本文提供了在 Azure Kubernetes 服务 (AKS) 工作负载的部署和群集级别实现的群集可靠性的最佳做法。 本文适用于负责在 AKS 中部署和管理应用程序的群集操作员和开发人员。
本文中的最佳做法分为以下类别:
| 类别 | 最佳实践 |
|---|---|
| 部署级别最佳做法 | • Pod CPU 和内存限制 • 垂直 Pod 自动缩放程序 (VPA) • Pod 中断预算 (PDB) • 升级期间的高可用性 • Pod 拓扑分布约束 • 就绪情况、运行情况和启动探测 • 多副本应用程序 |
| 群集和节点池级别最佳做法 | • 可用性区域 • 群集自动缩放 • 标准负载均衡器 • 系统节点池 • 升级节点池的配置 • 映像版本 • 用于动态 IP 分配的 Azure CNI • v5 SKU 虚拟机 • 不要使用 B 系列 VM • 高级磁盘 • 容器洞察 • Azure Policy |
部署级别最佳做法
以下部署级别最佳做法有助于确保 AKS 工作负载的高可用性和可靠性。 这些最佳做法是可在 POD 和部署的 YAML 文件中实现的本地配置。
注意
请确保每次将更新部署到应用程序时都实现这些最佳做法。 否则,可能会遇到应用程序可用性和可靠性问题,例如意外的应用程序停机。
Pod CPU 和内存限制
最佳实践指南
为所有 Pod 设置 Pod CPU 和内存限制,以确保 Pod 不会消耗节点上的所有资源,并在服务威胁(例如,DDoS 攻击)期间提供保护。
Pod CPU 和内存限制定义 Pod 可使用的最大 CPU 和内存量。 当 Pod 超出其定义的限制时,它会被标记为候选删除。 有关详细信息,请参阅Kubernetes 中的 CPU 资源单元和Kubernetes 中的内存资源单元。
设置 CPU 和内存限制有助于维护节点运行状况,并最大程度地减少对节点上其他 Pod 的影响。 请避免设置的 pod 限制超过节点可以支持的限制。 每个 AKS 节点将为核心 Kubernetes 组件保留一定的 CPU 和内存量。 如果设置的 Pod 限制高于节点可以支持的限制,则应用程序可能会尝试消耗过多的资源,并对节点上的其他 Pod 产生负面影响。 群集管理员需要针对需设置资源请求和限制的命名空间设置资源配额。 有关详细信息,请参阅在 AKS 中强制实施资源配额。
在以下示例 Pod 定义文件中,resources部分设置 Pod 的 CPU 和内存限制:
kind: Pod
apiVersion: v1
metadata:
name: mypod
spec:
containers:
- name: mypod
image: mcr.azk8s.cn/oss/nginx/nginx:1.15.5-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
提示
可以使用kubectl describe node命令查看节点的 CPU 和内存容量,如以下示例所示:
kubectl describe node <node-name>
# Example output
Capacity:
cpu: 8
ephemeral-storage: 129886128Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 32863116Ki
pods: 110
Allocatable:
cpu: 7820m
ephemeral-storage: 119703055367
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 28362636Ki
pods: 110
有关详细信息,请参阅将 CPU 资源分配到容器和 Pod和将内存资源分配给容器和 Pod。
垂直 Pod 自动缩放程序 (VPA)
最佳实践指南
使用垂直 Pod 自动缩放程序(VPA)根据 Pod 的实际使用情况自动调整 Pod 的 CPU 和内存请求。
虽然不直接通过 Pod YAML 实现,但垂直 Pod 自动缩放程序(VPA)通过自动调整 Pod 的 CPU 和内存请求来帮助优化资源分配。 这可确保应用程序具有高效运行所需的资源,而无需过度预配或预配不足。
