Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Cassandra
Cassandra
![]() Gremlin
Gremlin
![]() Table
Table
This article will enumerate some of the key benefits of NoSQL databases over relational databases. We'll also discuss some of the challenges in working with NoSQL. For an in-depth look at the different data stores that exist, have a look at our article on choosing the right data store.
High throughput
One of the most obvious challenges when maintaining a relational database system is that most relational engines apply locks and latches to enforce strict ACID semantics. This approach has benefits in terms of ensuring a consistent data state within the database. However, there are heavy trade-offs with respect to concurrency, latency, and availability. Due to these fundamental architectural restrictions, high transactional volumes can result in the need to manually shard data. Implementing manual sharding can be a time consuming and painful exercise.
In these scenarios, distributed databases can offer a more scalable solution. However, maintenance can still be a costly and time-consuming exercise. Administrators may have to do extra work to ensure that the distributed nature of the system is transparent. They may also have to account for the "disconnected" nature of the database.
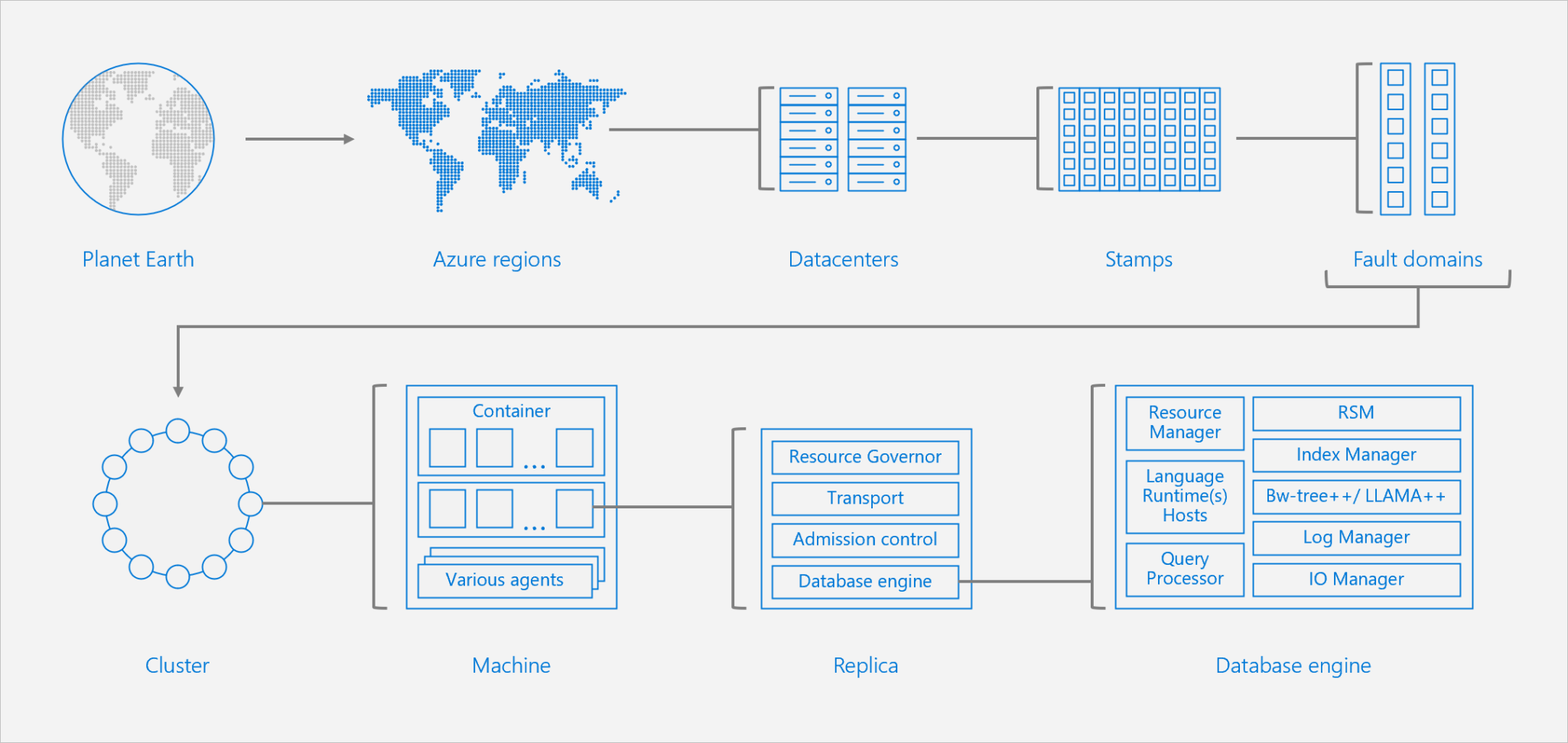
Azure Cosmos DB simplifies these challenges, by being deployed around China across all Azure China regions. Partition ranges are capable of being dynamically subdivided to seamlessly grow the database in line with the application, while simultaneously maintaining high availability. Fine-grained multi-tenancy and tightly controlled, cloud-native resource governance facilitates astonishing latency guarantees and predictable performance. Partitioning is fully managed, so administrators won't need to write code or manage partitions.
If your transactional volumes are reaching extreme levels, such as many thousands of transactions per second, you should consider a distributed NoSQL database. Consider Azure Cosmos DB for maximum efficiency, ease of maintenance, and reduced total cost of ownership.
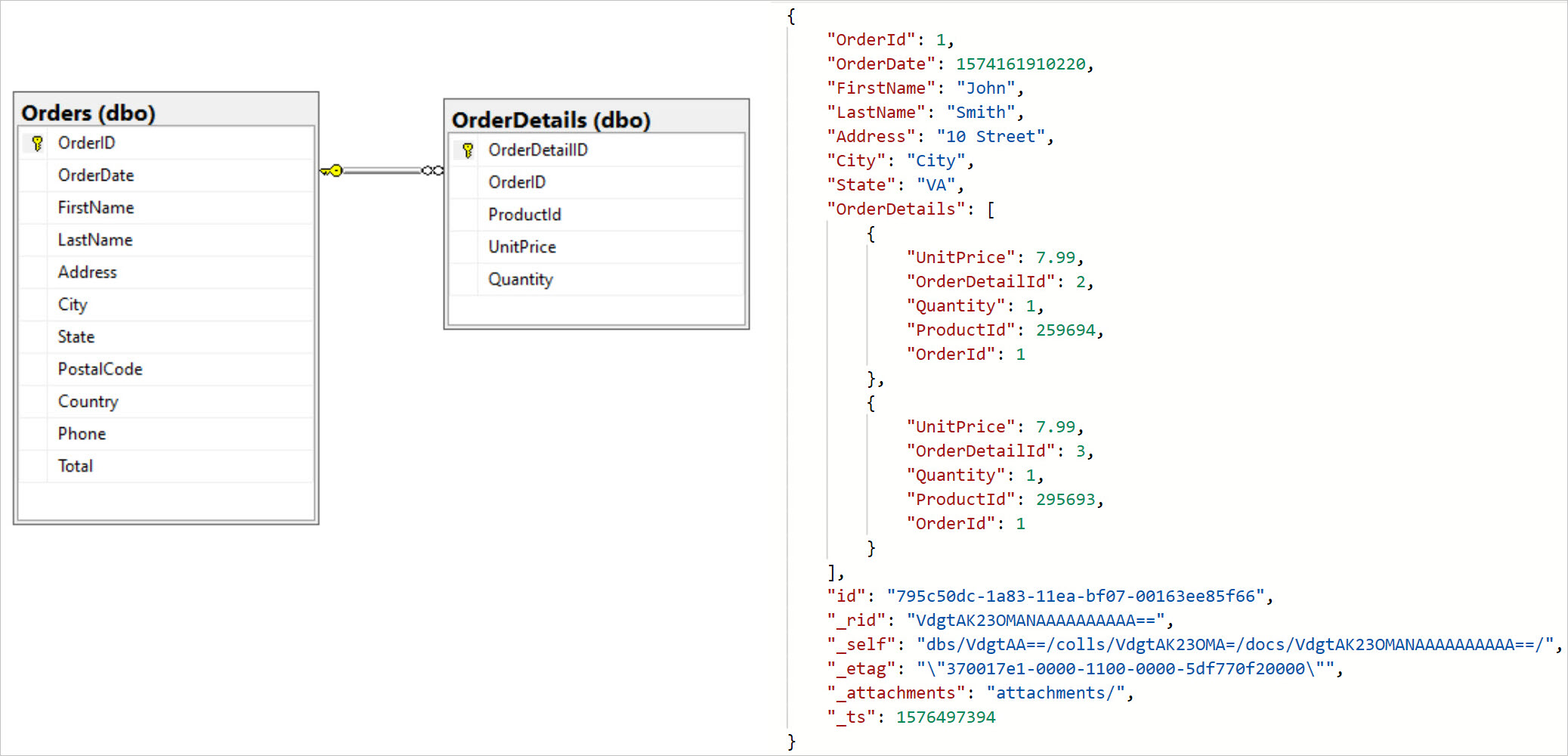
Hierarchical data
There are a significant number of use cases where transactions in the database can contain many parent-child relationships. These relationships can grow significantly over time, and prove difficult to manage. Forms of hierarchical databases did emerge during the 1980s, but were not popular due to inefficiency in storage. They also lost traction as Ted Codd's relational model became the de facto standard used by virtually all mainstream database management systems.
However, today the popularity of document-style databases has grown significantly. These databases might be considered a reinventing of the hierarchical database paradigm, now uninhibited by concerns around the cost of storing data on disk. As a result, maintaining many complex parent-child entity relationships in a relational database could now be considered an anti-pattern compared to modern document-oriented approaches.
The emergence of object oriented design, and the impedance mismatch that arises when combining it with relational models, also highlights an anti-pattern in relational databases for certain use cases. Hidden but often significant maintenance costs can arise as a result. Although ORM approaches have evolved to partly mitigate this, document-oriented databases nonetheless coalesce much better with object-oriented approaches. With this approach, developers are not forced to be committed to ORM drivers, or bespoke language specific OO Database engines . If your data contains many parent-child relationships and deep levels of hierarchy, you may want to consider using a NoSQL document database such as the Azure Cosmos DB SQL API.
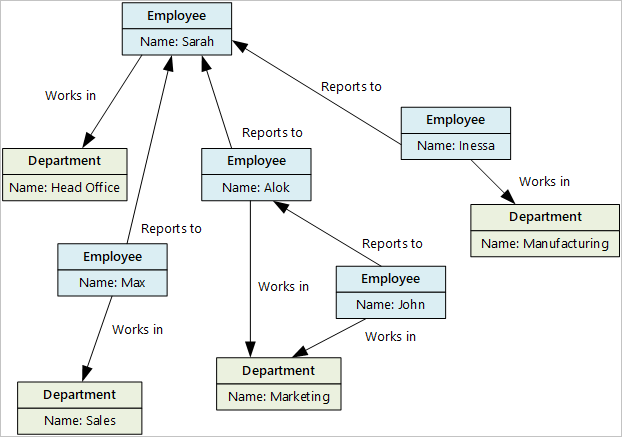
Complex networks and relationships
Ironically, given their name, relational databases present a less than optimal solution for modeling deep and complex relationships. The reason for this is that relationships between entities don't actually exist in a relational database. They need to be computed at runtime, with complex relationships requiring cartesian joins in order to allow mapping using queries. As a result, operations become exponentially more expensive in terms of computation as relationships increase. In some cases, a relational database attempting to manage such entities will become unusable.
Various forms of "Network" databases did emerge during the time that relational databases emerged, but as with hierarchical databases, these systems struggled to gain popularity. Slow adoption was due to a lack of use cases at the time, and storage inefficiencies. Today, graph database engines could be considered a re-emergence of the network database paradigm. The key benefit with these systems is that relationships are stored as "first class citizens" within the database. Thus, traversing relationships can be done in constant time, rather than increasing in time complexity with each new join or cross product.
If you're maintaining a complex network of relationships in your database, you may want to consider a graph database such as the Azure Cosmos DB for Gremlin.
Azure Cosmos DB is a multi-model database service, which offers an API projection for all the major NoSQL model types; Column-family, Document, Graph, and Key-Value. The API for Gremlin (graph) and NoSQL are fully interoperable. This interoperability has benefits for switching between different models at the programmability level. Graph stores can be queried in terms of both complex network traversals and transactions modeled as document records in the same store.
