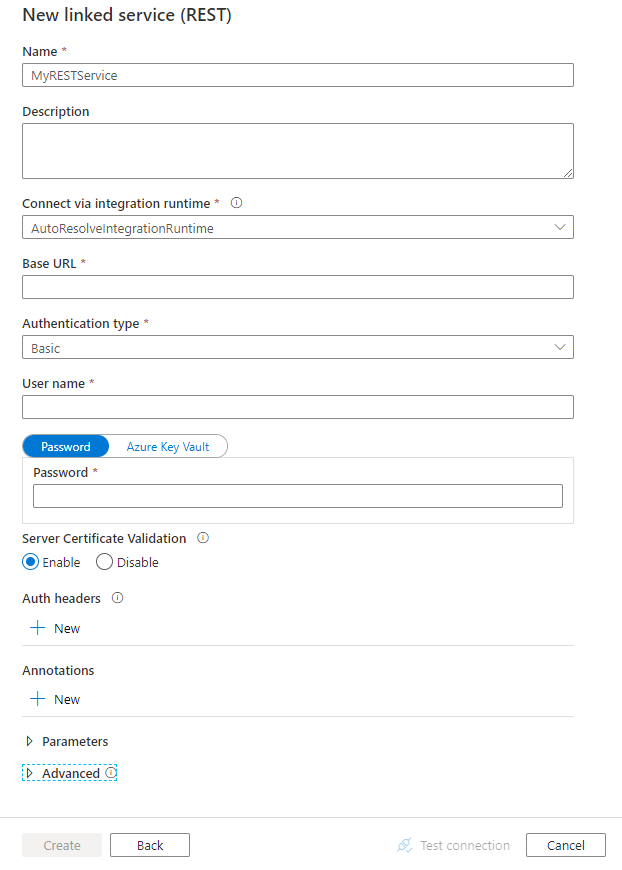
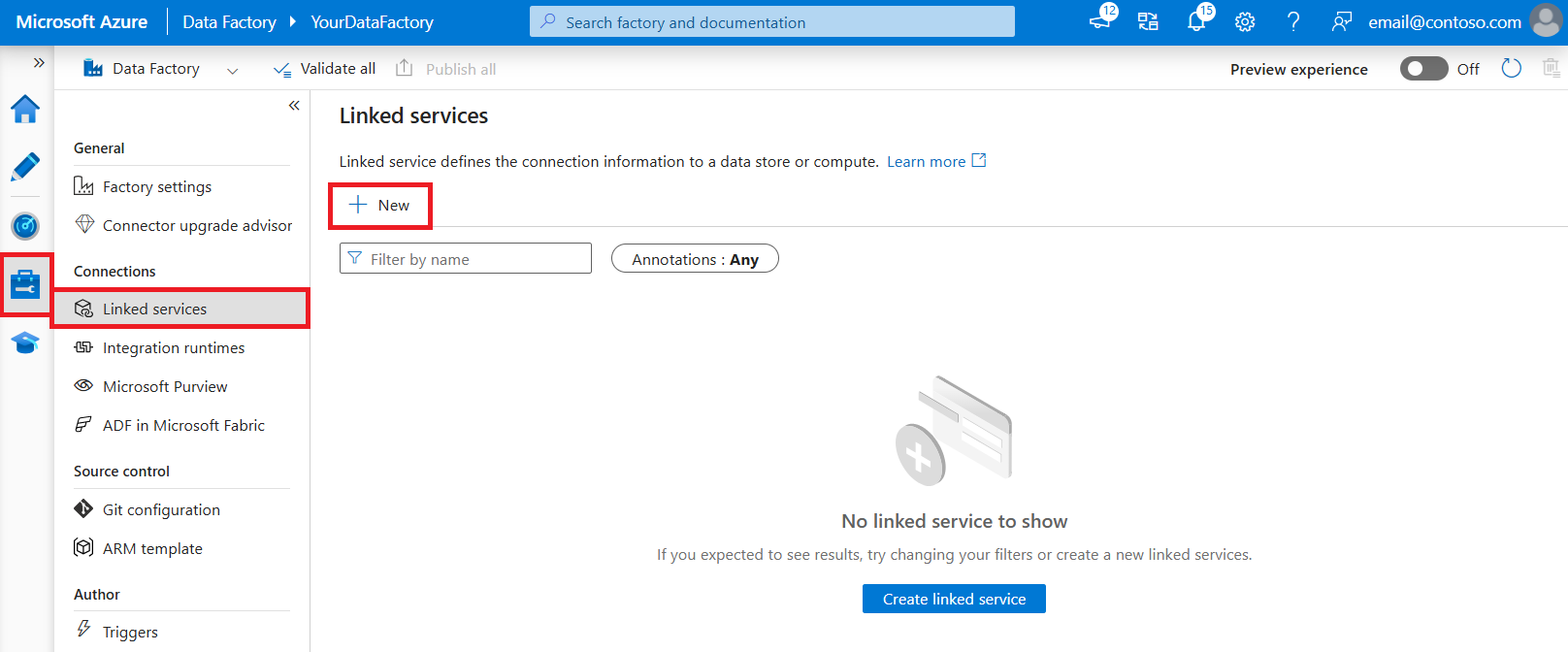
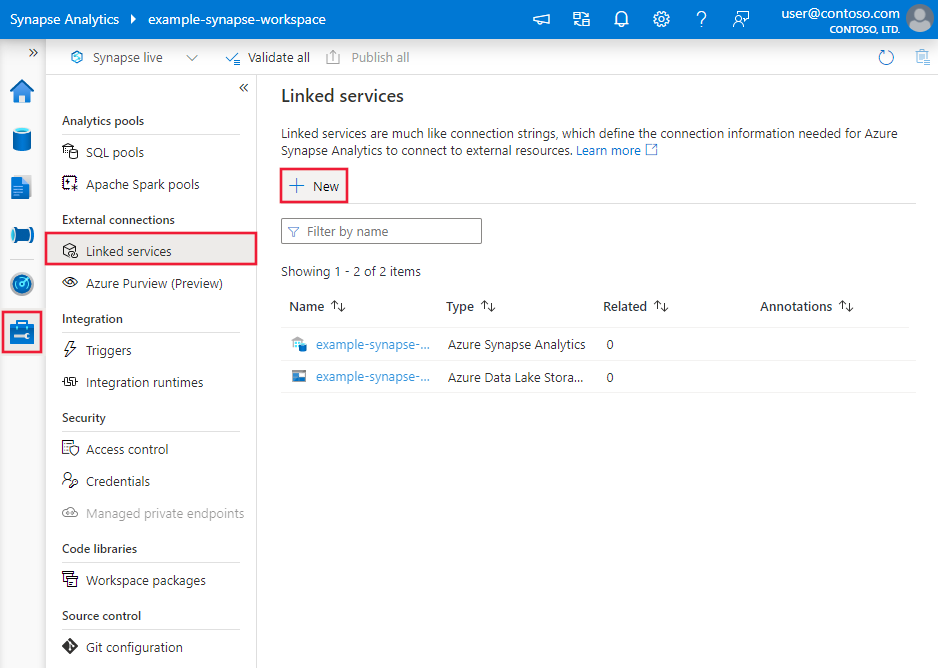
连接器配置详细信息
对于特定于 REST 连接器的数据工厂实体,以下部分提供了有关用于定义这些实体的属性的详细信息。
连接的服务属性
REST 链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为 RestService。 | 是 |
| 网址 | REST 服务的基础 URL。 | 是 |
| 启用服务器证书验证 | 连接到终结点时是否要验证服务器端 TLS/SSL 证书。 | 否 (默认值为 true) |
| 验证类型 | 用于连接到 REST 服务的身份验证类型。 允许的值为 Anonymous、Basic、AadServicePrincipal、OAuth2ClientCredential 和 ManagedServiceIdentity。 此外,还可以在 authHeaders 属性中配置身份验证标头。 有关其他属性和示例,请参阅下面的相应部分。 |
是 |
| authHeaders | 用于身份验证的其他 HTTP 请求标头。 例如,若要使用 API 密钥身份验证,可以将身份验证类型选为“匿名”,然后在标头中指定 API 密钥。 |
否 |
| 连接方式 | 用于连接到数据存储的 Integration Runtime。 从先决条件部分了解更多信息。 如果未指定,此属性将使用默认Azure Integration Runtime。 | 否 |
有关不同的身份验证类型,请参阅相应的部分了解详细信息。
使用基本身份验证
将 authenticationType 属性设置为 Basic。 除了前面部分所述的通用属性,还指定以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 用户名 | 用于访问 REST 终结点的用户名。 | 是 |
| 密码 | 用户(userName 值)的密码。 将此字段标记为 SecureString 类型,以便安全地将其存储在数据工厂中。 还可以引用存储在 Azure Key Vault 中的机密。 | 是 |
示例
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"authenticationType": "Basic",
"url" : "<REST endpoint>",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
使用服务主体身份验证
将 authenticationType 属性设置为 AadServicePrincipal。 除了前面部分所述的通用属性,还指定以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 服务主体标识符 | 指定Microsoft Entra应用程序的客户端 ID。 | 是 |
| 服务主体凭证类型 | 指定要用于服务主体身份验证的凭据类型。 允许的值为 ServicePrincipalKey 和 ServicePrincipalCert。 |
否 |
| 适用于 ServicePrincipalKey | ||
| 服务主体密钥 | 指定Microsoft Entra应用程序的密钥。 将此字段标记为 SecureString 以安全地将其存储在数据工厂中,或引用存储在 Azure Key Vault 中的机密。 | 否 |
| 适用于 ServicePrincipalCert | ||
| 服务主体嵌入式证书 | 指定在 Microsoft Entra ID 中注册的应用程序的 base64 编码证书,并确保证书内容类型PKCS #12。 将此字段标记为 SecureString 以安全地存储该字段,或引用存储在 Azure Key Vault 中的机密。 转到此 section 了解如何在Azure Key Vault中保存证书。 | 否 |
| servicePrincipalEmbeddedCertPassword(服务主体嵌入式证书密码) | 如果使用密码保护证书,请指定证书的密码。 将此字段标记为 SecureString 以安全地存储该字段,或引用存储在 Azure Key Vault 中的机密。 | 否 |
