适用对象:![]() NoSQL
NoSQL![]() MongoDB
MongoDB![]() Cassandra
Cassandra![]() Gremlin
Gremlin![]() 表
表
本文列举 NoSQL 数据库相比关系数据库的一些重要优势。 此外,将讨论使用 NoSQL 时存在的一些难点。 若要深入了解现存的不同数据存储,请查看有关选择适当的数据存储的文章。
在维护关系数据库系统时,最突出的难题之一是,大多数关系引擎都会应用闩锁机制来实施严格的 ACID 语义。 这种做法的优点是可以确保数据库中数据的一致状态。 但是,它在并发性、延迟和可用性方面也会带来严重的弊端。 由于存在这种根本性的体系结构限制,在事务量较高时,可能需要手动将数据分片。 实现手动分片可能很耗时且非常棘手。
针对这种情况,分布式数据库可提供更具伸缩性的解决方案。 但是,维护过程仍可能成本高昂且很耗时。 管理员可能需要执行额外的工作来确保系统分布性是透明的。 他们还可能需要考虑到数据库的“离线”性。
Azure Cosmos DB 已部署到所有 Azure 中国区域,因此简化了这些难题。 可以动态划分分区范围,使数据库随着应用程序的扩展而无缝增长,同时保持高可用性。 精细粒度的多租户功能以及严格受控的云原生资源监管功能有助于提供令人惊叹的延迟保证和可预测的性能。 分区是完全托管式的,因此管理员无需编写代码或管理分区。
如果事务量达到极限(例如,每秒数千个事务),则应考虑采用分布式 NoSQL 数据库。 若要实现最大效率、简化维护和降低总拥有成本,请考虑采用 Azure Cosmos DB。
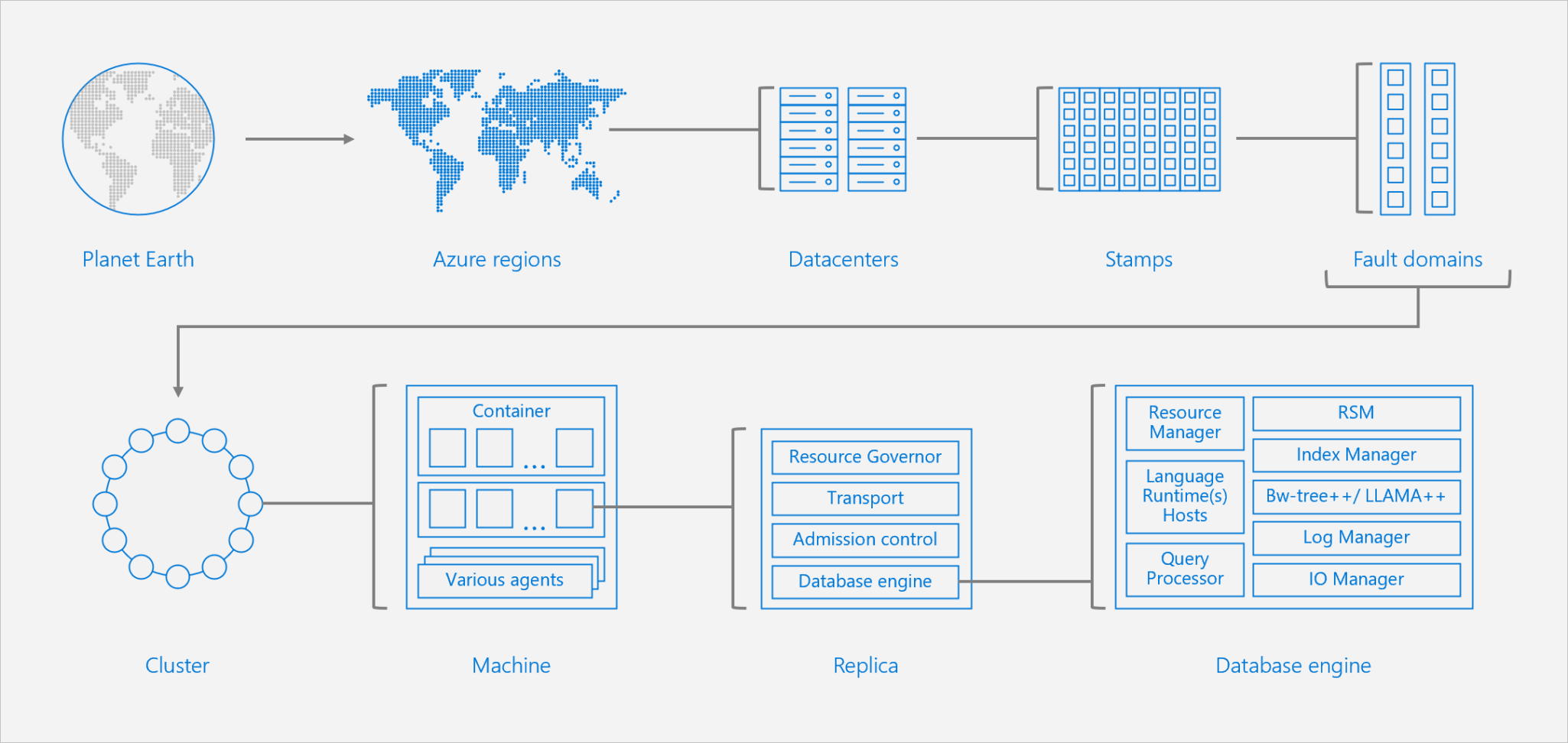
在大量的用例中,数据库中的事务可能包含许多父子关系。 随着时间的推移,这些关系可能会急剧增加,最终变得难以管理。 分层数据库形式在上世纪 80 年代即已出现,但由于存储效率低下而并未普及。 此外,随着 Ted Codd 关系模型成为几乎所有主流数据库管理系统使用的事实标准,分层数据层日渐失去其吸引力。
