Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
While schema-free databases, like Azure Cosmos DB, make it easy to store and query unstructured and semi-structured data, think about your data model to optimize performance, scalability, and cost.
How is data stored? How does your application retrieve and query data? Is your application read-heavy or write-heavy?
After reading this article, you can answer the following questions:
- What is data modeling and why should I care?
- How is modeling data in Azure Cosmos DB different from a relational database?
- How do you express data relationships in a nonrelational database?
- When do I embed data and when do I link to data?
Numbers in JSON
Azure Cosmos DB saves documents in JSON, so it's important to determine whether to convert numbers into strings before storing them in JSON. Convert all numbers to a String if they might exceed the boundaries of double-precision numbers as defined by Institute of Electrical and Electronics Engineers (IEEE) 754 binary64. The JSON specification explains why using numbers outside this boundary is a bad practice due to interoperability problems. These concerns are especially relevant for the partition key column because it's immutable and requires data migration to change later.
Embed data
When you model data in Azure Cosmos DB, treat your entities as self-contained items represented as JSON documents.
For comparison, let's first see how we might model data in a relational database. The following example shows how a person might be stored in a relational database.
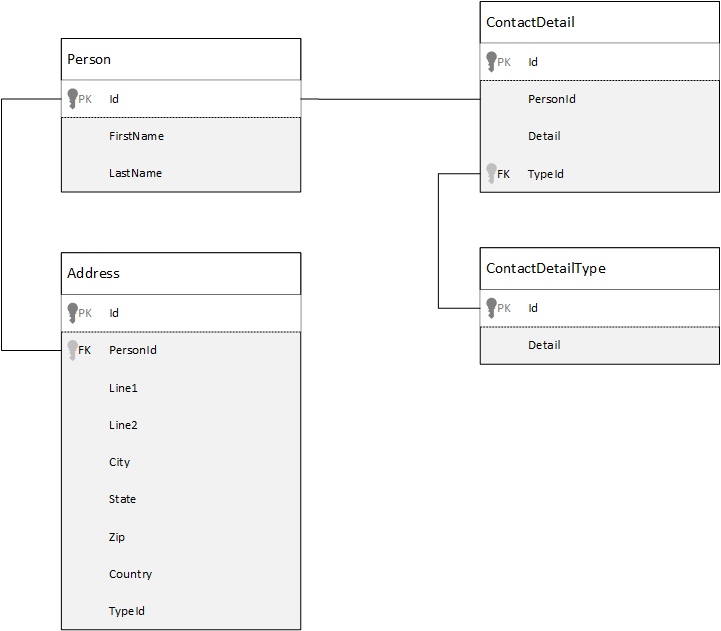
The strategy, when working with relational databases, is to normalize all your data. Normalizing your data typically involves taking an entity, such as a person, and breaking it down into discrete components. In the example, a person might have multiple contact detail records, and multiple address records. You can further break down contact details by extracting common fields such as type. The same approach applies to addresses. Each record can be classified as Home or Business.
The guiding premise when normalizing data is to avoid storing redundant data in each record and instead refer to data. In this example, to read a person, with all their contact details and addresses, you need to use JOINS to effectively compose back (or denormalize) your data at run time.
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Updating a single person's contact details and addresses requires write operations across many individual tables.
Now let's take a look at how we would model the same data as a self-contained entity in Azure Cosmos DB.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Using this approach, we've denormalized the person record by embedding all the information related to this person, such as their contact details and addresses, into a single JSON document. In addition, because we're not confined to a fixed schema we have the flexibility to do things like having contact details of different shapes entirely.
Retrieving a complete person record from the database is now a single read operation against a single container for a single item. Updating the contact details and addresses of a person record is also a single write operation against a single item.
Denormalizing data might reduce the number of queries and updates your application needs to complete common operations.
When to embed
In general, use embedded data models when:
- There are contained relationships between entities.
- There are one-to-few relationships between entities.
- The data changes infrequently.
- The data does not grow without bound.
- The data is queried frequently together.
Note
Typically denormalized data models provide better read performance.
When not to embed
Although the rule of thumb in Azure Cosmos DB is to denormalize everything and embed all data into a single item, this approach can lead to situations to avoid.
Take this JSON snippet.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
This example might be what a post entity with embedded comments would look like if we were modeling a typical blog, or content management system (CMS). The problem with this example is that the comments array is unbounded, meaning that there's no (practical) limit to the number of comments any single post can have. This design might cause problems as the item's size can grow infinitely large, so avoid it.
As the item size increases, transmitting, reading, and updating the data at scale becomes more challenging.
In this case, it would be better to consider the following data model.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
This model has an item for each comment with a property that contains the post identifier. This model lets posts contain any number of comments and grow efficiently. Users wanting to see more than the most recent comments would query this container passing the postId, which should be the partition key for the comments container.
Another case where embedding data isn't a good idea is when the embedded data is used often across items and changes frequently.
Take this JSON snippet.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
This example could represent a person's stock portfolio. We chose to embed the stock information into each portfolio document. In an environment where related data is changing frequently embedding data that changes frequently is going to mean that you're constantly updating each portfolio. Using an example of a stock trading application, you're updating each portfolio item every time a stock is traded.