| 租户 | 请指定您的应用程序所归属的租户信息(域名或租户 ID)。 通过将鼠标悬停在Azure门户右上角来检索它。 | 是 |
| aadResourceId | 指定要请求授权的Microsoft Entra资源,例如https://management.core.chinacloudapi.cn。 |
是 |
| Azure云类型 | 对于服务主体身份验证,请指定注册Microsoft Entra应用程序的Azure云环境的类型。 允许的值为“AzureChina”。 默认情况下,使用数据工厂的云环境。 |
否 |
示例 1:使用服务主体密钥身份验证
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.partner.onmschina.cn>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.chinacloudapi.cn>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
示例 2:使用服务主体证书身份验证
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "AadServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalCert",
"servicePrincipalEmbeddedCert": {
"type": "SecureString",
"value": "<the base64 encoded certificate of your application registered in Microsoft Entra ID>"
},
"servicePrincipalEmbeddedCertPassword": {
"type": "SecureString",
"value": "<password of your certificate>"
},
"tenant": "<tenant info, e.g. microsoft.partner.onmschina.cn>",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.chinacloudapi.cn>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
将服务主体证书保存在 Azure Key Vault
可以使用两个选项在 Azure Key Vault 中保存服务主体证书:
选项 1
将服务主体证书转换为 base64 字符串。 有关详细信息,请参阅本文。
将 base64 字符串另存为Azure Key Vault中的机密。
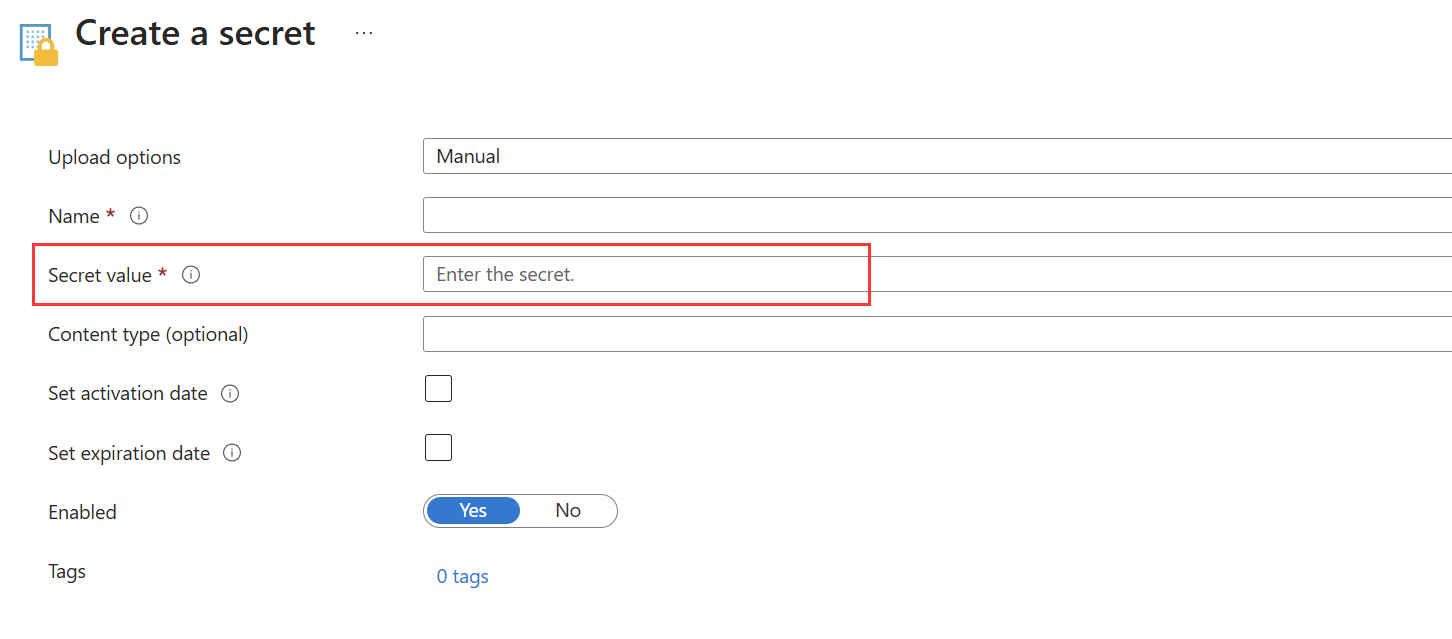
方法 2
如果无法从 Azure Key Vault 下载证书,则可以使用此 template 将转换的服务主体证书保存为Azure Key Vault中的机密。

使用 OAuth2 客户端凭据身份验证
将 authenticationType 属性设置为 OAuth2ClientCredential。 除了前面部分所述的通用属性,还指定以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| tokenEndpoint | 用于获取访问令牌的授权服务器的令牌终结点。 | 是 |
| 客户端 ID | 与应用程序关联的客户端 ID。 | 是 |
| 客户密钥 | 与应用程序关联的客户端密码。 将此字段标记为 SecureString 类型,以便安全地将其存储在数据工厂中。 还可以引用存储在 Azure Key Vault 中的机密。 | 是 |
| 作用域 | 所需的访问范围。 它描述将请求哪种类型的访问。 | 否 |
| 资源 | 将请求访问的目标服务或资源。 | 否 |
示例
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"enableServerCertificateValidation": true,
"authenticationType": "OAuth2ClientCredential",
"clientId": "<client ID>",
"clientSecret": {
"type": "SecureString",
"value": "<client secret>"
