使用 Azure 门户扩展和缩减资源
若要缩放缓存,请在 Azure 门户 中导航到缓存,并从“资源”菜单中选择 缩放。
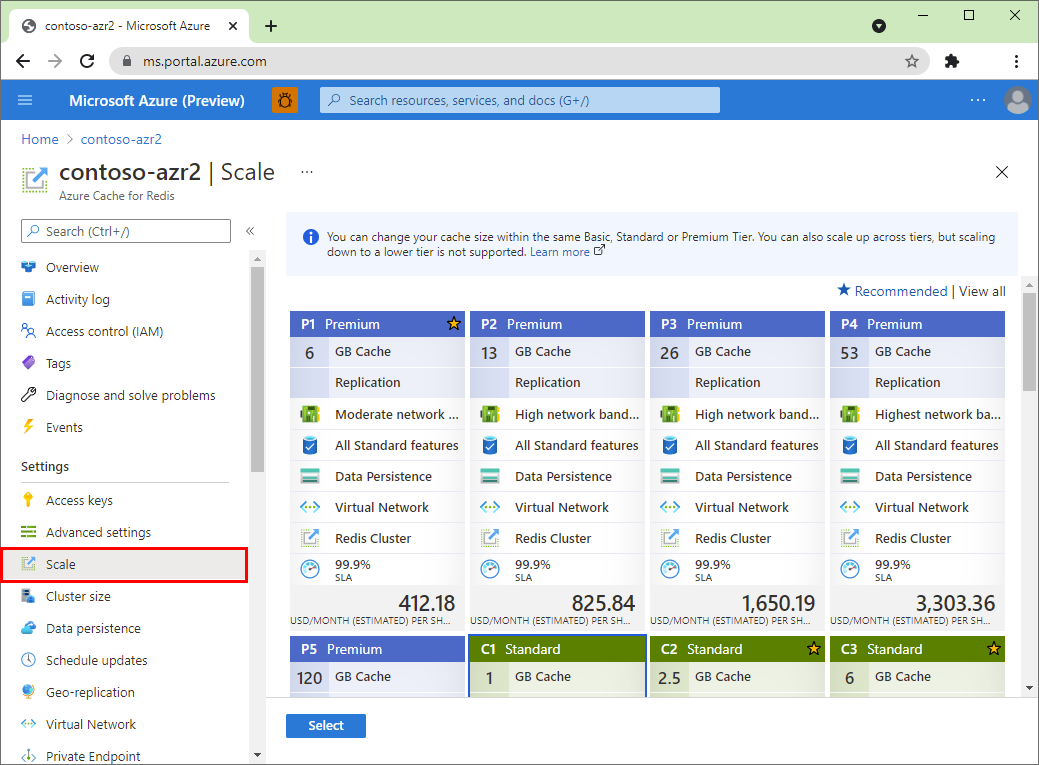
选择工作窗格中的定价层,然后选择“选择”。
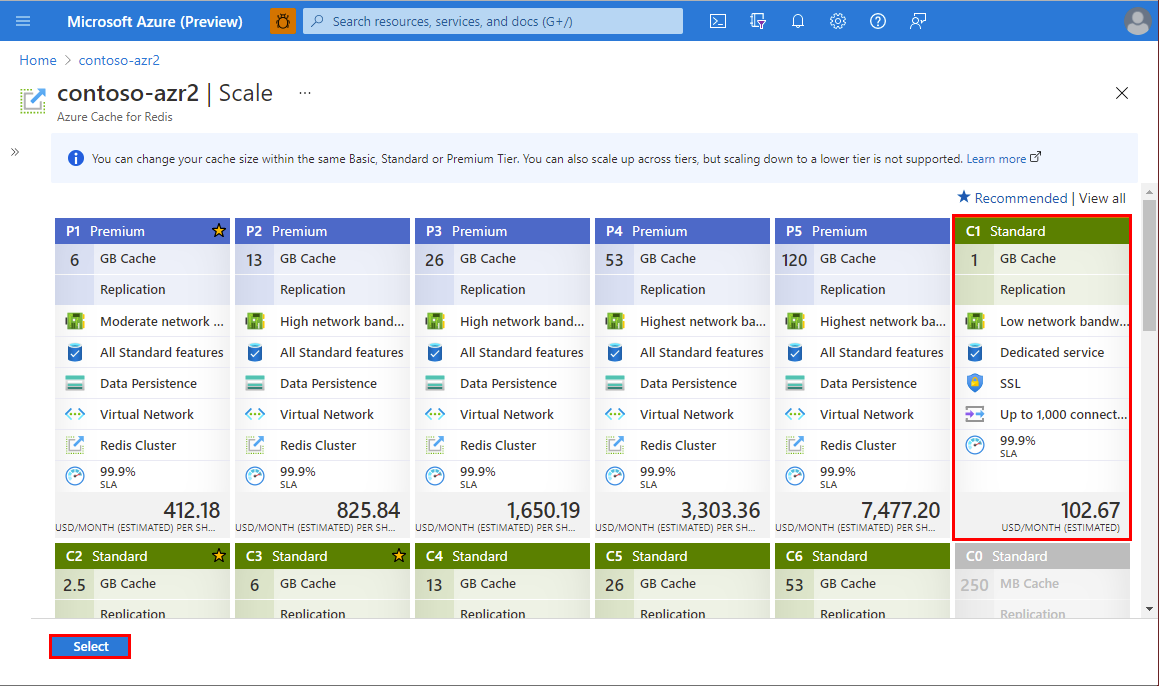
当缓存缩放到新层级时,会显示“缩放 Redis 缓存”通知。
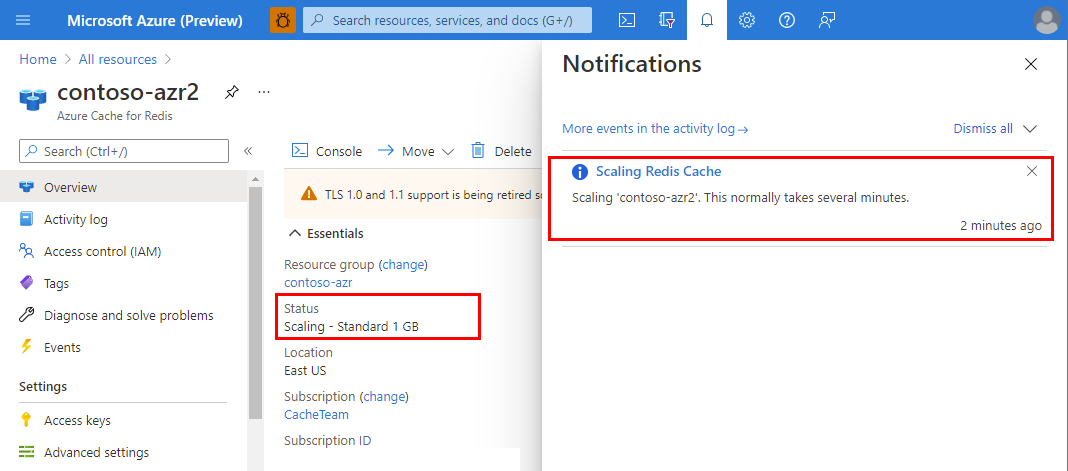
缩放完成后,状态将从正在缩放更改为正在运行。
注意
使用门户纵向扩展或缩减缓存时,maxmemory-reserved 和 maxfragmentationmemory-reserved 设置都会自动根据缓存大小按比例进行缩放。
例如,如果 maxmemory-reserved 在 6 GB 缓存上设置为 3 GB,并且你扩展到 12 GB 缓存,则在扩展期间这些设置会自动更新为 6 GB。
纵向缩减时,将发生相反的行为。
使用 PowerShell 扩展或缩减
当修改 或 Size 属性时,可以通过 PowerShell 使用 Sku cmdlet 来缩放 Azure Cache for Redis 实例。 以下示例演示了如何将名为 myCache 的缓存缩放为同一层中的 6 GB 缓存。
Set-AzRedisCache -ResourceGroupName myGroup -Name myCache -Size 6GB
有关通过 PowerShell 缩放的更多信息,请参阅 使用 PowerShell 缩放 Azure Cache for Redis。
使用Azure CLI纵向扩展和缩减
若要使用 Azure CLI 缩放Azure Cache for Redis实例,请调用 az redis update 命令。 使用 sku.capacity 属性在层内缩放,例如从标准 C0 到标准 C1 缓存:
az redis update --cluster-name myCache --resource-group myGroup --set "sku.capacity"="2"
使用“sku.name”和“sku.family”属性纵向扩展到不同的层,例如从标准 C1 缓存扩展到高级 P1 缓存:
az redis update --cluster-name myCache --resource-group myGroup --set "sku.name"="Premium" "sku.capacity"="1" "sku.family"="P"
有关使用 Azure CLI 进行扩展缩放操作的详细信息,请参阅 更改现有 Azure Cache for Redis 的设置。
注意
当您以编程方式(例如使用 PowerShell 或 Azure CLI)缩放缓存时,更新请求中的任何 maxmemory-reserved 或 maxfragmentationmemory-reserved 都将被忽略。 只有缩放更改会被遵循。 缩放作完成后,可以更新这些内存设置。
创建使用集群进行横向扩展的新缓存
在从工作窗格中创建新的 Azure Cache for Redis 时,会启用群集功能。
使用 创建开源 Redis 缓存快速入门指南开始使用 Azure 门户创建新缓存。
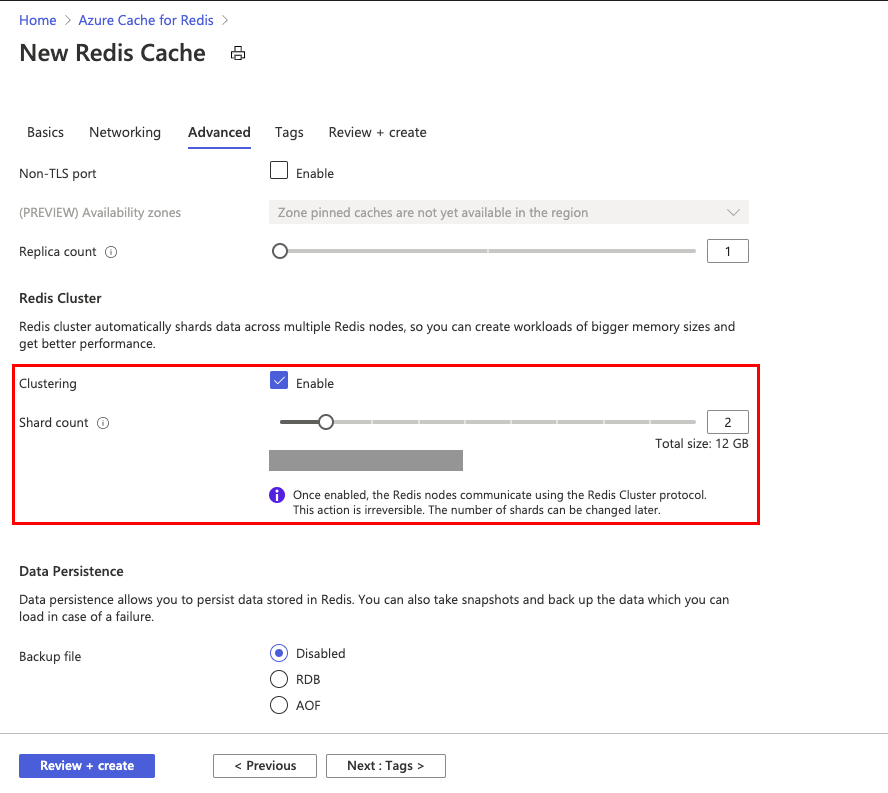
在高级缓存实例的“高级”选项卡中,配置非 TLS 端口、聚类分析和数据持久化的设置。 若要选择群集,请选择“启用”。
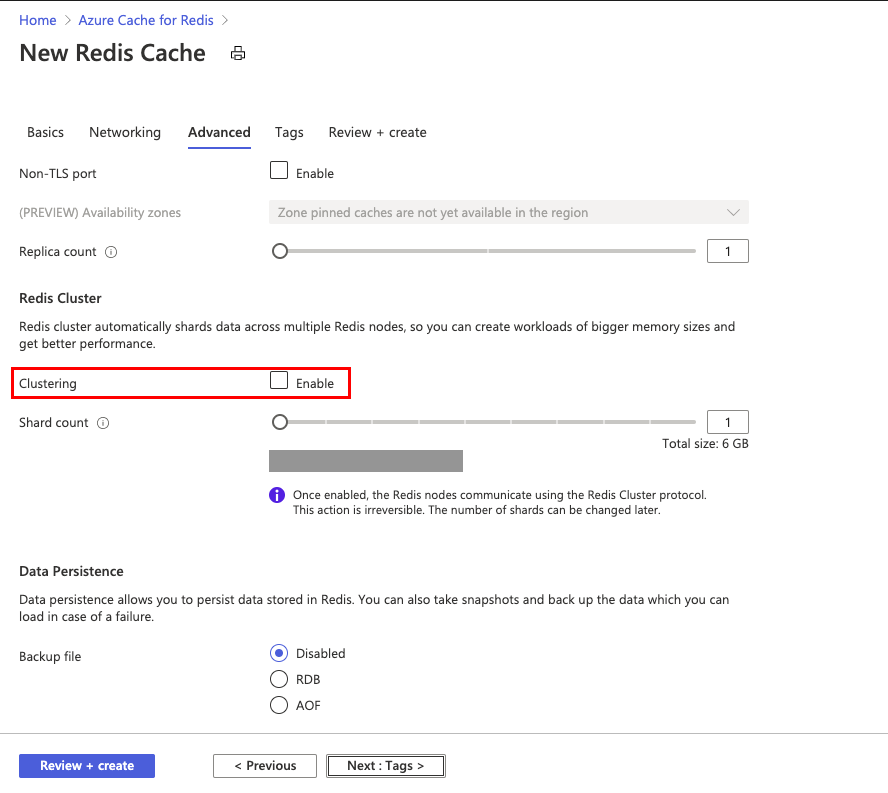
群集中最多可以有 30 个分片。 选择“启用”后,滑动滑块或者针对“分片计数”键入一个 1 到 30 之间的数字,并选择“确定”。
每个分片都是由Azure管理的主要/副本缓存对。 缓存的总大小是通过将在定价层中选择的缓存大小乘以分片数来计算的。
创建缓存后,可连接到缓存,并像使用非群集缓存一样使用它。 Redis 将数据分布在各个缓存分片中。 如果启用了诊断功能,则会为每个分片单独捕获指标,并且可以使用“资源”菜单在 Azure 缓存 Redis 中查看。
使用快速入门指南完成缓存的创建。
创建缓存需要花费片刻时间。 可以在 Azure Cache for Redis Overview 页上监视进度。 如果“状态”显示为“正在运行”,则表示该缓存可供使用。
有关使用 StackExchange.Redis 客户端进行聚类分析的示例代码,请参阅 Hello World 示例的 clustering.cs 部分。
缩减或扩展正在运行的高级缓存
如果之前创建的高级缓存正在运行且已启用群集功能,若要更改它上面的群集大小,请在“资源菜单”中选择“群集大小”。
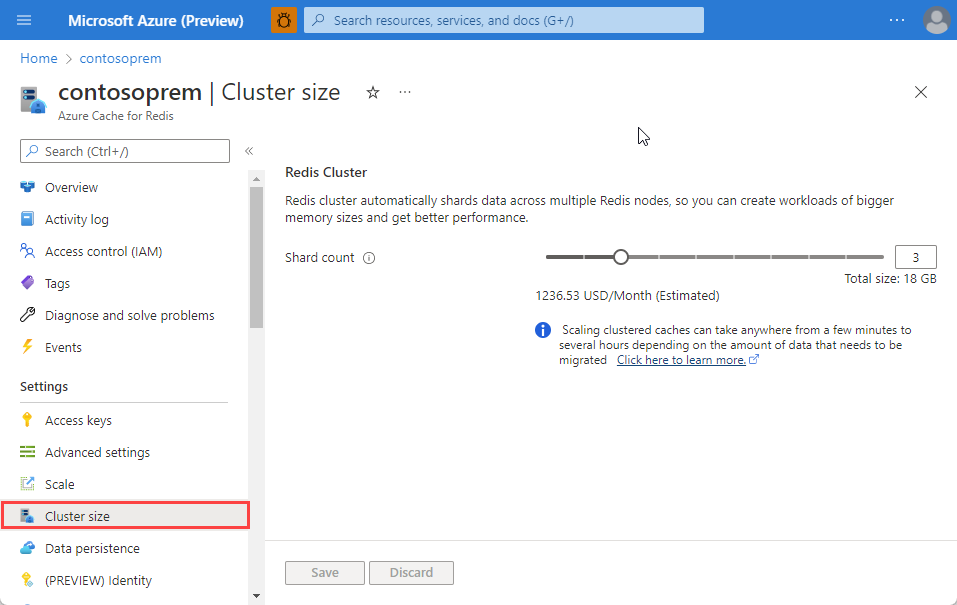
若要更改群集大小,请使用滑块,或在“分片计数”文本框中键入 1 到 30 之间的数字。 然后选择“确定”以保存。
增加群集大小会增加最大吞吐量和缓存大小。 增加群集大小不会增加可供客户端使用的最大连接数。
使用 PowerShell 横向扩展和缩减
修改 属性时,可以使用 ShardCount cmdlet 通过 PowerShell 横向扩展Azure Cache for Redis实例。 以下示例演示了如何横向扩展名为 myCache 的缓存以使用三个分片(即按三倍进行横向扩展)
Set-AzRedisCache -ResourceGroupName myGroup -Name myCache -ShardCount 3
有关通过 PowerShell 缩放的更多信息,请参阅 使用 PowerShell 缩放 Azure Cache for Redis。
使用 Azure CLI 进行横向扩展和收缩