VPA 以三种模式运行:
- 关闭:仅提供建议而不应用更改。
- 自动:在每次 Pod 重启时自动更新 Pod 资源请求。
- 初始:仅在 Pod 创建过程中设置资源请求。
以下示例演示如何在 Kubernetes 中配置 VPA 资源:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: my-deployment
updatePolicy:
updateMode: "Auto" # Options: Off, Auto, Initial
有关详细信息,请参阅垂直 Pod 自动缩放程序文档。
Pod 中断预算 (PDB)
最佳实践指南
使用 Pod 中断预算 (PDB) 确保在自愿性中断(例如,升级操作或意外删除 Pod)期间,最小的 Pod 数保持可用。
Pod 中断预算 (PDB)允许定义部署或副本集在自愿性中断(例如,升级操作或意外删除 Pod)期间的响应方式。 使用 PDB,可以定义最小或最大的不可用资源计数。 PDB 仅在自愿中断的情况下影响逐出 API。
例如,假设需要执行群集升级并已定义 PDB。 在执行群集升级之前,Kubernetes 计划程序可确保 PDB 中定义的最小 Pod 数可用。 如果升级会导致可用 Pod 数低于 PDB 中定义的最小值,计划程序会在允许升级继续之前在其他节点上计划额外的 Pod。 如果未设置 PDB,则计划程序对升级期间可能不可用的 Pod 数没有任何约束,这可能会导致资源缺少和潜在的群集中断。
在以下示例 PDB 定义文件中,minAvailable字段设置在自愿中断期间必须保持可用的最小 Pod 数量。 该值可以是绝对数(例如,3)或所需 pod 数的百分比(例如,10%)。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: mypdb
spec:
minAvailable: 3 # Minimum number of pods that must remain available during voluntary disruptions
selector:
matchLabels:
app: myapp
有关详细信息,请参阅使用 PDB 规划可用性和为应用程序指定中断预算。
Pod 的正常终止
最佳实践指南
利用
PreStop挂钩并配置适当的terminationGracePeriodSeconds值,以确保 Pod 正常终止。
正常终止可确保 Pod 有足够的时间来清理资源、完成正在进行的任务,或在终止之前通知依赖服务。 对于需要正确关闭过程的有状态应用程序或服务,这尤其重要。
使用 PreStop 挂钩
在由于 API 请求或管理事件(例如抢占、资源争用或存活/启动探测失败)导致容器终止之前,会立即调用 PreStop 挂钩。 挂钩 PreStop 允许在容器停止之前定义要执行的自定义命令或脚本。 例如,可以使用它刷新日志、关闭数据库连接或通知其他服务关闭。
以下示例 Pod 定义文件演示了如何使用PreStop挂钩确保容器正常终止:
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "nginx -s quit; while killall -0 nginx; do sleep 1; done"]
配置 terminationGracePeriodSeconds
该 terminationGracePeriodSeconds 字段指定 Kubernetes 在强制终止 Pod 之前等待的时间量。 此时间段包括执行 PreStop 挂钩所需的时间。 如果 PreStop 挂钩未在宽限期内完成,Pod 将强制终止。
例如,以下 Pod 定义设置 30 秒的终止宽限期:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
terminationGracePeriodSeconds: 30
containers:
- name: example-container
image: nginx
升级期间的高可用性
使用 maxSurge 实现更快的更新
最佳实践指南
配置
maxSurge字段以允许在滚动更新期间创建其他 Pod,从而在最短的停机时间内实现更快的更新。
该 maxSurge 字段指定在滚动更新期间可以超出所需 Pod 数之外创建的其他 Pod 的最大数目。 这允许在旧 Pod 终止之前创建并准备好新 Pod,确保更新速度更快,并降低停机风险。
以下示例部署清单演示如何配置 maxSurge:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 33% # Maximum number of additional pods created during the update
通过将 maxSurge 设置为 3,此配置可确保在滚动更新期间最多可以创建三个额外的 Pod,从而加快部署过程,同时保持应用程序的可用性。
有关详细信息,请参阅 Kubernetes 中的滚动更新。
使用 maxUnavailable 进行受控更新
最佳实践指南
配置
maxUnavailable字段以限制在滚动更新期间不可用的 Pod 数,确保应用程序保持运行状态,且中断最少。
此 maxUnavailable 字段对于需要计算密集型或具有特定基础结构需求的应用程序特别有用。 它指定滚动更新期间在任何给定时间不可用的最大 Pod 数。 这可确保在部署新 Pod 并终止旧 Pod 时,应用程序的一部分保持正常运行。
可以将 maxUnavailable 设置为绝对值(例如 1)或所需的 Pod 数量的百分比(例如 25%)。 例如,如果您的应用程序有四个副本,并且您将设置从maxUnavailable更改为1,Kubernetes 可确保在更新过程中至少有三个 Pod 仍然可用。
以下示例部署清单演示如何配置 maxUnavailable:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 4
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1 # Maximum number of pods that can be unavailable during the update
在此示例中,将 maxUnavailable 设置为 1 可确保在滚动更新期间在任何给定时间都不可用。 此配置非常适合需要专用计算的应用程序,其中维护最低级别的服务可用性至关重要。
有关详细信息,请参阅 Kubernetes 中的滚动更新。
Pod拓扑扩展约束
最佳实践指南
使用 Pod 拓扑分布约束来确保 Pod 分布在不同的节点或区域,以提高可用性和可靠性。
可以使用 Pod 拓扑分布约束来控制 Pod 如何根据节点的拓扑在群集之间分布,并将 Pod 分散到不同的节点或区域,以提高可用性和可靠性。
以下示例 Pod 定义文件演示如何使用 topologySpreadConstraints 字段将 Pod 分散到不同节点:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # optional
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # optional
nodeAffinityPolicy: [Honor|Ignore] # optional
nodeTaintsPolicy: [Honor|Ignore] # optional
有关详细信息,请参阅 Pod 拓扑分布约束。
就绪情况、运行情况和启动探测
最佳实践指南
为提高在高负载时的弹性并减少容器重启,请配置就绪探测、存活探测和启动探测。
就绪情况探测
在 Kubernetes 中,kubelet 使用就绪情况探测了解容器什么时候准备好开始接受流量。 当所有容器都准备就绪后,Pod 被视为就绪。 当 pod 未准备好时,会被从负载均衡器中删除。 有关详细信息,请参阅Kubernetes 中的就绪情况探测。
以下示例 Pod 定义文件显示了就绪情况探测配置:
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