},
"tokenEndpoint": "<token endpoint>",
"scope": "<scope>",
"resource": "<resource>"
}
}
}
使用系统分配的托管标识身份验证
将 authenticationType 属性设置为 ManagedServiceIdentity。 除了前面部分所述的通用属性,还指定以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| aadResourceId | 指定要请求授权的Microsoft Entra资源,例如https://management.core.chinacloudapi.cn。 |
是 |
示例
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<AAD resource URL e.g. https://management.core.windows.net>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
使用用户分配的托管身份身份验证
将 authenticationType 属性设置为 ManagedServiceIdentity。 除了前面部分所述的通用属性,还指定以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| aadResourceId | 指定要请求授权的Microsoft Entra资源,例如https://management.core.chinacloudapi.cn。 |
是 |
| 凭据 | 将用户分配的托管标识指定为凭据对象。 | 是 |
示例
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint e.g. https://www.example.com/>",
"authenticationType": "ManagedServiceIdentity",
"aadResourceId": "<Azure AD resource URL e.g. https://management.core.chinacloudapi.cn>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
使用身份验证标头
此外,还可以配置身份验证请求标头,以及内置的身份验证类型。
示例:使用 API 密钥身份验证
{
"name": "RESTLinkedService",
"properties": {
"type": "RestService",
"typeProperties": {
"url": "<REST endpoint>",
"authenticationType": "Anonymous",
"authHeaders": {
"x-api-key": {
"type": "SecureString",
"value": "<API key>"
}
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
本部分提供 REST 数据集支持的属性列表。
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集和链接服务。
若要从 REST 复制数据,支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集的 type 属性必须设置为 RestResource。 | 是 |
| relativeUrl | 包含数据的资源的相对 URL。 未指定此属性时,仅使用链接服务定义中指定的 URL。 HTTP 连接器从以下组合 URL 复制数据:[URL specified in linked service]/[relative URL specified in dataset]。 |
否 |
如果在数据集中设置了 requestMethod、additionalHeaders、requestBody 和 paginationRules,则仍按原样支持该数据集,但建议你以后在活动中使用新模型。
示例:
{
"name": "RESTDataset",
"properties": {
"type": "RestResource",
"typeProperties": {
"relativeUrl": "<relative url>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<REST linked service name>",
"type": "LinkedServiceReference"
}
}
}
复制活动属性
本部分提供了 REST 源和接收器支持的属性列表。
有关可用于定义活动的各个部分和属性的完整列表,请参阅管道。
REST 作为源
复制活动source部分支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动源的 type 属性必须设置为 RestSource。 | 是 |
| 请求方法 | HTTP 方法。 允许的值为 GET(默认值)和 POST。 | 否 |
| 附加头信息 | 其他 HTTP 请求标头。 | 否 |
| 请求主体 | HTTP 请求的正文。 | 否 |
| 分页规则 | 用于撰写下一页请求的分页规则。 有关详细信息,请参阅分页支持部分。 | 否 |
| httpRequestTimeout | 用于获取响应的 HTTP 请求的超时 (TimeSpan 值)。 该值是用于获取回应的超时时间,而不是读取回应数据的超时时间。 默认值为 00:01:40。 | 否 |
| 请求间隔 | 发送下一页请求之前等待的时间。 默认值为 00:00:01 | 否 |
注意
REST 连接器忽略在 additionalHeaders 中指定的任何 Accept 标头。 因为它仅支持 JSON 响应,因此会自动将标头设置为 Accept: application/json。
顶级结构是 JSON 数组的 REST API 响应不支持分页。
示例 1:对分页使用 Get 方法
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"additionalHeaders": {
"x-user-defined": "helloworld"
},
"paginationRules": {
"AbsoluteUrl": "$.paging.next"
},
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
示例 2:使用 Post 方法
"activities":[
{
"name": "CopyFromREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<REST input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "RestSource",
"requestMethod": "Post",
"requestBody": "<body for POST REST request>",
"httpRequestTimeout": "00:01:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
REST 作为接收器
复制活动接收器部分中支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动接收器的 type 属性必须设置为 RestSink。 | 是 |
| 请求方法 | HTTP 方法。 允许的值为 POST(默认值)、PUT 和 PATCH。 | 否 |
| 附加头信息 | 其他 HTTP 请求标头。 | 否 |
| httpRequestTimeout | 用于获取响应的 HTTP 请求的超时 (TimeSpan 值)。 此值是获取响应的超时,而不是写入数据的超时。 默认值为 00:01:40。 | 否 |
| 请求间隔 | 不同请求之间的间隔时间(以毫秒为单位)。 请求时间间隔值应当为 [10, 60000] 范围中的数字。 | 否 |
| HTTP压缩类型 (httpCompressionType) | 使用最佳压缩级别发送数据时要使用的 HTTP 压缩类型。 允许的值为 none 和 gzip。 | 否 |
| writeBatchSize | 每批写入 REST 接收端的记录数。 默认值为 10000。 | 否 |
REST 连接器作为接收器时适用于接受 JSON 的 REST API。 数据将采用 JSON 以下列模式发送。 根据需要,可以使用复制活动架构映射来重新调整源数据的形式,使之符合 REST API 预期的有效负载。
[
{ <data object> },
{ <data object> },
...
