按照本文中的步骤确定无法在 Azure Monitor 中按预期方式收集 Prometheus 指标的原因。
副本 Pod 从 kube-state-metrics、ama-metrics-prometheus-config 配置映射中的自定义抓取目标以及自定义资源中定义的自定义抓取目标中抓取指标。 DaemonSet Pod 在其各自的节点上从以下目标中抓取指标:kubelet、cAdvisor、node-exporter 和 ama-metrics-prometheus-config-node 配置映射中的自定义抓取目标。 要查看日志的 Pod 和 Prometheus UI 取决于你正在调查的抓取目标。
使用 PowerShell 脚本进行故障排除
如果在尝试为 AKS 群集启用监视时遇到错误,请按照以下说明运行故障排除脚本。 此脚本旨在就群集上是否存在配置问题进行基本诊断,你可以在创建支持请求时附加生成的文件,以便更快地解决支持案例。
指标限制
适用于 Prometheus 的 Azure Monitor 托管服务具有用于引入的默认限制和配额。 当达到引入限制时,可能会发生限制。 可以请求增加这些限制。 有关 Prometheus 指标限制的信息,请参阅Azure Monitor 服务限制。
在 Azure 门户中,导航到你的 Azure Monitor 工作区。 转到 Metrics,然后选择指标 Active Time Series % Utilization 和 Events Per Minute Received % Utilization。 验证两者是否都低于 100%。
若要详细了解如何监视引入指标并针对其发出警报,请参阅监视 Azure Monitor 工作区指标引入。
指标数据收集中的间歇性间隙
在节点更新期间,对于从群集级别收集器收集的指标,你可能会看到指标数据中存在 1 到 2 分钟的间隔。 之所以存在此间隙,是因为运行它的节点正在更新,作为正常更新过程的一部分。 这会影响群集范围内的目标,例如 kube-state-metrics 和指定的自定义应用程序目标。 手动更新群集或通过自动更新来更新群集时,会出现这种情况。 此行为是预期的,因为其运行的节点正在更新。 我们推荐的警报规则均不受此行为的影响。
Pod 状态
使用以下命令检查 pod 状态:
kubectl get pods -n kube-system | grep ama-metrics
当服务正常运行时,会返回以下格式为 ama-metrics-xxxxxxxxxx-xxxxx 的 Pod 的列表:
ama-metrics-operator-targets-*ama-metrics-ksm-*- 群集上每个节点的
ama-metrics-node-*Pod。
每个 pod 的状态应为 Running,并且重启次数与已应用的 configmap 更改次数相等。 ama-metrics-operator-targets-* Pod 开始时可能会有一次额外重启,这是预期的:

如果每个 pod 的状态为 Running,但有一个或多个 pod 重启,请运行以下命令:
kubectl describe pod <ama-metrics pod name> -n kube-system
- 此命令会提供重启的原因。 如果 configmap 已更改,则预计会重启 Pod。 如果重启的原因为
OOMKilled,Pod 无法跟上指标量。 请参阅关于指标规模的建议。
如果 Pod 按预期运行,则下一个检查位置是容器日志。
检查重新标记配置
如果缺少指标,还可以检查是否有重新标记配置。 使用重新标记配置时,请确保重新标记不会筛选掉目标,并且配置的标签与目标正确匹配。 有关详细信息,请参阅 Prometheus 重新标记配置文档。
容器日志
使用以下命令查看容器日志:
kubectl logs <ama-metrics pod name> -n kube-system -c prometheus-collector
启动时,任何初始错误都以红色显示,而警告则以黄色显示。 (至少需要安装 PowerShell 版本 7 或 Linux 发行版才能查看彩色日志内容。)
- 验证获取身份验证令牌时是否出现问题:
- 每 5 分钟记录一次消息“AKS 资源不存在配置”。
- Pod 每 15 分钟重启一次,然后重试并出现错误:AKS 资源不存在任何配置。
- 如果是这样,请检查资源组中是否存在数据收集规则和数据收集终结点。
- 此外,请验证 Azure Monitor 工作区是否存在。
- 确保没有专用 AKS 群集,并且该 AKS 群集未关联到任何其他服务的 Azure Monitor 专用链接范围。 目前不支持此方案。
配置处理
使用以下命令查看容器日志:
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c config-reader
- 验证 Prometheus 配置的解析是否无误,确保与所有启用的默认抓取目标正确合并,并验证完整配置。
- 如果你确实加入了自定义 Prometheus 配置,请验证它是否在日志中被识别。 如果不是这样的话:
- 验证 configmap 的名称是否正确:
ama-metrics-prometheus-config,所在命名空间为kube-system。 - 验证在 configmap 中,Prometheus 配置是否位于
prometheus-config下名为data的部分下,如下所示:kind: ConfigMap apiVersion: v1 metadata: name: ama-metrics-prometheus-config namespace: kube-system data: prometheus-config: |- scrape_configs: - job_name: <your scrape job here>
- 验证 configmap 的名称是否正确:
- 如果确实创建了自定义资源,那么你应该已经在创建 Pod/服务监视器期间看到了任何验证错误。 如果仍然看不到目标中的指标,请确保日志未显示任何错误。
kubectl logs <ama-metrics-operator-targets pod name> -n kube-system -c targetallocator
- 验证
MetricsExtension中是否未发生有关对 Azure Monitor 工作区进行身份验证的错误。 - 确认
OpenTelemetry collector中没有关于抓取目标的错误。
运行以下命令:
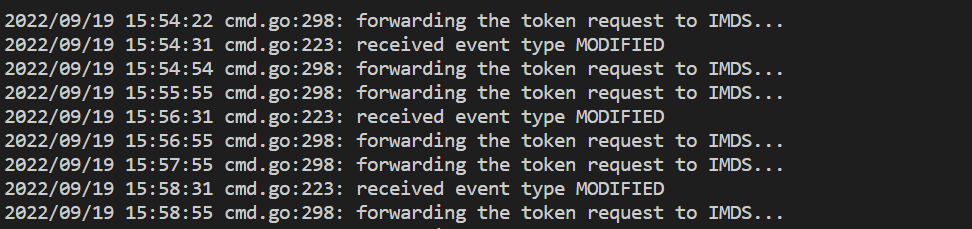
kubectl logs <ama-metrics pod name> -n kube-system -c addon-token-adapter
- 如果对 Azure Monitor 工作区进行身份验证时出现问题,此命令会显示错误。 下面是一个没有问题的日志示例:

如果日志中没有错误,则可以使用 Prometheus 接口进行调试,以验证是否抓取了预期的配置和目标。
Prometheus 接口
每个 ama-metrics-* Pod 都有端口 9090 上提供的 Prometheus 代理模式用户界面。
自定义配置和自定义资源目标由 ama-metrics-* Pod 抓取,节点目标则由 ama-metrics-node-* pod 抓取。
端口转发到副本 Pod 或其中一个守护程序集 Pod,以如此处所述检查配置、服务发现和目标终结点,确认自定义配置正确、已发现每个作业的预期目标以及抓取特定目标时没有错误。
运行命令 kubectl port-forward <ama-metrics pod> -n kube-system 9090。
打开浏览器并访问地址
127.0.0.1:9090/config。 此用户界面具有完整的抓取配置。 验证所有作业是否都包含在配置中。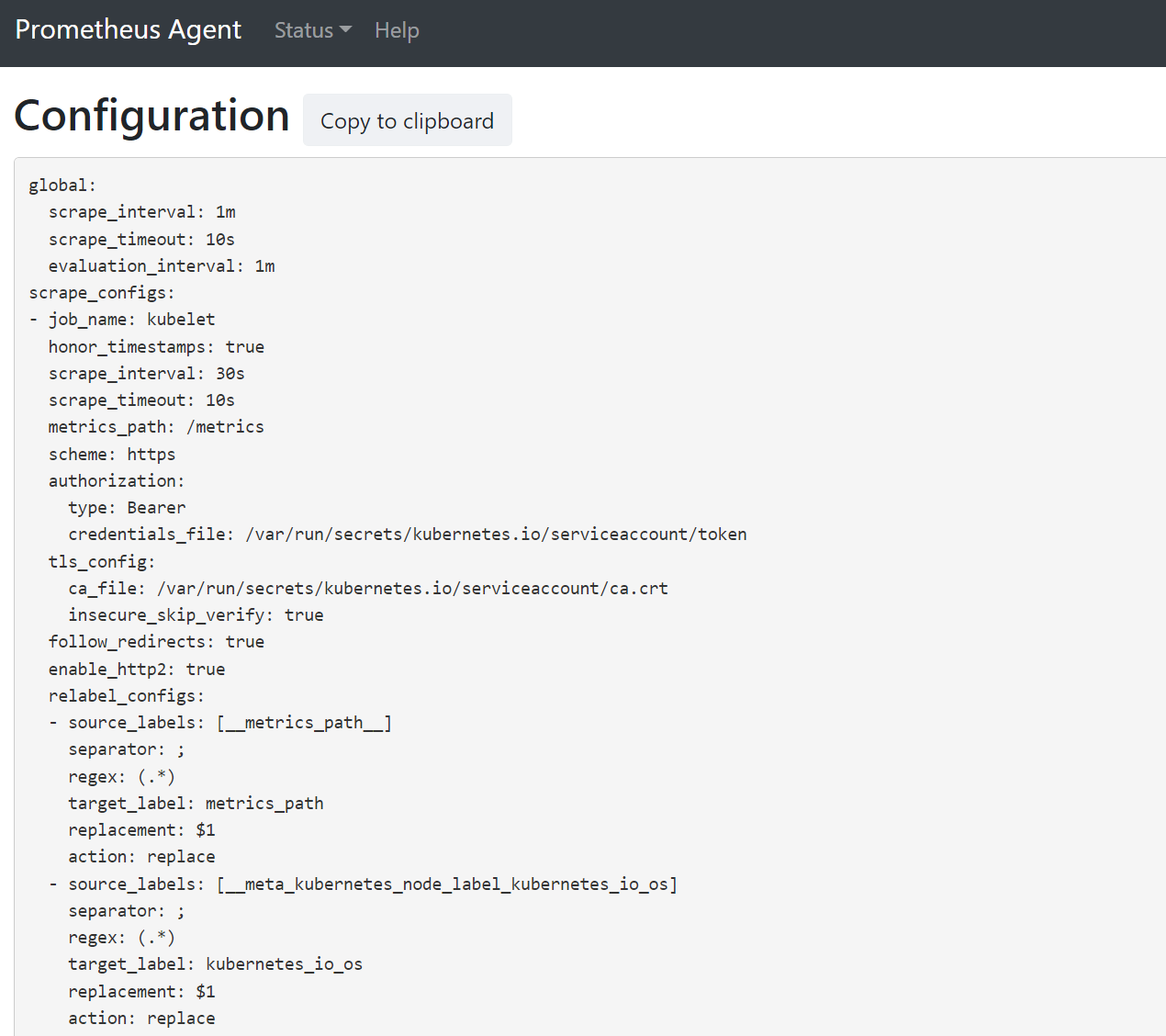
转到
127.0.0.1:9090/service-discovery查看指定的服务发现对象发现的目标以及 relabel_configs 已筛选目标的内容。 例如,如果某个 Pod 缺少指标,你可以查看该 Pod 是否被发现以及它的 URI 是什么。 然后,可以在查看目标时使用此 URI 来确定是否发生任何抓取错误。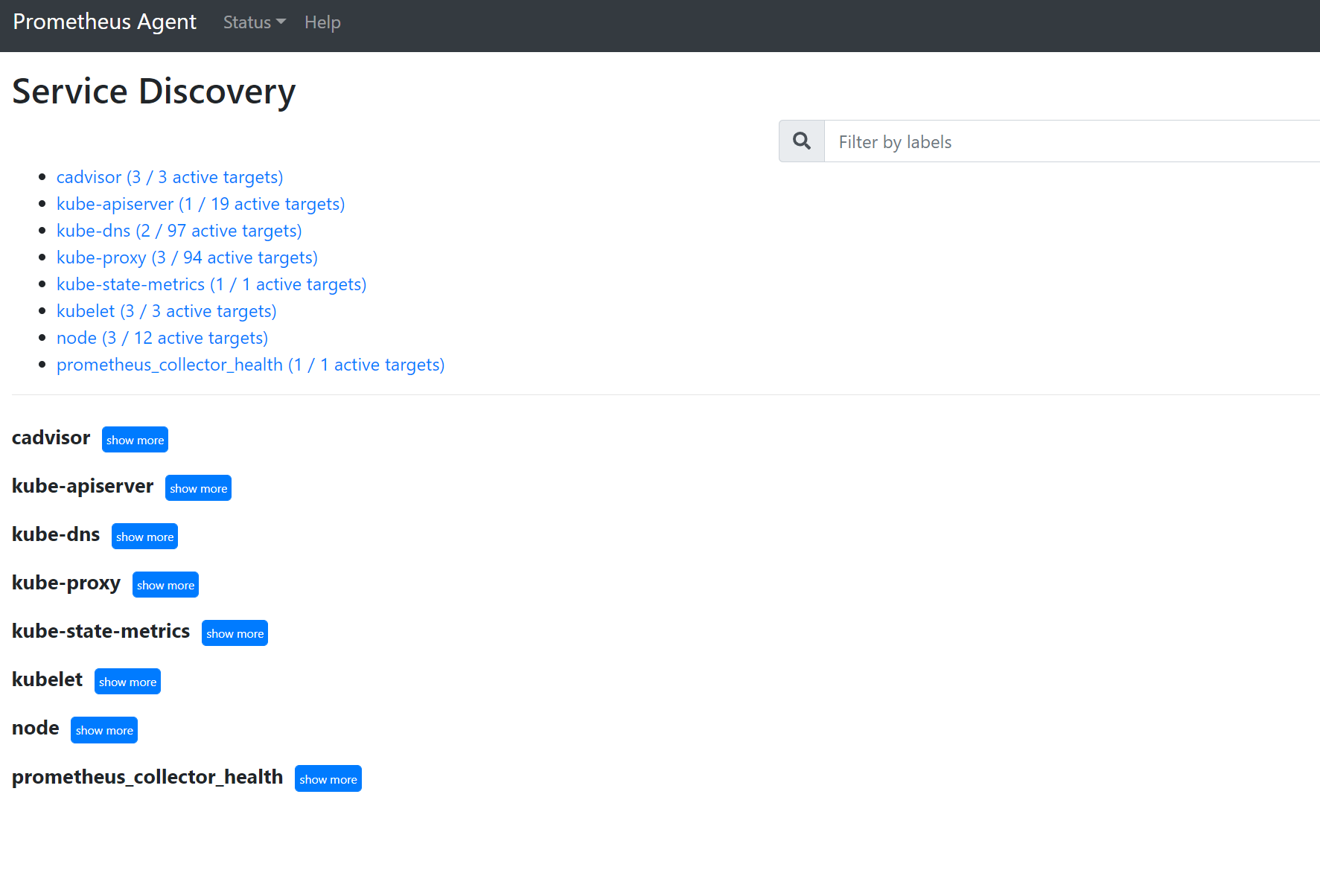
转到
127.0.0.1:9090/targets查看所有作业、上次抓取该作业的终结点的时间以及任何错误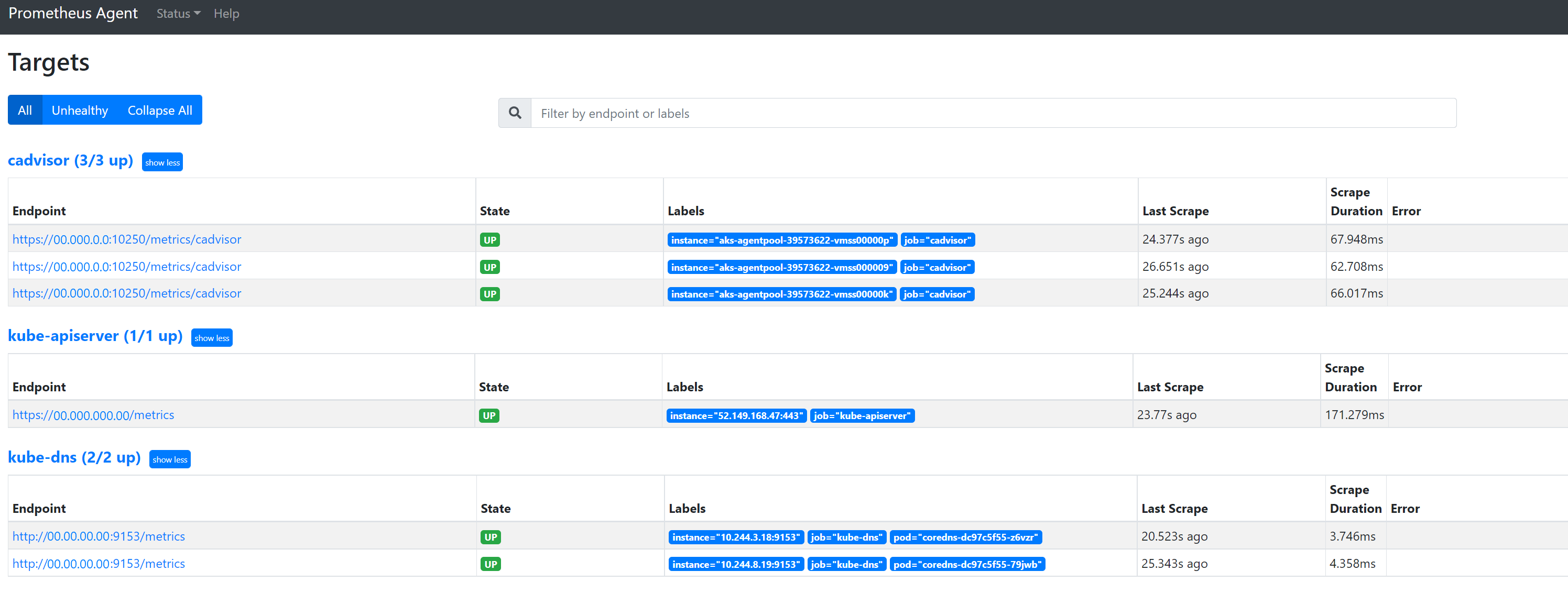



自定义资源
- 如果确实包含了自定义资源,请确保它们显示在配置、服务发现和目标下方。
配置

服务发现

目标

如果没有问题,并且正在抓取预期目标,则可以通过启用调试模式来查看正抓取的确切指标。
调试模式
警告
此模式可能会影响性能,应该出于调试目的短时间启用。
可以按照enabled的说明,通过将 debug-mode 下的 configmap 设置 true 更改为 ,将指标加载项配置为以调试模式运行。
启用后,所有抓取的 Prometheus 指标将托管在端口 9091 上。 运行以下命令:
kubectl port-forward <ama-metrics pod name> -n kube-system 9091
转到浏览器中的 127.0.0.1:9091/metrics,查看是否已由 OpenTelemetry 收集器抓取指标。 每个 ama-metrics-* Pod 都可以访问此用户界面。 如果未显示指标,原因可能是指标或标签名称长度或者标签数量有问题。 此外,检查是否超出了本文中指定的 Prometheus 指标的引入配额。
指标名称、标签名称和标签值
指标抓取目前有下表中的限制:
| 属性 | 限制 |
|---|---|
| 标签名称长度 | 小于或等于 511 个字符。 如果作业中的任何时序超过此限制,整个抓取作业会失败,并且在引入之前会从该作业中删除指标。 可以看到该作业的 up=0,并且目标 Ux 也显示了 up=0 的原因。 |
| 标签值长度 | 小于或等于 1023 个字符。 如果作业中的任何时序超过此限制,整个抓取会失败,并且在引入之前会从该作业中删除指标。 可以看到该作业的 up=0,并且目标 Ux 也显示了 up=0 的原因。 |
| 每个时序的标签数 | 小于或等于 63。 如果作业中的任何时序超过此限制,整个抓取作业会失败,并且在引入之前会从该作业中删除指标。 可以看到该作业的 up=0,并且目标 Ux 也显示了 up=0 的原因。 |
| 度量值名称长度 | 小于或等于 511 个字符。 如果作业中的任何时序超过此限制,只会删除该特定时序。 MetricextensionConsoleDebugLog 包含已丢弃指标的跟踪。 |
| 具有不同大小写的标签名称 | 同一指标示例中两个具有不同大小写的标签将被视为具有重复标签,并在引入时被丢弃。 例如,时序 my_metric{ExampleLabel="label_value_0", examplelabel="label_value_1} 会因重复的标签而被删除,因为 ExampleLabel 和 examplelabel 被视为相同的标签名称。 |
检查 Azure Monitor 工作区上的引入配额
如果发现指标缺失,您可以首先检查 Azure Monitor 工作区的引入限制是否被超出。 在 Azure 门户中,可以检查任何 Azure Monitor 工作区的当前使用情况。 可以在 Azure Monitor 工作区的 Metrics 菜单下查看当前使用指标。 以下利用率指标可作为每个 Azure Monitor 工作区的标准指标。
- 活动时序 - 过去 12 小时内最近引入工作区的唯一时序数
- 活动时序限制 - 可主动引入工作区的唯一时序数的限制
- 活动时序利用率百分比 - 当前利用的活动时序百分比
- 每分钟引入的事件数 - 最近每分钟收到的事件数(示例)
- 每分钟引入的事件数限制 - 在限制之前可以引入的每分钟最大事件数
- 每分钟引入的事件利用率百分比 - 当前指标引入速率限制的利用率百分比
要避免指标引入限制,可以监视和设置有关引入限制的警报。 请参阅监视引入限制。
请参阅服务配额和限制,了解默认配额以及可以根据使用情况增加的内容。 可以使用 Azure Monitor 工作区的 Support Request 菜单请求增加 Azure Monitor 工作区的配额。 确保在支持请求中包含 Azure Monitor 工作区的 ID、内部 ID 和位置/区域,你可以在 Azure 门户 Azure Monitor 工作区的“属性”菜单中找到这些信息。
由于 Azure Policy 评估,创建 Azure Monitor 工作区失败
如果创建 Azure Monitor 工作区失败,并出现错误 [策略禁止使用资源“resource-name-xyz”],则可能存在正在阻止创建资源的 Azure 策略。 如果有策略为 Azure 资源或资源组强制实施命名约定,则需为创建 Azure Monitor 工作区的命名约定创建豁免。
创建 Azure Monitor 工作区时,“MA_azure-monitor-workspace-name_location_managed”形式的资源组中默认自动创建“azure-monitor-workspace-name”形式的数据收集规则和数据收集终结点。 目前无法更改这些资源的名称,需要在 Azure Policy 上设置豁免,以免除上述资源免受策略评估。 请参阅Azure Policy 豁免结构。
大规模注意事项
如果要大规模收集指标,请查看以下部分以获取 HPA 和大规模指导。
图表停滞在加载状态
如果 Azure Monitor 工作区的网络流量被阻止,则会出现此问题。 这一点的根本原因通常与网络策略(如广告阻止软件)相关。 若要解决此问题,请禁用广告拦截器或将 monitor.azure.cn 流量列入允许名单,然后刷新页面。