Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
本文包含有关如何排查 Azure Synapse Analytics 中无服务器 SQL 池最频繁的问题的信息。
若要了解有关 Azure Synapse Analytics 的详细信息,请查看 Overview 中的主题。
Synapse Studio
Synapse Studio是一种易于使用的工具,可通过浏览器访问数据,而无需安装数据库访问工具。 Synapse Studio不设计为读取大量数据或完全管理 SQL 对象。
无服务器 SQL 池在 Synapse Studio 中灰显
如果Synapse Studio无法建立与无服务器 SQL 池的连接,你会注意到无服务器 SQL 池灰显或显示状态Offline。
通常,此问题是以下两种原因之一造成的:
- 网络阻止与 Azure Synapse Analytics 后端通信。 最常见的情况是 TCP 端口 1443 被阻止。 若要使无服务器 SQL 池正常工作,请取消阻止此端口。 其他问题可能也会阻止无服务器 SQL 池运行。 有关详细信息,请参阅故障排除指南。
- 你无权登录到无服务器 SQL 池。 若要获得访问权限,Azure Synapse 工作区管理员必须将你添加到工作区管理员角色或 SQL 管理员角色。 有关详细信息,请参阅 Azure Synapse access control。
WebSocket 连接意外关闭
查询可能会因错误消息而失败。Websocket connection was closed unexpectedly. 该消息意味着您的浏览器与 Synapse Studio 的连接由于网络问题而中断。
- 若要解决此问题,请重新运行查询。
- 请尝试使用 Visual Studio Code 的 MSSQL 扩展或 SQL Server Management Studio,而不是 Synapse Studio,用于进行相同查询的进一步调查。
- 如果你的环境中经常出现此消息,请向网络管理员求助。 还可以检查防火墙设置,并查看故障排除指南。
- 如果问题仍然存在,请通过 Azure门户 创建 支持请求。
无服务器数据库未显示在 Synapse Studio
如果看不到在无服务器 SQL 池中创建的数据库,请检查是否启动了无服务器 SQL 池。 如果无服务器 SQL 池处于停用状态,则不会显示数据库。 对无服务器 SQL 池执行任何查询(例如 SELECT 1)以将其激活,使数据库出现。
Synapse 无服务器 SQL 池显示为不可用
错误的网络配置通常是导致此行为的原因。 请确保正确配置了端口。 如果使用防火墙或专用终结点,请检查它们的设置。
最后,请确保授予了适当的角色且未撤销这些角色。
无法创建新数据库,因为请求将使用旧密钥/过期密钥
此错误是由更改用于加密的工作区客户管理的密钥导致的。 你可以选择使用最新版本的有效密钥对工作区中的所有数据进行重新加密。 若要重新加密,请将Azure portal中的密钥更改为临时密钥,然后切换回要用于加密的密钥。 在此处了解如何管理工作区密钥。
将订阅转移到其他 Microsoft Entra 租户后,Synapse 无服务器 SQL 池不可用
如果你将订阅移到了另一个 Microsoft Entra 租户,则无服务器 SQL 池可能会遇到一些问题。 创建支持票证,Azure support将与你联系以解决该问题。
存储访问
如果在尝试访问 Azure 存储中的文件时遇到错误,请确保你有权限访问数据。 你应该能够访问公开的文件。 如果您试图在没有凭据的情况下访问数据,请确保您的 Microsoft Entra 身份可以直接访问文件。
如果你拥有一个用于访问文件的共享访问签名密钥,请确保创建了包含该密钥的 服务器级 或 数据库范围 凭据。 如果需要通过使用工作区的托管标识和自定义服务主体名称(SPN)来访问数据,则需要凭据。
无法读取、列出或访问 Azure Data Lake Storage 中的文件
如果使用没有显式凭据的 Microsoft Entra 登录,请确保您的 Microsoft Entra 标识能够访问存储中的文件。 若要访问文件,您的 Microsoft Entra 标识必须具有 Blob 数据读取者权限,或对 ADLS 中的 List 和 Read访问控制列表(ACL)的权限。 有关详细信息,请参阅查询因无法打开文件而失败。
如果使用 credentials 访问存储,请确保 托管标识 或 SPN 拥有 Data Reader 或 Contributor 角色或特定的 ACL 权限。 如果您使用了共享访问签名令牌,请确保它具有rl权限,并且它尚未过期。
如果使用 SQL 登录名和 OPENROWSET 函数 没有数据源,请确保具有与存储 URI 一致的服务器级凭据,并且有权访问存储。
查询因无法打开文件而失败
如果查询失败并出现错误File cannot be opened because it does not exist or it is used by another process,并且你确信这两个文件都存在,并且其他进程未使用,则无服务器 SQL 池无法access该文件。 此问题通常是因为 Microsoft Entra 标识没有权限访问文件,或因为防火墙阻止了文件访问。
默认情况下,无服务器 SQL 池会尝试使用 Microsoft Entra 身份来访问文件。 若要解决此问题,您必须具有访问文件的适当权限。 最简单的方法是在尝试查询的存储帐户上向自己授予存储 Blob 数据贡献者角色。
有关详细信息,请参阅:
- 存储的 Microsoft Entra ID 访问控制
- 控制 Synapse Analytics 中无服务器 SQL 池的存储帐户访问
Storage Blob 数据参与者角色的替代方法
与授予自己为 Storage Blob 数据参与者角色相比,您还可以为文件子集授予更精细的权限。
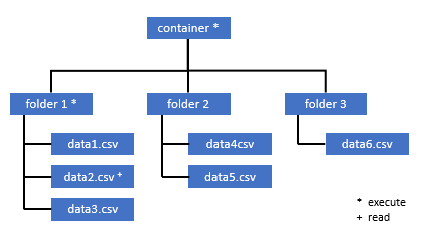
需要访问此容器中某些数据的所有用户还必须对从父文件夹到根文件夹(即容器)的所有文件夹具有 EXECUTE 权限。
详细了解如何在 Azure Data Lake Storage Gen2 中设置 ACL。
注意
必须在Azure Data Lake Storage Gen2内设置容器级别的执行权限。 可以在Azure Synapse中设置对文件夹的权限。
如果要在此示例中查询 data2.csv,则需要以下权限:
- 对容器的“执行”权限
- 对 folder1 的“执行”权限
- 对 data2.csv 的“读取”权限
使用一个对您需要访问的数据具有完全权限的管理员用户登录到Azure Synapse。
在数据窗格中,右键单击该文件,然后选择 Manage access。
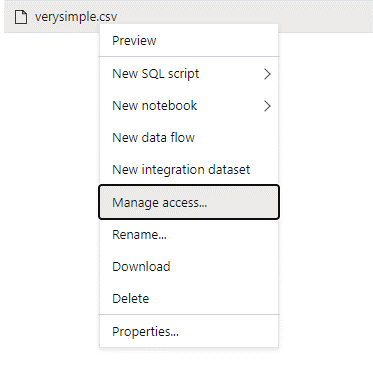
至少选择“读取”权限。 输入用户的 UPN 或对象 ID,例如
user@contoso.com。 选择 添加 。授予此用户读取权限。

注意
对于来宾用户,此步骤需要使用 Azure Data Lake 直接完成,因为无法直接通过Azure Synapse完成此步骤。
无法列出路径上目录的内容
此错误表示查询 Azure Data Lake 的用户无法列出storage中的文件。 在以下几种情况下,可能会发生此错误:
- 使用 Microsoft Entra 直通身份验证的 Microsoft Entra 用户无权列出Data Lake Storage中的文件。