]
示例:
"activities":[
{
"name": "CopyToREST",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<REST output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "RestSink",
"requestMethod": "POST",
"httpRequestTimeout": "00:01:40",
"requestInterval": 10,
"writeBatchSize": 10000,
"httpCompressionType": "none",
},
}
}
]
映射数据流属性
在数据流中,REST 支持集成数据集和内联数据集。
源转换
| 属性 | 描述 | 必需 |
|---|---|---|
| 请求方法 | HTTP 方法。 允许的值为 GET 和 POST。 | 是 |
| relativeUrl | 包含数据的资源的相对 URL。 未指定此属性时,仅使用链接服务定义中指定的 URL。 HTTP 连接器从以下组合 URL 复制数据:[URL specified in linked service]/[relative URL specified in dataset]。 |
否 |
| 附加头信息 | 其他 HTTP 请求标头。 | 否 |
| httpRequestTimeout | 用于获取响应的 HTTP 请求的超时 (TimeSpan 值)。 此值是获取响应的超时,而不是写入数据的超时。 默认值为 00:01:40。 | 否 |
| 请求间隔 | 不同请求之间的间隔时间(以毫秒为单位)。 请求时间间隔值应当为 [10, 60000] 范围中的数字。 | 否 |
| QueryParameters.request_query_parameter 或 QueryParameters['request_query_parameter'] | “request_query_parameter”由用户定义,引用下一个 HTTP 请求 URL 中的一个查询参数名称。 | 否 |
接收器转换
| 属性 | 描述 | 必需 |
|---|---|---|
| 附加头信息 | 其他 HTTP 请求标头。 | 否 |
| httpRequestTimeout | 用于获取响应的 HTTP 请求的超时 (TimeSpan 值)。 此值是获取响应的超时,而不是写入数据的超时。 默认值为 00:01:40。 | 否 |
| 请求间隔 | 不同请求之间的间隔时间(以毫秒为单位)。 请求时间间隔值应当为 [10, 60000] 范围中的数字。 | 否 |
| HTTP压缩类型 (httpCompressionType) | 使用最佳压缩级别发送数据时要使用的 HTTP 压缩类型。 允许的值为 none 和 gzip。 | 否 |
| writeBatchSize | 每批写入 REST 接收端的记录数。 默认值为 10000。 | 否 |
可以设置 delete、insert、update 和 upsert 方法,以及相应的行数据,这些数据将发送到 REST 终端以进行 CRUD 操作。
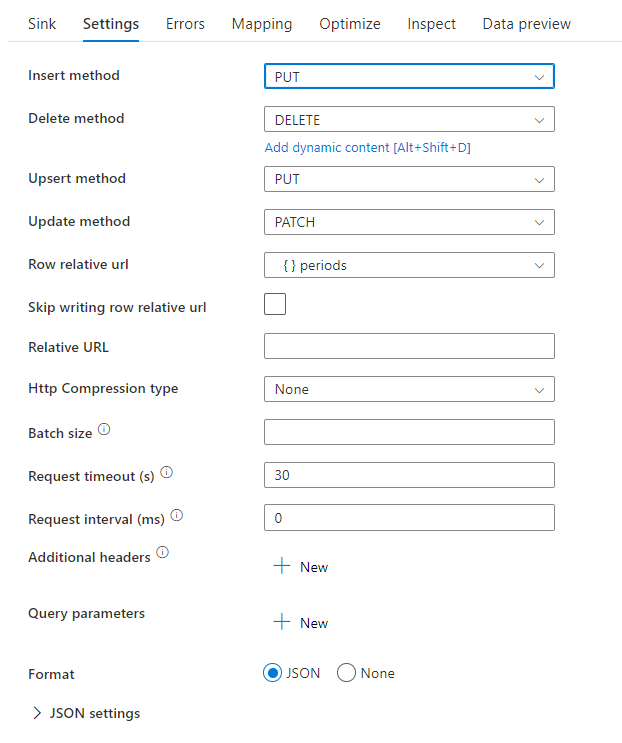
示例数据流脚本
请注意,先于接收器使用更改行转换,指示 ADF 要对 REST 接收器执行哪种类型的操作。 即插入、更新、合并、删除。
AlterRow1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
rowRelativeUrl: 'periods',
insertHttpMethod: 'PUT',
deleteHttpMethod: 'DELETE',
upsertHttpMethod: 'PUT',
updateHttpMethod: 'PATCH',
timeout: 30,
requestFormat: ['type' -> 'json'],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
注意
Data Flow在处理 N 页时生成总共 N+1 API 调用。 这包括一个用于推断架构的初始调用,后跟对应于从源中提取的页数的 N 个调用。
分页支持
从 REST API 复制数据时,REST API 通常会将单个请求的响应有效负载大小限制在合理的数字以下;若要返回大量的数据,它会将结果拆分成多个页面,并要求调用方发送连续的请求来获取下一页结果。 一般情况下,一个页面的请求是动态的,由上一页响应中返回的信息构成。
此泛型 REST 连接器支持以下分页模式:
- 下一个请求的绝对或相对 URL = 当前响应正文中的属性值
- 下一个请求的绝对或相对 URL = 当前响应标头中的标头值
- 下一个请求的查询参数 = 当前响应正文中的属性值
- 下一个请求的查询参数 = 当前响应标头中的标头值
- 下一个请求的标头 = 当前响应正文中的属性值
- 下一个请求的标头 = 当前响应标头中的标头值
“分页规则”定义为包含一个或多个区分大小写的键值对的数据集中的字典。 该配置将用于从第二页开始生成请求。 当连接器收到 HTTP 状态代码 204(无内容),或者“paginationRules”中的任意 JSONPath 表达式返回 null 时,连接器将停止迭代。