若要使用 Azure CLI 缩放Azure Cache for Redis实例,请调用 az redis update 命令并使用 shard-count 属性。 以下示例演示了如何横向扩展名为 myCache 的缓存以使用三个分片(即按三倍进行横向扩展)。
az redis update --cluster-name myCache --resource-group myGroup --set shard-count=3
有关使用 Azure CLI 进行扩展缩放操作的详细信息,请参阅 更改现有 Azure Cache for Redis 的设置。
注意
当您以编程方式(例如使用 PowerShell 或 Azure CLI)缩放缓存时,更新请求中的任何 maxmemory-reserved 或 maxfragmentationmemory-reserved 都将被忽略。 只有缩放更改会被遵循。 缩放作完成后,可以更新这些内存设置。
缩放群集会运行 MIGRATE 命令,而这是一个价格高昂的命令。 为了尽量减少影响,请考虑在非高峰时段运行此作。 在迁移过程中,服务器负载会达到峰值。 缩放群集的运行过程耗时较长,所花费的时间量取决于密钥数以及与这些密钥相关联的值的大小。
关于扩展的常见问题
以下列表包含有关Azure Cache for Redis缩放的常见问题的解答。
是否可以扩展到高级缓存、从高级缓存缩减,或在高级缓存内部调整大小?
- 不能从高级缓存向下缩放到基本或标准定价层。
- 可以将一个高级缓存定价层扩展到另一个高级缓存定价层。
- 不能从基本缓存直接缩放到高级缓存。 首先在一个缩放操作中从“基本”缩放到“标准”,然后在后续的缩放操作中从“标准”缩放到“高级”。
- 如果在创建高级缓存时启用了群集,则可以更改群集大小。 如果创建缓存时未启用群集功能,可以稍后进行配置。
缩放后,我是否需要更改缓存名称或访问密钥?
否,在缩放作期间,缓存名称和密钥不会更改。
缩放的工作原理?
- 当您将基本缓存调整为不同大小时,该缓存将被关闭,并使用新的大小创建一个新缓存。 在此期间,缓存不可用,且缓存中的所有数据都将丢失。
- 将基本缓存缩放为标准缓存时,将预配副本缓存并将主缓存中的数据复制到副本缓存。 在缩放过程中,缓存仍然可用。
- 将 Standard 缓存和 Premium 缓存缩放为不同的大小时,其中一个副本会被关闭,然后重新预配为新的大小,并转移数据。随后,另一个副本在重新预配之前执行故障转移,类似于一个缓存节点发生故障时的过程。
- 横向扩展群集缓存时,将预配新的分片并将其添加到 Redis 服务器群集中。 然后,数据将在所有分片上重新切分。
- 在群集缓存中进行缩放时,首先对数据重新进行切分,然后针对所需的分片缩减群集大小。
- 将缓存缩放或迁移到其他群集时,缓存的基础 IP 地址可能会更改。 缓存的 DNS 记录会发生变化,并且对大多数应用程序是透明的。 但是,如果使用 IP 地址配置与缓存的连接,或配置允许流量到缓存的 NSG 或防火墙,则应用程序在 DNS 记录更新后连接时可能会遇到问题。
在缩放过程中是否会丢失缓存中的数据?
- 将基本缓存缩放为新的大小时,所有数据都会丢失,且在缩放操作期间缓存将不可用。
- 将基本缓存缩放为标准缓存时,通常将保留缓存中的数据。
- 将标准、高级缓存扩展到更大尺寸时,通常会保留所有数据。 将标准缓存或高级缓存缩放为更小的大小时,如果原始数据大小超出了新的较小大小,数据可能会丢失。 如果在缩小时数据丢失,则使用 allkeys-LRU 逐出策略清除密钥。
扩展后是否可以使用付费版的所有功能?
否,某些功能只能在高级层中创建缓存时设置,无法在缩放后使用。
创建高级缓存后,无法添加这些功能:
- 注入虚拟网络
- 添加区域冗余
- 每个主数据库使用多个副本
若要使用这些功能中的任何一个,必须在高级层中创建新的缓存实例。
在缩放过程中,自定义数据库设置是否会受影响?
如果在缓存创建过程中为 databases 设置配置了自定义值,请记住,某些定价层具有不同的数据库限制。 以下是在这种情况下缩放时的一些注意事项:
- 当缩放到限制低于当前层的定价层时:
- 如果使用的是默认
databases 数(对于所有定价层来说为 16),则不会丢失数据。
- 如果你使用的是在你要扩展的等级限制内的自定义
databases 数,此 databases 设置将保持不变,并且数据不会丢失。
- 如果使用的是超出新层限制的自定义
databases 数,则 databases 设置将降低到新层的限制,并且已删除数据库中的所有数据都将丢失。
- 当您缩放到限制等于或高于当前层的定价层时,
databases 设置会保留,并且数据不会丢失。
虽然“标准”、“高级”缓存具有可用性 SLA,但没有数据丢失方面的 SLA。
缓存在缩放期间是否可用?