- 使用 共享访问签名密钥或 工作区托管标识读取数据的 Microsoft Entra ID 或 SQL 用户,并且该密钥或标识无权列出存储中的文件。
- 访问 Dataverse 数据的用户没有在 Dataverse 中查询数据的权限。 如果你使用 SQL 用户,则可能会发生这种情况。
- 访问 Delta Lake 的用户可能无权读取 Delta Lake 事务日志。
解决此问题的最简单方法是在尝试查询的 storage 帐户中向自己授予 Storage Blob 数据参与者角色。
有关详细信息,请参阅:
- 微软 Entra ID 存储访问控制
- 在 Synapse Analytics 中控制无服务器 SQL 池的存储帐户访问
无法列出 Dataverse 表的内容
如果您使用 Azure Synapse Link for Dataverse 来读取链接的 Dataverse 表,那么需要使用 Microsoft Entra 帐户来通过无服务器 SQL 池访问链接的数据。 有关详细信息,请参阅 Azure Synapse Link for Dataverse with Azure Data Lake。
如果尝试使用 SQL 登录读取引用 DataVerse 表的外部表,则会收到以下错误:External table '???' is not accessible because content of directory cannot be listed.
DataVerse 外部表始终使用 Microsoft Entra 直通身份验证。 不能将其配置为使用共享访问签名密钥或工作区托管身份。
无法列出 Delta Lake 事务日志的内容
当无服务器 SQL 池无法读取 Delta Lake 事务日志文件夹时,将返回以下错误:
Content of directory on path 'https://.....core.chinacloudapi.cn/.../_delta_log/*.json' cannot be listed.
确保 _delta_log 文件夹存在。 可能你正在查询未转换为 Delta Lake 格式的普通 Parquet 文件。 如果该 _delta_log 文件夹存在,请确保对基础 Delta Lake 文件夹拥有“读取”和“列出”权限。 尝试使用 FORMAT='csv' 直接读取 json 文件。 将 URI 置于 BULK 参数中:
select top 10 *
from openrowset(BULK 'https://.....core.chinacloudapi.cn/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
如果此查询失败,则调用方无权读取底层存储文件。
执行查询
在以下情况下,可能会在查询执行过程中遇到错误:
- 调用方无法access某些对象。
- 查询无法访问外部数据。
- 查询包含无服务器 SQL 池不支持的某些功能。
由于当前的资源约束导致查询无法执行,因此查询失败
查询可能失败,并显示错误消息 This query cannot be executed due to current resource constraints.。此消息表示无服务器 SQL 池目前无法执行。 下面提供了一些故障排除选项:
- 请确保使用大小合理的数据类型。
- 如果查询的目标是 Parquet 文件,请考虑为字符串列定义显式类型,因为它们将默认为 VARCHAR(8000)。 查看推理数据类型。
- 如果你的查询针对 CSV 文件,请考虑创建统计信息。
- 若要优化查询,请参阅适用于无服务器 SQL 池的性能最佳做法。
查询超时时间已到
如果查询在无服务器 SQL 池上执行的时间超过 30 分钟,则会返回错误 Query timeout expired。 无法更改无服务器 SQL 池的此限制。
- 请尝试通过应用最佳做法来优化查询。
- 尝试使用 create external table as select (CETAS) 来具体化查询的一部分。
- 检查是否有正在无服务器 SQL 池上运行的并发工作负载,因为其他查询可能会占用资源。 在这种情况下,可以在多个工作区上拆分工作负载。
对象名称无效
错误 Invalid object name 'table name' 表示所使用的对象(例如表或视图)在无服务器 SQL 池数据库中不存在。 请尝试以下选项:
列出表或视图,并检查对象是否存在。 使用 SQL Server Management Studio 或 Visual Studio Code,因为 Synapse Studio 可能会显示一些在 Serverless SQL 池中不可用的表。
如果看到该对象,请检查是否使用了区分大小写或二进制的数据库排序规则。 对象名称可能与查询中使用的名称不匹配。 使用二进制数据库排序规则时,
Employee和employee是两个不同的对象。如果看不到该对象,原因可能是你正在尝试从 Lake 数据库或 Spark 数据库查询表。 该表可能出于以下原因而在无服务器 SQL 池中不可用:
- 表具有一些无法在无服务器 SQL 池中表示的列类型。
- 表的格式在无服务器 SQL 池中不受支持。 示例为 Avro 或 ORC。
字符串或二进制数据会被截断
如果你的字符串或二进制列类型(例如 VARCHAR、VARBINARY 或 NVARCHAR)的长度短于你读取的数据的实际大小,则会发生此错误。 你可以通过增大列类型的长度来修复此错误:
- 如果你的字符串列定义为
VARCHAR(32)类型,并且文本为 60 个字符,请在你的列架构中使用VARCHAR(60)类型(或更长的类型)。 - 如果你使用架构推理(没有
WITH架构),则所有字符串列都将自动定义为VARCHAR(8000)类型。 如果收到此错误,请在具有较大的WITH列类型的VARCHAR(MAX)子句中显式定义架构,以解决此错误。 - 如果表位于 Lake 数据库中,请尝试增大 Spark 池中的字符串列大小。
- 请尝试使用
SET ANSI_WARNINGS OFF,使无服务器 SQL 池能够自动截断 VARCHAR 值(如果这不会影响你的功能)。
字符串后的引号不完整
在罕见的情况下,当将 LIKE 运算符用于字符串列或与字符串文本进行某种比较时,可能会遇到下面的错误:
Unclosed quotation mark after the character string
如果在列上使用 Latin1_General_100_BIN2_UTF8 排序规则,则可能会发生此错误。 请尝试在列上设置 Latin1_General_100_CI_AS_SC_UTF8 排序规则(而不是 Latin1_General_100_BIN2_UTF8 排序规则)来解决该问题。 如果仍返回错误,请通过Azure portal提出支持请求。
将数据从一个分布区传输到另一个分布区时无法分配 tempdb 空间
当查询执行引擎无法处理数据并在执行查询的节点之间传输数据时,将返回错误 Could not allocate tempdb space while transferring data from one distribution to another。 这是一般性的查询失败,原因是当前的资源约束导致查询无法执行错误的一种特殊情况。 如果分配给 tempdb 数据库的资源不足以运行该查询,则会返回此错误。
在提交支持票证之前,请应用最佳做法。
处理外部文件时查询因错误失败(错误次数已达最大值)