但如今,文档式数据库的普及性已得到大幅提高。 这种数据库可被视为分层数据库范型的重新改造。由于解除了在磁盘上存储数据造成的成本忧虑,此类数据库让人随心所欲。 因此,相较于面向文档的新式方法,在关系数据库中维护许多复杂父子实体关系现在可被视为一种反模式。
面向对象的设计的出现,以及将它与关系模型相结合时所发生的阻抗失配,在某些用例中也突出了关系数据库中的反模式。 因此可能会造成隐含的但往往很高昂的维护成本。 尽管 ORM 方法已有演进,可在一定程度上缓解此问题,但面向文档的数据库与面向对象的方法的融合度要好得多。 利用此方法,开发人员无需致力于开发 ORM 驱动程序,也无需定制语言特定的 OO 数据库引擎。 如果数据包含许多父子关系和深度的层次级别,可以考虑使用 NoSQL 文档数据库,例如 Azure Cosmos DB SQL API。
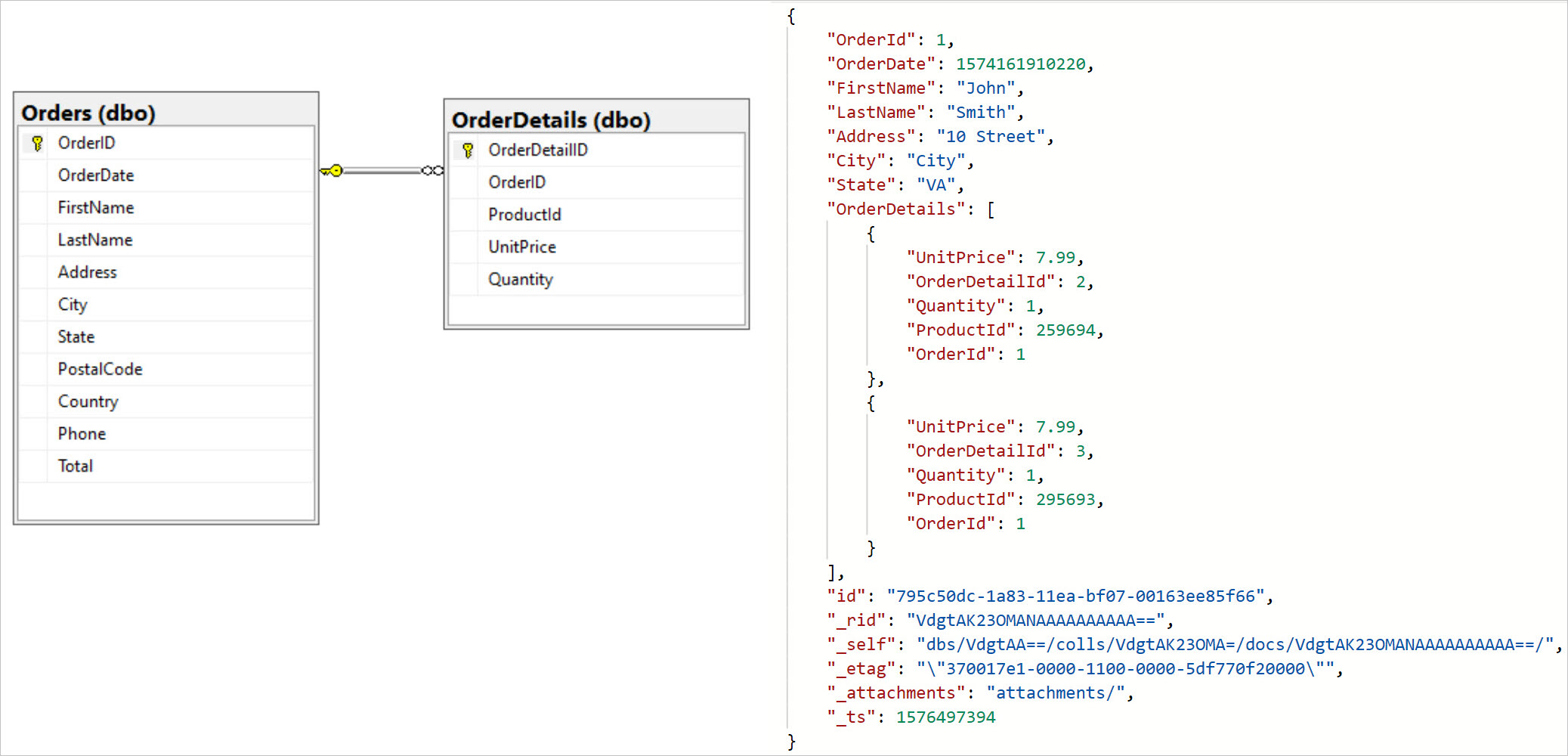
讽刺的是,在为深层且复杂的关系建模时,关系数据库的名称虽然带有“关系”二字,但还算不上最佳的解决方案。 原因在于,关系数据库中实际上并不存在实体之间的关系。 这些关系需要在运行时计算,而复杂的关系还需要运用笛卡尔联接才能使用查询进行映射。 因此,在计算方面,随着关系的增加,运算的开销将呈指数级增大。 在某些情况下,尝试管理此类实体的关系数据库将不可用。
各种形式的“网络”数据库在关系数据库问世时即已出现,但与分层数据库一样,这些系统的普及也面临着重重困难。 对其的采用裹足不前的原因是一时缺少用例,且存储效率低下。 当今,可将图形数据库引擎视为网络数据库范型的再生。 这些系统的主要优势在于,关系作为“一等公民”存储在数据库中。 因此,关系的遍历可在恒定的时间内完成,而不会在每次计算新的联接或叉积时增大时间和复杂性。
如果在数据库中维护复杂的关系网络,可以考虑使用图形数据库,例如 Azure Cosmos DB for Gremlin。
Azure Cosmos DB 是一个多模型数据库服务,它为所有主要 NoSQL 模型类型(列系列、文档、图形和键-值)提供 API 投影。 API for Gremlin(图形)和 API for NoSQL 完全可互操作。 这种互操作性的优点是可以在编程级别切换不同的模型。 图形存储可以根据复杂的网络遍历和在同一存储中建模为文档记录的事务来查询。
关系数据库的另一个特殊特征是需要在设计时定义架构。 预定义架构在数据的引用完整性和一致性方面有好处。 但是,随着应用程序的增大,这种特征也会带来限制。 为了应对各个逻辑独立的模型中的架构变化,共享相同的表或数据库定义可能会变得越来越复杂。 将架构转移到应用程序并按记录进行管理往往可让此类用例受益。 这些用例要求数据库具有“架构不可知性”,并允许记录“自我描述”其中包含的数据。
如果管理的数据的结构经常高速变化,那么可以考虑使用一种更不确定架构的方法,即使用托管的 NoSQL 数据库服务,如 Azure Cosmos DB。 特别是,如果事务可能来自外部源,很难在整个数据库中强制实施一致性,请考虑使用 Azure Cosmos DB 等服务。
近年来,微服务模式已得到长足发展。 此模式根植于面向服务的体系结构。 在这些新式微服务体系结构中,数据传输的事实标准是 JSON,而 JSON 也正好是绝大多数面向文档的 NoSQL 数据库的存储媒介。 JSON 大大提高了 NoSQL 文档存储的无缝吻合性,可在复杂的微服务实施方案中实现持久性和同步(通过事件寻源模式)。 在这些体系结构中维护较传统的关系数据库可能要复杂得多。 这是因为,在 API 之间维护状态和同步需要更多的转换。 具体而言,相比 NoSQL 数据库,Azure Cosmos DB 提供许多功能来进一步提高基于 JSON 的微服务体系结构的无缝吻合度:
尽管实施 NoSQL 数据库可以获得一些明显的优势,但同时也要考虑到它存在的一些难题。 使用关系模型时,所呈现挑战的程度不一:
- 事务中包含许多关系,而这些关系指向同一实体。
- 事务要求对整个数据集实现强一致性。
第一个挑战需要非规范化的解决方案。 NoSQL 数据库的经验法则通常是去规范化,如前所述,它在分布式系统中产生更有效的读取。 但是,在使用这种方法时,会遇到一些设计难题。 让我们以一个类别和多个标记相关的产品为例:
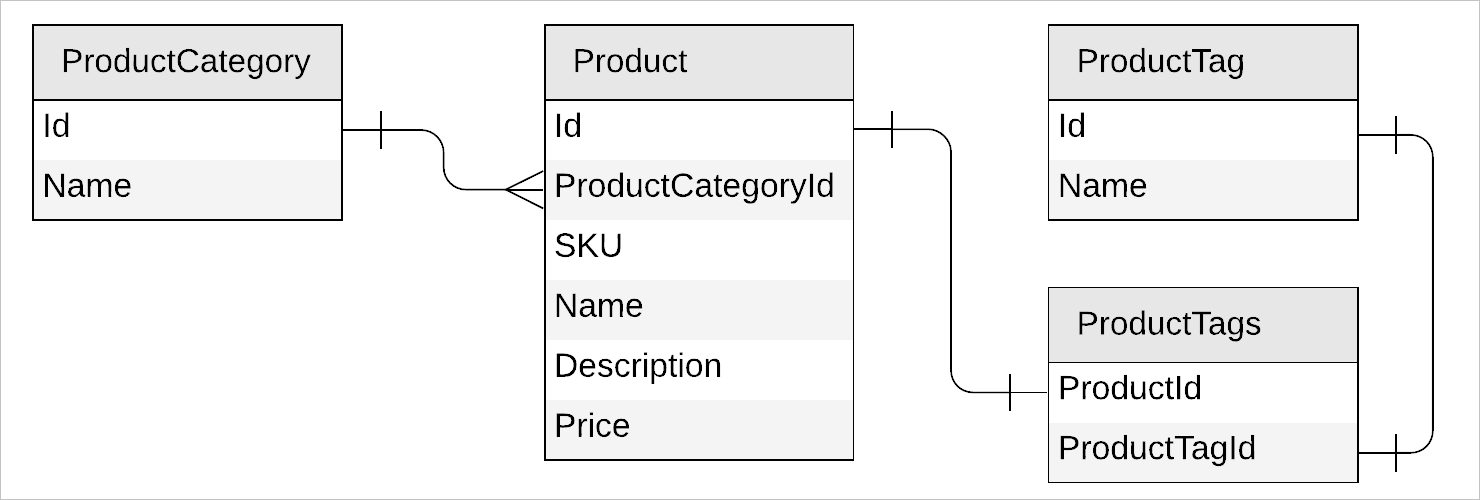
NoSQL 文档数据库的最佳做法是直接在“产品文档”中反规范化类别名称和标记名称。 为了保持类别、标记和产品同步;为了方便这一点的设计选项增加了维护复杂性。 发生这种复杂性的原因是数据在产品中的多个记录之间重复。 在关系数据库中,操作将是“一对多”关系的直接更新,以及用于检索数据的联接。
优势是反规范化记录中读取效率更高,并且随着概念上联接的实体数量的增加,效率进一步提高。 但是,正因为反规范化记录中读取效率随着联接实体数量的增加而提高,使实体保持同步的维护复杂性也随之增大。缓解这种利弊的方法之一是创建混合数据模型。
尽管 NoSQL 数据库提供更高的灵活性来处理这些利弊,但灵活性的增高也可能会产生更多的设计决策。 有关保持非规范化用户数据同步的详细信息,请参阅如何使用实际示例对 Azure Cosmos DB 上的数据进行建模和分区。 此示例包含一种保持非规范化数据同步的方法,其中用户不仅位于不同的分区中,而且位于不同的容器中。
至于强一致性,很少需要整个数据集都具有强一致性。 但是,如果存在这种强度的一致性需要,在分布式数据库中可能很难做到这一点。 为确保强一致性,需要在所有副本和区域之间同步数据,然后再允许客户端读取数据。 这种同步可能会增大读取延迟。
同样,Azure Cosmos DB 提供了比关系数据库更大的灵活性,以实现与此相关的各种权衡。 对于小规模实现,此方法可能会增加更多的设计注意事项。 有关详细信息,请参阅一致性、可用性和性能权衡。
了解如何管理 Azure Cosmos DB 帐户及其他概念: