Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure Cosmos DB uses partitioning to scale containers in a database to meet your application's performance needs. The items in a container are divided into distinct subsets called logical partitions. Logical partitions form based on the value of a partition key associated with each item in a container. All the items in a logical partition have the same partition key value.
For example, a container holds items. Each item has a unique value for the UserID property. If UserID serves as the partition key for the items in the container and there are 1,000 unique UserID values, 1,000 logical partitions are created for the container.
Each item in a container has a partition key that determines its logical partition and an item ID unique within that partition. Combining the partition key and the item ID creates the item's index, which uniquely identifies the item. Choosing a partition key is an important decision that affects your application's performance.
Note
In some distributed database systems and learning materials, the term shard key is used to describe the property that determines how data is distributed across shards. In Azure Cosmos DB, this same concept is called the partition key.
Both terms refer to the value used to distribute and locate data, but partition key is the official and correct term used throughout Azure Cosmos DB documentation and APIs.
This article explains the relationship between logical and physical partitions, discusses best practices for partitioning, and provides an in-depth view of how horizontal scaling works in Azure Cosmos DB. You don't need to understand these internal details to select your partition key, but this article covers them to clarify how Azure Cosmos DB works.
Logical partitions
A logical partition is a set of items that share the same partition key. For example, in a container that contains data about food nutrition, all items contain a foodGroup property. Use foodGroup as the partition key for the container. Groups of items that have specific values for foodGroup, such as Beef Products, Baked Products, and Sausages and Luncheon Meats, form distinct logical partitions.
A logical partition also defines the scope of database transactions. You can update items within a logical partition by using a transaction with snapshot isolation. When new items are added to a container, the system transparently creates new logical partitions. You don't have to worry about deleting a logical partition when the underlying data is deleted.
There's no limit to the number of logical partitions in a container. Each logical partition can store up to 20 GB of data. Effective partition keys have a wide range of possible values. For example, in a container where all items contain a foodGroup property, the data within the Beef Products logical partition can grow up to 20 GB. Selecting a partition key with a wide range of possible values ensures that the container is able to scale.
Use Azure Monitor Alerts to monitor whether a logical partition's size is approaching 20 GB.
Physical partitions
A container scales by distributing data and throughput across physical partitions. Internally, one or more logical partitions map to a single physical partition. Typically, smaller containers have many logical partitions but require only a single physical partition. Unlike logical partitions, physical partitions are an internal system implementation, and Azure Cosmos DB fully manages them.
The number of physical partitions in a container depends on these characteristics:
The amount of throughput provisioned (each individual physical partition can provide a throughput of up to 10,000 request units per second). The 10,000 RU/s limit for physical partitions implies that logical partitions also have a 10,000 RU/s limit, as each logical partition is only mapped to one physical partition.
The total data storage (each individual physical partition can store up to 50 gigabytes of data).
Note
Physical partitions are an internal system implementation, fully managed by Azure Cosmos DB. When developing your solutions, don't focus on physical partitions because you can't control them. Instead, focus on partition keys. Choosing a partition key that evenly distributes throughput consumption across logical partitions ensures balanced throughput consumption across physical partitions.
There's no limit to the total number of physical partitions in a container. As your provisioned throughput or data size grows, Azure Cosmos DB automatically creates new physical partitions by splitting existing ones. Physical partition splits don't affect your application's availability. After the physical partition split, all data within a single logical partition will still be stored on the same physical partition. A physical partition split simply creates a new mapping of logical partitions to physical partitions.
Provisioned throughput for a container divides evenly among physical partitions. A partition key design that doesn't distribute requests evenly might result in too many requests directed to a small subset of partitions that become "hot." Hot partitions cause inefficient use of provisioned throughput, which can result in rate limiting and higher costs.
For example, consider a container with the path /foodGroup specified as the partition key. The container could have any number of physical partitions, but in this example we assume it has three. A single physical partition could contain multiple partition keys. As an example, the largest physical partition could contain the top three most significant size logical partitions: Beef Products, Vegetable and Vegetable Products, and Soups, Sauces, and Gravies.
