Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文介绍如何在 Azure HDInsight 中设置和配置 Apache Hadoop、Apache Spark、Apache Kafka、Interactive Query 或 Apache HBase。 另外,了解如何自定义群集,并将它们加入域以提高安全性。
Hadoop 群集由用于对任务进行分布式处理的多个虚拟机(VM,也称为节点)组成。 HDInsight 处理各个节点安装和配置的实现详细信息。 你只需提供常规配置信息。
重要
创建群集后便开始 HDInsight 群集计费,删除群集后停止计费。 按分钟计费,因此当你不再需要使用群集时,应始终将其删除。 了解如何删除群集。
如果同时使用多个群集,则需创建虚拟网络。 如果使用 Spark 群集,则还需要使用 Hive Warehouse Connector。 有关详细信息,请参阅 为 Azure HDInsight 规划虚拟网络 和 使用 Hive Warehouse Connector 集成 Apache Spark 和 Apache Hive。
群集设置方法
下表显示了可用于设置 HDInsight 群集的不同方法。
| 群集创建方法 | web 浏览器 | 命令行 | REST API | SDK |
|---|---|---|---|---|
| Azure 门户 | ✅ | |||
| Azure Data Factory | ✅ | ✅ | ✅ | ✅ |
| Azure CLI | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Azure Resource Manager 模板 | ✅ |
本文介绍如何在 Azure 门户中完成设置,可在其中创建 HDInsight 群集。
基础
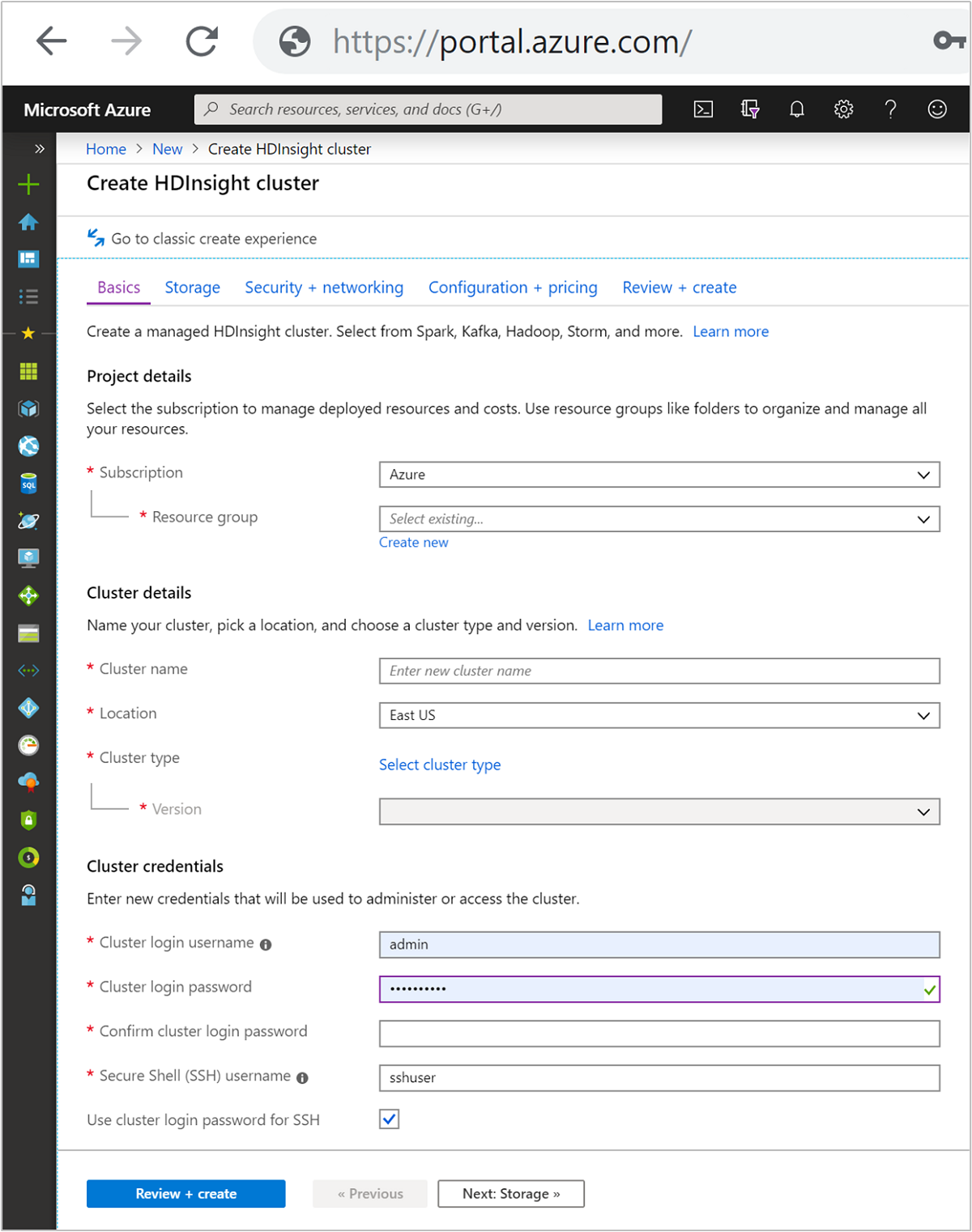
项目详细信息
Azure Resource Manager帮助您将应用内的资源作为一个组进行管理,这个组称为 Azure 资源组。 可以通过单个协调的操作来部署、更新、监视或删除应用程序的所有资源。
群集详细信息
群集详细信息包括名称、区域、类型和版本。
群集名称
HDInsight 群集名称具有以下限制:
- 允许的字符:a-z、0-9、A-Z
- 最大长度:59
- 保留名称:应用程序
- Cluster 命名:范围适用于所有 Azure 服务的所有订阅。 该群集名称必须全球唯一。 前六个字符在虚拟网络中必须唯一。
区域
不需要显式指定群集位置。 群集与默认存储在同一位置。 若要获取受支持区域的列表,请选择 HDInsight 定价中的“区域”下拉列表。
群集类型
在下面的表中,HDInsight 目前提供几种群集类型,每种类型都具有一组用于提供特定功能的组件。
重要
HDInsight 群集以多种类型提供,每种类型适用于单个工作负荷或技术。 没有支持的方法能够创建结合多种类型的群集,例如在一个群集中包含 HBase。 如果解决方案需要分布在多个 HDInsight 群集类型的技术,Azure虚拟网络可以连接所需的群集类型。
| 群集类型 | 功能 |
|---|---|
| Hadoop | 批量查询和分析存储数据。 |
| HBase | 处理大量无架构、NoSQL数据。 |
| 交互式查询 | 针对交互式和更快速 Hive 查询的内存缓存。 |
| Kafka | 分布式流式处理平台,可用于构建实时流数据管道和应用程序。 |
| Spark | 内存中处理、交互式查询、微批流处理。 |
版本
选择此群集的 HDInsight 版本。 有关详细信息,请参阅支持的 HDInsight 版本。
群集凭据
使用 HDInsight 群集时,可以在群集创建期间配置两个用户帐户:
- Cluster 登录用户名:默认用户名为admin。它在 Azure 门户中使用基本配置。 它也称为“群集用户”或“HTTP 用户”。
- 安全外壳 (SSH) 用户名:用于通过 SSH 连接到群集。 有关详细信息,请参阅 将 SSH 与 HDInsight 配合使用。
HTTP 用户名具有以下限制:
- 允许的特殊字符:_ 和 @
- 不允许使用的字符:#;."',/:!*?$(){}[]<>|&--=+%~^space
- 最大长度:20
SSH 用户名具有以下限制:
- 允许的特殊字符:_ 和 @
- 不允许使用的字符:#;."',/:!*?$(){}[]<>|&--=+%~^space
- 最大长度:64
- 保留名称:hadoop、users、oozie、hive、mapred、ambari-qa、zookeeper、tez、hdfs、sqoop、yarn、hcat、ams、hbase、administrator、admin、user、user1、test、user2、test1、user3、admin1、1、123、a、actuser、adm、admin2、aspnet、backup、console、David、guest、John、owner、root、server、sql、support、support_388945a0、sys、test2、test3、user4、user5、spark
存储
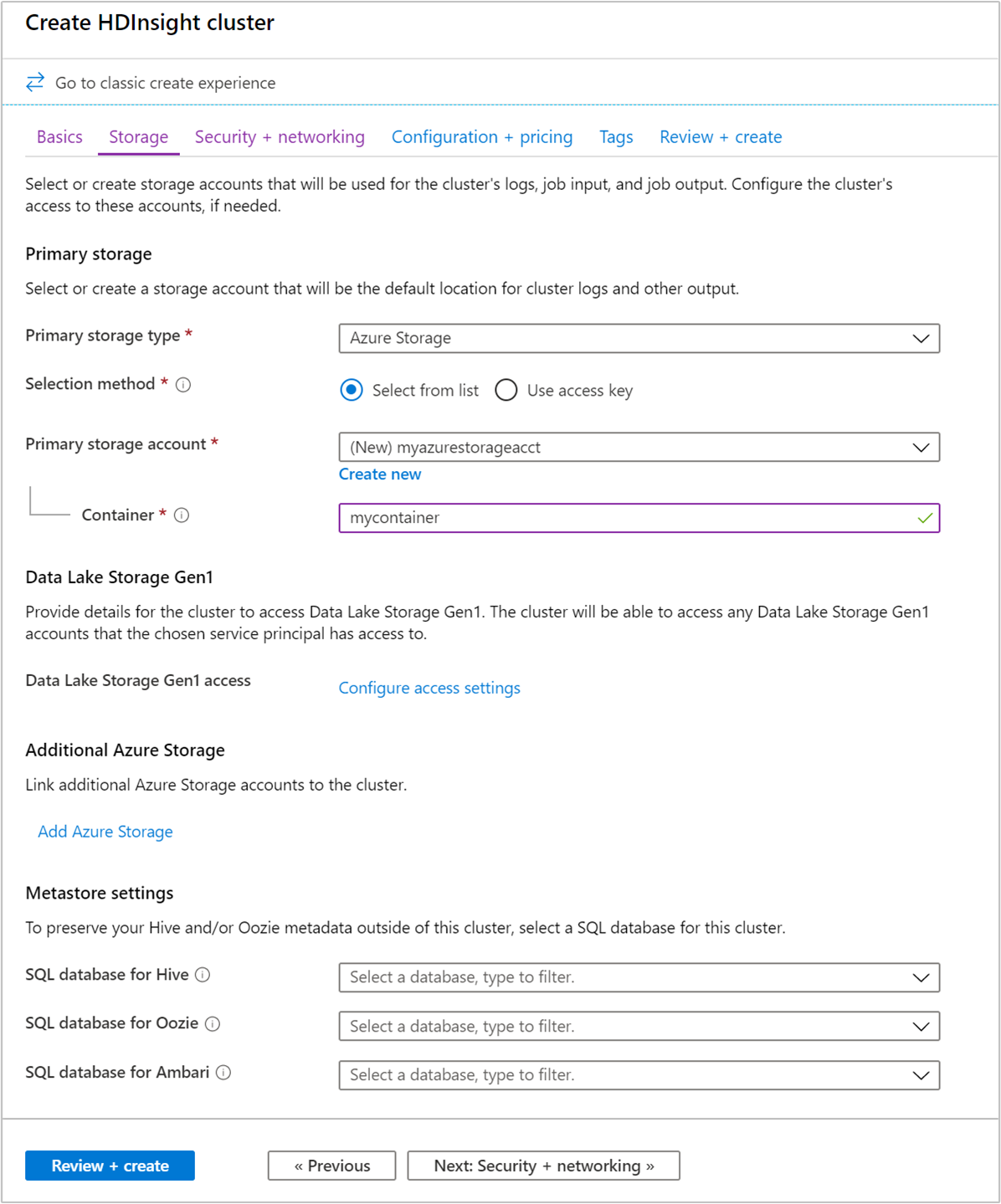
虽然 Hadoop 的本地安装使用 Hadoop 分布式文件系统 (HDFS) 作为群集上的存储,但在云中,会使用连接到群集的存储终结点。 使用云存储空间意味着可以安全删除用于计算的 HDInsight 群集,同时仍可保留数据。
HDInsight 群集可以使用以下存储选项:
- Azure Data Lake Storage Gen2
- Azure Storage常规用途 v2
- Azure Storage Block blob(仅支持作为辅助存储)
不支持在 HDInsight 群集之外的其他位置使用其他存储帐户。
在配置过程中,对于默认存储终结点,请指定存储帐户的 blob 容器或数据湖存储。 默认存储包含应用程序日志和系统日志。 (可选)可以指定群集可以访问的更多链接存储帐户和Data Lake Storage帐户。 HDInsight 群集和依赖存储帐户必须位于同一Azure位置。
注意
需要安全传输的功能强制所有请求通过安全连接到达您的帐户。 仅 HDInsight 群集 3.6 或更高版本支持此功能。 有关详细信息,请参阅 在 Azure HDInsight 中创建具有安全传输存储帐户的 Apache Hadoop 群集。
创建群集后不要启用安全存储传输,因为使用存储帐户可能会导致错误。 最好使用已启用安全传输的存储帐户创建新群集。
HDInsight 不会将存储中存储的数据从一个区域自动传输、移动或复制到另一区域。
元存储设置
你可以创建可选的 Hive 或 Apache Oozie 元存储。 并非所有群集类型都支持元存储,Azure Synapse Analytics与元存储不兼容。
有关详细信息,请参阅 使用 Azure HDInsight 中的外部元数据存储。
创建自定义元存储时,请不要在数据库名称中使用破折号、连字符或空格。 这些字符可能导致群集创建过程失败。
适用于 Hive 的 SQL 数据库
如果希望在删除 HDInsight 群集后保留 Hive 表,请使用自定义元存储。 这样,您可以将元存储连接到另一个 HDInsight 群集。
为一个 HDInsight 群集版本创建的 HDInsight 元存储不能在不同的 HDInsight 群集版本之间共享。 有关 HDInsight 版本的列表,请参阅支持的 HDInsight 版本。
可以使用托管标识对 Hive 的 SQL 数据库进行身份验证。 有关详细信息,请参阅在 HDInsight 中使用托管标识进行 SQL 数据库身份验证。
默认元数据存储提供一个 SQL 数据库,具有基本层 5 DTU 限制(不可升级)。 它适合用于基础测试目的。 对于大型工作负载或生产工作负载,建议迁移到外部元存储。
适用于 Oozie 的 SQL 数据库
若要提高使用 Oozie 时的性能,请使用自定义元存储。 删除群集后,元存储也可提供对 Oozie 作业数据的访问权限。
安全性 + 网络
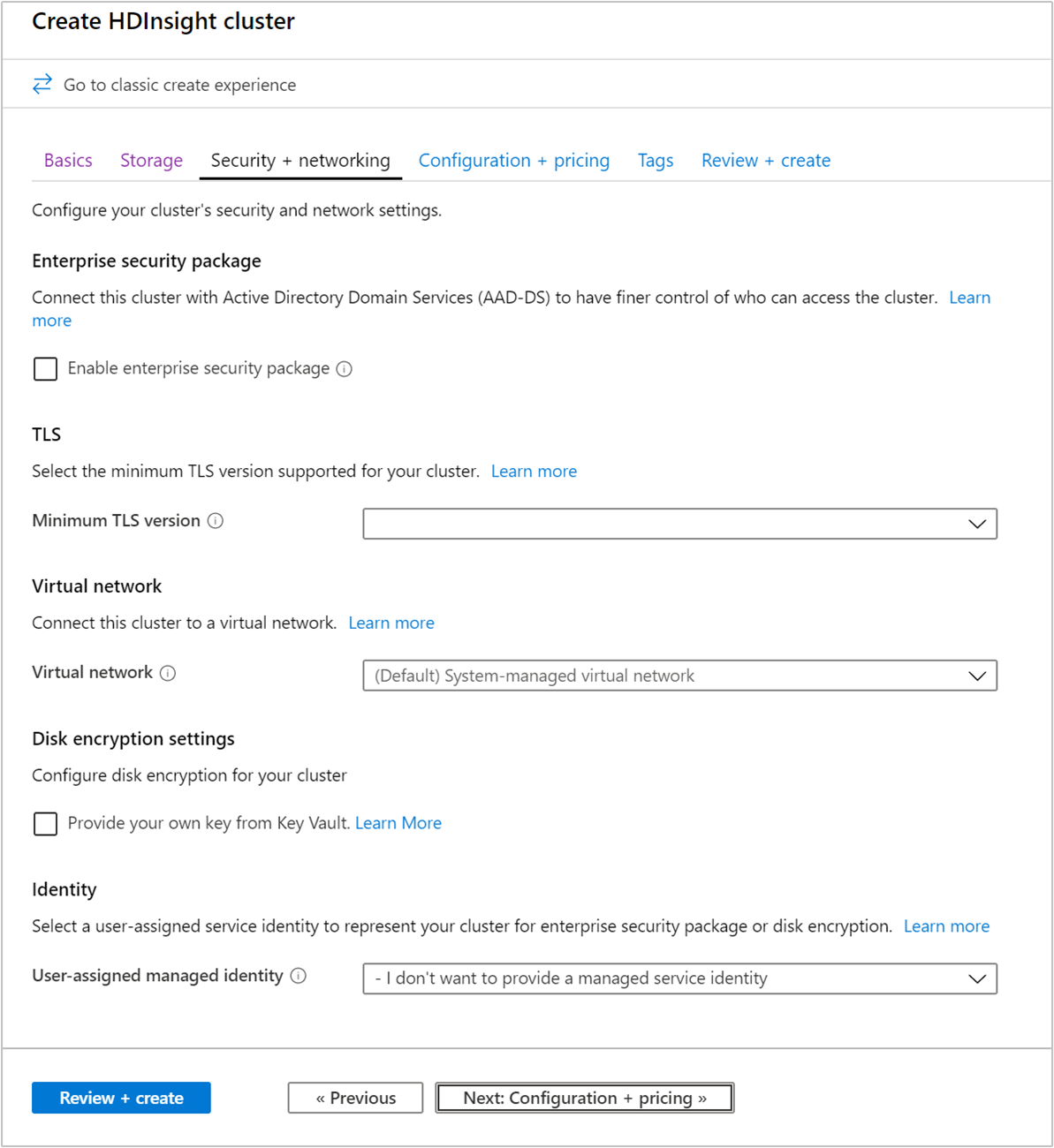
企业安全套件
对于 Hadoop、Spark、HBase、Kafka 和 Interactive Query 群集类型,可以选择启用企业安全包。 此包提供了使用 Apache Ranger 并与 Azure Entra 集成来设置更安全的群集设置的选项。 有关详细信息,请参阅 Azure HDInsight 中的企业安全性概述。
借助企业安全包,可以将 HDInsight 与 Microsoft Entra 和 Apache Ranger 集成。 可以使用企业安全性套餐创建多个用户。
有关如何创建已加入域的 HDInsight 群集的详细信息,请参阅创建已加入域的 HDInsight 沙盒环境。
传输层安全性
有关详细信息,请参阅传输层安全性。
虚拟网络
如果解决方案需要分布在多个 HDInsight 群集类型的技术,Azure虚拟网络可以连接所需的群集类型。 此配置允许群集以及部署到群集的任何代码直接相互通信。
有关将 Azure 虚拟网络与 HDInsight 配合使用的详细信息,请参阅规划 HDInsight 的虚拟网络。
在 Azure 虚拟网络中使用两种群集类型的示例,请参阅 使用 Apache Spark 结构化流式处理与 Apache Kafka。 有关在 HDInsight 中使用虚拟网络的详细信息(包括虚拟网络的特定配置要求),请参阅规划 HDInsight 的虚拟网络。
磁盘加密设置
有关详细信息,请参阅客户管理的密钥磁盘加密。
Kafka REST 代理
此设置仅适用于 Kafka 群集类型。 有关详细信息,请参阅使用 REST 代理。
身份
有关详细信息,请参阅 Azure HDInsight 中的托管身份。
配置 + 定价
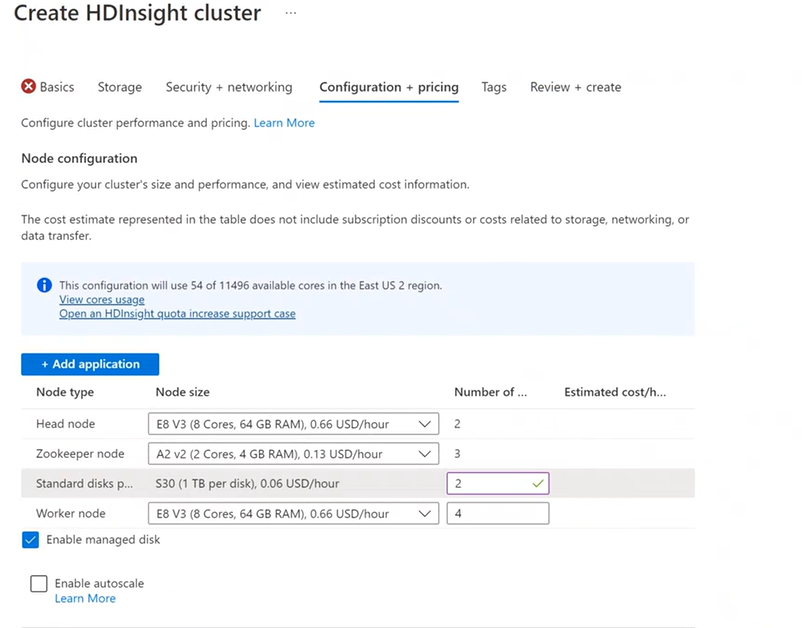
只要群集存在,就会产生节点使用费。 创建群集后便开始计费,删除群集后停止计费。 群集无法解分配或暂停。
节点配置
每个群集类型有自身的节点数目、节点术语和默认的 VM 大小。 下表中的括号内列出了每个节点类型的节点数目。
| 类型 | 节点 | 图示 |
|---|---|---|
| Hadoop | 头节点 (2)、工作器节点 (1+) |
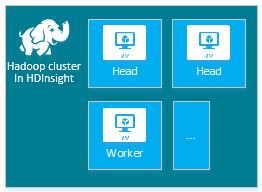
|
| HBase | 头服务器 (2),区域服务器 (1+),主控/ZooKeeper 节点 (3) |
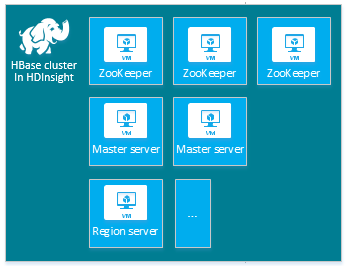
|
| Spark | 头节点 (2),工作器节点 (1+),ZooKeeper 节点 (3)(对于 A1 ZooKeeper VM 大小免费) |
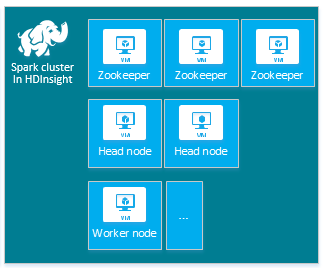
|
有关详细信息,请参阅群集的默认节点配置和 VM 大小。
HDInsight 群集的成本取决于节点数和节点的 VM 大小。
不同群集类型具有不同的节点类型、节点数和节点大小:
Hadoop 群集类型的默认配置:
- 两个头节点
- 四个工作节点
如果你想要试用 HDInsight,我们建议你使用一个工作器节点。 有关 HDInsight 定价的详细信息,请参阅 HDInsight 定价。
注意
群集大小限制因Azure订阅而异。 请联系 Azure 计费支持团队以提高限制。
使用 Azure 门户配置群集时,可以通过 Configuration + 定价选项卡获取节点大小。在门户中,还可以查看与不同节点大小关联的成本。
虚拟机大小
部署群集时,根据计划部署的解决方案选择计算资源。 以下 VM 用于 HDInsight 群集:
- A 系列和 D1-4 系列 VM:常规用途 Linux VM 大小
- D11-14 系列 VM:内存优化 Linux VM 大小
若要了解在使用不同 SDK 或Azure PowerShell创建群集时应用于指定 VM 大小的值,请参阅用于 HDInsight 群集的 VM 大小。 请在这个链接文章的多个表格中使用“大小”列中的值。
重要
如果需要群集中有 32 个以上的辅助节点,则必须选择至少具有 8 个核心和 14 GB RAM 的头节点大小。
有关详细信息,请参阅 VM 大小。 有关不同大小的定价信息,请参阅 HDInsight 定价。
磁盘附件
注意
添加的磁盘仅针对节点管理器本地目录而不是数据节点目录进行配置。
HDInsight 群集附带基于版本的预定义磁盘空间。 运行某些大型应用程序可能会导致磁盘空间不足(出现磁盘已满错误 LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE)和作业失败。
可以使用本地目录新功能 NodeManager 将更多磁盘添加到群集。 创建 Hive 和 Spark 群集时,可以选择磁盘数并将其添加到工作器节点。 所选磁盘可用作 1 TB,每个都是 NodeManager 本地目录的一部分。
- 在“配置 + 定价”选项卡上,选择“启用托管磁盘”。
- 在“标准磁盘”中,输入磁盘数。
- 选择您的工作节点。
你可以在“群集配置”下的“查看 + 创建”选项卡中验证磁盘数量。
添加应用程序
可在基于 Linux 的 HDInsight 群集上安装 HDInsight 应用程序。 可以使用由Azure或第三方提供的应用程序,或者开发的应用程序。 有关详细信息,请参阅 在 Azure HDInsight 上安装第三方 Apache Hadoop 应用程序。
大多数 HDInsight 应用程序安装在空边缘节点上。 空边缘节点是安装并配置了与头节点中相同的客户端工具的 Linux VM。 可以使用该边缘节点来访问群集、测试客户端应用程序和托管客户端应用程序。 有关详细信息,请参阅在 HDInsight 中使用空边缘节点。
脚本操作
可以在创建期间通过使用脚本安装更多组件或自定义群集配置。 此类脚本通过 script 操作调用,这是可从 Azure 门户、HDInsight Windows PowerShell cmdlet 或 HDInsight .NET SDK 中使用的配置选项。 有关详细信息,请参阅使用脚本操作自定义 HDInsight 群集。
某些本机Java组件(如 Apache Mahout 和级联)可以在群集中作为Java存档(JAR)文件运行。 可以使用 Hadoop 作业提交机制将这些 JAR 文件分发到存储,并将其提交到 HDInsight 群集。 有关详细信息,请参阅以编程方式提交 Apache Hadoop 作业。
注意
如果在将 JAR 文件部署到 HDInsight 群集或调用 HDInsight 群集上的 JAR 文件时出现问题,请联系 Azure Support。
HDInsight 不支持级联,并且不符合Azure支持的条件。 有关支持的组件的列表,请参阅 HDInsight 提供的群集版本有哪些新功能?。
在创建过程中,有时需要配置以下配置文件:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
有关详细信息,请参阅使用 Bootstrap 自定义 HDInsight 群集。