有关详细信息,请参阅配置就绪情况探测。
存活探测
在 Kubernetes 中,kubelet 使用存活探针判断何时需要重启容器。 如果容器的存活探针失败,会重启容器。 有关详细信息,请参阅Kubernetes 中的运行情况探测。
以下示例 Pod 定义文件包含了活跃性探测器配置:
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
另一种运行情况探测使用 HTTP GET 请求。 以下示例 Pod 定义文件显示了 HTTP GET 请求运行情况探测配置:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: registry.k8s.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
有关详细信息,请参阅配置运行情况探测和定义运行情况 HTTP 请求。
启动探测
在 Kubernetes 中,kubelet 使用启动探测了解容器应用程序什么时候已启动。 配置启动探测时,在启动探测成功之前,就绪情况和运行情况探测不会启动,确保就绪情况和运行情况探测不会干扰应用程序启动。 有关详细信息,请参阅Kubernetes 中的启动探测。
以下示例 Pod 定义文件显示了启动探测配置:
startupProbe:
httpGet:
path: /healthz
port: 8080
failureThreshold: 30
periodSeconds: 10
多副本应用程序
最佳实践指南
至少部署应用程序的两个副本,以确保节点关闭场景中的高可用性和复原能力。
在 Kubernetes 中,可以使用部署中的replicas字段指定要运行的 Pod 数。 运行应用程序的多个实例有助于确保节点关闭场景中的高可用性和复原能力。 如果已启用可用性区域,可以使用replicas字段指定要跨多个可用性区域运行的 Pod 数。
以下示例 Pod 定义文件演示了如何使用replicas字段指定要运行的 Pod 数:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
有关详细信息,请参阅AKS 的建议主动-主动高可用性解决方案概述和部署规范中的副本。
群集和节点池级别最佳做法
以下群集和节点池级别最佳做法有助于确保 AKS 群集的高可用性和可靠性。 可以在创建或更新 AKS 群集时实现这些最佳做法。
可用性区域
最佳实践指南
创建 AKS 群集时使用多个可用性区域,以确保区域关闭场景中的高可用性。 请记住,创建群集后无法更改可用性区域配置。
可用性区域是区域内数据中心的分隔组。 这些区域足够近,可以彼此建立低延迟连接,但相距足够远,以减少多个区域受到本地中断或天气影响的可能性。 使用可用性区域有助于数据在区域关闭场景中保持同步和可访问。 有关详细信息,请参阅在多个区域中运行。
群集自动缩放
最佳实践指南
使用群集自动缩放确保群集可以处理增加的负载并在低负载期间降低成本。
若要跟上 AKS 中的应用程序需求,可能需要调整运行工作负荷的节点数。 群集自动缩放程序组件可监视群集中由于资源约束而无法进行计划的 Pod。 当群集自动缩放程序检测到问题时,它会纵向扩展节点池中的节点数来满足应用程序需求。 它还会定期检查节点是否没有正在运行的 Pod,并根据需要缩减节点数量。 有关详细信息,请参阅AKS 中的群集自动缩放。
对于 AKS Standard,可以在创建群集时使用 --enable-cluster-autoscaler 参数:
az aks create \
--resource-group myResourceGroup \
--name myAKSCluster \
--node-count 2 \
--vm-set-type VirtualMachineScaleSets \
--load-balancer-sku standard \
--enable-cluster-autoscaler \
--min-count 1 \
--max-count 3 \
--generate-ssh-keys
还可以更改群集范围内的自动缩放程序配置文件中的默认值,从而在现有节点池上启用群集自动缩放程序,并配置群集自动缩放程序的更精细的详细信息。