If you assign a throughput of 18,000 request units per second (RU/s), each of the three physical partitions uses one-third of the total provisioned throughput. Within the selected physical partition, the logical partition keys Beef Products, Vegetable and Vegetable Products, and Soups, Sauces, and Gravies can, collectively, utilize the physical partition's 6,000 provisioned RU/s. Because provisioned throughput is evenly divided across your container's physical partitions, it's important to choose a partition key that evenly distributes throughput consumption. For more information, see Choosing the right logical partition key.
Managing logical partitions
Azure Cosmos DB automatically manages the placement of logical partitions on physical partitions to meet the scalability and performance needs of the container. When the throughput and storage requirements of an application increase, Azure Cosmos DB moves logical partitions to spread the load across more physical partitions. Learn more about physical partitions.
Azure Cosmos DB uses hash-based partitioning to distribute logical partitions across physical partitions. Azure Cosmos DB hashes the partition key value of an item. The hashed result determines the logical partition. Then, Azure Cosmos DB allocates the key space of partition key hashes evenly across the physical partitions.
Transactions in stored procedures or triggers are allowed only for items in a single logical partition.
Replica sets
Each physical partition consists of a set of replicas, also called a replica set. Each replica hosts an instance of the database engine. A replica set makes the data store within the physical partition durable, highly available, and consistent. Each replica in the physical partition inherits the partition's storage quota. All replicas of a physical partition collectively support the throughput allocated to that physical partition. Azure Cosmos DB automatically manages replica sets.
Smaller containers usually require a single physical partition, but they still have at least four replicas.
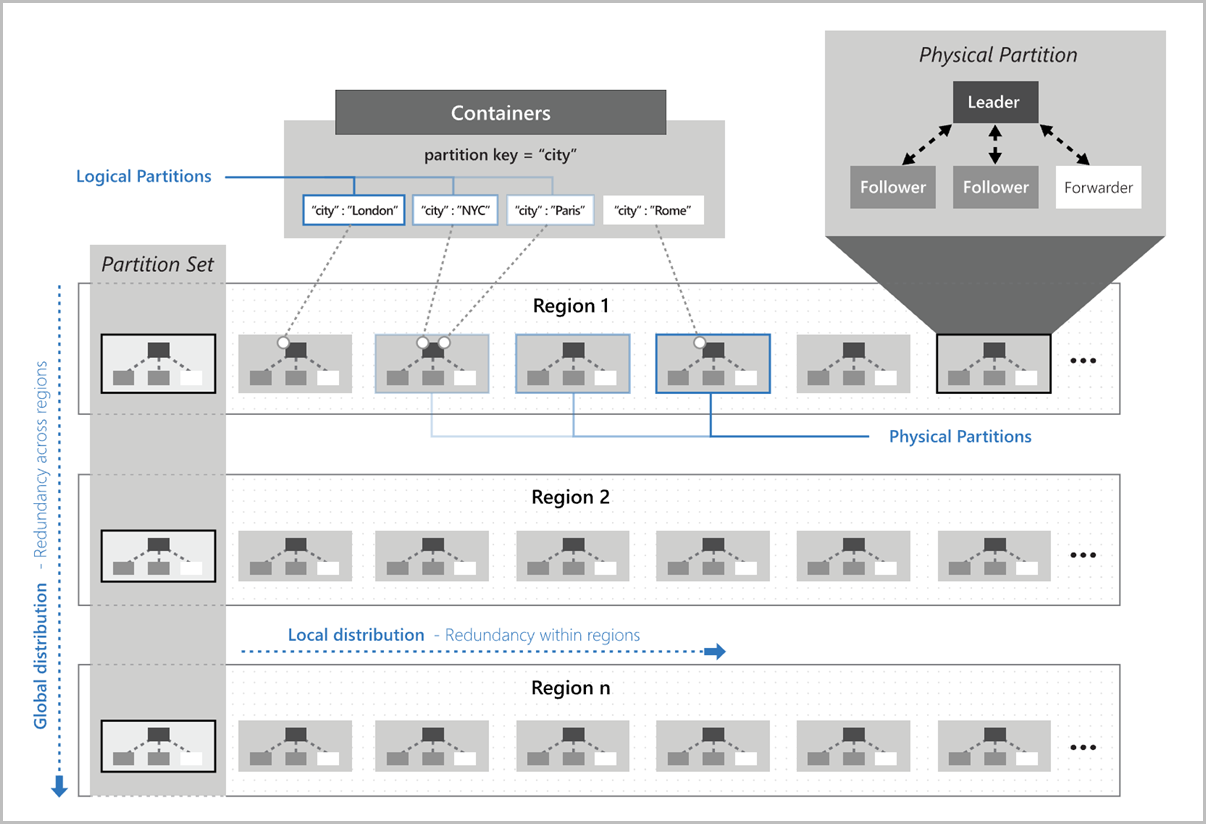
This image shows how logical partitions map to physical partitions distributed multiple-regionally. Partition set in the image refers to a group of physical partitions that manage the same logical partition keys across multiple regions:
Choose a partition key
A partition key has two components: partition key path and the partition key value. For example, consider an item { "userId" : "Andrew", "worksFor": "Microsoft" } if you choose "userId" as the partition key, the following are the two partition key components:
The partition key path (For example: "/userId"). The partition key path accepts alphanumeric and underscores (_) characters. You can also use nested objects by using the standard path notation(/).
The partition key value (For example: "Andrew"). The partition key value can be of string or numeric types.
Learn about the limits on throughput, storage, and partition key length in the Azure Cosmos DB service quotas article.
Selecting your partition key is a simple but important design choice in Azure Cosmos DB. Once you select your partition key, you can't change it in-place. If you need to change your partition key, move your data to a new container with your desired partition key.
For all containers, the partition key should:
Be a property that has a value, which doesn't change. If a property is your partition key, you can't update that property's value.
Important
Partition key values are immutable. Once an item is created, its partition key value cannot be changed in place. An item replacement operation requires the partition key to match the existing item — you cannot use it to move an item between partitions. To "move" an item, you must create a new item with the new partition key value and delete the original item. These two operations cannot be performed atomically across different logical partitions.
Contain only
Stringvalues—or convert numbers into aStringif they might exceed the boundaries of double precision numbers according to Institute of Electrical and Electronics Engineers (IEEE) 754 binary64. The Json specification explains why using numbers outside this boundary is a bad practice due to interoperability problems. These concerns are especially relevant for the partition key column because it's immutable and requires data migration to change later.Have a high cardinality. In other words, the property should have a wide range of possible values.
Spread request unit (RU) consumption and data storage evenly across all logical partitions. This spread ensures even RU consumption and storage distribution across your physical partitions.
Have values that are no larger than 2048 bytes typically, or 101 bytes if large partition keys aren't enabled. For more information, see large partition keys
If you need multi-item ACID transactions in Azure Cosmos DB, you need to use stored procedures or triggers. All JavaScript-based stored procedures and triggers are scoped to a single logical partition.
Note
If you only have one physical partition, or the number of partitions is small, for example <= 5, the value of the partition key might not be relevant. For queries, the overhead of checking each additional physical partition when the partition key is not included is 2-3 RU per physical partition. Learn more about physical partitions.
Common partition key anti-patterns
When you choose a partition key, avoid patterns that look convenient at first but can create scale or query issues later.
Using id as the partition key for general-purpose workloads
Using /id creates a 1:1 mapping between items and partition key values, which means each item is effectively its own logical partition. This pattern gives excellent write distribution and enables low-latency, low-RU point reads. However, any query that filters on properties other than id requires a cross-partition query.
Use /id when your workload is mostly point reads and writes, and you rarely run broader filters. For mixed query workloads, choose a key that also matches your filter patterns.
Using low-cardinality fields
Using fields like status, type, or country creates a limited number of logical partitions equal to the number of distinct values. This pattern often leads to uneven RU and storage distribution, and can create hot partitions under load.
Use a low-cardinality field only when data volume is small and traffic per value stays well below logical partition limits (20 GB storage and 10,000 RU/s per logical partition). Otherwise, use a property (or synthetic key) with more distinct values.
Types of partition keys
| Partitioning strategy | When to use | Pros | Cons |
|---|---|---|---|
| Regular Partition Key (for example, CustomerId, OrderId) | Use when the partition key has high cardinality and aligns with query patterns (for example, filtering by CustomerId). Suitable for workloads where queries mostly target a single customer's data (for example, retrieving all orders for a customer). | Simple to manage. Efficient queries when the access pattern matches the partition key (for example, querying all orders by CustomerId). Prevents cross-partition queries if access patterns are consistent. | Risk of hot partitions if some values (for example, a few high-traffic customers) generate more data than others. Might hit the 20-GB limit per logical partition if data volume for a specific key grows rapidly. |
| Synthetic Partition Key (for example, CustomerId + OrderDate) | Use when no single field has both high cardinality and matches query patterns. Good for write-heavy workloads where data needs to be evenly distributed across physical partitions (for example, many orders placed on the same date). | Helps distribute data evenly across partitions, reducing hot partitions (for example, distributing orders by both CustomerId and OrderDate). Spreads writes across multiple partitions and improves throughput. | Queries that only filter by one field (for example, CustomerId only) could result in cross-partition queries. Cross-partition queries can lead to higher RU consumption (2-3 RU/s extra charge for every physical partition that exists) and added latency. |
| Hierarchical Partition Key (HPK) (for example, CustomerId/OrderId, StoreId/ProductId) | Use when you need multi-level partitioning to support large-scale datasets. Ideal when queries filter on first and second levels of the hierarchy. | Helps avoid the 20-GB limit by creating multiple levels of partitioning. Efficient querying on both hierarchical levels (for example, filtering first by CustomerID, then by OrderID). Minimizes cross-partition queries for queries targeting the top level (for example, retrieving all data from a specific CustomerID). | Requires careful planning to ensure the first-level key has high cardinality and is included in most queries. More complex to manage than a regular partition key. If queries don't align with the hierarchy (for example, filtering only by OrderID when CustomerID is the first level), query performance might suffer. |
Partition keys for read-heavy containers
For most containers, these criteria are all you need to consider when choosing a partition key. For large read-heavy containers, however, you might want to choose a partition key that appears frequently as a filter in your queries. Including the partition key in the filter predicate lets queries be efficiently routed to only the relevant physical partitions.
This property is a good partition key choice if most of your workload's requests are queries and most of your queries use an equality filter on the same property. For example, if you frequently run a query that filters on UserID, then selecting UserID as the partition key would reduce the number of cross-partition queries.
If your container is small, you likely don't have enough physical partitions to worry about the performance of cross-partition queries. Most small containers in Azure Cosmos DB only require one or two physical partitions.
If your container could grow to more than a few physical partitions, then you should make sure you pick a partition key that minimizes cross-partition queries. Your container needs more than a few physical partitions if either of the following scenarios is true:
Your container has over 30,000 request units provisioned
Your container stores over 100 GB of data
Use item ID as the partition key
Note
This section primarily applies to the API for NoSQL. Other APIs, such as the API for Gremlin, don't support the unique identifier as the partition key.
If your container has a property with a wide range of possible values, it's likely a great partition key choice. An example of such a property is the item ID. For small read-heavy containers or write-heavy containers of any size, the item ID (/id) is naturally a great choice for the partition key.
The system property item ID is present in every item in your container. You might have other properties that represent a logical ID of your item. In many cases, these unique identifiers are also great partition key choices for the same reasons as the item ID.
The item ID is a great partition key choice for the following reasons:
- There are a wide range of possible values (one unique item ID per item).
- Because there's a unique item ID per item, the item ID does a great job at evenly balancing RU consumption and data storage.
- You can easily do efficient point reads since you always know an item's partition key if you know its item ID.
Consider the following caveats when selecting the item ID as the partition key:
- If the item ID is the partition key, it becomes a unique identifier for your entire container. You can't create items with duplicate identifiers.
- If you have a read-heavy container with many physical partitions, queries are more efficient if they have an equality filter with the item ID.
- Stored procedures or triggers can't target multiple logical partitions.