分页规则中支持的键:
| 键 | 描述 |
|---|---|
| AbsoluteUrl | 指示用于发出下一个请求的 URL。 它可以是绝对 URL 或相对 URL。 |
| QueryParameters.request_query_parameter 或 QueryParameters['request_query_parameter'] | “request_query_parameter”由用户定义,引用下一个 HTTP 请求 URL 中的一个查询参数名称。 |
| Headers.request_header 或 Headers['request_header'] | “request_header”由用户定义,引用下一个 HTTP 请求中的一个标头名称。 |
| 结束条件:end_condition | “end_condition”由用户定义,指示在下一个 HTTP 请求中结束分页循环的条件。 |
| MaxRequestNumber (最大请求数量) | 指示最大分页请求数。 设置为空表示没有限制。 |
| 支持RFC5988 | 默认情况下,如果未定义分页规则,则此值设置为 true。 可以通过将 supportRFC5988 设置为 false 或从脚本中删除此属性来禁用该规则。 |
分页规则中支持的值:
| 价值 | 描述 |
|---|---|
| Headers.response_header 或 Headers['response_header'] | “response_header”由用户定义,引用当前 HTTP 响应中的一个标头名称,其值用于发出下一个请求。 |
| 以“$”(表示响应正文的根)开头的 JSONPath 表达式 | 响应正文应仅包含一个 JSON 对象,不支持将对象数组作为响应正文。 JSONPath 表达式应返回单个基元值,该值用于发出下一个请求。 |
注意
在以下几个方面,映射数据流中的分页规则不同于复制活动中的分页规则:
- 映射数据流不支持范围。
-
['']不支持在映射数据流中使用。 请改为使用{}对特殊字符进行转义。 例如body.{@odata.nextLink},其 JSON 节点@odata.nextLink包含特殊字符.。 - 结束条件在映射数据流中受支持,但条件语法不同于复制活动中的条件语法。
body(而不是$)用于指示响应正文。header(而不是headers)用于指示响应头。 下面是展示此差异的两个示例:- 示例 1:
Copy activity: “EndCondition:$.data”: “Empty”
映射数据流:"EndCondition:body.data": "Empty" - 示例 2:
Copy activity: “EndCondition:headers.complete”: “Exist”
映射数据流:"EndCondition:header.complete": "Exist"
- 示例 1:
分页规则示例
本部分提供了一系列的分页规则设置示例。
示例 1:QueryParameters 中的变量
此示例提供用于发送多个请求(其变量在 QueryParameters 中)的配置步骤。
多个请求:
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
......
baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=10000
步骤 1:在“基本 URL”或“相对 URL”中输入 sysparm_offset={offset},如以下屏幕截图所示:
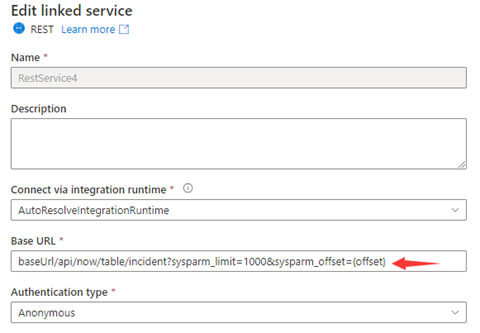
或
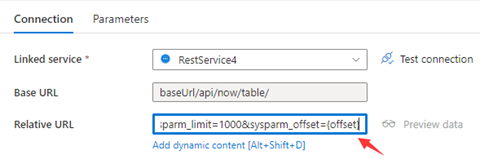
步骤 2:将“分页规则”设置为选项 1 或选项 2:
选项 1:"QueryParameters.{offset}" : "RANGE:0:10000:1000"
选项 2:"AbsoluteUrl.{offset}" : "RANGE:0:10000:1000"
示例 2:AbsoluteUrl 中的变量
此示例提供用于发送多个请求(其变量在 AbsoluteUrl 中)的配置步骤。
多个请求:
BaseUrl/api/now/table/t1
BaseUrl/api/now/table/t2
......
BaseUrl/api/now/table/t100
步骤 1:在“链接服务配置”页的“基本 URL”中或在“数据集连接”窗格的“相对 URL”中输入 {id}。
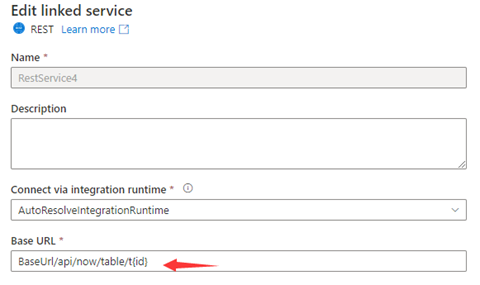
或
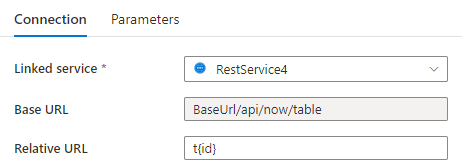
步骤 2:将“分页规则”设置为 "AbsoluteUrl.{id}" :"RANGE:1:100:1"。
示例 3:Headers 中的变量
此示例提供用于发送多个请求(其变量在 Headers 中)的配置步骤。
多个请求:
RequestUrl: https://example/table
Request 1: Header(id->0)
Request 2: Header(id->10)
......
