Azure 应用程序网关监视其后端池中所有服务器的运行状况,并自动停止向其认为运行不正常的任何服务器发送流量。 探测继续监视此类运行不正常的服务器,只要探测检测到流量正常,网关就会再次将流量路由到该服务器。
默认探测使用关联后端设置的端口号和其他预设配置。 可以使用自定义探测按照自己的方式来配置。
探测行为
源 IP 地址
探测的源 IP 地址取决于后端服务器类型:
- 如果后端池中的服务器是公共终结点,则源地址是应用程序网关的前端公共 IP 地址。
- 如果后端池中的服务器是专用终结点,则源 IP 地址将来自应用程序网关子网的地址空间。
探测操作
在配置规则后,网关立即启动探测,方法是将规则与后端设置和后端池(当然还有侦听器)相关联。 图示显示网关自主探测所有后端池服务器。 开始到达的传入请求仅发送到运行正常的服务器。 默认情况下,后端服务器标记为运行不正常,直到收到成功的探测响应。
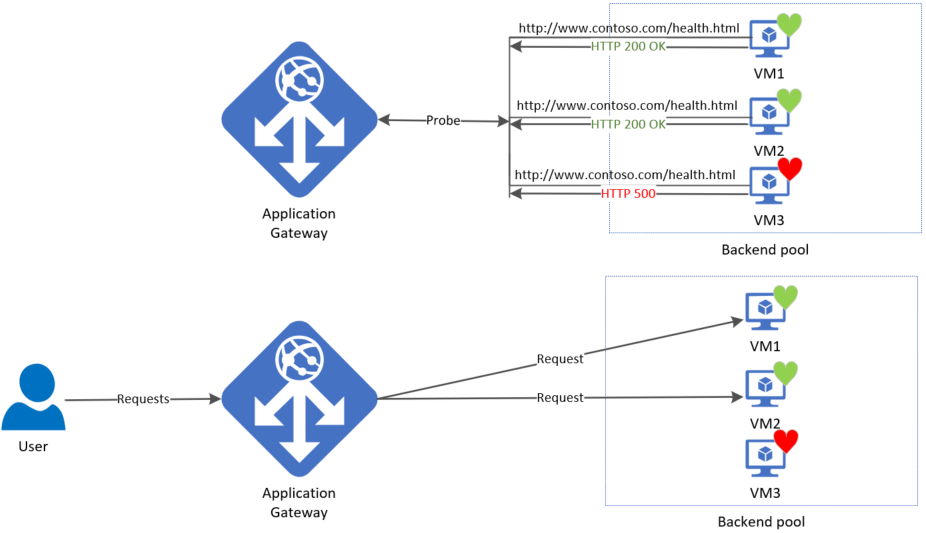
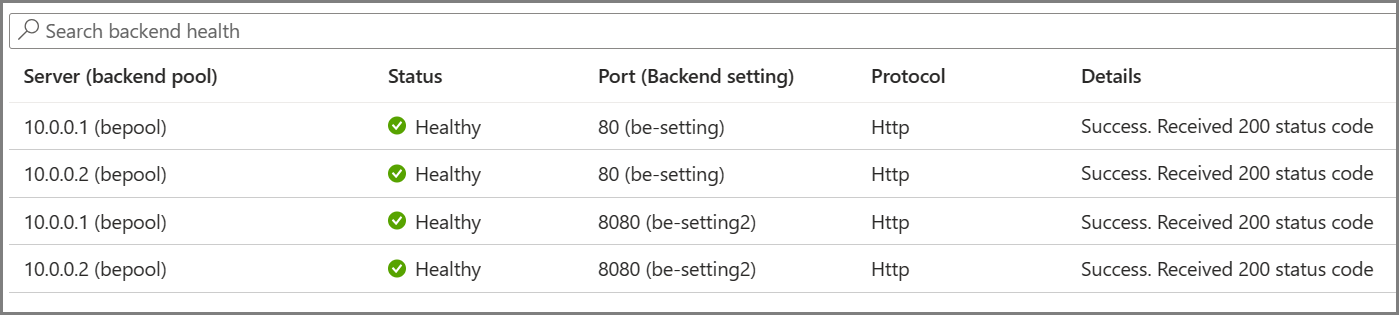
所需的探测是根据后端服务器和后端设置的唯一组合确定的。 例如,考虑一个拥有两个服务器和两个后端设置的单个后端池,每个都有不同的端口号。 当这些不同的后端设置使用各自的规则与同一后端池相关联时,网关会为每个服务器和后端设置的组合创建探测。 可以在后端运行状况页上查看此信息。
此外,应用程序网关的所有实例都独立地探测后端服务器。
探测间隔
相同的探测配置适用于应用程序网关的每个实例。 例如,如果应用程序网关有两个实例,并且探测间隔设置为 20 秒,则这两个实例将每隔 20 秒发送一次运行状况探测。
探测检测到失败的响应后,“不正常阈值”计数器会关闭,如果连续失败计数与配置的阈值匹配,则将服务器标记为运行不正常。 因此,如果将此运行不正常阈值设置为 2,则下一次探测将首先检测到此次故障。 然后,应用程序网关将在连续 2 个失败的探测后将服务器标记为运行不正常 [第一次检测 20 秒 +(连续 2 个失败的探测 * 20 秒)]。
注意
后端运行状况报告根据相应的探测的刷新间隔进行更新,不依赖于用户的请求。
默认的运行状况探测
如果未设置任何自定义探测配置,应用程序网关自动配置默认运行状况探测。 监视行为的工作方式是向在后端池中配置的 IP 地址或 FQDN 发出 HTTP GET 请求。 对于默认探测,如果后端 http 设置是针对 HTTPS 配置的,则探测会使用 HTTPS 测试后端服务器的运行状况。
例如:将应用程序网关配置为使用 A、B 和 C 后端服务器来接收端口 80 上的 HTTP 网络流量。 默认健康监控每隔 30 秒测试三台服务器,以确保在每个请求的 30 秒超时时间内接收到健康的 HTTP 响应。 正常的 HTTP 响应具有 200 到 399 的状态代码。 在这种情况下,运行状况探测的 HTTP GET 主机标头显示为 http://127.0.0.1/,除非后端 设置中配置了主机名。
如果服务器 A 的默认探测检查失败,应用程序网关将停止将请求转发到此服务器。 默认探测仍继续每隔 30 秒检查服务器 A。 当服务器 A 成功响应默认运行状况探测发出的请求时,应用程序网关会开始再次将请求转发到此服务器。
默认的运行状况探测设置
| 探测属性 | 值 | 说明 |
|---|---|---|
| 探测 URL | <协议>://127.0.0.1:<端口>/ | 协议和端口继承自探测关联的后端设置。 默认主机为 127.0.0.1,除非在关联的后端设置中指定了一个主机。 |
| 时间间隔 | 30 | 下一个健康探测发送前的等待时间(以秒为单位)。 |
| 超时 | 30 | 将探测标记为不正常前,应用程序网关等待探测响应的时间(以秒为单位)。 如果探测返回为正常,则相应的后端立即被标记为正常。 |
| 不健康阈值 | 3 | 控制在常规健康探测失败时要发送的探测数。 在 v1 SKU 中,快速连续发送这些额外的运行状况探测,以快速确定后端的运行状况,并且无需等待探测时间间隔。 对于 v2 SKU,运行状况探测会等待一段时间间隔。 连续探测失败计数达到不正常阈值后,将后端服务器标记为故障。 |
默认探测仅查看 <协议>://127.0.0.1:<端口> 以确定健康状态。 如果需要配置运行状况探测以使其转到自定义 URL 或修改任何其他设置,必须使用自定义探测。 有关 HTTPS 探测的详细信息,请参阅应用程序网关的 TLS 终止和端到端 TLS 概述。
自定义的运行状况探测
使用自定义探测可以更精细地监控健康状态。 使用自定义探测时,可以配置自定义主机名、URL 路径、探测间隔,以及在将后端池实例标记为不正常之前可接受的失败响应次数等。
自定义健康检查设置
下表提供自定义健康探针属性的定义。
| 探测属性 | 说明 |
|---|---|
| 名称 | 探测的名称。 此名称用于在后端 HTTP 设置中标识和引用探测。 |
| 协议 | 用于发送探测的协议。 这必须与它关联到的后端 HTTP 设置中定义的协议匹配 |
| 主机 | 发送探测时使用的主机名。 在 v1 SKU 中,此值仅用作探测请求的主机头。 在 v2 SKU 中,此值被用作主机名头和 SNI |
| 路径 | 探测的相对路径。 有效路径以“/”开头 |
| 端口 | 如果已定义,它将用作目标端口。 否则,它会使用与其关联的 HTTP 设置相同的端口。 此属性仅在 v2 SKU 中可用 |
| 时间间隔 | 探测间隔(秒)。 此值是每两次连续探测之间的时间间隔 |
| 超时 | 探测超时时间,以秒为单位。 如果在此超时期间内未收到有效响应,探测将被标记为失败 |
| 不健康阈值 | 探针重试计数。 连续探测失败次数达到不健康阈值后,后端服务器将被标记为宕机。 |
| MinServers | 始终保持正常状态的最小服务器数量。 默认值为 0,这意味着运行状况探测结果确定所有后端服务器的运行状况状态。 当设置为大于 0 的值时,无论探测结果如何,指定的服务器数始终标记为正常。 此属性只能通过 PowerShell、Azure CLI 或 ARM 模板进行配置(在 Azure 门户中不可用)。 |
警告
请谨慎使用 MinServers 参数。 将 MinServers 设置为大于 0 的值时,应用程序网关始终将最小后端服务器数标记为正常,即使其运行状况探测失败也是如此。 这可能会导致流量发送到不正常的服务器,这可能会导致客户端出现 502 错误的网关错误或其他连接问题。 仅在您具有特定的可用性要求并且理解重写健康探测结果的影响时,才配置 MinServers。
探针匹配
默认情况下,状态代码为 200 到 399 的 HTTP(S) 响应被视为正常。 自定义运行状况探测另外支持两个额外的匹配条件。 可根据需要使用条件匹配来修改构成正常响应的因素的默认解释。
下面是匹配条件:
- HTTP 响应状态代码匹配 - 接受用户指定的 HTTP 响应代码或响应代码范围的探针匹配标准。 支持逗号分隔的单个响应状态代码,或一系列状态代码。
- HTTP 响应正文匹配 - 查找 HTTP 响应正文并匹配用户指定字符串的探测匹配条件。 该匹配操作只会在响应正文中确定是否存在用户指定的字符串,而不执行完整正则表达式匹配。 指定的匹配项不得超过 4090 个字符。
可以使用 New-AzApplicationGatewayProbeHealthResponseMatch cmdlet 指定匹配条件。
例如:
$match = New-AzApplicationGatewayProbeHealthResponseMatch -StatusCode 200-399
$match = New-AzApplicationGatewayProbeHealthResponseMatch -Body "Healthy"
可以在 PowerShell 中使用 -Match 运算符将匹配条件附加到探测配置。
自定义探测的一些用例
- 如果后端服务器仅允许经过身份验证的用户访问,则应用程序网关探测将收到 403 响应代码而不是 200。 由于客户端(用户)必须针对实时流量自行进行身份验证,因此可以将探测流量配置为接受 403 作为预期响应。
- 当后端服务器安装了通配符证书 (*.contoso.com) 来为不同的子域提供服务时,可以使用具有接受的特定主机名(SNI 必需)的自定义探测来建立成功的 TLS 探测,并将该服务器报告为运行正常。 将后端设置中的“替代主机名”设置为“否”时,不同的传入主机名(子域)将按原样传递到后端。
NSG 注意事项
公共预览版中可以通过 NSG 规则对应用程序网关子网进行精细控制。 更多详细信息请参阅此处。
对于当前功能,存在一些限制:
对于应用程序网关 v1 SKU,必须允许 TCP 端口 65503-65534 上的传入 Internet 流量;对于 v2 SKU,必须允许 TCP 端口 65200-65535 上的传入 Internet 流量,并将目标子网设置为“任何”,将源设置为“GatewayManager”服务标记。 此端口范围是进行 Azure 基础结构通信所必需的。
此外,不能阻止出站 Internet 连接,并且必须允许来自 AzureLoadBalancer 标记的入站流量。
有关详细信息,请参阅应用程序网关配置概述。
后续步骤
了解应用程序网关的运行状况监视后,可以在 Azure 门户中配置自定义运行状况探测,或使用 PowerShell 和 Azure Resource Manager 部署模型配置自定义运行状况探测。