-
“标准”、“高级”缓存在缩放操作期间保持可用。 但在缩放这些缓存时,以及从基本缓存缩放到标准缓存时,可能会遇到连接问题。 Redis 客户端通常可以迅速重新建立连接,这些连接中断预计很小。
-
基本缓存会在变更至不同大小的缩放操作期间处于离线状态。 基本缓存在从基本缩放到标准时仍然可用,但可能会出现较小的连接波动。 如果发生连接故障,Redis 客户端通常可以立即重新建立连接。
异地复制是否存在扩展限制?
在配置了被动异地复制的情况下,你可能会注意到无法缩放缓存或更改群集中的分片。 两个缓存之间的异地复制链接会阻止你执行缩放操作或更改群集中的分片数。 若要发布这些命令,必须取消链接缓存。 有关详细信息,请参阅配置异地复制。
不支持的操作
- 不能从较高的定价层缩放到较低的定价层。
- 不能从高级缓存向下缩放到标准或基本缓存。
- 不能从标准缓存向下缩放到基本缓存。
- 可从基本缓存缩放到标准缓存,但不能同时更改大小。 以后如果需要不同的大小,可以执行缩放操作以缩放为所需大小。
- 不能从基本缓存直接缩放到高级缓存。 首先在一次扩展操作中将“基本”扩展到“标准”,然后在之后的操作中将“标准”扩展到“高级”。
- 不能从较大的大小减小为 C0 (250 MB) 。
如果缩放操作失败,该服务将尝试还原操作并且缓存将还原为原始大小。
扩展需要多长时间?
扩展时间取决于几个因素。 以下因素可能会影响调整规模所需的时间:
- 数据量:较大的数据量需要更长的时间才能复制。
- 高写入请求:写入次数较高意味着跨节点或分片复制的数据越多。
- 高服务器负载:更高的服务器负载意味着 Redis 服务器正忙,并且有限的 CPU 周期可用于完成数据重新分发。
缩放缓存并不是一个简单作,可能需要很长时间。 在负载不重的情况下,用一到两个分片缩放缓存可能需要一到两小时。 如果有更多的分片,缩放时间不会以线性方式增加。
如何判断缩放何时完成?
在Azure门户中,您可以看到缩放操作正在进行。 缩放完成后,缓存状态将更改为正在运行。
使用群集功能时,是否需要对客户端应用程序进行更改?
启用群集功能时,仅数据库 0 可用。 如果客户端应用程序使用多个数据库并尝试读取或写入非零的数据库,则会发生以下异常: Unhandled Exception: StackExchange.Redis.RedisConnectionException: ProtocolFailure on GET --->StackExchange.Redis.RedisCommandException: Multiple databases are not supported on this server; cannot switch to database: 6
有关详细信息,请参阅 Redis 群集规范 - 已实现子集。
如果使用的是 StackExchange.Redis,则必须使用 1.0.481 或更高版本。 连接到该缓存时,可以使用的终结点、端口和密钥与连接到禁用了群集功能的缓存时使用的相同。 唯一的区别是,所有读取和写入都必须在数据库 0 中进行。
其他客户端可能有不同的要求。 有关详细信息,请参阅所有 Redis 客户端是否支持群集?
如果应用程序使用的多个密钥操作都在单个命令中成批执行,则所有密钥都必须位于同一分片。 若要在同一分片中找到密钥,请参阅 如何在群集中分发密钥?
如果使用 Redis ASP.NET 会话状态提供程序,则必须使用 2.0.1 或更高版本。 有关详细信息,请参阅 是否可以将群集与 Redis ASP.NET 会话状态和输出缓存提供程序配合使用?。
密钥在群集中是如何分布的?