Fluid schema
Another particular characteristic of relational databases is that schemas are required to be defined at design time. Pre-defined schemas have benefits in terms of referential integrity and conformity of data. However, it can also be restrictive as the application grows. Responding to changes in the schema across logically separate models sharing the same table or database definition can become complex over time. Such use cases often benefit from the schema being devolved to the application to manage on a per record basis. These use cases require the database to be “schema agnostic” and allow records to be “self-describing” in terms of the data contained within them.
If you're managing data whose structures are constantly changing at a high rate, consider a more schema-agnostic approach using a managed NoSQL database service like Azure Cosmos DB. Particularly, if transactions can come from external sources where it's difficult to enforce conformity across the database, consider services like Azure Cosmos DB.
Microservices
The microservices pattern has grown significantly in recent years. This pattern has its roots in Service-Oriented Architecture. The de-facto standard for data transmission in these modern microservices architectures is JSON, which also happens to be the storage medium for the vast majority of document-oriented NoSQL Databases. This makes NoSQL document stores a much more seamless fit for both the persistence and synchronization (using event sourcing patterns) across complex Microservice implementations. More traditional relational databases can be much more complex to maintain in these architectures. This is due to the greater amount of transformation required for both state and synchronization across APIs. Azure Cosmos DB in particular has a number of features that make it an even more seamless fit for JSON-based Microservices Architectures than many NoSQL databases:
- a choice of pure JSON data types
- a JavaScript engine and query API built into the database.
- a state-of-the-art change feed which clients can subscribe to in order to get notified of modifications to a container.
Some challenges with NoSQL databases
Although there are some clear advantages when implementing NoSQL databases, there are also some challenges that you may want to take into consideration. These challenges may not be present to the same degree when working with the relational model:
- transactions with many relations pointing to the same entity.
- transactions requiring strong consistency across the entire dataset.
The first challenge requires a denormalized solution. The rule-of-thumb in NoSQL databases is generally denormalization, which as articulated earlier, produces more efficient reads in a distributed system. However, there are some design challenges that come into play with this approach. Let’s take an example of a product that’s related to one category and multiple tags:

A best practice approach in a NoSQL document database would be to denormalize the category name and tag names directly in a “product document”. In order to keep categories, tags, and products in sync; the design options to facilitate this have added maintenance complexity. This complexity occurs because the data is duplicated across multiple records in the product. In a relational database, the operation would be a straightforward update in a “one-to-many” relationship, and a join to retrieve the data.
The trade-off is that reads are more efficient in the denormalized record, and become increasingly more efficient as the number of conceptually joined entities increases. However, just as the read efficiency increases with increasing numbers of joined entities in a denormalize record, so too does the maintenance complexity of keeping entities in sync. One way of mitigating this trade-off is to create a hybrid data model.
While there's more flexibility available in NoSQL databases to deal with these trade-offs, increased flexibility can also produce more design decisions. For more information about keeping denormalized user data in sync, see how to model and partition data on Azure Cosmos DB using a real-world example. This example includes an approach for keeping denormalized data in sync where users not only sit in different partitions, but in different containers.
With respect to strong consistency, it's rare that strong consistency will be required across the entire data set. However, cases where this level of consistency is necessary can be a challenge in distributed databases. To ensure strong consistency, data needs to be synchronized across all replicas and regions before allowing clients to read it. This synchronization can increase the latency of reads.
Again, Azure Cosmos DB offers more flexibility than relational databases for the various trade-offs that are relevant here. For small scale implementations, this approach may add more design considerations. For more information, see consistency, availability, and performance tradeoffs.
Next steps
Learn how to manage your Azure Cosmos DB account and other concepts:
- How-to manage your Azure Cosmos DB account
- Multiple-regional distribution
- Consistency levels
- Working with Azure Cosmos DB containers and items
- VNET service endpoint for your Azure Cosmos DB account
- IP-firewall for your Azure Cosmos DB account
- How-to add and remove Azure regions to your Azure Cosmos DB account
- Azure Cosmos DB SLAs