Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article explains how to update an existing index in Azure AI Search with schema changes or content changes through incremental indexing.
Tip
To update documents immediately, skip to Update content. For schema changes, see Update an index schema.
Prerequisites
An Azure AI Search service (any tier). Create a service or find an existing one.
An existing search index with documents. This article assumes you already created an index and loaded documents.
Permissions to update or rebuild indexes:
- Key-based authentication: An admin API key for your search service.
- Role-based authentication: Search Index Data Contributor role for document updates, or Search Service Contributor for schema changes.
For SDK development, install the Azure Search client library:
- Python: azure-search-documents
- .NET: Azure.Search.Documents
- JavaScript: @azure/search-documents
- Java: azure-search-documents
Tip
During active development, it's common to drop and rebuild indexes when iterating over index design. Work with a small representative sample of data so that reindexing goes faster. For production schema changes, create and test a new index side by side, then use an index alias to swap indexes without changing application code.
Update content
Incremental indexing and synchronizing an index against changes in source data is fundamental to most search applications. This section explains the workflow for adding, removing, or overwriting the content of a search index through the REST API, but the Azure SDKs provide equivalent functionality.
The body of the request contains one or more documents to be indexed. Within the request, each document in the index is:
- Identified by a unique case-sensitive key.
- Associated with an action: "upload", "delete", "merge", or "mergeOrUpload".
- Populated with a set of key/value pairs for each field that you're adding or updating.
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
Reference: Documents - Index
First, use the APIs for loading documents, such as Documents - Index (REST) or an equivalent API in the Azure SDKs. For more information about indexing techniques, see Load documents.
For a large update, batching (up to 1,000 documents per batch, or about 16 MB per batch, whichever limit comes first) is recommended and significantly improves indexing performance.
Set the
@search.actionparameter on the API to determine the effect on existing documents. UsemergeOrUploadfor incremental updates (most common),deleteto remove documents, ormergefor partial field updates on existing documents.Action Effect delete Removes the entire document from the index. If you want to remove an individual field, use merge instead, setting the field in question to null. Deleted documents and fields don't immediately free up space in the index. Every few minutes, a background process performs the physical deletion. Whether you use the Azure portal or an API to return index statistics, you can expect a small delay before the deletion is reflected in the Azure portal and through APIs. For more information, see Delete documents in a search index. merge Updates a document that already exists, and fails a document that can't be found. Merge replaces existing values. For this reason, be sure to check for collection fields that contain multiple values, such as fields of type Collection(Edm.String). For example, if atagsfield starts with a value of["budget"]and you execute a merge with["economy", "pool"], the final value of thetagsfield is["economy", "pool"]. It won't be["budget", "economy", "pool"].
The same behavior applies to complex collections. If the document contains a complex collection field named Rooms with a value of[{ "Type": "Budget Room", "BaseRate": 75.0 }], and you execute a merge with a value of[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }], the final value of the Rooms field will be[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }]. It won't append or merge new and existing values.mergeOrUpload Behaves like merge if the document exists, and upload if the document is new. This is the most common action for incremental updates. upload Similar to an "upsert" where the document is inserted if it's new, and updated or replaced if it exists. If the document is missing values that the index requires, the document field's value is set to null.
Queries continue to run during indexing, but if you're updating or removing existing fields, you can expect mixed results and a higher incidence of throttling.
Note
There are no ordering guarantees for which action in the request body is executed first. It's not recommended to have multiple "merge" actions associated with the same document in a single request body. If there are multiple "merge" actions required for the same document, perform the merging client-side before updating the document in the search index.
Responses
Status code 200 is returned for a successful response, meaning that all items have been stored durably and will start to be indexed. Indexing runs in the background and makes new documents available (that is, queryable and searchable) a few seconds after the indexing operation completed. The specific delay depends on the load on the service.
Successful indexing is indicated by the status property being set to true for all items, as well as the statusCode property being set to either 201 (for newly uploaded documents) or 200 (for merged or deleted documents):
{
"value": [
{
"key": "unique_key_of_new_document",
"status": true,
"errorMessage": null,
"statusCode": 201
},
{
"key": "unique_key_of_merged_document",
"status": true,
"errorMessage": null,
"statusCode": 200
},
{
"key": "unique_key_of_deleted_document",
"status": true,
"errorMessage": null,
"statusCode": 200
}
]
}
Status code 207 is returned when at least one item wasn't successfully indexed. Items that haven't been indexed have the status field set to false. The errorMessage and statusCode properties indicate the reason for the indexing error:
{
"value": [
{
"key": "unique_key_of_document_1",
"status": false,
"errorMessage": "The search service is too busy to process this document. Please try again later.",
"statusCode": 503
},
{
"key": "unique_key_of_document_2",
"status": false,
"errorMessage": "Document not found.",
"statusCode": 404
},
{
"key": "unique_key_of_document_3",
"status": false,
"errorMessage": "Index is temporarily unavailable because it was updated with the 'allowIndexDowntime' flag set to 'true'. Please try again later.",
"statusCode": 422
}
]
}
The errorMessage property indicates the reason for the indexing error if possible.
The following table explains the various per-document status codes that can be returned in the response. Some status codes indicate problems with the request itself, while others indicate temporary error conditions. The latter you should retry after a delay.
| Status code | Meaning | Retryable | Notes |
|---|---|---|---|
| 200 | Document was successfully modified or deleted. | n/a | Delete operations are idempotent. That is, even if a document key doesn't exist in the index, attempting a delete operation with that key results in a 200 status code. |
| 201 | Document was successfully created. | n/a | |
| 400 | There was an error in the document that prevented it from being indexed. | No | The error message in the response indicates what is wrong with the document. |
| 404 | The document couldn't be merged because the given key doesn't exist in the index. | No | This error doesn't occur for uploads since they create new documents, and it doesn't occur for deletes because they're idempotent. |
| 409 | A version conflict was detected when attempting to index a document. | Yes | This can happen when you're trying to index the same document more than once concurrently. |
| 422 | The index is temporarily unavailable because it was updated with the 'allowIndexDowntime' flag set to 'true'. | Yes | |
| 429 | Too Many Requests | Yes | If you get this error code during indexing, it usually means that you're running low on storage. As you near storage limits, the service can enter a state where you can't add or update until you delete some documents. For more information, see Plan and manage capacity if you want more storage, or free up space by deleting documents. |
| 503 | Your search service is temporarily unavailable, possibly due to heavy load. | Yes | Your code should wait before retrying in this case or you risk prolonging the service unavailability. |
If your client code frequently encounters a 207 response, one possible reason is that the system is under load. You can confirm this by checking the statusCode property for 503. If the statusCode is 503, we recommend throttling indexing requests. Otherwise, if indexing traffic doesn't subside, the system could start rejecting all requests with 503 errors.
Status code 429 indicates that you have exceeded your quota on the number of documents per index. You must either create a new index or upgrade for higher capacity limits.
Note
When you upload DateTimeOffset values with time zone information to your index, Azure AI Search normalizes these values to UTC. For example, 2024-01-13T14:03:00-08:00 is stored as 2024-01-13T22:03:00Z. If you need to store time zone information, add an extra column to your index for this data point.
Tips for incremental indexing
Indexers automate incremental indexing. If you can use an indexer, and if the data source supports change tracking, you can run the indexer on a recurring schedule to add, update, or overwrite searchable content so that it's synchronized to your external data.
If you're making index calls directly through the push API, use
mergeOrUploadas the search action.The payload must include the keys or identifiers of every document you want to add, update, or delete.
If your index includes vector fields and you set the
storedproperty to false, make sure you provide the vector in your partial document update, even if the value is unchanged. A side effect of settingstoredto false is that vectors are dropped on a reindexing operation. Providing the vector in the documents payload prevents this from happening.To update the contents of simple fields and subfields in complex types, list only the fields you want to change. For example, if you only need to update a description field, the payload should consist of the document key and the modified description. Omitting other fields retains their existing values.
To merge inline changes into string collection, provide the entire value. Recall the
tagsfield example from the previous section. New values overwrite the old values for an entire field, and there's no merging within the content of a field.
Here's a REST API example demonstrating these tips:
### Get Stay-Kay City Hotel by ID
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
### Change the description, city, and tags for Stay-Kay City Hotel
POST {{baseUrl}}/indexes/hotels-vector-quickstart/docs/search.index?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"value": [
{
"@search.action": "mergeOrUpload",
"HotelId": "1",
"Description": "I'm overwriting the description for Stay-Kay City Hotel.",
"Tags": ["my old item", "my new item"],
"Address": {
"City": "Gotham City"
}
}
]
}
### Retrieve the same document, confirm the overwrites and retention of all other values
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Reference: Documents - Index, Lookup Document
SDK examples
The following examples show how to update documents using the Azure SDKs.
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
# Set up the client
service_name = "<your-search-service-name>"
index_name = "hotels-sample"
api_key = "<your-admin-api-key>"
endpoint = f"https://{service_name}.search.azure.cn"
credential = AzureKeyCredential(api_key)
client = SearchClient(endpoint=endpoint, index_name=index_name, credential=credential)
# Update documents using merge_or_upload
documents = [
{
"HotelId": "1",
"Description": "Updated description for the hotel.",
"Tags": ["updated", "renovated"]
}
]
result = client.merge_or_upload_documents(documents=documents)
print(f"Updated {len(result)} document(s)")
Reference: SearchClient, merge_or_upload_documents
Update an index schema
The index schema defines the physical data structures created on the search service, so there aren't many schema changes that you can make without incurring a full rebuild.
Updates with no rebuild
The following list enumerates the schema changes that can be introduced seamlessly into an existing index. Generally, the list includes new fields and functionality used during query execution.
- Add an index description
- Add a new field
- Set the
retrievableattribute on an existing field - Update
searchAnalyzeron a field having an existingindexAnalyzer - Add a new analyzer definition in an index (which can be applied to new fields)
- Add, update, or delete scoring profiles
- Add, update, or delete synonym maps
- Add, update, or delete semantic configurations
- Add, update, or delete CORS settings
The order of operations is:
Revise the schema with updates from the previous list.
Update index schema on the search service.
Update index content to match your revised schema if you added a new field. For all other changes, the existing indexed content is used as-is.
When you update an index schema to include a new field, existing documents in the index are given a null value for that field. On the next indexing job, values from external source data replace the nulls added by Azure AI Search.
There should be no query disruptions during the updates, but query results will vary as the updates take effect.
Updates requiring a rebuild
Some modifications require an index drop and rebuild, replacing a current index with a new one.
| Action | Description |
|---|---|
| Delete a field | To physically remove all traces of a field, you have to rebuild the index. When an immediate rebuild isn't practical, you can modify application code to redirect access away from an obsolete field or use the searchFields and select query parameters to choose which fields are searched and returned. Physically, the field definition and contents remain in the index until the next rebuild, when you apply a schema that omits the field in question. |
| Change a field definition | Revisions to a field name, data type, or specific index attributes (searchable, filterable, sortable, facetable) require a full rebuild. |
| Assign an analyzer to a field | Analyzers are defined in an index, assigned to fields, and then invoked during indexing to inform how tokens are created. You can add a new analyzer definition to an index at any time, but you can only assign an analyzer when the field is created. This is true for both the analyzer and indexAnalyzer properties. The searchAnalyzer property is an exception (you can assign this property to an existing field). |
| Update or delete an analyzer definition in an index | You can't delete or change an existing analyzer configuration (analyzer, tokenizer, token filter, or char filter) in the index unless you rebuild the entire index. |
| Add a field to a suggester | If a field already exists and you want to add it to a Suggesters construct, rebuild the index. |
| Switch tiers | In-place upgrades aren't supported. If you require more capacity, create a new service and rebuild your indexes from scratch. To help automate this process, you can use a code sample that backs up your index to a series of JSON files. You can then recreate the index in a search service you specify. |
The order of operations is:
Get an index definition in case you need it for future reference, or to use as the basis for a new version.
Consider using a backup and restore solution to preserve a copy of index content. There are solutions in C# and in Python. We recommend the Python version because it's more up to date.
If you have capacity on your search service, keep the existing index while creating and testing the new one.
Drop the existing index. Queries targeting the index are immediately dropped. Remember that deleting an index is irreversible, destroying physical storage for the fields collection and other constructs.
Post a revised index, where the body of the request includes changed or modified field definitions and configurations.
Load the index with documents from an external source. Documents are indexed using the field definitions and configurations of the new schema.
When you create the index, physical storage is allocated for each field in the index schema, with an inverted index created for each searchable field and a vector index created for each vector field. Fields that aren't searchable can be used in filters or expressions, but don't have inverted indexes and aren't full-text or fuzzy searchable. On an index rebuild, these inverted indexes and vector indexes are deleted and recreated based on the index schema you provide.
To minimize disruption to application code, consider creating an index alias. Application code references the alias, but you can update the name of the index that the alias points to.
Add an index description
An index has a description property that you can specify and use when a system must access several indexes and make a decision based on the description. Consider a Model Context Protocol (MCP) server that must pick the correct index at run time. The decision can be based on the description rather than on the index name alone.
An index description is a schema update, and you can add it without having to rebuild the entire index.
- String length is 4,000 characters maximum.
- Content must be human-readable, in Unicode. Your use-case should determine which language to use.
You can add an index description through the Azure portal, the latest stable REST API, or an Azure SDK package that provides the feature.
The Azure portal supports the latest preview API.
Go to your search service in the Azure portal.
Under Search management > Indexes, select an index.
Select Edit JSON.
Insert
"description", followed by the description. The value must be less than 4,000 characters and in Unicode.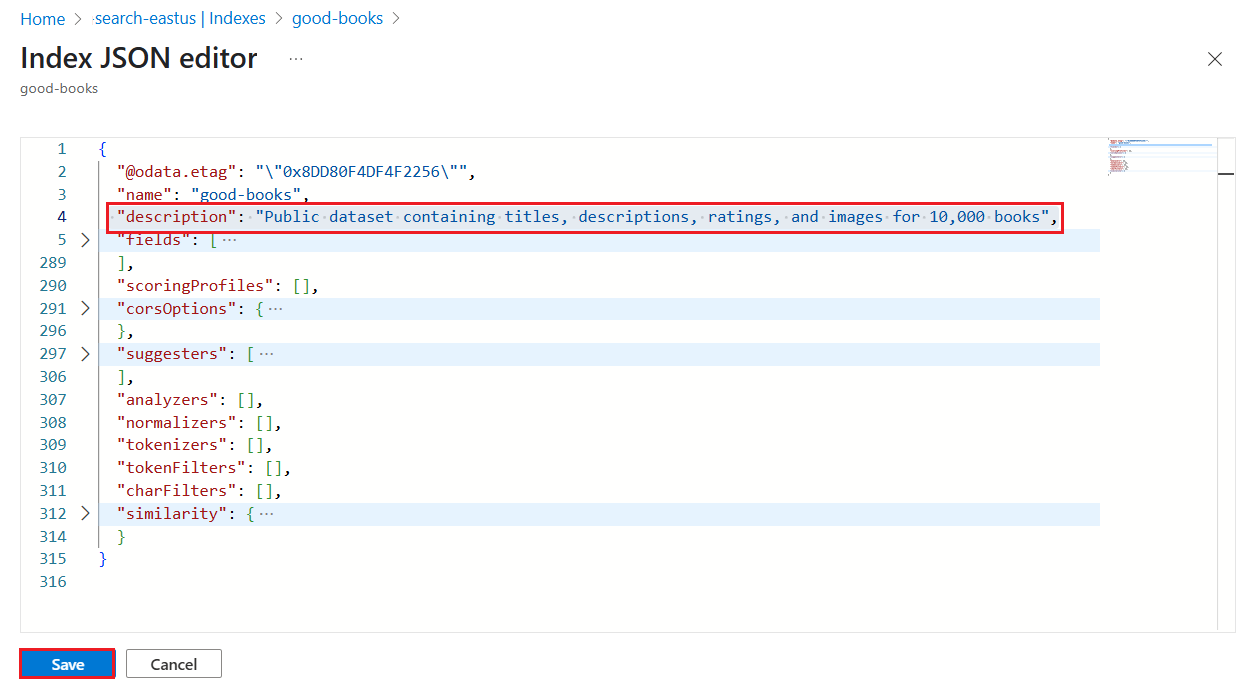
Save the index.
Balancing workloads
Indexing doesn't run in the background, but the search service will balance any indexing jobs against ongoing queries. During indexing, you can monitor query requests in the Azure portal to ensure queries are completing in a timely manner.
If indexing workloads introduce unacceptable levels of query latency, conduct performance analysis and review these performance tips for potential mitigation.
Check for updates
You can begin querying an index as soon as the first document is loaded. If you know a document's ID, the Lookup Document REST API returns the specific document. For broader testing, you should wait until the index is fully loaded, and then use queries to verify the context you expect to see.
You can use Search Explorer or a REST client to check for updated content.
If you added or renamed a field, use select to return that field:
"search": "*",
"select": "document-id, my-new-field, some-old-field",
"count": true
The Azure portal provides index size and vector index size. You can check these values after updating an index, but remember to expect a small delay as the service processes the change and to account for portal refresh rates, which can be a few minutes.
Troubleshoot reindexing
The following table lists common issues when updating or rebuilding indexes and how to resolve them.
| Issue | Cause | Resolution |
|---|---|---|
| 207 response with mixed results | Some documents succeeded, others failed. | Check statusCode for each document in response. If 503, throttle requests and retry. |
| 409 Version conflict | Concurrent updates to same document. | Serialize updates to the same document or implement retry with exponential backoff. |
| 429 Too Many Requests | Storage quota exceeded or too many concurrent requests. | Delete documents to free space, or upgrade service tier for more capacity. |
| 503 Service unavailable | Service under heavy load. | Wait and retry with exponential backoff. Consider reducing batch size. |
| Document count unchanged after delete | Deletion is asynchronous. | Wait 2-3 minutes for background process to complete physical deletion. |
| New field returns null | Field added to schema but documents not reindexed. | Run indexer or push updated documents to populate the new field. |
| Schema change rejected | Attempted incompatible change (rename, type change). | Drop and rebuild the index. Use index alias to minimize downtime. |