如果查询失败并出现错误消息“error handling external file: Max errors count reached”,则表示指定的列类型与需要加载的数据不匹配。
若要获取有关错误以及要查看的行和列的详细信息,请将分析器版本从 2.0 更改为 1.0。
示例
如果要使用查询 1 查询文件 names.csv,Azure Synapse 无服务器化 SQL 池会返回以下错误:Error handling external file: 'Max error count reached'. File/External table name: [filepath]. 例如:
names.csv 文件包含:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
查询 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
原因
分析器版本从版本 2.0 更改为 1.0 后,错误消息将有助于识别问题。 现在,新的错误消息是 Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
截断告诉您列类型太小,无法容纳您的数据。 此 names.csv 文件中的最长名字包含七个字符。 要使用的对应数据类型应至少为 VARCHAR(7)。 此错误是由下面这行代码引起的:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
相应地更改查询可以解决错误。 调试后,再次将分析器版本更改为 2.0 以获得最高性能。
有关在何种情况下使用哪个解析器版本的详细信息,请参阅在 Synapse Analytics 中通过无服务器 SQL 池使用 OPENROWSET。
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
由于无法打开文件,无法批量加载
如果在查询执行期间修改了文件,则会返回错误 Cannot bulk load because the file could not be opened。 通常,可能会收到类似于 Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.) 的错误
无服务器 SQL 池无法读取在查询运行时正在修改的文件。 查询无法对文件上锁。 如果明确知道修改操作为“追加”,可以尝试设置以下选项:{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}。
有关详细信息,请参阅如何查询仅追加文件或在仅追加文件上创建表。
查询失败,出现数据转换错误
查询可能会失败,并显示错误消息 Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath].。此消息表示你的数据类型与第 n 行、第 m 列的实际数据不匹配。
例如,如果你只需要数据中的整数,但第 n 行中可能存在字符串,则会出现此错误消息。
若要解决此问题,请检查文件和所选的数据类型。 另外,还要检查行分隔符和字段终止符设置是否正确。 以下示例演示如何使用 VARCHAR 作为列类型来完成检查。
有关字段终止符、行分隔符和转义引号字符的详细信息,请参阅查询 CSV 文件。
示例
如果要查询文件 names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
使用以下查询:
查询 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Azure Synapse无服务器 SQL 池返回错误Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
需要浏览数据并作出明智的决策来处理此问题。 若要查看导致此问题的数据,需要先更改数据类型。 现在使用 VARCHAR(100) 来分析此问题,而不是查询数据类型为 SMALLINT 的 ID 列。
使用这个经过小幅修改的查询 2,现在可以处理数据,以返回名称列表。
查询 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
你可能会发现数据在第五行中具有 ID 的意外值。 在这种情况下,请务必与数据的业务所有者保持一致,了解如何按此示例所示避免损坏数据。 如果无法在应用程序级别进行预防,则合理大小的 VARCHAR 可能是这里唯一的选择。
提示
尝试使 VARCHAR () 尽可能简短。 请尽可能避免 VARCHAR (MAX),因为它可能会影响性能。
查询结果不符合预期
查询可能未失败,但结果集不符合预期。 生成的列可能是空的,或者可能返回了意外的数据。 出现这种情况的可能原因是错误地选择了行分隔符或字段终止符。
若要解决此问题,请再次查看数据并更改这些设置。 调试此查询非常简单,如以下示例中所示。
示例
如果要使用查询 1 的条件对文件 names.csv 进行查询,Azure Synapse SQL 无服务器池返回的结果令人感到奇怪:
在 names.csv中:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Firstname 列中似乎没有值。 所有值最终都出现在 ID 列中。 这些值以逗号分隔。 这个问题是由以下代码行引起的,因为需要选择逗号作为字段终止符,而不是分号符号:
FIELDTERMINATOR =';',
只需更改这个字符便可解决问题:
FIELDTERMINATOR =',',
查询 2 创建的结果集现在符合预期:
查询 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
返回:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
数据列的类型与外部数据类型不兼容
如果查询失败并显示错误消息 Column [column-name] of type [type-name] is not compatible with external data type […],,则可能是 PARQUET 数据类型映射到了不正确的 SQL 数据类型。
例如,如果 Parquet 文件的“价格”列采用浮点数(例如 12.89),而你尝试将该文件映射到 INT,则会出现此错误消息。
若要解决此问题,请检查文件和所选的数据类型。 此映射表有助于选择正确的 SQL 数据类型。 最佳做法是为将会解析为 VARCHAR 数据类型的列指定映射。 尽可能避免使用 VARCHAR,从而在查询中提高性能。
示例
如果要使用此查询 1 查询文件 taxi-data.parquet,Azure Synapse无服务器 SQL 池将返回以下错误:
文件 taxi-data.parquet 包含:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
查询 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
此错误消息指出数据类型不兼容,并建议使用 FLOAT 来代替 INT。 此错误是由下面这行代码引起的:
SumTripDistance INT,
使用这个经过小幅修改的查询 2,现在可以处理数据,并显示全部三列:
查询 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
查询引用的对象在分布式处理模式下不受支持
错误The query references an object that is not supported in distributed processing mode表示,在查询 Azure Storage 或 Azure Cosmos DB 分析存储中的数据时,您使用了无法使用的对象或函数。
某些对象(如系统视图和函数)在查询存储在 Azure data Lake 或 Azure Cosmos DB 分析storage中的数据时无法使用。 避免使用将外部数据与系统视图联接、在临时表中加载外部数据或是使用某些安全性或元数据函数筛选外部数据的查询。
WaitIOCompletion 调用失败
错误消息WaitIOCompletion call failed指示查询在等待完成从远程存储(Azure Data Lake)读取数据的 I/O 操作时失败。
该错误消息具有以下模式:Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
请确保将存储放置在与无服务器 SQL 池相同的区域内。 检查storage指标,并验证storage层上没有其他工作负载,例如上传可能使 I/O 请求饱和的新文件。
字段 HRESULT 包含结果代码。 下面列出了最常见错误代码及其可能的解决方法。
此错误代码表示源文件不在storage中。
发生此错误代码的原因包括:
- 另一个应用程序删除了该文件。
- 在此常见方案中,查询执行将启动,它会枚举文件并找到文件。 然后,在查询执行期间删除了某个文件。 例如,Databricks、Spark 或Azure Data Factory可能会删除它。 由于找不到该文件,查询失败。
- Delta 格式也可能出现此问题。 如果重试,查询可能会成功,因为存在新版本的表,并且不再查询已删除的文件。
- 缓存了无效的执行计划。
- 作为临时缓解措施,请运行命令
DBCC FREEPROCCACHE。 如果问题仍然存在,请创建支持工单。
- 作为临时缓解措施,请运行命令
NOT 附近有语法错误
错误 Incorrect syntax near 'NOT' 表示有一些外部表的列在列定义中包含 NOT NULL 约束。
- 更新表以移除列定义中的 NOT NULL。
- 此错误有时也可能在使用 CETAS 语句创建的表上暂时出现。 如果该问题无法解决,可以尝试删除并重新创建外部表。
分区列返回 NULL 值
如果查询返回 NULL 值而不是分区列,或者找不到分区列,则可能有几个可能的故障排除步骤:
- 如果使用表来查询分区数据集,表不支持分区。 将表替换为分区视图。
- 如果将分区视图与使用 FILEPATH() 函数查询分区文件的 OPENROWSET 一起使用,请确保已在位置中正确指定了通配符模式,并且已使用适当的索引来引用通配符。
- 如果直接在分区文件夹中查询文件,分区列不是文件列的组成部分。 分区值位于文件夹路径而不是在文件中。 因此,这些文件不包含分区值。
向列类型 DATETIME2 的批插入值失败
错误 Inserting value to batch for column type DATETIME2 failed 表示无服务器池无法从基础文件读取日期值。 存储在 Parquet 或 Delta Lake 文件中的日期/时间值不能表示为 DATETIME2 列。
使用 Spark 检查文件中的最小值,并检查是否存在早于 0001-01-03 的日期。 如果使用较高版本的 Spark 存储文件,并且该版本仍使用旧的日期/时间存储格式,那么在无服务器 SQL 池中,由于采用的是不一致的 proleptic 格里高利历法,之前的日期/时间值是用 Julian 日历编写的。
在某些 Spark 版本中,用于在 Parquet 文件中写入值的儒略历与无服务器 SQL 池使用的公历之间可能存在两天的差异。 这种差异可能会导致转换为无效的负日期值。
尝试使用 Spark 更新这些值,因为它们在 SQL 中被视为无效日期值。 下面的示例演示如何在 Delta Lake 中将 SQL 日期范围外的值更新为 NULL:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.chinacloudapi.cn/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
此更改会删除无法表示的值。 其他日期值可能会正确加载,但表示不正确,因为儒略历和公历之间仍然存在差异。 如果使用 Spark 3.0 或更早版本,即使是 1900-01-01 之前的日期,也可能会遇到意外的日期变化。
考虑迁移到 Spark 3.1 或更高版本,并切换到公历。 最新的 Spark 版本默认使用与无服务器 SQL 池日历一致的公历。 使用更高版本的 Spark 重新加载旧数据,并使用以下设置更正日期:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
由于拓扑变更或计算容器故障,查询失败
此错误可能表示无服务器 SQL 池中发生了某些内部进程问题。 提交支持票证,其中包含可帮助Azure support团队调查问题的所有必要详细信息。
描述与常规工作负载相比可能不寻常的任何内容。 例如,可能存在大量并发请求,或者在发生此错误之前开始执行了特殊的工作负载或查询。
通配符扩展超时
如查询文件夹和多个文件部分中所述,无服务器 SQL 池支持使用通配符读取多个文件/文件夹。 每个查询最多有 10 个通配符。 必须知道,此功能也是有代价的。 无服务器池需要花费一定的时间才能列出与通配符匹配的所有文件。 这会导致延迟,如果你尝试查询的文件数较多,这种延迟可能会增大。 在这种情况下,你可能会遇到以下错误:
"Wildcard expansion timed out after X seconds."
可以采取多个缓解步骤来避免这种情况:
- 应用无服务器 SQL 池最佳做法中所述的最佳做法。
- 尝试通过将文件压缩成少量较大的文件来减少要查询的文件数。 尝试将文件大小保持在 100 MB 以上。
- 确保尽可能使用基于分区列的筛选器。
- 如果您使用 Delta 文件格式,请使用 Spark 中的优化写功能。 这样可以通过减少需要读取和处理的数据量来提高查询性能。 在 Apache Spark 上使用优化写入中介绍了如何使用优化写入。
- 若要通过有效地对基于分区依据列的隐式筛选器进行硬编码来避免某些顶级通配符,请使用动态 SQL。
使用自动架构推理时缺少列
通过省略 WITH 子句,无需了解或指定架构,即可轻松查询文件。 在这种情况下,将从文件中推断列名和数据类型。 请记住,如果同时读取多个文件,架构将从服务从存储中获取的第一个文件推断出来。 这可能意味着预期的一些列被省略了,这都是因为服务用来定义架构的文件不包含这些列。 若要显式指定架构,请使用 OPENROWSET WITH 子句。 如果你指定架构(通过使用外部表或 OPENROWSET WITH 子句),则将使用默认的宽松路径模式。 这意味着某些文件中不存在的列将返回为 NULL(对于这些文件中的行)。 若要了解如何使用路径模式,请查看以下文档和示例。
配置
无服务器 SQL 池允许使用 T-SQL 配置数据库对象。 下面是一些约束:
- 无法在
master和lakehouse或 Spark 数据库中创建对象。 - 必须有一个主密钥才能创建凭据。
- 必须拥有引用对象中使用的数据的权限。
无法创建数据库
如果收到错误 CREATE DATABASE failed. User database limit has been already reached.,则表示已创建一个工作区中支持的最大数据库数。 有关详细信息,请参见约束。
- 如果需要分隔对象,请在数据库中使用架构。
- 如果需要引用 Azure 数据湖存储,请创建将在无服务器 SQL 池中同步的 Lakehouse 数据库或 Spark 数据库。
创建或更改表失败,因为最小行大小超过允许的最大表行大小 8060 字节
任何表每个行最多可以有 8KB 大小(不包括行外 VARCHAR(MAX)/VARBINARY(MAX) 数据)。 如果创建行中单元格的总大小超过 8060 字节的表,则会出现以下错误:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
如果创建列大小超过 8060 字节的 Spark 表,并且无服务器 SQL 池无法创建引用 Spark 表数据的表,则 Lake 数据库中也可能发生此错误。
作为缓解措施,请避免使用 CHAR(N) 等固定大小类型,改为使用可变大小 VARCHAR(N) 类型,或在 CHAR(N) 中减小大小。 请参阅 SQL Server 中的
在执行此操作之前,请在数据库中创建一个主密钥或在会话中打开该主密钥
如果查询失败并显示错误消息 Please create a master key in the database or open the master key in the session before performing this operation.,则表示用户数据库目前没有access主密钥。
最有可能的是,你创建了一个新的用户数据库,但尚未创建主密钥。
若要解决此问题,请通过以下查询创建主密钥:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
注意
请将此处的 'strongpasswordhere' 替换为其他机密。
master 数据库不支持 CREATE 语句
如果查询失败并出现错误消息 Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database.,则表示无服务器 SQL 池中的 master 数据库不支持创建以下内容:
- 外部表。
- 外部数据源。
- 以数据库为作用域的凭据。
- 外部文件格式。
解决方法如下:
创建用户数据库:
CREATE DATABASE <DATABASE_NAME>在 <DATABASE_NAME> 的上下文中执行 CREATE 语句,该语句之前在
master数据库中执行失败。下面是创建外部文件格式的示例:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
无法创建 Microsoft Entra 登录名或用户
如果在数据库中尝试创建新的 Microsoft Entra 登录名或用户时遇到错误,请检查用于连接到数据库的登录名。 尝试创建新 Microsoft Entra 用户的登录帐户必须有权访问 Microsoft Entra 域,并检查用户是否存在。 请注意:
- SQL 登录名没有此权限,因此如果使用 SQL 身份验证,则总是会遇到此错误。
- 如果使用 Microsoft Entra 登录名创建新登录名,请检查你是否有权访问 Microsoft Entra 域。
Azure Cosmos DB
借助无服务器 SQL 池,可以使用 OPENROWSET 函数查询 Azure Cosmos DB 分析存储。 确保 Azure Cosmos DB 容器具有分析存储。 请确保正确指定了帐户、数据库和容器名称。 此外,请确保 Azure Cosmos DB 帐户密钥有效。 有关详细信息,请参阅先决条件。
无法使用 OPENROWSET 函数查询 Azure Cosmos DB
如果无法连接到 Azure Cosmos DB 帐户,请查看 必备条件。 下表列出了可能的错误和故障排除操作。
| 错误 | 根本原因 |
|---|---|
| 语法错误: - OPENROWSET 附近有语法错误。- ... 不是已识别的 BULK OPENROWSET 供应商选项。- ... 附近有语法错误。 |
可能的根本原因: - 不使用 Azure Cosmos DB 作为第一个参数。 - 在第三个参数中使用字符串字面量而不是标识符。 - 未指定第三个参数(容器名称)。 |
| Azure Cosmos DB connection string中出现错误。 | - 未指定帐户、数据库或密钥。 - 在连接字符串中存在无法识别的选项。 分号( ;)被放在连接字符串的末尾。 |
| 解决 Azure Cosmos DB 路径失败,出现错误“帐户名称不正确”或“数据库名称不正确”。 | 找不到指定的帐户名称、数据库名称或容器,或者未对指定的集合启用分析存储。 |
| 解决Azure Cosmos DB 路径失败,出现错误“机密值不正确”或“机密为 null 或空”。 | 帐户密钥无效或缺失。 |
读取 Azure Cosmos DB 字符串类型时返回 UTF-8 排序规则警告
如果 OPENROWSET 列排序规则没有 UTF-8 编码,则无服务器 SQL 池会返回编译时警告。 可以使用 T-SQL 语句轻松更改当前数据库中运行的所有 OPENROWSET 函数的默认排序规则:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
使用字符串谓词筛选数据时,Latin1_General_100_BIN2_UTF8 排序规则可提供最佳性能。
Azure Cosmos DB 分析存储中缺少行
Azure Cosmos DB 中的某些项可能不会由 OPENROWSET 函数返回。 请注意:
- 事务存储和分析存储之间存在同步延迟。 在 Azure Cosmos DB 事务存储中输入的文档可能会在两到三分钟后显示在分析存储中。
- 该文档可能会违反某些架构约束。
查询在某些 Azure Cosmos DB 项中返回 NULL 值
Azure Synapse SQL 返回 NULL,而不是在事务存储中看到的值,在这种情况下:
- 事务存储和分析存储之间存在同步延迟。 在 Azure Cosmos DB 事务存储中输入的值可能会在两到三分钟后显示在分析存储中。
- WITH 子句中可能存在错误的列名或路径表达式。 WITH 子句中的列名(或列类型之后的路径表达式)必须与 Azure Cosmos DB 集合中的属性名称匹配。 比较区分大小写。 例如,
productCode和ProductCode是不同的属性。 请确保列名称与 Azure Cosmos DB 属性名称完全匹配。 - 该属性可能不会移动到分析存储,是因为它违反了一些架构约束,例如超过 1,000 个属性或超过 127 个嵌套级别。
- 如果使用定义完善的架构表示形式,则事务存储中的值可能具有错误的类型。 定义完善的架构通过对文档进行采样来锁定每个属性的类型。 在事务存储中添加的任何与类型不匹配的值都将被视为错误的值,并且不会迁移到分析存储中。
- 如果使用的是全保真架构表示形式,请确保在属性名后面添加类型后缀,如
$.price.int64。 如果看不到引用的路径的值,值可能是存储在不同的类型路径下面,例如$.price.float64。 有关详细信息,请参阅 在完整保真架构中查询 Azure Cosmos DB 集合。
列与外部数据类型不兼容