Request 100: Header(id->100)
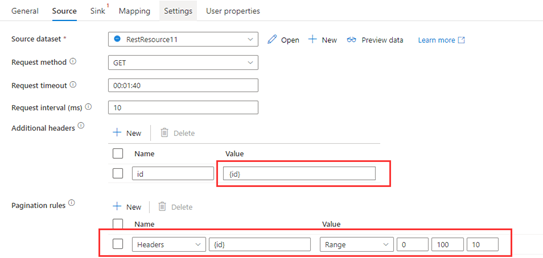
步骤 1:在{id}中输入。
步骤 2:将“分页规则”设置为“Headers.{id}”:“RARNGE:0:100:10”。
示例 4:变量位于 AbsoluteUrl/QueryParameters/Headers 中,未预定义结束变量,并且结束条件基于响应
此示例提供配置步骤来发送多个请求,其变量位于 AbsoluteUrl/QueryParameters/Headers 中,但未定义结束变量。 对于不同的响应,示例 4.1-4.6 中显示了不同的结束条件规则设置。
多个请求:
Request 1: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=0,
Request 2: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=1000,
Request 3: baseUrl/api/now/table/incident?sysparm_limit=1000&sysparm_offset=2000,
......
在此示例中遇到了两个响应:
响应 1:
{
Data: [
{key1: val1, key2: val2
},
{key1: val3, key2: val4
}
]
}
响应 2:
{
Data: [
{key1: val5, key2: val6
},
{key1: val7, key2: val8
}
]
}
步骤 1:按示例 1 设置“分页规则”的范围,并将范围末尾留空,其形式为 "AbsoluteUrl.{offset}": "RANGE:0::1000"。
步骤 2:根据不同的上一个响应设置不同的结束条件规则。 请参阅以下示例:
示例 4.1:当响应中的特定节点的值为空时,分页结束
REST API 返回采用以下结构的上一个响应:
{ Data: [] }将结束条件规则设置为 "EndCondition:$.data": "Empty",以便在响应中的特定节点的值为空时结束分页。

示例 4.2:当响应中特定节点的值不存在时,分页结束
REST API 返回采用以下结构的上一个响应:
{}将结束条件规则设置为 “EndCondition:$.data”:“NonExist” ,以在响应中特定节点的值不存在时结束分页。

示例 4.3:当响应中的特定节点的值存在时,分页结束
REST API 返回采用以下结构的上一个响应:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }将结束条件规则设置为 "EndCondition:$.Complete": "Exist",以便在响应中的特定节点的值存在时结束分页。

示例 4.4:当响应中的特定节点的值是用户定义的常量值时,分页结束
REST API 返回采用以下结构的响应:
{ Data: [ {key1: val1, key2: val2 }, {key1: val3, key2: val4 } ], Complete: false }......
上一个响应采用以下结构:
{ Data: [ {key1: val991, key2: val992 }, {key1: val993, key2: val994 } ], Complete: true }将结束条件规则设置为 "EndCondition:$.Complete": "Const:true",以便在响应中的特定节点的值是用户定义的常量值时结束分页。

示例 4.5:当响应中的标头键的值是用户定义的常量值时,分页结束
REST API 响应中的标头键按照下面的结构显示:
响应头 1:
header(Complete->0)
......
上一个响应头:header(Complete->1)将结束条件规则设置为 "EndCondition:headers.Complete": "Const:1",以便在响应中的标头键的值等于用户定义的常量值时结束分页。

示例 4.6:当响应头中存在该键时,分页结束
REST API 响应中的标头键按照下面的结构显示:
响应头 1:
header()
......
上一个响应头:header(CompleteTime->20220920)将结束条件规则设置为 "EndCondition:headers.CompleteTime": "Exist",以便在响应头中存在该键时结束分页。

示例 5:设置结束条件以避免在未定义范围规则时无休止的请求
此示例提供了在不使用范围规则时发送多个请求的配置步骤。 可以参考示例 4.1-4.6 来设置结束条件,以避免无限请求。 REST API 返回采用以下结构的响应,在此情况下,下一页的 URL 将在 paging.next 中表示。
{
"data": [
{
"created_time": "2017-12-12T14:12:20+0000",
"name": "album1",
"id": "1809938745705498_1809939942372045"
},
{
"created_time": "2017-12-12T14:14:03+0000",
"name": "album2",
"id": "1809938745705498_1809941802371859"
},
{
"created_time": "2017-12-12T14:14:11+0000",
"name": "album3",
"id": "1809938745705498_1809941879038518"
}
],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
...