按照关于密钥分布模型的 Redis 文档:密钥空间会拆分为 16,384 个槽。 每个密钥都经过哈希处理并分配到其中一个槽,这些槽分布在群集的节点中。 对密钥的哪部分进行哈希处理是可以配置的,这样可确保多个使用哈希标记的密钥位于同一分片。
- 使用哈希标记的密钥 - 如果将密钥的任意部分括在
{ 和 } 中,则只会对密钥的该部分进行哈希处理,以便确定密钥的哈希槽。 例如,以下 3 个密钥将位于同一分片中:{key}1、{key}2 和 {key}3,因为只对名称的 key 部分进行了哈希处理。 如需密钥哈希标记规范的完整列表,请参阅 密钥哈希标记。
- 不带哈希标记的密钥 - 使用整个密钥名称进行哈希处理,从而在缓存的分片中均匀分布。
为了优化性能和吞吐量,建议将密钥平均分布。 如果使用带哈希标记的密钥,则应用程序会负责确保密钥平均分布。
有关详细信息,请参阅 密钥分布模型、Redis 群集数据分片 和 密钥哈希标记。
有关使用 StackExchange.Redis 客户端在同一分片中使用群集和定位键的示例代码,请参阅 Hello World 示例的 clustering.cs 部分。
可以创建的最大缓存大小是多大?
可以具有的最大缓存大小为 4.5 TB。 此结果是容量为 9 的群集的 F1500 缓存。 有关详细信息,请参阅 Azure Cache for Redis Pricing。
是否所有 Redis 客户端都支持群集功能?
很多(但并非全部)客户端库都支持 Redis 群集。 检查您正在使用的库的文档,以确认您所选择的库和版本是否支持群集。 StackExchange.Redis 是一个库,它在更新的版本中确实支持群集。 有关其他客户端的详细信息,请参阅 Redis cluster tutorial(Redis 群集教程)的 Playing with the cluster(操作群集)部分。
Redis 群集协议要求每个客户端以群集模式直接连接到每个分片,并且还定义了新的错误响应,例如 MOVED 和 CROSSSLOTS。 尝试使用的客户端库不支持群集但包含群集模式缓存时,结果可能造成很多 MOVED 重定向异常,如果正在执行跨槽多密钥请求,则会中断应用程序。
启用群集功能后,如何连接到缓存?
连接到缓存时,可以使用的终结点、端口和密钥与你连接到未启用群集功能的缓存时使用的相同。 Redis 在后端管理群集功能,因此不需要你通过客户端来管理它。
可以直接连接到缓存的各个分片吗?
群集协议要求客户端建立正确的分片连接,以便客户端应为你建立共享连接。 话虽如此,但每个分片都是由主/副缓存对组成的,该缓存对统称为缓存实例。 可以使用 GitHub Redis 存储库的 unstable 分支中的 Redis-CLI 实用工具连接到这些缓存实例。 使用 -c 开关启动后,此版本可实现基本的支持。 有关更多信息,请参阅Redis 群集教程中的https://redis.io。
需要使用 -p 开关来指定要连接到的正确端口。 使用 CLUSTER NODES 命令来确定用于主节点和副本节点的确切端口。 使用以下端口范围:
- 对于非 TLS 高级层缓存,端口在
130XX 范围内可用
- 对于已启用 TLS 的高级层缓存,端口在
150XX 范围内可用
是的。 首先,通过向上扩展来升级缓存,以确保缓存处于高级层级。 接下来,你将看到群集配置选项,包括启用群集的选项。 在创建缓存或首次启用群集功能后更改群集大小。
重要
无法撤消启用群集功能。 启用了群集功能且只有一个分片的缓存的行为与没有群集功能的相同大小缓存的行为不同。
群集功能仅适用于高级缓存。
是否可以将群集与 Redis ASP.NET 会话状态和输出缓存提供程序配合使用?
-
Redis 输出缓存提供程序 - 无需进行更改。
- Redis 会话状态提供程序 - 若要使用群集,必须使用 RedisSessionStateProvider 2.0.1 或更高版本,否则会引发异常,这是一个重要的破坏性更改。 有关更多信息,请参阅 v2.0.0 重大变更详细信息。
我在使用 StackExchange.Redis 和群集功能时出现 MOVE 异常,应该怎么办?
如果使用的是 StackExchange.Redis 并在使用群集功能时收到 MOVE 异常,请确保使用的是 StackExchange.Redis 1.1.603 或更高版本。
后续步骤