有关详细信息,请参阅在 AKS 中使用群集自动缩放程序。
入口和出口可靠性
最佳实践指南
使用符合 AKS 群集模式和可靠性要求的群集网络模型。
对于 AKS 标准版,标准负载均衡器仍然是入站和出站流量方案的常见和建议的可靠性选择。
如果你使用的是 AKS 标准层,则以下标准负载均衡器指南仍然适用:
标准负载均衡器
最佳实践指南
使用标准负载均衡器提供更高的可靠性和资源,跨多个数据中心支持多个可用性区域、HTTP 探测和功能。
在 Azure 中,标准负载均衡器 SKU 旨在在需要高性能和低延迟时为网络层流量进行负载均衡。 标准负载均衡器在区域内和跨区域路由流量,并路由到可用区以提升高可用性。 建议使用标准 SKU,并在创建 AKS 群集时使用默认 SKU。
重要
从 2025 年 9 月 30 日开始,Azure Kubernetes 服务(AKS)不再支持基本负载均衡器。 为了避免任何潜在的服务中断,我们建议使用标准负载均衡器进行新部署 ,并将任何现有部署升级到标准负载均衡器。 有关此停用的详细信息,请参阅 停用 GitHub 问题和Azure 更新停用公告。 若要随时了解公告和更新,请关注AKS 发行说明。
以下示例演示了使用标准负载均衡器的LoadBalancer服务清单:
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/azure-load-balancer-ipv4 # Service annotation for an IPv4 address
name: azure-load-balancer
spec:
type: LoadBalancer
ports:
- port: 80
selector:
app: azure-load-balancer
有关详细信息,请参阅在 AKS 中使用标准负载均衡器。
系统节点池
使用专用系统节点池
最佳实践指南
使用系统节点池确保没有其他用户应用程序在同一节点上运行,这可能导致资源短缺并影响系统 Pod 的运行。
使用专用系统节点池确保没有其他用户应用程序在同一节点上运行,这可能会因争用条件导致资源短缺和潜在的群集中断。 要使用专用系统节点池,可以在系统节点池上使用CriticalAddonsOnly污点。 有关详细信息,请参阅在 AKS 中使用系统节点池。
系统节点池的自动缩放
最佳实践指南
配置系统节点池的自动缩放程序,以设置节点池的最小和最大缩放限制。
在节点池上使用自动缩放程序为节点池配置最小和最大缩放限制。 系统节点池应始终能够缩放以满足系统 Pod 的需求。 如果系统节点池无法缩放,群集会耗尽资源,以帮助管理计划、缩放和负载均衡,这可能会导致无响应群集。
有关详细信息,请参阅在节点池上使用群集自动缩放程序。
每个系统节点池至少有两个节点
最佳实践指南
确保系统节点池至少有两个节点,以确保针对冻结/升级方案提供复原能力,这可能导致节点重启或关闭。
在 AKS 标准版中,系统节点池应至少有两个节点,以提高重启或升级事件期间的复原能力。
系统节点池用于运行系统 Pod,例如 kube-proxy、coredns 和 Azure CNI 插件。 建议 确保系统节点池至少有两个节点 ,以确保针对冻结/升级方案提供复原能力,这可能导致节点重启或关闭。 有关详细信息,请参阅在 AKS 中管理系统节点池。
升级节点池的配置
- AKS 标准:操作员显式配置升级通道和节点池设置,例如 maxSurge 和 maxUnavailable。
使用 maxSurge 进行节点池升级
最佳实践指南
配置
maxSurge节点池升级的设置以提高可靠性和最大程度地减少升级作期间的停机时间。
该 maxSurge 设置指定在升级期间可以创建的其他节点的最大数目。 这可确保在清空和删除旧节点之前预配并准备好新节点,从而减少应用程序停机的风险。
例如,以下 Azure CLI 命令将节点池的 maxSurge 设置为 1:
az aks nodepool update \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name myNodePool \
--max-surge 1
通过配置 maxSurge,可以确保升级的执行速度更快,同时维护应用程序可用性。
有关详细信息,请参阅 AKS 中的升级节点池。
使用 maxUnavailable 进行节点池升级
最佳实践指南
配置
maxUnavailable节点池升级的设置,以确保在升级作期间应用程序可用性。
该 maxUnavailable 设置指定在升级期间可能不可用的最大节点数。 这可确保在升级节点时,节点池的一部分保持正常运行。
例如,以下 Azure CLI 命令将节点池的 maxUnavailable 设置为 1:
az aks nodepool update \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name myNodePool \
--max-unavailable 1
通过配置 maxUnavailable,可以控制升级对工作负荷的影响,确保在此过程中有足够的资源可用。
有关详细信息,请参阅 AKS 中的升级节点池。
网络加速技术
最佳实践指南
使用加速网络在 VM 上提供更低的延迟、减少抖动并降低 CPU 利用率。
加速网络在受支持的 VM 类型上启用单根 I/O 虚拟化 (SR-IOV),从而大大提高了网络性能。
下图说明了在有和无加速网络的情况下,两个 VM 如何通信:
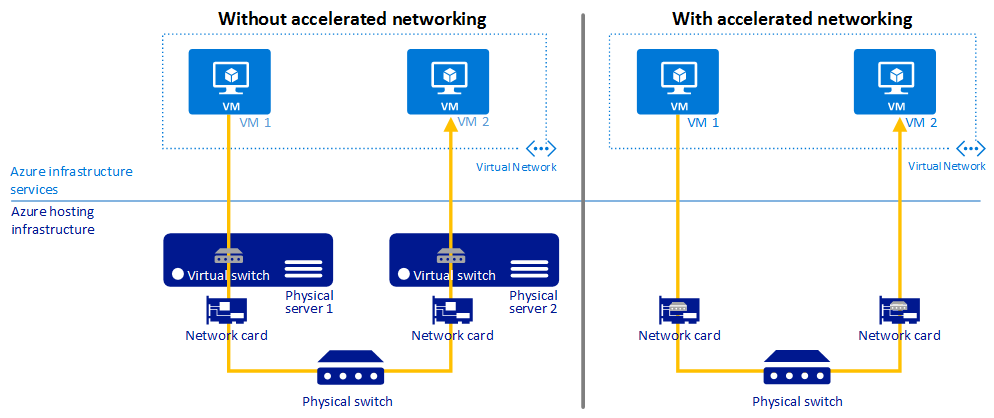
有关详细信息,请参阅加速网络概述。
映像版本
最佳实践指南
图像不应使用
latest标记。
容器映像标记
使用latest标签可能会导致行为不可预测,并且使得难以追踪群集中正在运行的具体镜像版本。 在生成和运行时,通过在容器中集成和运行扫描及修正工具可最大程度降低风险。 有关详细信息,请参阅AKS 中容器映像管理的最佳做法。
节点映像升级
AKS 为节点 OS 映像升级提供了多个自动升级通道。 可以使用这些通道控制升级的时间。 建议加入这些自动升级通道,以确保节点正在运行最新的安全修补程序和更新。 有关详细信息,请参阅在 AKS 中自动升级节点 OS 映像。
适用于生产工作负载的标准定价层级
最佳实践指南
对生产工作负载使用标准定价层级,以获得更高的群集可靠性和更多资源,支持单个群集最多 5,000 个节点,并默认启用正常运行时间 SLA。 如果需要 LTS,请考虑使用高级级别。
Azure Kubernetes 服务 (AKS) 标准层为生产工作负载提供具有经济担保的 99.9% 正常运行时间服务级别协议 (SLA)。 标准层还提供更高的群集可靠性和资源,支持群集中最多 5,000 个节点,以及默认启用的运行时间 SLA。 有关详细信息,请参阅AKS 群集管理的定价层。
用于 DNS 可靠性的 LocalDNS
最佳实践指南
在节点池上启用 LocalDNS 以提高 DNS 解析可靠性,并在暂时性 DNS 中断期间维护服务连接。
LocalDNS 在每个 AKS 节点上部署 DNS 代理,提供低延迟、可复原的 DNS 解析。 通过在本地解析查询,LocalDNS 可减少对集中式 CoreDNS Pod 的依赖,并避免 conntrack 表耗尽,这是在高吞吐量环境中丢弃 DNS 查询的常见原因。 LocalDNS 还支持在上游 DNS 不可用时,提供陈旧的缓存响应服务,以帮助在中断期间维护 Pod 的连接。 有关配置说明和最佳做法,请参阅 在 AKS 中配置 LocalDNS。
用于动态 IP 分配的 Azure CNI
最佳实践指南
为 Azure CNI 配置动态 IP 分配,以提高 IP 利用率,并防止 AKS 群集的 IP 耗尽。
对于 AKS 标准版,Azure CNI 动态 IP 分配有助于提高 IP 利用率并防止 IP 耗尽。
Azure CNI 的动态 IP 分配功能从一个独立于托管 AKS 群集的子网中分配 Pod IP,并提供以下优势:
- 更高的 IP 利用率:IP 地址是从 Pod 子网动态分配给群集 Pod 的。 与传统的 CNI 解决方案(为每个节点静态分配 IP)相比,此功能可以优化群集中的 IP 利用率。