上一个响应是:
{
"data": [],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw",
"next": "Same with Last Request URL"
}
}
步骤 1:将“分页规则”设置为 "AbsoluteUrl": "$.paging.next"。
步骤 2:如果上一个响应中的 next 始终与上一个请求 URL 相同并且不为空,则会发送无限请求。 结束条件可用于避免无限请求。 因此,请参阅示例 4.1-4.6 来设置结束条件规则。
示例 6:设置最大请求数以避免无限请求
设置 MaxRequestNumber 以避免无限请求,如以下屏幕截图所示:

示例 7:默认支持 RFC 5988 分页规则
后端将基于标头中的 RFC 5988 样式链接自动获取下一个 URL。

提示
如果不想启用此默认分页规则,可以在脚本中将 supportRFC5988 设置为 false 或将其删除。
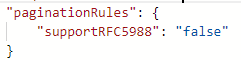
示例 8a:在映射数据流中使用分页时,下一个请求 URL 位于响应正文中
此示例说明当下一个请求 URL 来自响应正文时,如何在映射数据流中设置分页规则与结束条件规则。
响应架构如下所示:
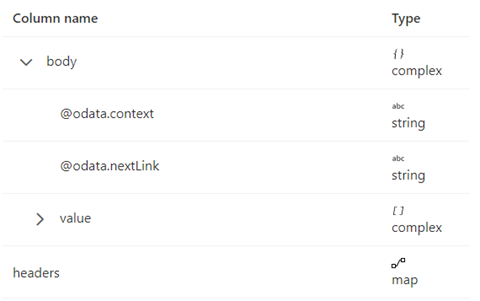
应按以下屏幕截图所示设置分页规则:

默认情况下,当 body.{@odata.nextLink}** 为 null 或为空时,将停止分页。
但如果上一个响应正文中 @odata.nextLink 的值等于上一个请求 URL,则会导致无限循环。 若要避免这种情况,请定义结束条件规则。
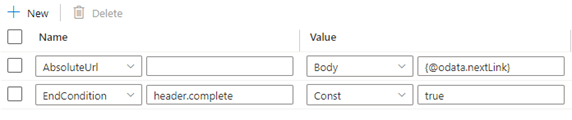
如果上一个响应中的“值”为空,则可以按下面所示设置结束条件规则:

如果响应头中完成键的值等于 true 指示分页结束,则可以按下面所示设置结束条件规则:
示例 8b:在复制活动中使用分页时,下一个请求 URL 位于响应正文中
此示例演示当下一个请求 URL 包含在响应正文中时,如何在复制活动中设置分页规则。
响应架构如下所示:
应按以下屏幕截图所示设置分页规则:

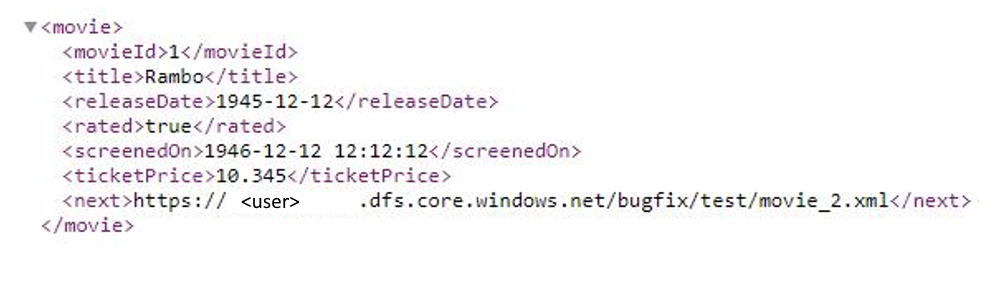
示例 9:在映射数据流中使用分页时,响应格式为 XML 并且下一个请求 URL 来自响应正文
此示例说明当响应格式为 XML 并且下一个请求 URL 来自响应正文时,如何在映射数据流中设置分页规则。 如以下屏幕截图所示,第一个 URL 是 https://<user>.dfs.core.chinacloudapi.cn/bugfix/test/movie_1.xml
响应架构如下所示:
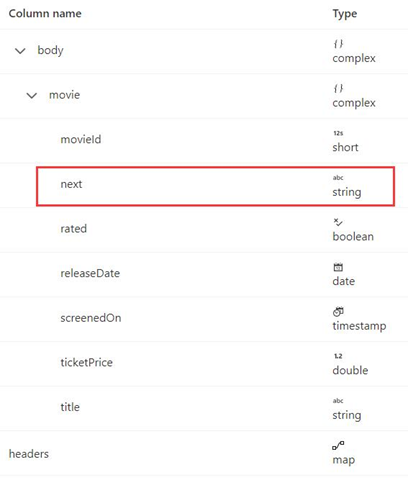
分页规则语法与示例 8 中的语法相同,应按以下示例所示进行设置:

按原样导出 JSON 响应
可以使用 REST 连接器将 REST API 的 JSON 响应 as-is 导出到各种基于文件的存储系统(接收器)。 若要启用此与架构无关的复制行为,请使用默认架构映射(请勿在复制活动的“映射”选项卡中定义任何映射)。
模式映射
若要将数据从 REST 终结点复制到表格接收器,请参阅架构映射。
相关内容
有关 Azure Data Factory 中复制活动支持作为源和汇聚点的数据存储的列表,请参阅 支持的数据存储和格式。