如果 WITH 子句中的指定列类型与 Azure Cosmos DB 容器中的类型不匹配,则返回错误Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'.。 尝试根据Azure Cosmos DB 到 SQL 类型映射中的说明更改列类型,或使用 VARCHAR 类型。
解决:Azure Cosmos DB 路径失败并出现错误
如果收到错误Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'.,请检查是否在 Azure Cosmos DB 中使用了专用终结点。 若要允许无服务器 SQL 池通过专用终结点访问分析存储,必须为 Azure Cosmos DB 分析存储配置专用终结点。
Azure Cosmos DB 性能问题
如果你遇到一些意外的性能问题,请确保应用了最佳做法,例如:
- 请确保将客户端应用程序、无服务器池和 Azure Cosmos DB 分析存储放置在同一区域。
- 确保使用带有最佳数据类型的 WITH 子句。
- 使用字符串谓词筛选数据时,请确保使用 Latin1_General_100_BIN2_UTF8 排序规则。
- 如果已重复缓存的查询,请尝试使用 CETAS 将查询结果存储在 Azure Data Lake Storage。
Delta Lake
无服务器 SQL 池中的 Delta Lake 支持可能存在一些限制:
- 请确保在 OPENROWSET 函数或外部表位置中引用 Delta Lake 根文件夹。
- 根文件夹必须有一个名为
_delta_log的子文件夹。 如果没有_delta_log文件夹,则查询将会失败。 如果看不到该文件夹,则表明你正在引用纯 Parquet 文件,必须使用 Apache Spark 池将其转换为 Delta Lake。 - 不要指定用于描述分区架构的通配符。 Delta Lake 查询会自动标识 Delta Lake 分区。
- 根文件夹必须有一个名为
- 在 Apache Spark 池中创建的 Delta Lake 表在无服务器 SQL 池中自动可用,但架构不会进行更新(公共预览版限制)。 如果使用 Spark 池在 Delta 表中添加列,则不会在无服务器 SQL 池数据库中显示更改。
- 外部表不支持分区。 请对 Delta Lake 文件夹使用分区视图以使用分区排除。 请参阅本文后面的已知问题和解决方法。
- 无服务器 SQL 池不支持时间旅行查询。 使用 Synapse Analytics 中的 Apache Spark 池读取历史数据。
- 无服务器 SQL 池不支持更新 Delta Lake 文件。 可以使用无服务器 SQL 池来查询最新版本的 Delta Lake。 使用 Synapse Analytics 中的 Apache Spark 池更新 Delta Lake。
- 无法使用 CETAS 命令将查询结果以 Delta Lake 格式存储到存储空间。 CETAS 命令仅支持 Parquet 和 CSV 作为输出格式。
- Synapse Analytics 中的无服务器 SQL 池与 Delta 读取器版本 1 兼容。
- Synapse Analytics 中的无服务器 SQL 池不支持带有 BLOOM 筛选器的数据集。 无服务器 SQL 池将忽略 BLOOM 筛选器。
- 专用 SQL 池中不支持 Delta Lake。 确保使用无服务器 SQL 池来查询 Delta Lake 文件。
- 有关无服务器 SQL 池的已知问题的详细信息,请参阅 Azure Synapse Analytics 已知问题。
无服务器支持 Delta 1.0 版本
无服务器 SQL 池仅读取 Delta Lake 1.0 版本。 无服务器 SQL 池是一个 级别 1 的 Delta 读取器,不支持以下功能:
- 忽略列映射 - 无服务器 SQL 池将返回原始列名。
- 忽略删除向量,并且将返回已删除/更新行的旧版本(可能是错误的结果)。
- 不支持以下 Delta Lake 功能:V2 检查点、不带时区的 timestamp、VACUUM 协议检查
删除向量被忽略
如果将 Delta Lake 表配置为使用 Delta 编写器版本 7,它将在“删除向量”(DV) 中存储被删除的行和已更新行的旧版本。 由于无服务器 SQL 池具有 1 级 Delta 读取器,它们将忽略删除向量,并可能在读取不支持的 Delta Lake 版本时产生错误的结果。
不支持 Delta 表中的列重命名
无服务器 SQL 池不支持使用重命名的列来查询 Delta Lake 表。 无服务器 SQL 池无法从重命名的列中读取数据。
Delta 表中列的值为 NULL
如果使用的是需要 Delta 读取器版本 2 或更高版本的 Delta 数据集,并且使用版本 1 不支持的功能(例如,重命名列、删除列或列映射),则可能不会显示引用列中的值。
JSON 文本的格式不正确
此错误表示无服务器 SQL 池无法读取 Delta Lake 事务日志。 你可能会看到以下错误:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
确保 Delta Lake 数据集未损坏。 验证是否可以在 Azure Synapse 中使用 Apache Spark 池读取 Delta Lake 文件夹的内容。 这可以确保文件 _delta_log 文件未损坏。
解决方法
尝试使用 Apache Spark 池在 Delta Lake 数据集上创建检查点,然后重新运行查询。 检查点汇总事务 JSON 日志文件,可能会解决这个问题。
如果数据集有效,创建支持票证并提供详细信息:
- 请不要进行添加或删除列或优化表之类的任何更改,因为此操作可能会更改 Delta Lake 事务日志文件的状态。
- 将
_delta_log文件夹的内容复制到新的空文件夹中。 不要 复制.parquet data文件。 - 尝试读取已复制到新文件夹中的内容,并验证是否收到相同的错误。
- 将复制的
_delta_log文件的内容发送到Azure support。
现在,可以继续将 Delta Lake 文件夹与 Spark 池配合使用。 如果允许共享此信息,则会向Microsoft support提供复制的数据。 Azure团队将调查 delta_log 文件的内容,并提供有关可能的错误和解决方法的详细信息。
解析 Delta 日志失败
以下错误表明无服务器 SQL 池无法解析 Delta 日志:Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder.最常见的原因是 Spark 3.3 中添加的 last_checkpoint_file 字段导致 _delta_log 文件夹中的 checkpointSchema 大小超过 200 字节。
有两个选项可用于规避此错误:
- 在 Spark 笔记本中修改适当的配置并生成新的检查点,以便重新创建
last_checkpoint_file。 如果使用 Azure Databricks,配置修改如下:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - 降级到 Spark 3.2.1。
我们的工程团队目前正在努力实现对 Spark 3.3 的全面支持。
在 Spark 中创建的 Delta 表未显示在无服务器池中
注意
复制 Spark 中创建的 Delta 表的功能目前仍以公共预览版提供。
如果在 Spark 中创建了 Delta 表,并且该表未显示在无服务器 SQL 池中,请检查以下内容:
- 等待一段时间(通常为 30 秒),因为 Spark 表需要在延迟一段时间后才同步。
- 如果等待一段时间后该表仍未出现在无服务器 SQL 池中,请检查 Spark Delta 表的架构。 在无服务器环境中,复杂类型或不受支持的类型的 Spark 表不可用。 尝试在湖数据库中创建采用相同架构的 Spark Parquet 表,并检查该表是否出现在无服务器 SQL 池中。
- 检查工作区中托管标识对表所引用的 Delta Lake 文件夹的访问权限。 无服务器 SQL 池使用工作区托管标识从存储中获取表列信息来创建表。
湖泊数据库
使用 Spark 或 Synapse 设计器创建的 Lake 数据库表在无服务器 SQL 池中自动可用(用于查询)。 可以使用无服务器 SQL 池查询使用 Spark 池创建的 Parquet、CSV 和 Delta Lake 表,并将其他架构、视图、过程、表值函数和 db_datareader 角色中的 Microsoft Entra 用户添加到 Lake 数据库。 本部分列出了可能的问题。
在 Spark 中创建的表在无服务器池中不可用
创建的表可能无法立即在无服务器 SQL 池中使用。
- 表将在无服务器池中提供,但存在一定延迟。 在 Spark 中创建表后,可能需要等待 5 到 10 分钟才能在无服务器 SQL 池中查看该表。
- 只有引用 Parquet、CSV 和 Delta 格式的表在无服务器 SQL 池中可用。 其他类型的表格是不可用的。
- 包含某些不受支持的列类型的表在无服务器 SQL 池中不可用。
- 对湖数据库中的 Delta Lake 表的访问权限在公共预览版中提供。 请查看此部分或 Delta Lake 部分中列出的其他问题。
Spark 中创建的外部表在无服务器池 (Serverless Pool) 中显示出意外的结果。
可能会出现源 Spark 外部表与无服务器池上的复制外部表不匹配的情况。 如果在创建 Spark 外部表时使用的文件没有扩展,则可能会发生这种情况。 若要获取正确的结果,请确保所有文件都带有扩展名,如 .parquet。
无法对复制的数据库进行操作
如果尝试修改 Lake 数据库,或在 Lake 数据库中创建外部表、外部数据源、数据库范围的凭据或其他对象,将返回此错误。 只能在 SQL 数据库上创建这些对象。
Lake 数据库是从 Apache Spark 池复制的,并由 Apache Spark 管理。 因此不能像在 SQL 数据库中那样使用 T-SQL 语言创建对象。
仅允许在 Lake 数据库中执行以下操作:
- 在
dbo以外的 架构中创建、删除或更改视图、过程和内联表值函数 (iTVF)。 - 从Microsoft Entra ID创建和删除数据库用户。
- 在
db_datareader架构中添加或删除数据库用户。
Lake 数据库中不允许执行其他操作。
注意
如果在 dbo 架构中创建视图、过程或函数(或省略架构并使用通常为 dbo 的默认架构),将会收到一条错误消息。
Lake 数据库中的 Delta 表在无服务器 SQL 池中不可用
确保您的工作区托管身份对包含 Delta 文件夹的 ADLS 存储具有读取访问权限。 无服务器化SQL池从放置在ADLS中的Delta日志中读取Delta Lake表架构,并使用工作区托管身份访问Delta事务日志。
尝试使用托管身份凭据在某些引用 Azure Data Lake 存储的 SQL 数据库中设置数据源,并尝试在该数据源上方使用托管身份创建外部表,以确认具有托管身份的表是否可以访问存储。
湖数据库中的 Delta 表在 Spark 池和无服务器池中模式不一致
使用无服务器 SQL 池,可以使用 Spark 或 Synapse 设计器访问 Lake 数据库中的 Parquet、CSV 和 Delta 表。 对 Delta 表的访问权限在公共预览版中提供,目前无服务器将在创建时与 Spark 同步 Delta 表,但如果稍后使用 Spark 中的 ALTER TABLE 语句添加列,则不会更新架构。
这是公共预览版的限制。 若要解决此问题,请在 Spark 中删除并重新创建 Delta 表(如果可能),而不是更改表。
对表的查询超时或性能降低
修改 Spark 或 Dataverse 中的原始表时,将自动重新创建无服务器池中的相应表。 此过程会导致表上的现有统计信息丢失。 如果没有这些统计信息,对表的查询可能会遇到延迟甚至超时。
如果遇到此问题,请考虑设置作业,以在 Spark/Dataverse 发生更改后或按定期计划重新创建表的统计信息。
性能
无服务器 SQL 池根据数据集的大小和查询复杂程度将资源分配给查询。 不能更改或限制向查询提供的资源。 在某些情况下,你可能会遇到意外的查询性能下降,且可能必须确定根本原因。
查询持续时间很长
如果查询的持续时间超过 30 分钟,则表明查询将结果返回到客户端的速度较慢。 无服务器 SQL 池的执行限制为 30 分钟。 任何额外的时间都花费在结果流式处理上。 请尝试以下解决方法:
- 如果使用 Synapse Studio,请尝试重现其他应用程序(如 SQL Server Management Studio 或 Visual Studio Code)的问题。
- 如果使用 SQL Server Management Studio、Visual Studio Code、Power BI 或其他应用程序执行查询速度缓慢,请检查网络问题和最佳做法。
- 将查询置于 CETAS 命令中并测量查询持续时间。 CETAS 命令将结果存储到Azure Data Lake Storage,并且不依赖于客户端连接。 如果 CETAS 命令的完成速度比原始查询快,请检查客户端与无服务器 SQL 池之间的网络带宽。
使用 Synapse Studio 执行查询时速度缓慢
如果使用Synapse Studio,请尝试使用桌面客户端(如 SQL Server Management Studio 或 Visual Studio Code)。 Synapse Studio是一个 Web 客户端,它使用 HTTP 协议连接到无服务器 SQL 池,这通常比 SQL Server Management Studio 或 Visual Studio Code 中使用的本机 SQL 连接慢。
查询在使用应用程序执行时速度缓慢
如果查询执行速度缓慢,请检查以下问题:
- 请确保客户端应用程序与无服务器 SQL 池终结点并置。 跨区域执行查询可能会导致额外的延迟,并使结果集的流式处理速度变慢。
- 确保没有可能导致结果集流式处理速度缓慢的网络问题
- 确保客户端应用程序有足够的资源(例如 CPU 使用率未达到 100%)。
- 确保将存储帐户或 Azure Cosmos DB 分析存储放置在与无服务器 SQL 终结点相同的区域中。
请参阅并置资源的最佳做法。
查询持续时间变化大
如果执行相同的查询并观察到查询持续时间有变化,则可能有多种原因导致此行为:
- 检查是否为首次执行查询。 首次执行查询会收集创建计划所需的统计信息。 统计信息是通过扫描基础文件进行收集的,此收集过程可能会延长查询持续时间。 在Synapse Studio中,你将在查询之前执行的 SQL 请求列表中看到“全局统计信息创建”查询。
- 统计信息可能会在一段时间后过期。 你可能会定期观察到对性能的影响,因为无服务器池必须扫描并重新生成统计信息。 你可能会注意到 SQL 请求列表中出现其他“全局统计信息创建”查询,这些查询会在你的查询之前执行。
- 执行查询的持续时间较长时,请检查是否在同一终结点上运行了一些工作负载。 无服务器 SQL 终结点将平等地将资源分配给并行执行的所有查询,并且查询可能会延迟。
连接
无服务器 SQL 池使你可以使用 TDS 协议进行连接,并使用 T-SQL 语言查询数据。 大多数可以连接到SQL Server或Azure SQL Database的工具也可以连接到无服务器 SQL 池。
SQL 池正在预热
在较长时间处于非活动状态后,无服务器 SQL 池会停用。 激活会在接下来的第一个活动(例如首次连接尝试)时自动进行。 激活过程可能需要比单次连接尝试间隔更长的时间,因此会显示错误消息。 重新尝试连接应该足以解决问题。
最佳做法是,对于支持它的客户端,请使用 ConnectionRetryCount 和 ConnectRetryInterval connection string 关键字来控制重新连接行为。
如果错误消息仍然存在,请通过Azure门户提交支持请求。
无法从Synapse Studio进行连接
请参阅 Synapse Studio 部分。
无法从工具连接到Azure Synapse池
某些工具可能没有可用于连接到Azure Synapse无服务器 SQL 池的显式选项。 使用用于连接到SQL Server或 SQL 数据库的选项。 连接对话框不需要标记为“Synapse”,因为无服务器 SQL 池使用与SQL Server或 SQL 数据库相同的协议。
即使工具仅允许输入逻辑服务器名称并预定义 database.chinacloudapi.cn 域,也请将 Azure Synapse 工作区名称后加上 -ondemand 后缀和 database.chinacloudapi.cn 域。
安全性
确保用户有权访问数据库、执行命令的权限以及对访问 Azure Data Lake 或 Azure Cosmos DB 存储 的权限。
无法访问 Azure Cosmos DB 帐户
必须使用只读的Azure Cosmos DB密钥访问您的分析性存储,因此请确保它未过期或未被重新生成。
如果出现错误 “解析 Azure Cosmos DB 路径失败,出现错误”,请确保已配置防火墙。
无法访问湖仓或 Spark 数据库
如果用户无法访问湖仓或 Spark 数据库,则可能是因为用户无权访问和读取该数据库。 具有 CONTROL SERVER 权限的用户应对所有数据库具有完全访问权限。 作为受限权限,可以尝试使用 CONNECT ANY DATABASE 和 SELECT ALL USER SECURABLES。
SQL 用户无法访问 Dataverse 表格
Dataverse 表通过调用方的 Microsoft Entra 身份访问存储。 具有高权限的 SQL 用户可能会尝试从表中选择数据,但该表将无法access Dataverse 数据。 此方案不受支持。
当 SPI 创建角色分配时,Microsoft Entra 服务主体登录失败
如果要使用另一个 SPI 为服务主体标识符 (SPI) 或 Microsoft Entra 应用创建角色分配,或已创建了一个角色分配但它无法登录,则可能会收到以下错误:Login error: Login failed for user '<token-identified principal>'.
对于服务主体,应使用应用程序 ID 而不是对象 ID 作为安全 ID (SID) 来创建登录名。 服务主体存在一个已知的限制,当服务主体为另一个 SPI 或应用创建角色分配时,Azure Synapse无法从Microsoft Graph提取应用程序 ID。
解决方案 1
转到 Azure portal>Synapse Studio>管理>访问控制,并为所需的服务主体手动添加 Synapse 管理员 或 Synapse SQL 管理员。
解决方案 2
必须使用 SQL 代码手动创建正确的登录名:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
解决方法 3
还可以使用 PowerShell 设置服务主体的 Azure Synapse 管理员。 必须安装 Az.Synapse 模块。
解决方案是将 cmdlet New-AzSynapseRoleAssignment 与 -ObjectId "parameter" 配合使用。 在该参数字段中,使用工作区管理员的Azure服务主体凭据输入应用程序 ID,而不是对象 ID。
PowerShell 脚本:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId -Environment AzureChinaCloud
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
注意
在这种情况下,synapse Data Studio UI 不会显示上述方法添加的角色分配,因此建议同时将角色分配添加到对象 ID 和应用程序 ID,以便它也可以在 UI 上显示。
New-AzSynapseRoleAssignment -WorkspaceName“<workspaceName>”-RoleDefinitionName“Synapse Administrator”-ObjectId“<object_id_to_add_as_admin>”[-Debug]
验证
连接到无服务器 SQL 终结点,并验证是否已使用 SID(上一示例中的 app_id_to_add_as_admin)创建外部登录名:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
或者尝试使用设置的管理员应用在无服务器 SQL 终结点上登录。
约束
有一些常规系统约束可能会影响工作负载:
| 财产 | 限制 |
|---|---|
| 每个订阅的最大Azure Synapse工作区数 | 查看限制。 |
| 每个无服务器池的数据库最大数目 | 100(不包括从 Apache Spark 池同步的数据库)。 |
| 从 Apache Spark 池同步的数据库最大数目 | 无限制。 |
| 每个数据库的数据库对象最大数目 | 数据库中所有对象的数量总和不能超过 2,147,483,647。 请参阅SQL Server 数据库引擎中的限制。 |
| 最大标识符长度(以字符计) | 128. 请参阅 SQL Server 数据库引擎中的限制。 |
| 查询最长持续时间 | 30 分钟。 |
| 结果集的最大大小 | 在两次并发查询之间共享最多 400 GB。 |
| 最大并发度 | 不受限制,具体取决于查询复杂性和扫描的数据量。 一个无服务器 SQL 池可以同时处理 1,000 个执行轻型查询的活动会话。 如果查询比较复杂或扫描的数据量比较大,则数字将下降,因此在这种情况下,请考虑降低并发数,并在可能的情况下用较长的时间来执行查询。 |
| 外部表名的最大大小 | 100 个字符。 |
无法在无服务器 SQL 池中创建数据库
无服务器 SQL 池具有限制,为每个工作区创建的数据库不能多于 100 个。 如果需要分隔对象并进行隔离,请使用架构。
如果收到错误 CREATE DATABASE failed. User database limit has been already reached,这表示您已在一个工作区中创建了支持的最大数量的数据库。
无需使用单独数据库来隔离不同租户的数据。 所有数据都存储在外部的 数据湖 和 Azure Cosmos DB 中。 元数据(例如表、视图和函数定义)可以使用架构成功隔离。 基于架构的隔离也用于 Spark,其中数据库和架构是相同概念。