Stock zbzb can be traded hundreds of times in a single day, and thousands of users could have zbzb in their portfolios. With a data model like the example, the system must update thousands of portfolio documents many times each day, which doesn't scale well.
Reference data
Embedding data works well in many cases, but there are scenarios where denormalizing your data causes more problems than it's worth. So, what can you do?
You can create relationships between entities in document databases, not just in relational databases. In a document database, one item can include information that connects to data in other documents. Azure Cosmos DB isn't designed for complex relationships like those in relational databases, but simple links between items are possible and can be helpful.
In the JSON, we use the example of a stock portfolio from earlier, but this time we refer to the stock item in the portfolio instead of embedding it. This way, when the stock item changes frequently throughout the day the only item that needs to be updated is the single stock document.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
One drawback of this approach is that your application must make several database requests to get information about each stock in a person's portfolio. This design makes writing data faster, since updates happen often. However, it makes reading or querying data slower, which is less important for this system.
Note
Normalized data models can require more round trips to the server.
What about foreign keys?
Because there's no concept of a constraint, such as a foreign key, the database doesn't verify any inter-document relationships in documents; these links are effectively "weak." If you want to ensure that the data an item is referring to actually exists, then you need to do this step in your application, or by using server-side triggers or stored procedures on Azure Cosmos DB.
When to reference
In general, use normalized data models when:
- Representing one-to-many relationships.
- Representing many-to-many relationships.
- Related data changes frequently.
- Referenced data could be unbounded.
Note
Typically normalizing provides better write performance.
Where do I put the relationship?
The growth of the relationship helps determine in which item to store the reference.
If we observe the JSON that models publishers and books.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over China one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
If the number of books per publisher is small and growth is limited, storing the book reference inside the publisher item might be useful. However, if the number of books per publisher is unbounded, then this data model would lead to mutable, growing arrays, as in the example publisher document.
Switching the structure results in a model that represents the same data but avoids large mutable collections.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over China one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
In this example, the publisher document no longer contains an unbounded collection. Instead, each book document includes a reference to its publisher.
How do I model many-to-many relationships?
In a relational database, many-to-many relationships are often modeled with join tables. These relationships just join records from other tables together.
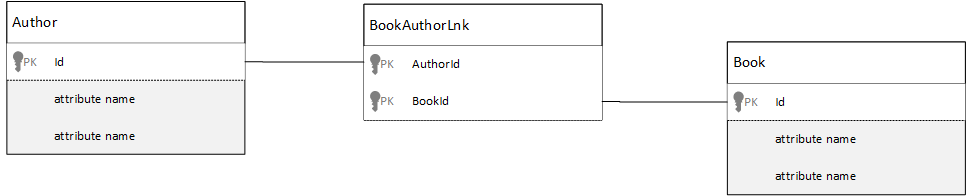
You might be tempted to replicate the same thing using documents and produce a data model that looks similar to the following.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over China one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
This approach works, but loading an author with their books or a book with its author always requires at least two extra database queries. One query to the joining item and then another query to fetch the actual item being joined.
If this join is only gluing together two pieces of data, then why not drop it completely? Consider the following example.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
With this model, you can easily see which books an author wrote by looking at their document. You can also see which authors wrote a book by checking the book document. You don't need to use a separate join table or make extra queries. This model makes it faster and simpler for your application to get the data it needs.
Migrating from relational databases
If you're migrating from PostgreSQL or another relational database, plan to reshape both your data model and your queries. In relational systems, queries often reconstruct business entities with JOINs across tables. In Azure Cosmos DB, design each item around the way your application reads and writes that data.
Understand JOIN semantics
In Azure Cosmos DB, a JOIN works within a single item, typically between the root item and a nested array. It doesn't join items across containers or across top-level items.
- Relational JOINs across tables typically require you to remodel data based on access patterns, using approaches such as embedding, references, or read-optimized projections.
- Use embedding for contained data that is read together.
- Use references when related entities are large, unbounded, or updated independently.
For JOIN syntax details, see JOIN in Azure Cosmos DB query language.
Apply common restructuring patterns
Use these patterns when you convert normalized tables:
- One-to-few parent-child: Embed child rows in the parent item.
- One-to-many with unbounded growth: Keep children as separate items and store a reference, such as
parentId. - Frequently updated child entities: Keep the changing entity separate to avoid fan-out updates across many parent items.
- Many-to-many: Replace join tables with reference arrays or duplicated read-optimized projections that match your query patterns.
Adapt queries
A common relational pattern joins parent and child tables:
SELECT c.customer_id, c.name, o.order_id, o.total
FROM Customers c
JOIN Orders o ON o.customer_id = c.customer_id
WHERE c.customer_id = 42
In Azure Cosmos DB, if you embed orders inside a customer item, query that single item and join to the nested array:
SELECT c.id, c.name, o.id AS order_id, o.total
FROM c
JOIN o IN c.orders
WHERE c.id = "42" AND c.tenantId = "adventureworks"
If orders are large or updated independently, store them as separate items and query by customerId instead of performing a cross-item JOIN:
SELECT o.id, o.total, o.customerId
FROM o
WHERE o.customerId = "42"
To keep these queries efficient, include the partition key in your filter whenever possible. For separate order items, customerId is often a good partition key when your common access pattern is "all orders for one customer," but choose it only when each customer's orders fit within the storage and throughput limits of a single logical partition. If some customers can grow without bound or create disproportionately high traffic, use a hierarchical or synthetic partitioning strategy instead of placing all of that customer's orders in one logical partition.
Hybrid data models
We explore embedding (or denormalizing) and referencing (or normalizing) data. Each approach offers benefits and involves trade-offs.
It doesn't always have to be either-or. Don't hesitate to mix things up a little.
Based on your application's specific usage patterns and workloads, mixing embedded and referenced data might make sense. This approach could simplify application logic, reduce server round trips, and maintain good performance.
Consider the following JSON.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Here we have (mostly) followed the embedded model, where data from other entities are embedded in the top-level document, but other data is referenced.
If you look at the book document, we can see a few interesting fields when we look at the array of authors. There's an id field that is the field we use to refer back to an author document, standard practice in a normalized model, but then we also have name and thumbnailUrl. We could use only the id and let the application retrieve any additional information it needs from the corresponding author item using the "link." However, since the application displays the author's name and a thumbnail picture with every book, denormalizing some data from the author reduces the number of server round trips per book in a list.
If the author's name changes or they update their photo, you'd need to update every book they published. However, for this application, assuming authors rarely change their names, this compromise is an acceptable design decision.
In the example, there are precalculated aggregate values to save expensive processing during a read operation. In the example, some of the data embedded in the author item is data that is calculated at run-time. Every time a new book is published, a book item is created and the countOfBooks field is set to a calculated value based on the number of book documents that exist for a particular author. This optimization would be good in read heavy systems where we can afford to do computations on writes in order to optimize reads.
The ability to have a model with precalculated fields is made possible because Azure Cosmos DB supports multi-document transactions. Many NoSQL stores can't perform transactions across documents and therefore advocate design decisions like "always embed everything" because of this limitation. With Azure Cosmos DB, you can use server-side triggers, or stored procedures that insert books and update authors all within an ACID transaction. Now you don't have to embed everything into one item just to be sure that your data remains consistent.
Distinguish between different item types
In some scenarios, you might want to mix different item types in the same collection; this design choice is usually the case when you want multiple, related documents to sit in the same partition. For example, you could put both books and book reviews in the same collection and partition it by bookId. In such a situation, you usually want to add a field to your documents that identifies their type to differentiate them.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
}
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Versioning and temporal data patterns
Choose a versioning pattern based on retention requirements, query latency goals, and cost limits when your data changes frequently and you need to query older states.
Event sourcing with change feed
Use an append-only event model where each mutation is written as a new event item. Use the change feed design patterns guidance to project current state into one or more materialized views.
- Storage cost: Higher over time because every mutation is retained as an event.
- Query complexity: Higher for point-in-time reconstruction unless you maintain read-optimized projections.
- Write throughput: Higher than overwrite-in-place because each mutation is an extra write, but writes stay simple and scalable.
Snapshot plus delta pattern
Store periodic full snapshots of an entity and store incremental deltas between snapshots. To read a historical version, load the closest snapshot and then apply later deltas up to the target timestamp.
- Storage cost: Lower than keeping every version as full copies, especially for large items with small changes.
- Query complexity: Moderate to high because historical reads might require replaying multiple deltas.
- Write throughput: Moderate because you write small deltas frequently and larger snapshots on a schedule.
TTL-based version expiry
Use time to live (TTL) to automatically age out older versions while keeping the current version indefinitely. A common approach is to set container TTL to -1 and assign ttl only to historical version items.
- Storage cost: Predictable and bounded because expired versions are removed automatically.
- Query complexity: Low to moderate, depending on whether your retention window is enough for your audit or replay needs.
- Write throughput: Similar to your chosen versioning model, with extra background delete activity as versions expire.
Analytical store for historical access
Enable analytical store to run large historical and trend queries on a synchronized column store without affecting transactional query performance on your operational container. Analytical store reflects the data that you persist, but it doesn't create prior versions when items are overwritten. For versioned or point-in-time reads, first store append-only events or snapshots, and then query that temporal dataset through analytical store.
- Storage cost: Adds analytical storage charges, but can reduce transactional RU consumption for historical reporting.
- Query complexity: Lower for long-range analytics because columnar scans and aggregations are optimized for this workload.
- Write throughput: Minimal direct impact on transactional writes because analytical synchronization is managed automatically.
In practice, teams often combine these patterns. For example, use event sourcing or snapshots for retention semantics, TTL for lifecycle control, and analytical store for cost-efficient historical analytics.
Takeaways
The biggest takeaway from this article is that data modeling in a schema-free scenario is as important as ever.
Just as there's no single way to represent a piece of data on a screen, there's no single way to model your data. You need to understand your application and how it produces, consumes, and processes the data. By applying the guidelines presented here, you can create a model that addresses the immediate needs of your application. When your application changes, use the flexibility of a schema-free database to adapt and evolve your data model easily.