- 可缩放性和灵活性:可以单独缩放节点和 Pod 子网。 单个 Pod 子网可以在群集的多个节点池之间或在同一 VNet 中部署的多个 AKS 群集之间共享。 你还可以为节点池配置单独的 Pod 子网。
- 高性能:由于为 Pod 分配了虚拟网络 IP,因此它们可以直接连接到 VNet 中的其他群集 Pod 和资源。 此解决方案支持非常大的群集,且丝毫不会降低性能。
- 用于 Pod 的单独 VNet 策略:由于 Pod 具有单独的子网,因此你可以单独为它们配置不同于节点策略的 VNet 策略。 这样可以实现许多有用的方案,例如只允许 Pod 而不允许节点连接 Internet,使用 Azure NAT 网关修复节点池中 Pod 的源 IP 以及使用 NSG 筛选节点池之间的流量。
- Kubernetes 网络策略:Azure 网络策略和 Calico 都适用于此解决方案。
有关详细信息,请参阅为 IP 的动态分配和增强的子网支持配置 Azure CNI 网络。
v5 SKU 虚拟机组
最佳实践指南
使用 v5 VM SKU 提高更新期间和之后的性能,减少整体影响,并为应用程序建立更可靠的连接。
对于 AKS 中的节点池,请使用具有临时 OS 磁盘的 v5 SKU 虚拟机,为 kube-system 的 Pod 提供充足的计算资源。 有关详细信息,请参阅 在 AKS 中实现性能和缩放大型工作负载的最佳做法。
不要使用 B 系列 VM
最佳实践指南
不要对 AKS 群集使用 B 系列 VM,因为它们性能低,并且不适用于 AKS。
B 系列 VM 的性能低,不适用于 AKS。 相反,建议使用v5 SKU VM。
高级磁盘
最佳实践指南
使用高级磁盘在一个虚拟机 (VM) 中实现 99.9% 的可用性。
Azure 高级磁盘提供一致的亚毫秒级磁盘延迟和高 IOPS 和吞吐量。 高级磁盘旨在为 VM 提供低延迟、高性能和一致的磁盘性能。
以下示例 YAML 清单显示了高级磁盘的存储类定义:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: premium2-disk-sc
parameters:
cachingMode: None
skuName: PremiumV2_LRS
DiskIOPSReadWrite: "4000"
DiskMBpsReadWrite: "1000"
provisioner: disk.csi.azure.com
reclaimPolicy: Delete
volumeBindingMode: Immediate
allowVolumeExpansion: true
有关详细信息,请参阅在 AKS 上使用 Azure 高级 SSD v2 磁盘。
容器洞察
最佳实践指南
启用 Container Insights 以监视和诊断容器化应用程序的性能。
Container Insights是 Azure Monitor 的一项功能,它从 AKS 收集和分析容器日志。 可以使用视图集合和预生成的工作簿分析收集的数据。
可以通过多种方法在 AKS 群集中启用容器 Insights 监控。 以下示例演示如何使用 Azure CLI在现有 AKS 标准群集上启用容器见解监视:
az aks enable-addons -a monitoring --name myAKSCluster --resource-group myResourceGroup
有关详细信息,请参阅为 Kubernetes 群集启用监视。
Azure Policy
最佳实践指南
使用 Azure Policy 为 AKS 群集应用并强制实施安全性和合规性要求。
可以使用 Azure Policy 在 AKS 群集上应用和强制实施内置的安全策略。 Azure Policy 有助于强制执行组织标准并进行大规模的合规性评估。 安装适用于 AKS 的 Azure Policy 加载项后,可将各个策略定义或策略定义组(称为计划)应用于群集。
有关详细信息,请参阅使用 Azure Policy 保护 AKS 群集。
相关内容
本文重点介绍 Azure Kubernetes 服务 (AKS) 群集的部署和群集可靠性的最佳做法。 有关相关主题的详细信息,请参阅以下文章: